在人工智能、高性能计算与云数据中心快速崛起的推动下,传统存储体系正面临前所未有的挑战。处理器性能仍在指数级增长,但数据传输速度却始终难以跟上,由此形成的 带宽瓶颈,严重制约了整机系统性能。
HBM(高带宽内存)的崛起并非偶然,其直接原因就是传统内存带宽不够用了。它凭借 3D 堆叠封装与超宽总线接口技术,大幅提升了单位功耗下的数据传输带宽,如今已被视作突破存储性能极限的核心技术之一。
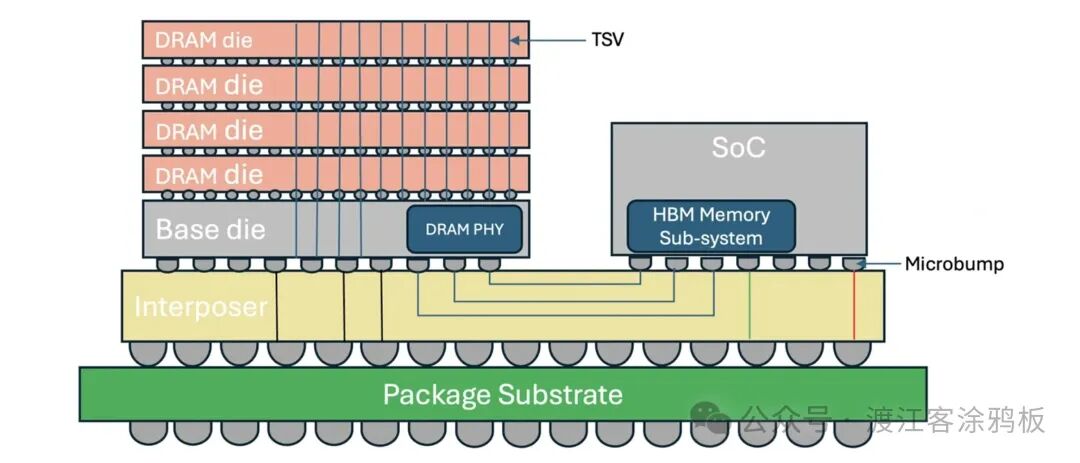
一、HBM 技术原理与架构
HBM 与传统 DDR 内存最大的区别,在于采用 3D TSV 硅通孔垂直互联 设计。多颗 DRAM 芯片垂直堆叠并通过硅通孔相连,再与逻辑芯片(通常为 GPU 或 AI 加速芯片)一同封装在硅中介层上。这种结构大幅缩短了信号传输路径,得以在更低功耗下实现更高传输速率。反观 DDR4、DDR5,仍沿用传统 PCB 并行布线方案,想要进一步提升带宽,就必须付出更高功耗与信号完整性的代价。
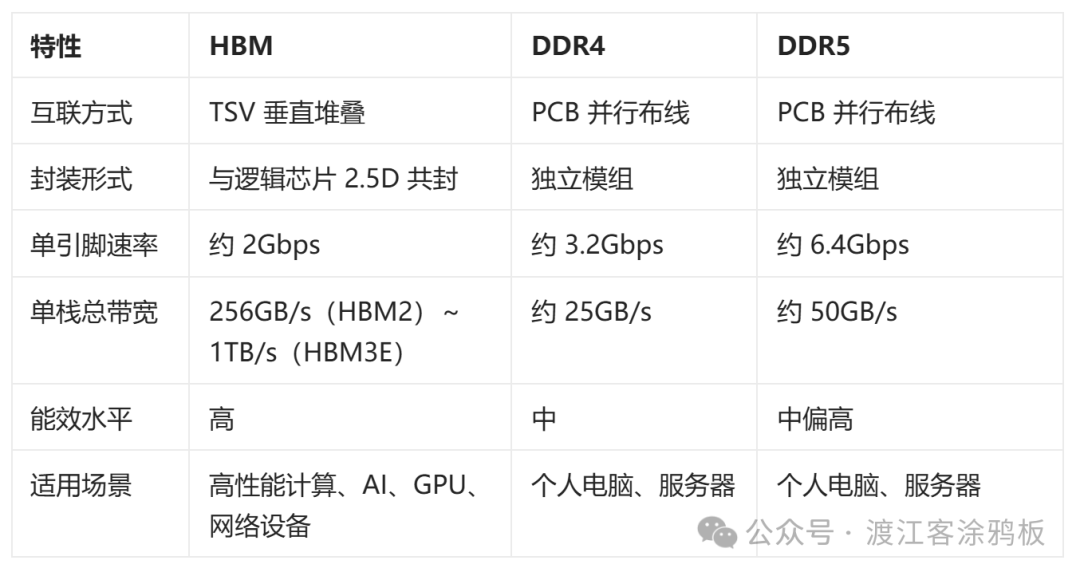
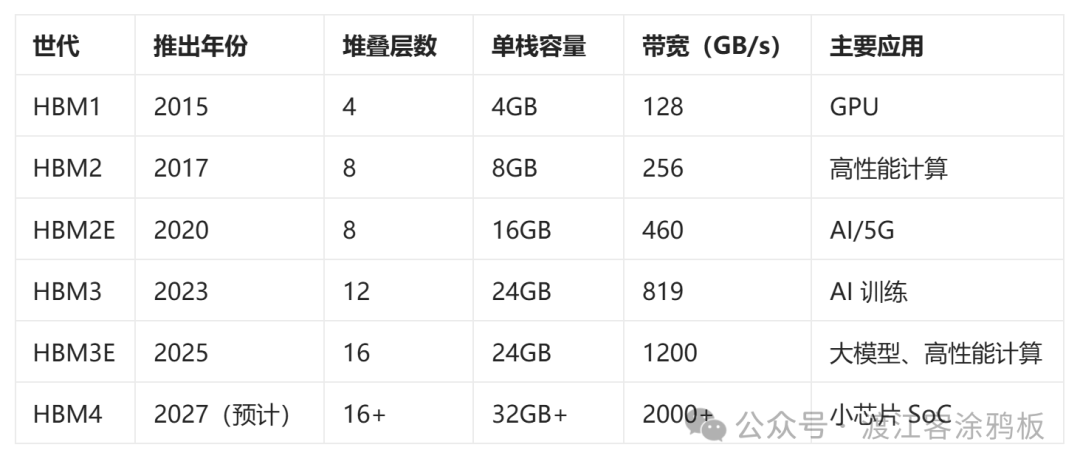
截至 2025 年,HBM 已迭代至 HBM3E,单栈容量最高 24GB,带宽可达 1.2TB/s。下一代 HBM4 预计将采用小芯片加主动中介层架构,集成度与散热效率将进一步提升。
二、HBM 的行业格局
HBM 行业格局呈现明显的寡头垄断特征,技术壁垒极高。制造难点集中在 3D 堆叠良率、封装精度、散热控制与中介层制造等环节,也因此形成了高度集中的全球市场格局,主要由三家存储大厂主导:

与此同时,日本与中国台湾地区的铠侠、南亚科、华邦电等企业仍处于研发阶段,商业化进度落后两到三代。国内的长鑫存储、长江存储已启动 HBM 前期项目,但受限于先进封装能力不足、设备依赖进口,短期内难以实现大规模量产。
这种 技术寡头格局 让头部企业拥有极强的定价权。2023 至 2025 年,英伟达 H100、H200 及 Blackwell 系列 GPU 引爆 HBM 需求,海力士利润创下历史新高,全球供应持续紧张。
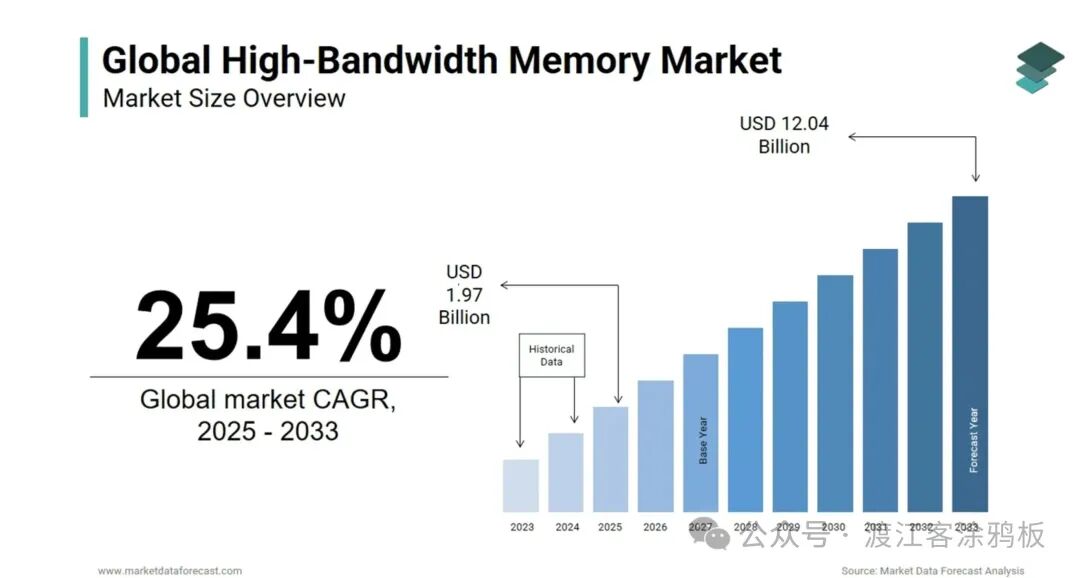
四、HBM 的市场动态
1. AI 训练成为核心增长引擎
随着生成式 AI 与大模型兴起,HBM 已成为 GPU 的标配组件。英伟达 H100 搭载 80GB HBM3,带宽达 3.35TB/s;新一代 Blackwell GPU 则采用 HBM3E,容量翻倍,总带宽最高 8TB/s。这意味着,2020 年至今,AI 训练所需存储带宽增长近十倍。HBM 性能直接决定 GPU 运行效率,已成为芯片竞争力的核心指标。
2. 价格暴涨,供应紧缺
AI 市场爆发式增长,推动 2024 至 2025 年 HBM 价格涨幅超 60%。海力士持续满产仍难以满足订单。由于 HBM 生产占用大量先进封装产能,部分 DDR5 产线转产 HBM,也进一步推高了通用存储价格。在 人工智能 算力需求井喷的背景下,这种紧俏局面短期内恐怕难以缓解。
3. 新玩家入局,产业链加速扩张
台积电、日月光、三星等先进封装厂商正扩产 CoWoS、InFO 产线;楷登、新思、科磊等 EDA 与检测设备企业也在针对性开发 3D DRAM 验证与检测工具,整个生态正快速成熟。
四、HBM 对传统存储市场的冲击
HBM 的崛起并非孤立事件,它正深刻重构整个存储生态,对 DDR、GDDR 市场产生深远影响。
1. DDR 转向中低端与通用服务器市场
HBM 主要适配高性能场景,消费级 PC 与基础服务器仍将沿用 DDR4/DDR5。但随着 AI 服务器成为需求增长主力,DDR 市场份额将持续收缩。据集邦咨询预测,2026 年数据中心 HBM 渗透率有望突破 35%,DDR4 将快速退出市场,DDR5 则进入成熟普及期。
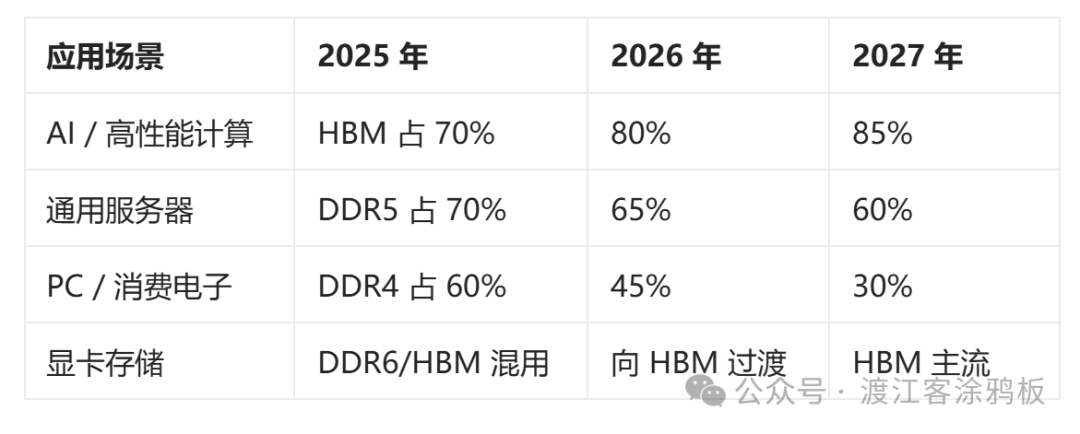
2. 传统存储厂商迎来二次转型
美光、三星等传统存储巨头纷纷调整战略:加大 HBM 研发与先进封装投入,同时将 DDR 定位为面向成本敏感市场的中低端产品。HBM 既成为新的增长引擎,也重塑了行业竞争格局。
五、未来展望
未来五年,HBM 将与小芯片架构深度融合。HBM4 预计 2026 至 2027 年面世,通过主动中介层实现超 2TB/s 带宽,能效再上台阶。
与此同时,英伟达、AMD、英特尔等芯片企业正探索将 HBM 与计算模块更深度集成,实现计算与存储一体化。这一趋势正在模糊存储、缓存与内存的边界,为“存算一体”的新型架构铺平道路。
六、存储革命的转折点
HBM 不只是一款新型存储产品,更是下一代计算时代的核心驱动力,标志着产业从“算力优先”转向“带宽优先”。在人工智能、自动驾驶、仿真模拟、云计算等领域,HBM 的应用范围将持续扩大,成为衡量性能的关键指标。但与此同时,高昂成本、复杂制造工艺与高度集中的供应链也带来新的风险,如何在性能与成本间取得平衡,仍是行业面临的最大挑战。
未来随着 HBM4、HBM5 相继问世,存储有望成为算力核心,而 HBM,将站在这场革命的最中心。
 发表于 2026-4-27 02:00:27
|
查看: 233|
回复: 0
发表于 2026-4-27 02:00:27
|
查看: 233|
回复: 0
