在云栈社区的技术讨论中,多模态模型的幻觉问题常被提及。传统模型要么输出流畅但缺乏细节的描述,要么能定位物体却无法理解深层含义。最近,阿里巴巴Logics团队发布的全新框架 Omni Parsing,试图打通这个困局——它覆盖文档、图像、音频、视频四大模态,将感知与认知解耦后通过结构化方式重新连接,最终输出标准化的 JSON,让每一条理解都有据可查。
三层次渐进式全模态解析
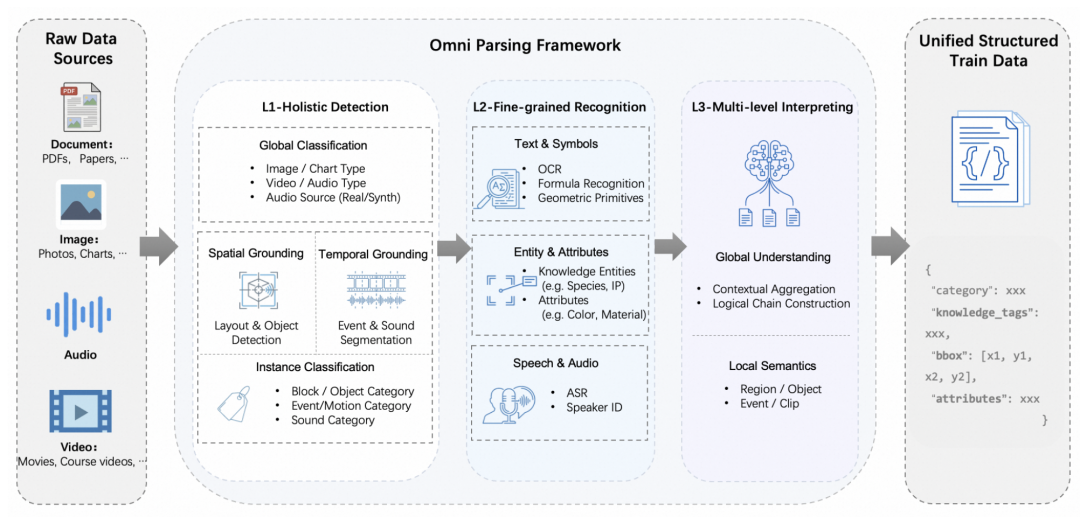
Omni Parsing 的核心思路不复杂:把“看”和“懂”分开,再让它们通过结构化数据彼此印证。整个过程分三层:
L1:整体检测(Holistic Detection)
模型先执行时空定位与粗粒度分类。对文档,它标记出文字块、表格、图表的边界框;对视频,则定位镜头切换的时间点以及关键物体的时空坐标。这一步建立了感知的几何基准。
L2:细粒度识别(Fine-grained Recognition)
定位后,进行符号化和属性提取。OCR/ASR 提取文字和语音内容;属性提取包括颜色、数量、类别;结构化知识则覆盖图表数据点和几何图形的点线关系。例如,一张包含奶酪与字母积木的静物图,模型能识别出“BASILILE DAY”的文本、蓝色奶酪的材质和葡萄的深紫色。


L3:多层次解释(Multi-level Interpreting)
基于前两层的结构化信息,模型进行推理:图表传达了哪种趋势?视频叙事逻辑是什么?几何图形中存在哪些关系?最终输出可追溯的推理链,并以统一 JSON 格式呈现,直接服务下游 RAG、QA 系统。
四大模态解析基准 OmniParsingBench
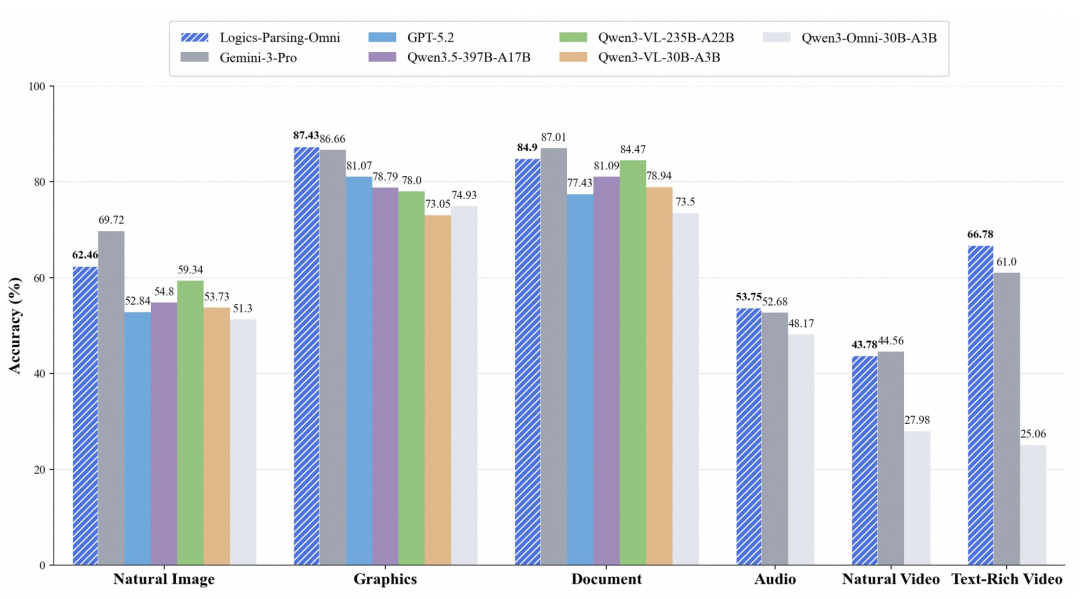
为了定量评估,团队开源了 OmniParsingBench 基准,覆盖文档、图像、音频、视频,重点考察三项能力:
- 细粒度定位:能否准确框出/定位关键元素
- 结构保真度:输出是否保留原布局逻辑关系
- 逻辑推理:基于结构化信息能否正确归纳和推理
以 Qwen3-Omni-30B 为基线模型,在图形认知(图表+几何)任务上做了消融实验。结果发现:纯描述微调反而有害(逻辑推理从73.97掉到68.04);而引入细粒度感知数据(图表HTML结构、几何坐标拓扑)后,逻辑推理飙升至90.87,数量关系达到96.08。
为什么这很重要?
这个框架最突出的价值在于:统一的全模态处理 + 标准化 JSON 输出。复杂文档(如财务报告、学术论文)中的图表、公式、插图,经过解析后可以直接对接 RAG 系统,实现“从文档到知识”的无缝转化。在教育场景中,它能将幻灯片切换、板书内容和语音精准对齐,回答“老师在第三分钟讲了哪个公式”这类可追溯问题。
感兴趣的可以查阅原论文和代码:
开源地址:https://github.com/alibaba/Logics-Parsing/tree/main/Logics-Parsing-Omni
|  发表于 2026-4-27 02:02:25
|
查看: 166|
回复: 0
发表于 2026-4-27 02:02:25
|
查看: 166|
回复: 0
