原本预计在2026年春节上演的中国AI大戏,延迟到了五一假期前。这周五,DeepSeek V4千呼万唤始出来。同样在这周,Qwen、Kimi、小米、腾讯都不约而同拿出了自己最新的代表作。
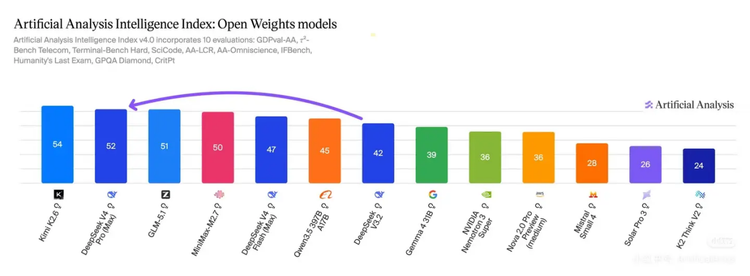
从Artificial Analysis最新放榜的开源模型智能指数看,开源模型的前几名已经都是中国模型。其中,TOP2都是这周发布的。他们也是这几天 OpenRouter 真实调用量上挤入全球TOP5的两家公司。
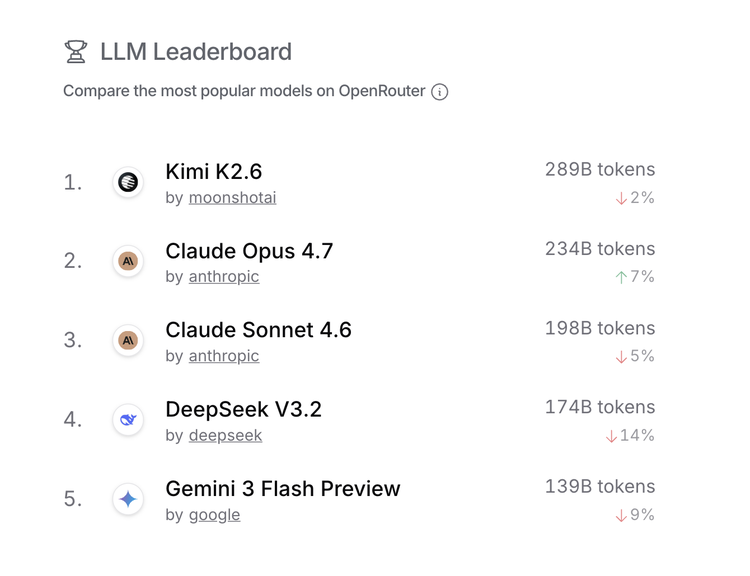
这已经不是DeepSeek和Kimi这么默契了。往回看看前面几次。2025年1月,DeepSeek R1和Kimi K1.5前后两个小时内发布,都把目标指向OpenAI o1。一个月后,DeepSeek NSA和Kimi MoBA几乎同时出现,都在改造Transformer最核心的注意力机制。2025年4月,Kimi的Kimina Prover Preview和DeepSeek-Prover-V2先后发布,都在向形式化数学推理和定理证明方向推进。时隔一年,现在,又一次,Kimi K2.6和DeepSeek V4在同一周先后发布,两个万亿参数的开源模型,前后脚摆到了桌面上。发力相同的技术方向,几乎同时到达同一个路口。这已经不像巧合了。
这次又撞了什么
先看这一轮各自拿出了什么。
DeepSeek V4是一个1.6万亿参数的MoE模型,49B激活参数,原生支持100万token上下文。它的核心叙事是效率革命,相比上一代V3.2,单token推理算力需求下降了73%,KV cache压缩到原来的十分之一。简单说,同样的硬件能处理多得多的请求,同样长度的文本花的钱少得多。与此同时,V4完成了对华为昇腾芯片的深度适配,从英伟达CUDA生态向华为CANN架构做了底层代码迁移,也让这一轮发布多了一层国产算力迁移的意味。
Kimi K2.6是一个万亿参数的MoE多模态模型,32B激活参数,256K上下文。它的核心叙事不是更大或更便宜,而是更持久。在测试中,K2.6可以不间断编码13小时,处理超过4000次工具调用,修改4000多行代码,完成一个接近性能极限的开源金融撮合引擎的深度重构。这不是普通的“代码能力提升”,而是在测试模型能不能从一次性回答,进入长时间、多工具、多Agent协作的工作状态。K2.6还引入了Agent集群架构,支持300个子Agent并行协作。月之暗面的RL基础设施团队已经用K2.6驱动的Agent连续自主运行了5天,负责监控、故障响应和系统运维。

它们总在同一个路口相遇,但开出去的方向并不一样。至少在这一轮,一个更像是在重写模型基础设施的成本结构,另一个更像是在验证模型能否进入更长周期的真实任务。方向不同,但在同一周发布这件事本身,已经足够让人截图发群了。但两家也有高度一致的选择:万亿参数的MoE架构、开源、继续相信Scaling Law。截至目前,它们也是中国仅有的两个已开源的万亿参数模型。
比撞车更有意思的事
多次撞车是一个好段子,但它背后有一个更值得注意的现象:两家的技术路线正在相互启发。
上一次,是Kimi K2借鉴了DeepSeek V3带火的MLA注意力机制。MLA是一种压缩注意力计算和KV缓存以提升效率的方案,DeepSeek V3让它成为中国开源模型技术栈里的显性选项。这一次,是DeepSeek V4把Muon优化器作为模型架构层的三大更新之一。Muon是一种二阶优化器,解决的是训练阶段参数更新的效率和稳定性问题,用来取代已经用了10年的Adam。Kimi是最早把Muon系优化器推到万亿参数级训练并系统公开经验的团队之一,杨植麟在GTC 2026演讲中称其可以带来2倍的token效率提升。而V4也跟进使用Muon优化器,用来提升收敛效率和训练稳定性。
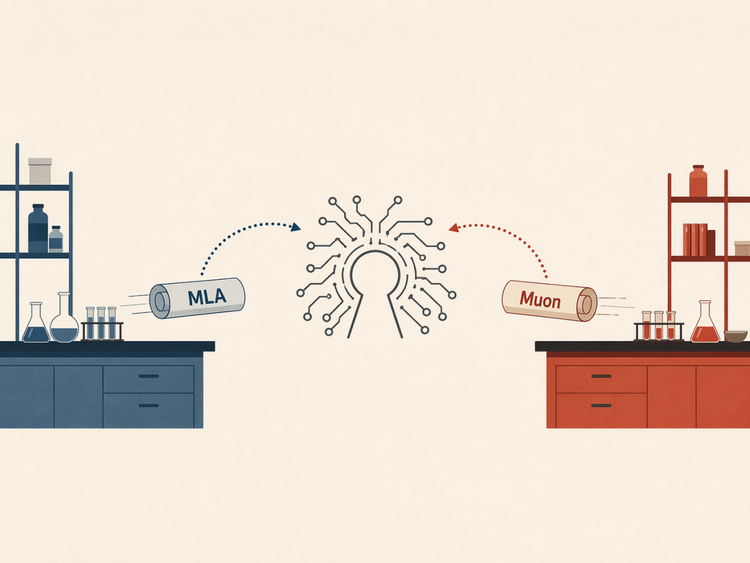
换句话说,MLA省的是推理时的钱,Muon省的是训练时的路。而这两条路,已经在两家之间来回走了一遍。这就让“撞车”不再只是发布时间上的巧合,而变成了技术栈层面的回声。更像是两家公司一边竞争,一边把对方探索过的技术思路变成自己下一轮实验的参考坐标。
这种相互启发还在继续延伸。在注意力机制上,DeepSeek探索的是稀疏注意力,Kimi下一代模型探索的是线性注意力,路径不同但要回答的问题一致,都是长上下文怎么不被全注意力的计算复杂度拖垮。在残差连接上,DeepSeek做mHC,Kimi做注意力残差,同样是不同方案指向同一个目标,让模型变深之后训练依然稳定。

这件事之所以值得说,是因为放在更大的行业背景里看,它其实是反常的。硅谷头部公司正在变得越来越封闭,OpenAI早已不再公开训练细节,Anthropic和Google的核心方法同样讳莫如深,社区只能靠猜测和拼凑来推断它们的技术路线。连在舞台上握手都不太可能了。

而在Kimi和DeepSeek之间,技术报告和开源代码的可见度让技术扩散的链条明显缩短了。多次撞车之所以能被看到、被讨论、被放在一起比较,前提恰恰是两家都选择了把东西摊在桌面上。中国开源模型的技术扩散速度,正在变得比过去快得多。 这可能才是频繁撞车真正说明的事情。
全球技术圈都在看它们撞车
这种“撞车”的叙事,最早当然是中文科技圈的发明。但海外开发者社区也在用自己的方式确认这件事。K2.6发布后,AI领域最有影响力的newsletter之一Latent Space直接把Kimi放进了“DeepSeek沉默期后中国开源模型实验室领跑者”的位置。几天后V4发布,海外开发者社区又立刻把V4、K2.6、GLM 5.1放到同一张表格里比较参数、价格、上下文长度和Agent能力。

英伟达GTC 2026上用来展示下一代芯片推理性能的中国模型,是这两家。
在海外开发者社区里,当人们讨论中国开源模型时,Kimi和DeepSeek的确越来越频繁地被放进同一张表里。
它们撞上的不是彼此
这也让DeepSeek和Kimi的关系变得有点微妙。它们当然是竞争对手,但在更大的模型生态里,又共同把中国开源模型推到了一个更难被忽视的位置。它们对闭源模型的压力,不只来自某一次benchmark,而来自成本、可部署性、开源权重和技术扩散速度这些更慢、更底层的变量。
所以,Kimi到底有没有在故意撞车DeepSeek?大概率没有。万亿参数的MoE要做,长上下文的注意力机制要改,训练效率的优化器要换,国产芯片的适配要啃,开源要开得真诚而不是做防御性姿态。这些不是“选项”,而是“必经之路”。两家公司都在认真地做底层技术,也都选择把关键进展放到公开语境里,于是就一次又一次地在同一个十字路口碰面。
不是它们太默契,是路太窄了。
至于下一次“撞车”,大概已经在路上了。如果没猜错的话,Kimi让大模型的文本和视觉能力齐头并进的技术方案,将启发更多中国开源纯文本模型长出“眼睛”,一起看到更远、更大的世界。
 发表于 2026-4-27 18:00:47
|
查看: 199|
回复: 0
发表于 2026-4-27 18:00:47
|
查看: 199|
回复: 0
