前言
公司数据库基础框架已运行多年,加之产品本身的特性,数据库操作的并发量并不高,因此除偶尔增加一些必要功能外,一直未对该框架的性能进行深入考量。近期,因一个临时项目需要频繁进行数据库操作,同事在压力测试过程中发现数据库调用的内存占用较高,便将此情况告知于我。
最近我正进行 vibe coding 的相关测试,收到同事反馈后未作过多考虑,当即按其建议完成修改并发布版本,同时通知同事在开发环境中升级并进行测试。同事测试后反馈可以正常运行,当时我并未太在意。
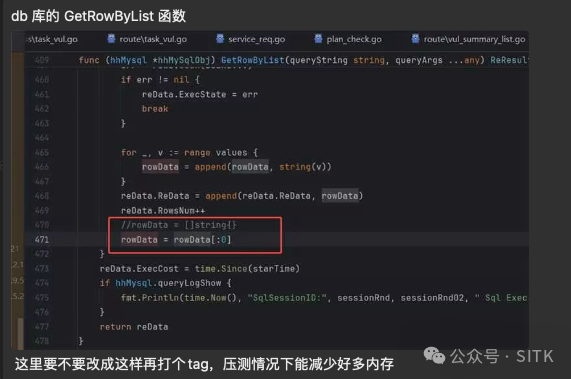
晚上回到家后,回想起此事,总觉得有些不妥。按照同事的建议,底层数据会被复用,但框架在处理每个 DB 请求时,每一行数据都应是全新的,不能复用。因此第二天一早到公司,我便立即开始补做前一日因疏忽未进行的测试,结果发现问题确实存在——该数据库函数最终返回的数据全部相同。于是,我立刻撤回已发布的标签版本,重新认真进行了测试与优化处理。
相关代码
原始运行代码
![Go 语言 GetRowByList01 函数源码截图,使用 []byte 扫描数据并 append 构建 rowData](https://static1.yunpan.plus/attachment/f419b4406739632a.webp)
同事建议代码
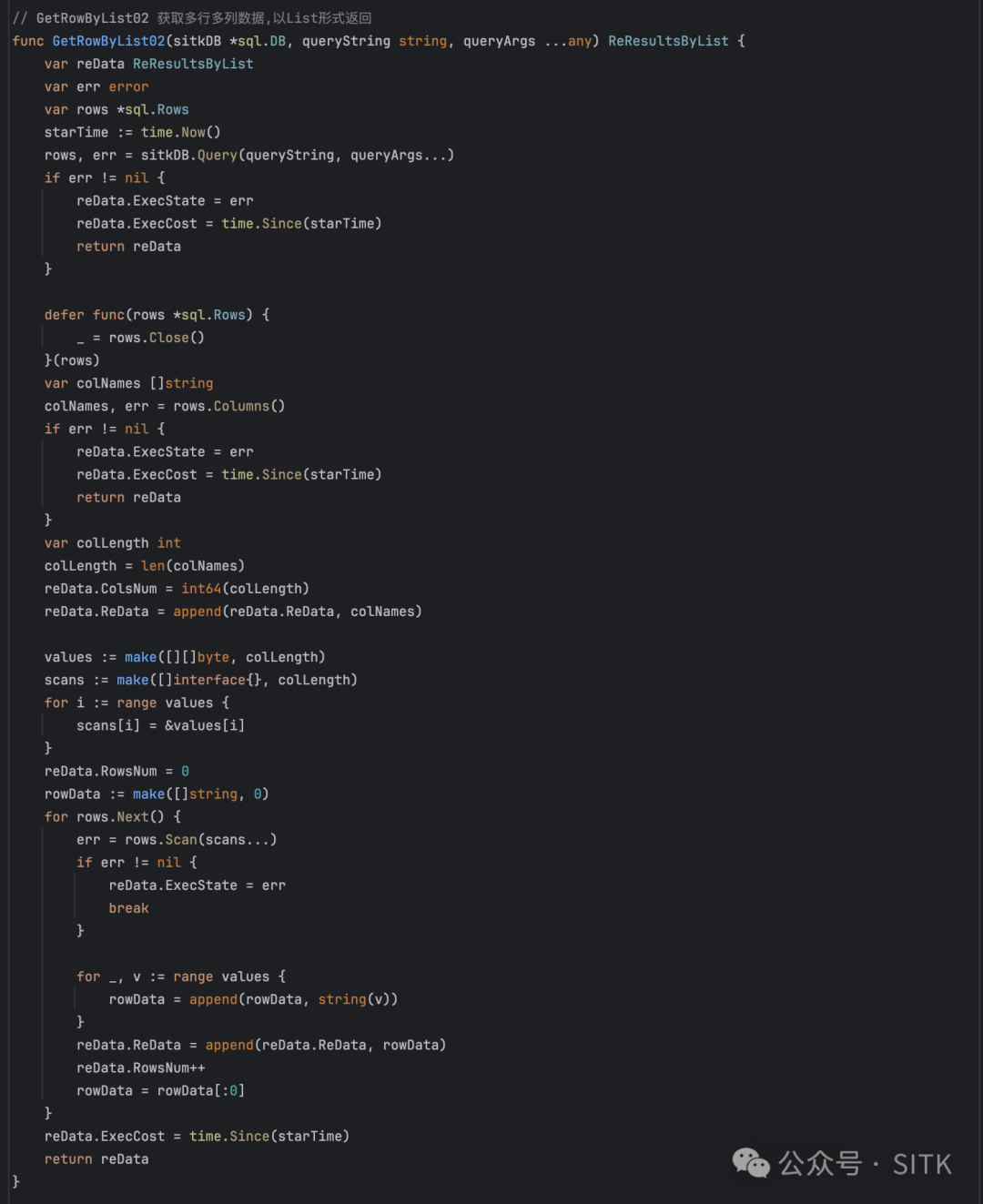
优化后的代码
验证测试
测试代码
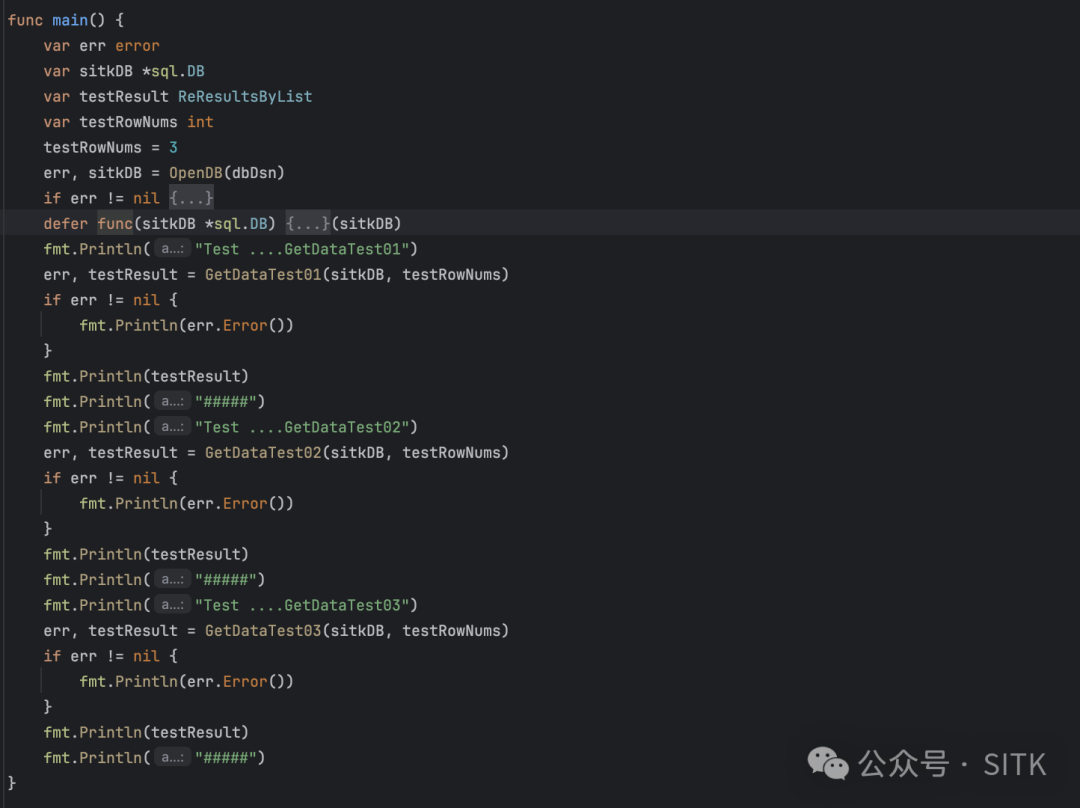
测试结果

我们发现 GetDataTest01、GetDataTest02、GetDataTest03 都按预期返回了三条数据,但 GetDataTest02 返回了三条一模一样的数据——因为同事建议的方案会导致底层数据共用。所以 GetDataTest02 的处理方案是错误、不可用的。通过与数据库直接对比,GetDataTest01 和 GetDataTest03 的数据与数据库的原始数据完全一致,符合预期。

性能测试
测试代码
性能测试结果
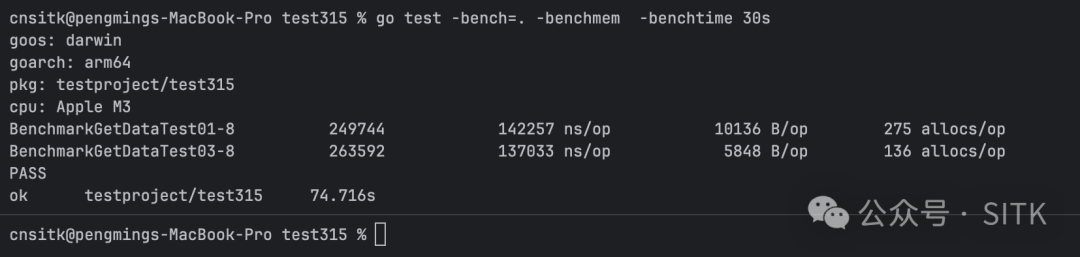
虽然耗时差异不算巨大,但内存分配次数从 275 次降到了 136 次,减少了整整一半!内存分配量也从 10136 字节降至 5848 字节,降幅超过 40%。
优化分析
数据类型选择:从 [][]byte 到 []string,避免不必要的数据转换
GetRowByList01 使用 [][]byte 作为中间存储,每行数据需要将 []byte 转换为 string。这个转换过程涉及内存分配和数据拷贝。
GetRowByList03 直接使用 []string,rows.Scan 直接将数据库值扫描进字符串,省去了类型转换的开销。
切片容量预分配,避免动态扩容
GetRowByList01 使用 rowData := make([]string, 0),初始容量为 0,每次 append 都可能触发切片扩容,导致多次内存重新分配。
GetRowByList03 使用 rowData := make([]string, colLength),直接分配了足够容量的切片,避免了动态扩容的开销。
数据复制方式,减少对象创建次数
GetRowByList01 使用 append 逐个添加元素,且每次循环都重新创建 rowData 为空切片。
GetRowByList03 使用索引赋值 rowData[tmpI] = values[tmpI],直接覆盖已分配的位置,减少了内存操作。
结论建议
6.1 几行简单的改动——少一次转换,少一次 append,少一次对象分配——就能够带来非常不错的内存优化收益。
6.2 Go 的 database/sql 包中,rows.Scan 可以接受多种类型的指针。[]byte 和 string 在底层表现不同,理解这些差异有助于我们做出更好的选择。如果你对 Go 语言底层实现感兴趣,不妨进一步探索 Go 内存管理机制。
6.3 一定要多测试、多验证,别偷懒,别偷懒。
6.4 如果字段类型复杂(如 NULL、JSON、时间类型),直接 scan 到 string 可能需要额外处理,性能有可能还会受到影响。
细节决定性能,而性能决定体验。当我们写出能够正常运行的代码时,不妨做一些 benchmark 测试,以发现性能的不足并启动优化。但当前很多程序员都开始 vibe coding 之后,还会有人关注这些吗?

 发表于 2026-4-27 17:58:34
|
查看: 158|
回复: 0
发表于 2026-4-27 17:58:34
|
查看: 158|
回复: 0
