你是否曾被AI领域层出不穷的术语搞得晕头转向?LLM、RAG、Agent、知识图谱、多模态……这些概念像“黑话”一样,每个字都认识,但连在一起就让人摸不着头脑。今天,我们就用一张“AI知识图谱”作为导航,结合通俗的比喻和实用的代码示例,帮你一次性理清这些核心概念的内涵、关联与应用。
一、AI知识图谱:你的技术导航图
理解复杂概念最好的方式,就是看清它们之间的关系。下面这张图将AI领域的主要技术与模块连接起来,构建成一个清晰的知识网络。
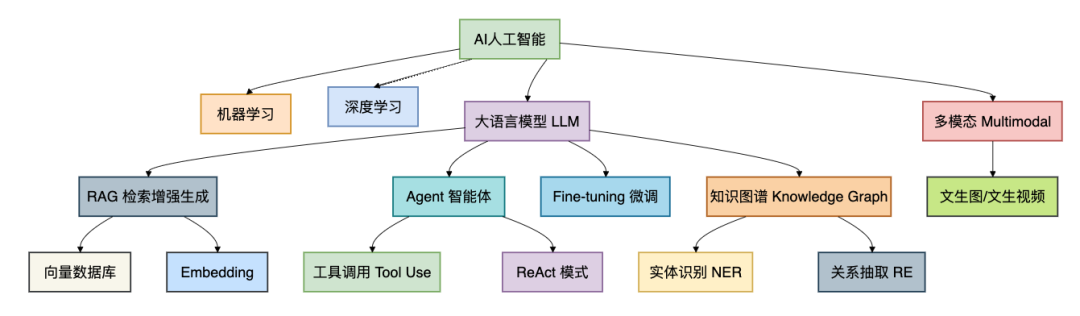
这张图清晰地展示了从宏观的AI人工智能,到具体的机器学习、深度学习,再到当下热门的大语言模型(LLM)和多模态(Multimodal)的层次关系。更重要的是,它揭示了LLM生态下的关键技术栈,如RAG、Agent、微调等,是如何协同工作的。下面,我们就顺着这张地图,逐一攻克每个“据点”。
二、核心概念深度拆解
2.1 机器学习 vs 深度学习
一句话解释:机器学习是让计算机从数据中“学习规律”,深度学习是机器学习的一种,它模仿人脑的神经网络结构。
通俗理解:
- 机器学习:就像教孩子认识苹果——你给他看10个苹果的图片,并告诉他“红色、圆形的是苹果”,他总结出这条规律。
- 深度学习:你直接给孩子看10000张包含各种水果的图片,但不做任何标记。他大脑中的“神经网络”会自动学习,最终不仅能认出苹果,还能发现苹果和其他水果的细微区别。
代码示例(用Java的Weka库做简单机器学习):
// 机器学习示例:用决策树判断天气是否适合打网球
import weka.core.Instances;
import weka.classifiers.trees.J48;
public class MachineLearningDemo {
public static void main(String[] args) throws Exception {
// 训练数据:天气情况 -> 是否打网球
// Outlook, Temperature, Humidity, Windy, Play
String data = "@relation weather\n" +
"@attribute outlook {sunny,overcast,rainy}\n" +
"@attribute temperature real\n" +
"@attribute humidity real\n" +
"@attribute windy {TRUE,FALSE}\n" +
"@attribute play {yes,no}\n" +
"@data\n" +
"sunny,85,85,FALSE,no\n" +
"sunny,80,90,TRUE,no\n" +
"overcast,83,86,FALSE,yes\n" +
"rainy,70,96,FALSE,yes";
Instances instances = new Instances(new StringReader(data));
instances.setClassIndex(instances.numAttributes() - 1);
// 训练决策树模型
J48 tree = new J48();
tree.buildClassifier(instances);
System.out.println("决策树模型:" + tree);
// 模型可以预测:新的一天[rainy,68,80,TRUE] -> 会输出yes/no
}
}
使用场景:推荐系统、垃圾邮件过滤、股票预测。
优点:能自动从数据中发现规律,不需要人工编写复杂规则。
缺点:需要大量高质量数据,模型可能过拟合。
2.2 大语言模型(LLM)
一句话解释:一种通过海量文本训练出来的、能理解和生成人类语言的巨型神经网络。
通俗理解:LLM就像一个读过整个互联网书籍和文章的人,你问它任何话题,它都能基于学到的知识聊上几句。但它不了解你私人的、未公开的信息,因为那些不在它的“阅读清单”里。
常见的LLM:GPT-4、Claude、文心一言、通义千问、DeepSeek。
代码示例(调用OpenAI API):
// 使用OkHttp调用大模型API
import okhttp3.*;
public class LLMDemo {
public static void main(String[] args) throws Exception {
OkHttpClient client = new OkHttpClient();
String json = "{\n" +
" \"model\": \"gpt-3.5-turbo\",\n" +
" \"messages\": [{\"role\": \"user\", \"content\": \"什么是大语言模型?\"}]\n" +
"}";
Request request = new Request.Builder()
.url("https://api.openai.com/v1/chat/completions")
.header("Authorization", "Bearer YOUR_API_KEY")
.post(RequestBody.create(json, MediaType.parse("application/json")))
.build();
Response response = client.newCall(request).execute();
System.out.println(response.body().string());
}
}
使用场景:智能客服、内容生成、代码辅助、翻译。
优点:理解能力强,能处理各种自然语言任务。
缺点:会产生“幻觉”(编造事实),成本高,不掌握私有数据。
2.3 RAG(检索增强生成)
一句话解释:让LLM在回答问题前,先去你的知识库里“查资料”,再根据查到的资料进行回答。
通俗理解:LLM本身是个“学霸”,但只学过公共教材。RAG就是让他在考试前,先翻翻你的公司内部资料或行业报告,再用自己的话总结出来。这样他既能回答专业问题,又不会脱离事实基础“胡说八道”。
工作原理图:

代码示例(Spring AI Alibaba实现):
@Service
public class RAGService {
@Autowired
private VectorStore vectorStore; // 向量数据库,存公司文档
@Autowired
private ChatClient chatClient;
public String ask(String question) {
// 1. 检索相关文档
List<Document> docs = vectorStore.similaritySearch(
SearchRequest.query(question).withTopK(3)
);
// 2. 把文档内容拼成上下文
String context = docs.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n"));
// 3. 让LLM基于上下文回答
return chatClient.prompt()
.system("请基于以下资料回答:" + context)
.user(question)
.call()
.content();
}
}
使用场景:企业知识库问答、智能客服、法律条文查询。
优点:答案可溯源、知识实时更新、防止幻觉。
缺点:多了一步检索,延迟增加;检索质量决定答案质量。
2.4 Agent(智能体)
一句话解释:一个能自主规划任务、调用工具、执行操作的AI程序。
通俗理解:普通LLM是“顾问”——你问它怎么办,它给你建议。Agent是“员工”——你给它一个目标(比如“订一张明天去上海的机票”),它会自己分析、决定步骤(查航班、比价、填写信息),并调用工具完成操作。
Agent的思考-行动循环(ReAct模式):

代码示例(使用Spring AI Alibaba的ReactAgent):
// 定义一个工具:查询天气
@Component
public class WeatherTool {
@Tool(description = "查询指定城市的天气")
public String getWeather(@P("城市名") String city) {
// 模拟调用天气API
return city + "今天晴天,25°C";
}
}
// 创建Agent
ReactAgent agent = ReactAgent.builder()
.name("助手")
.model(chatModel)
.tools(new WeatherTool()) // 给Agent配工具
.build();
// 用户只需说目标,Agent自己决定用哪个工具
String result = agent.call("我想知道北京今天能不能穿短袖?");
// Agent会:思考 → 调用天气工具 → 拿到天气 → 给出穿衣建议
使用场景:自动化客服、代码自动修复、行程规划、数据报表生成。
优点:能自主完成复杂任务,减少人工介入。
缺点:Token消耗大,可能陷入死循环,需要精心设计。
2.5 知识图谱(Knowledge Graph)
一句话解释:用“实体-关系-实体”的三元组形式,把知识连接成一张网。
通俗理解:传统的知识库是一堆文档(像一堆散落的书),知识图谱是一张“关系地图”(像地铁线路图)。你能沿着关系线从“高血压”走到“布洛芬”,再到“禁忌”,从而推理出“高血压患者不能吃布洛芬”。
三元组示例:
- (高血压, 症状, 头晕)
- (高血压, 禁用药物, 布洛芬)
- (布洛芬, 属于, NSAID类药物)
代码示例(使用Jena构建RDF知识图谱):
import org.apache.jena.rdf.model.*;
import org.apache.jena.vocabulary.RDF;
public class KnowledgeGraphDemo {
public static void main(String[] args) {
// 创建空模型
Model model = ModelFactory.createDefaultModel();
// 定义实体和关系(URI)
String ns = "http://example.com/medical/";
Resource hypertension = model.createResource(ns + "Hypertension");
Resource ibuprofen = model.createResource(ns + "Ibuprofen");
Property contraindicated = model.createProperty(ns + "contraindicated");
// 添加三元组:高血压 禁忌 布洛芬
model.add(hypertension, contraindicated, ibuprofen);
// 查询:高血压禁忌什么药物?
StmtIterator stmts = model.listStatements(hypertension, contraindicated, (RDFNode) null);
while (stmts.hasNext()) {
Statement stmt = stmts.next();
System.out.println("禁忌药物:" + stmt.getObject());
}
}
}
使用场景:医疗诊断辅助、反欺诈(挖掘资金关系网)、智能推荐。
优点:支持多跳推理,关系清晰,可解释性强。
缺点:构建成本高,需要领域专家参与。
2.6 多模态(Multimodal)
一句话解释:同时处理文本、图像、音频、视频等多种类型的数据。
通俗理解:以前的AI模型往往是“单线程”的,只能“看文字”或“看图片”。多模态AI则像人一样,具备综合感知能力。你可以给它一张风景图,让它“写一首诗”;也可以给它一段文字描述,让它“生成一张匹配的图片”。
代码示例(调用多模态模型API):
// 使用通义千问的多模态能力
public class MultimodalDemo {
public static void main(String[] args) {
String prompt = "描述这张图片的内容";
String imageUrl = "https://example.com/cat.jpg";
// 调用DashScope API(通义千问)
// 实际请求需要构造JSON,包含image和text
// 示例省略HTTP细节
}
}
使用场景:自动驾驶(图像+雷达)、视频理解、图文生成、语音助手。
优点:更接近人类的感知方式,应用场景更广。
缺点:模型更大、计算成本更高、训练数据更难获取。
2.7 微调(Fine-tuning)
一句话解释:在预训练好的大模型基础上,用少量特定领域的数据继续训练,让模型适应你的业务场景。
通俗理解:大模型像一个读过万卷书的通才,什么都懂一点,但不够专精。微调就像送这个通才去参加某个行业的“岗前培训”——给他看你们公司的产品手册、客服日志,让他变成你们业务领域的专家。
代码示例(伪代码示意):
// 微调通常需要Python环境,Java可通过HTTP调用微调服务
// 以下为伪代码示意微调请求
POST /v1/fine-tune
{
"model": "gpt-3.5-turbo",
"training_data": "company_qa.jsonl",
"epochs": 3,
"learning_rate": 0.00002
}
使用场景:定制客服机器人、特定领域问答、代码生成模型适配公司代码风格。
优点:让模型更懂你的业务,回答更精准。
缺点:需要一定量的标注数据,训练成本较高(比RAG贵)。
2.8 向量数据库与Embedding
2.8.1 Embedding(嵌入)
一句话解释:把文字、图片等转换成一组数字(向量),让计算机能计算“相似度”。
通俗理解:想象把“苹果”、“香蕉”、“汽车”这三个词放到一个多维坐标系里,“苹果”和“香蕉”因为都是水果,它们的向量距离很近;“苹果”和“汽车”距离则很远。Embedding就是自动计算出这个“语义坐标”的过程。
代码示例(调用Embedding API):
// 调用OpenAI的Embedding API
String text = "人工智能";
Request request = new Request.Builder()
.url("https://api.openai.com/v1/embeddings")
.post(RequestBody.create("{\"model\":\"text-embedding-ada-002\",\"input\":\""+text+"\"}", JSON))
.build();
// 返回的embedding是一个float数组,如[0.012, -0.345, ...]
2.8.2 向量数据库
一句话解释:专门存储和检索向量的数据库,核心功能是“给定一个向量,快速找出最相似的K个向量”。
通俗理解:想象你有一个巨大的仓库,里面每件物品都有其独特的“坐标”(即Embedding向量)。向量数据库能根据你手里一件物品的坐标,闪电般地找出仓库里和它最相似的几件物品。RAG中的“查资料”就是靠它完成的。
常用向量数据库:Milvus、Qdrant、pgvector、Chroma。你可以在云栈社区的开源实战板块找到这些项目的详细分析和实践指南。
代码示例(使用pgvector):
CREATE TABLE documents (id SERIAL, embedding VECTOR(768));
CREATE INDEX ON documents USING ivfflat (embedding vector_cosine_ops);
SELECT * FROM documents ORDER BY embedding <=> '[0.1,0.2,...]' LIMIT 5;
使用场景:RAG、推荐系统、图像相似度搜索。
优点:检索速度快(毫秒级),支持海量数据。
缺点:需要额外组件,不如传统数据库简单。
一句话解释:让Agent能够调用外部函数或API,执行实际操作。
通俗理解:Agent光会“思考”不行,还得会“动手”。工具调用就是给它配的“手”和“工具箱”——可以是查询数据库的函数、发送邮件的API、控制智能家居的接口。例如,用户说“帮我查一下上个月的销售额并总结成报告”,Agent就会依次调用“查询数据库”工具和“生成报告”工具。
代码示例:
@Tool(description = "发送邮件")
public String sendEmail(@P("收件人") String to, @P("主题") String subject, @P("内容") String body) {
// 实际调用邮件发送服务
emailService.send(to, subject, body);
return "邮件已发送";
}
优点:极大扩展Agent能力,让AI从“动口”变成“动手”。
缺点:需要严格的安全控制,防止恶意或错误调用。
2.10 ReAct模式
一句话解释:Agent的“思考(Reason)-行动(Act)-观察(Observe)”循环,让AI能像人一样边想边做,动态调整计划。
通俗理解:就像厨师做菜:先看菜谱想步骤(思考),然后动手切菜(行动),看看菜切得怎么样(观察),如果太大块就再切几刀,接着进行下一步。这个循环直到菜做完为止。
代码示例(伪代码展示ReAct循环):
while (!taskCompleted) {
// 思考
String thought = llm.think(goal, history);
// 决定行动(如调用工具)
String action = llm.decideAction(thought);
// 执行行动
String observation = execute(action);
// 记录结果
history.add(thought, action, observation);
}
优点:让Agent能灵活应对变化,自动调整计划。
缺点:可能陷入无限循环,需要设置最大迭代次数。
2.11 实体识别(NER)与关系抽取(RE)
2.11.1 实体识别(Named Entity Recognition, NER)
一句话解释:从文本中自动识别出人名、地名、组织名、时间、货币等关键信息实体。
通俗理解:给一段新闻,NER就像用不同颜色的荧光笔,自动把“马斯克”(人名)、“特斯拉”(组织名)、“2023年”(时间)标记出来。
代码示例(使用Stanford CoreNLP Java库):
import edu.stanford.nlp.pipeline.*;
import edu.stanford.nlp.ling.CoreAnnotations;
Properties props = new Properties();
props.setProperty("annotators", "tokenize,ssplit,pos,lemma,ner");
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
String text = "张三在北京的阿里巴巴工作";
CoreDocument doc = new CoreDocument(text);
pipeline.annotate(doc);
for (CoreEntityMention em : doc.entityMentions()) {
System.out.println(em.text() + " -> " + em.entityType());
}
// 输出:张三 -> PERSON,北京 -> LOCATION,阿里巴巴 -> ORGANIZATION
一句话解释:从文本中抽取出实体之间的关系,比如“张三是阿里巴巴的员工”。
通俗理解:NER找到了“张三”和“阿里巴巴”这两个实体,RE则进一步判断出他们之间的关系是“雇佣/工作于”。
代码示例(伪代码):
// 输入两个实体,判断关系
String relation = reModel.predict("张三", "阿里巴巴");
System.out.println(relation); // "works_at"
使用场景:构建知识图谱、信息检索、智能问答。
优点:自动从非结构化文本中提取结构化知识。
缺点:准确率依赖模型,复杂关系难以抽取。
2.12 文生图/文生视频
一句话解释:根据文字描述生成对应的图片或视频内容。
通俗理解:你输入“一只戴着礼帽的柯基犬在巴黎街头喝咖啡,电影质感”,AI就能生成一张高度符合描述的逼真图片。代表模型:Stable Diffusion、DALL-E、Sora。
代码示例(调用API伪代码):
// 伪代码:发送POST请求生成图片
POST /generate
{
"prompt": "一只猫坐在月亮上,卡通风格",
"width": 512,
"height": 512
}
// 返回图片URL或base64
使用场景:创意设计、游戏素材生成、广告制作、短视频创作。
优点:极大降低视觉内容创作门槛。
缺点:可能生成不符合预期的内容,版权与伦理问题需注意。
三、AI术语关系总结表
| 术语 |
核心作用 |
输入 |
输出 |
典型应用 |
| LLM |
理解生成语言 |
文本 |
文本 |
聊天、写作 |
| RAG |
检索+生成 |
问题+知识库 |
有依据的答案 |
企业问答 |
| Agent |
自主执行任务 |
目标 |
行动结果 |
自动化 |
| 知识图谱 |
存储关系网络 |
结构化数据 |
推理路径 |
智能搜索 |
| 多模态 |
跨数据类型理解 |
文本+图像+音频 |
综合理解 |
自动驾驶 |
| Fine-tuning |
领域适配 |
小规模标注数据 |
定制模型 |
垂直领域AI |
| Embedding |
语义向量化 |
文本/图像 |
向量数组 |
相似度计算 |
| 向量数据库 |
向量存储与检索 |
向量 |
相似向量 |
RAG、推荐 |
| 工具调用 |
执行外部操作 |
函数参数 |
执行结果 |
Agent行动 |
| ReAct |
思考-行动循环 |
任务目标 |
完成状态 |
智能体决策 |
| NER |
实体识别 |
文本 |
实体标签 |
信息抽取 |
| RE |
关系抽取 |
文本+实体 |
关系类型 |
知识图谱构建 |
| 文生图 |
生成图像 |
文本描述 |
图片 |
创意设计 |
四、如何组合使用这些技术?
在实际项目中,这些技术很少单独使用,而是像乐高积木一样组合在一起,形成强大的解决方案。一个智能体(Agent)往往是调度的核心。
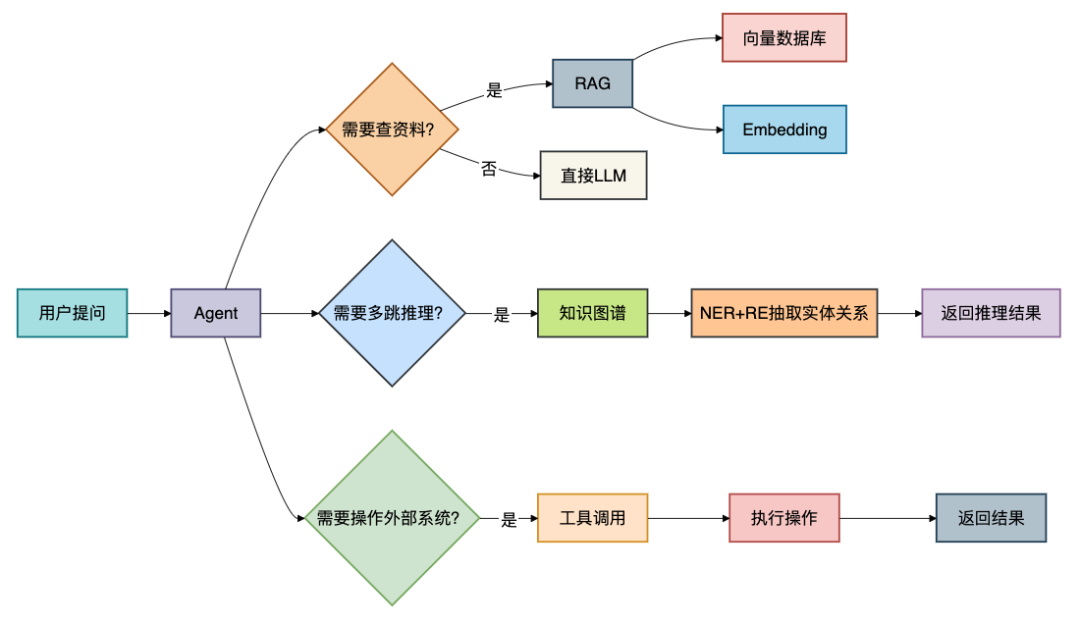
如上图所示,当用户提出一个问题时,智能体会进行判断和决策:
- 需要查资料? → 启用RAG流程,查询向量数据库。
- 需要进行多跳推理? → 查询知识图谱,可能用到NER和RE。
- 需要操作外部系统? → 进行工具调用。
- 如果都不需要,则直接由LLM回答。
经典组合案例:
- 企业智能助手 = Agent(任务调度与规划)+ RAG(查询内部文档/知识库)+ LLM(生成友好回答)+ 工具调用(创建工单、查询CRM)。
- 医疗问诊系统 = 知识图谱(疾病-症状-药品关系网)+ NER(识别病历中的实体)+ RE(抽取症状与疾病关系)+ LLM(生成问诊对话与建议)。
- 智能客服 = RAG(快速检索FAQ和产品文档)+ Agent(处理多轮复杂对话)+ 工具调用(查询订单物流、执行退款操作)。
五、总结
通过这张“AI知识图谱”,我们得以看清这些看似孤立的术语如何构成一个协同工作的技术生态:
- LLM是“大脑”,负责最核心的理解与生成能力。
- RAG是“外挂记忆”,让大脑在回答前能快速查阅海量、最新的外部知识。
- Agent是“肢体与代理”,让大脑具备规划和执行复杂任务的能力。
- 知识图谱是“结构化记忆”,存储实体间的关系,支持深度推理。
- 多模态是“多元感官”,让AI能看、能听,理解更丰富的世界。
- Embedding与向量数据库是连接非结构化信息与机器理解的“桥梁”,是语义搜索的基石。
- Fine-tuning、工具调用、ReAct、NER/RE 等则是让这个系统更专业、更强大、更自动化的关键“技能包”。
希望这份全景解析能帮助你拨开迷雾,建立起对AI技术栈的宏观认知。理解这些概念之间的关系,是灵活运用它们解决实际问题的第一步。如果你想深入探讨某个具体技术或寻找实战项目灵感,欢迎到云栈社区的人工智能板块与其他开发者交流。
 发表于 2026-4-20 07:49:08
|
查看: 200|
回复: 0
发表于 2026-4-20 07:49:08
|
查看: 200|
回复: 0
