很多朋友(无论是新手还是老鸟)遇到Linux系统变慢时,第一反应往往是“重启试试”或者“杀进程”。在Windows上或许还能靠任务管理器猜个大概,但面对黑乎乎的命令行界面,很多人只能干瞪眼,最后系统卡成幻灯片。别慌!今天我将分享一套系统化诊断+修复流程,从全局视图到精确定位,再到实际优化,全程使用免费的原生工具搞定。照着做,很快就能揪出性能问题的元凶,让你的服务器、桌面或工作站恢复流畅。
这套方法经过了生产环境的无数次验证,从个人Ubuntu桌面到企业级CentOS服务器,都曾用它解决过棘手的问题。

第一步:全局一览,瞬间看懂系统“健康报告”——htop登场
Linux变慢,从来不是“玄学”,而是资源被某个“隐形杀手”消耗殆尽。别急着 kill,首先需要获取系统全局视图。经典的 top 命令过于简陋,我强烈推荐直接使用 htop——它是Linux进程监控领域的“法拉利”,交互式、彩色、支持鼠标操作,比 top 好用得多。
安装非常简单(大多数发行版都有):
- Ubuntu/Debian:
sudo apt install htop
- CentOS/RHEL/Fedora:
sudo dnf install htop 或 sudo yum install htop
- Arch:
sudo pacman -S htop
安装完成后,在终端直接输入 htop 并回车,一个彩色的仪表盘立刻展现在眼前。界面主要分为上下两部分:
上半部分是资源彩条图:
- CPU:每个核心独立显示,用不同颜色区分用户态(绿色)、系统态(红色)、I/O等待(黄色)等状态。
- 内存(Mem):以进度条形式显示已用/总量,一眼就能判断内存是否即将耗尽。
- 交换分区(Swp):如果这里开始飙升,说明物理内存严重不足,系统正在疯狂进行换页操作,此时系统会“卡成狗”。
下半部分是进程实时列表:
- 自动按CPU或内存使用率排序(可按F6键切换排序依据)。
- 支持上下滚动、左右移动以查看完整的命令行。
- 快捷键设计非常人性化:F9杀进程、F4过滤、F5树状视图、F3搜索。
我曾帮一位朋友排查Ubuntu桌面卡顿问题。打开htop一看,所有CPU核心的彩条都显示为红色,负载平均值(Load Average)高达8.5(而他机器只有4个物理核心),同时内存使用率才60%。这立刻表明问题属于CPU-bound(计算密集型)。再看进程列表,排在最前面的一个Node.js爬虫脚本正在疯狂执行循环——直接按F9将其结束,系统瞬间流畅。
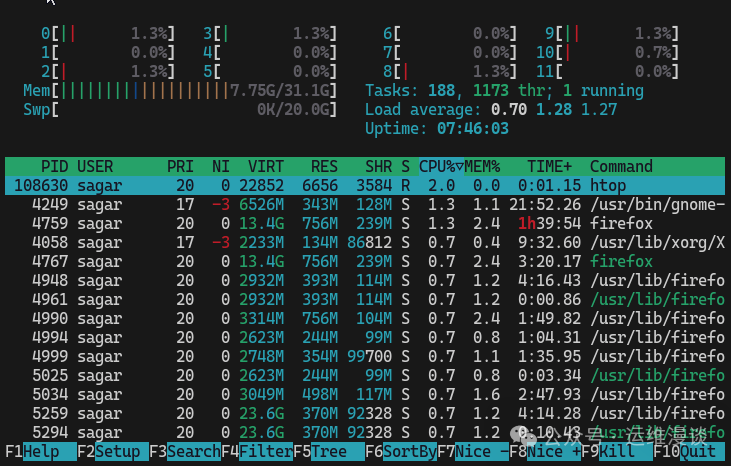
为什么htop如此强大? 它将 top、ps aux、free -h、uptime 等多个命令的信息整合到了一个界面中,并实时更新(默认每2秒刷新一次)。新手无需记忆一堆命令,老手还能自定义颜色和显示的列。
小贴士:按下F2进入Setup,可以开启“树状视图”(Tree View),直观展示父子进程关系;也可以按CPU%或MEM%排序,快速锁定资源“消耗大户”。建议将htop设为常用别名,可以把 alias htop='htop' 加到 ~/.bashrc 文件里。
使用htop获取全局视图后,你就不会再“盲目重启”了——它能明确告诉你“问题出在哪儿”,而不是让你感觉“哪儿都可能有问题”。许多刚开始学习 Linux运维 的朋友反馈,用过一次就离不开了,从此告别“卡顿焦虑”。
第二步:精准锁定瓶颈,4大子系统一网打尽
有了htop提供的全局观,下一步是识别具体的性能瓶颈。Linux性能下降,99%的根源在于以下四个地方:CPU、内存、磁盘I/O、网络。不要凭感觉猜测,让数据说话!
常见症状对照表(非常实用,建议截图保存):
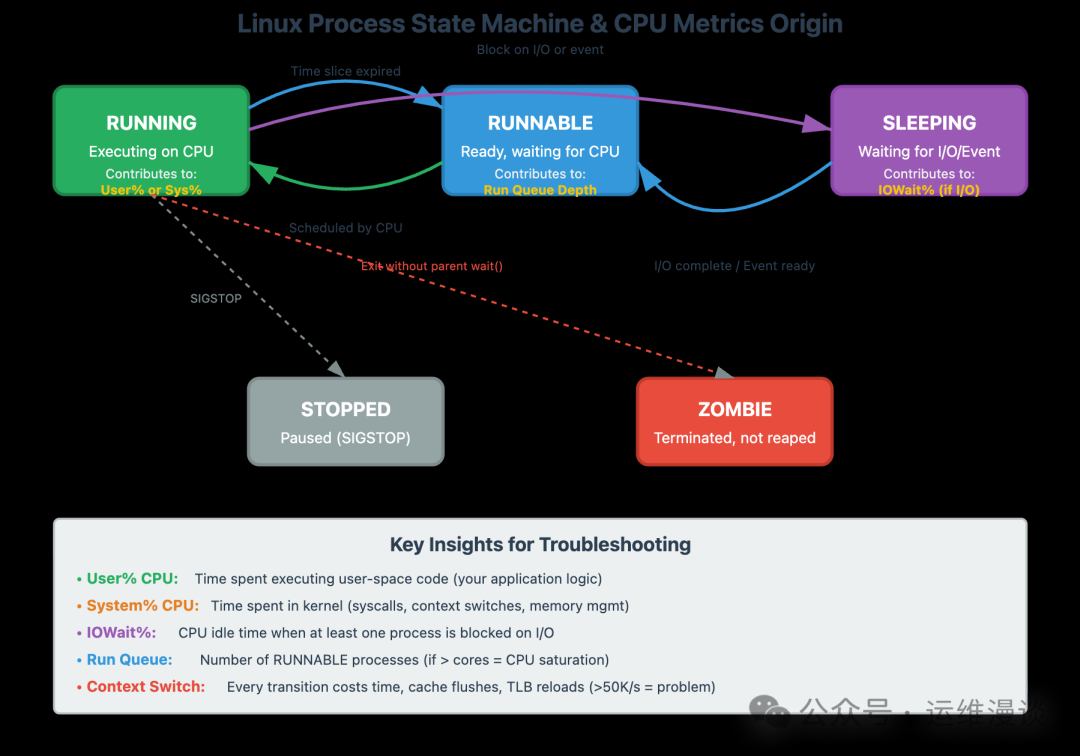
- CPU-bound:所有CPU核心占用率接近100%,负载平均值远超CPU物理核心数,CPU时间大部分消耗在User%或Sys%,空闲时间(Idle%)极少。
- Memory-bound:物理内存即将用满,Swap使用量开始飙升(出现thrashing现象),磁盘指示灯狂闪,系统响应极慢甚至“假死”。
- Disk I/O-bound(最常见的误判):CPU利用率低、内存充足,但系统“反应迟钝”。这时需要关注 Load Average 和 %wa(I/O等待) ——如果Load Average > CPU核心数,且%wa很高,那一定是磁盘I/O遇到了瓶颈。
- Network-bound:网络带宽被打满、丢包率高,表现为网页加载缓慢、SSH连接卡顿。
如何确认?htop上半部分的资源图已经给出了初步线索,再配合 uptime 命令查看1、5、15分钟的负载平均值(理想情况下,负载应接近或小于CPU核心数)。如果htop显示%wa(黄色部分)很高,基本可以锁定是磁盘瓶颈。
我的一位粉丝,其家用NAS(运行Rocky Linux)突然变得像蜗牛一样慢。htop显示CPU占用率只有20%,内存也充足,但Load Average高达12+,%wa更是达到了70%。他起初以为是CPU不够用,实际上却是机械硬盘被下载工具和Docker日志疯狂写入,导致I/O队列拥塞。后面使用专项工具一查,问题立刻现形。
请记住:瓶颈诊断是区分业余与专业的分水岭。业余选手靠猜,重启了事;专业运维看数据,进行精准“手术”。接下来就是第三步——调用“特种兵”工具,深挖罪魁祸首。
第三步:特种工具出击,精确到进程级诊断
锁定问题大类之后,就该部署针对性的工具,将问题范围缩小到具体的进程PID和命令行。
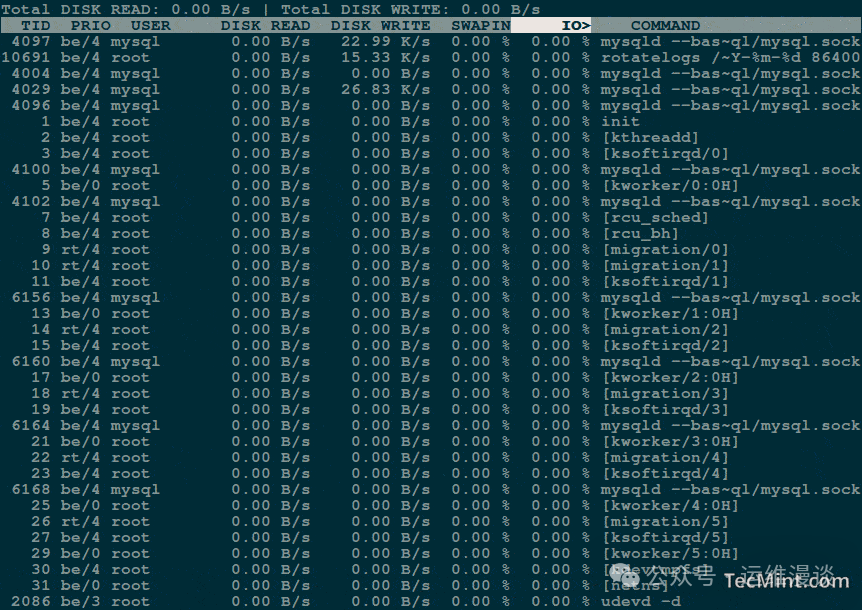
1. 磁盘I/O神器:iotop
如果是I/O瓶颈,iotop 就是你的“X光机”。安装命令:sudo apt install iotop(或使用 dnf/yum)。
以root权限运行 sudo iotop,其界面类似 top,但专门显示磁盘读写活动。它会实时展示每个进程的DISK READ/WRITE速度,单位是KB/s或MB/s。
我常用它来抓捕“日志炸弹”:某个服务的debug日志没有正确配置轮转,正在疯狂写盘;或者备份脚本在半夜运行,把SSD的I/O带宽打满。
例如,一个MySQL服务器出现卡顿,运行 iotop 发现 mysqld 进程的写盘速度高达300MB/s,原来是慢查询日志未做轮转,文件已经膨胀到几十GB。结束并重启日志服务后,I/O速度立刻恢复正常。
2. 内存与历史趋势:vmstat
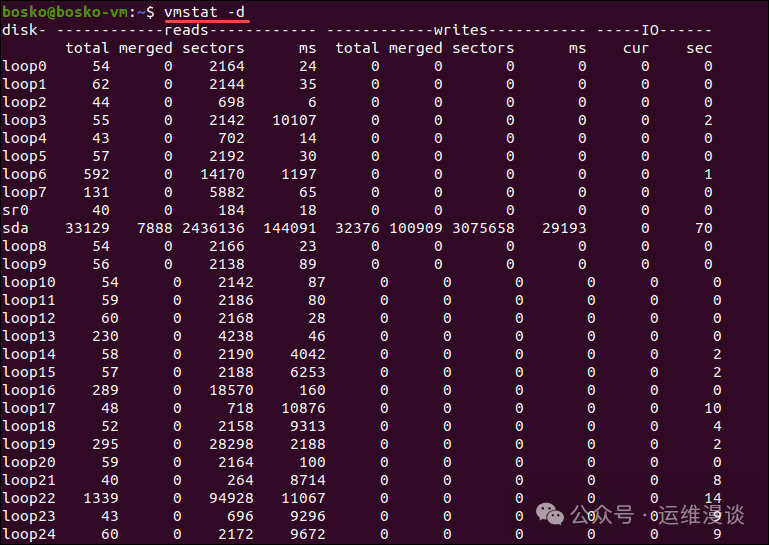
想要观察长时间的性能趋势,可以使用 vmstat。命令格式:vmstat 1 10(表示每1秒输出一次状态,共输出10次)。
关键列解读:
si/so(swap in/out):如果这两个值持续大于0,说明系统严重缺乏内存,正在发生频繁的交换(thrashing)。wa(CPU wait):这个值高,意味着CPU在等待I/O操作。free(空闲内存):需要结合缓存(buff/cache)来判断是真实的内存不足,还是缓存占用了大量内存造成的假象。
vmstat 还可以加上 -d 参数查看磁盘统计信息,或 -s 参数查看内存摘要。配合htop使用,基本能做到全方位无死角监控。
3. 网络瓶颈:iftop / nethogs
排查网络问题,可以使用 iftop(按网络接口显示实时流量,类似top)和 nethogs(按进程划分带宽占用)。安装简单,可以一眼看出是Chrome在疯狂下载视频,还是某个容器在内部造成DDoS。
4. 进阶组合拳(进阶玩家必备)
iostat -x 1:显示磁盘扩展统计信息,如果 %util 接近100%,说明I/O设备已经饱和。sar(来自sysstat包):记录和查看历史性能数据,sar -u 查看CPU历史,sar -d 查看磁盘历史,是完美的“事后诸葛亮”。perf top / strace -p PID:追踪系统调用和函数热点,深入挖掘某个进程卡顿的根本原因。free -h + cat /proc/meminfo:获取内存使用的详细细节。
所有这些工具都是免费的,由开源社区维护。请记住诊断顺序:htop → 瓶颈判断 → 专项工具 → 定位根因。整个流程通常不超过5分钟。
第四步:对症下药,实际部署修复方案
诊断完毕,就该动手修复了。针对不同的瓶颈,解决方案天差地别。
CPU瓶颈:
- 优化代码:将串行任务改为并行(或反之,根据场景)、增加缓存、升级算法。
- 限流:使用
nice/renice 降低进程优先级,或使用 cpulimit 工具限制其CPU占用率。
- 硬件升级或负载均衡(生产环境常用方案)。
内存瓶颈:
- 增加Swap空间(但不要过度依赖,频繁写入会影响SSD寿命):
sudo fallocate -l 4G /swapfile,然后依次执行 mkswap 和 swapon。
- 关闭不必要的服务:
systemctl disable --now xxx。
- 调整OOM Killer策略:在
/etc/sysctl.conf 中添加 vm.overcommit_memory=1(需谨慎使用)。
磁盘I/O瓶颈(最常见):
- 换用SSD! 机械硬盘的时代已经过去。
- 优化文件系统挂载选项:在
/etc/fstab 中为相应分区添加 noatime,nodiratime 选项。
- 配置日志轮转:合理设置logrotate,Docker容器可使用
--log-opt max-size=10m 限制日志大小。
- 数据库优化:为表添加索引、优化查询语句(MySQL可使用EXPLAIN分析)。
- 使用tmpfs(内存盘)存储临时文件:在
/etc/fstab 中添加 tmpfs /tmp tmpfs defaults,size=2G 0 0。
网络瓶颈:
- 限速:使用
tc(Traffic Control)工具或配置防火墙规则进行限速。
- 检查网卡驱动与配置:使用
ethtool 进行调优。
- 硬件升级:更换为更快的网卡或升级到10G/万兆网络。
修复完成后,再次运行htop验证效果。对于生产环境,建议编写脚本实现自动化监控,或者使用 prometheus + grafana 搭建仪表盘,实现长效监控。
预防胜于治疗:日常运维好习惯
- 监控先行:安装
htop + iotop + glances(全能仪表盘),或部署 netdata(提供浏览器可视化监控界面)。
- 定期维护:对SSD执行
fstrim、定期清理 /var/log 下的旧日志、谨慎地更新内核。
- 配置调优:在
/etc/sysctl.conf 中优化参数,如设置 vm.swappiness=10(减少Swap使用倾向)、增大 fs.file-max(文件句柄数上限)。
- 容器时代:使用Docker/K8s时,利用
docker stats + cadvisor 监控容器资源,避免单个容器拖垮宿主机。
- 备份与快照:使用Btrfs或ZFS文件系统的用户,可以利用快照功能快速回滚,非常省心。
新手常见误区:不要在生产环境随意使用 kill -9,优先尝试 systemctl restart;不要完全关闭Swap(可能导致OOM Killer直接杀掉关键进程);SSD不要写满,建议预留10%左右的空间。
Linux的强大之处就在于其透明与可控。不要再像使用Windows时那样依赖“重启大法”,熟练掌握htop、iotop、vmstat这套组合拳,你就能成为自己的运维专家。如果你在实践中遇到具体的卡顿场景,欢迎在技术社区分享你的htop截图或报错信息,与同行们一起交流探讨。
 发表于 2026-4-20 13:39:54
|
查看: 216|
回复: 0
发表于 2026-4-20 13:39:54
|
查看: 216|
回复: 0
