DeepSeek V4,千呼万唤始出来。
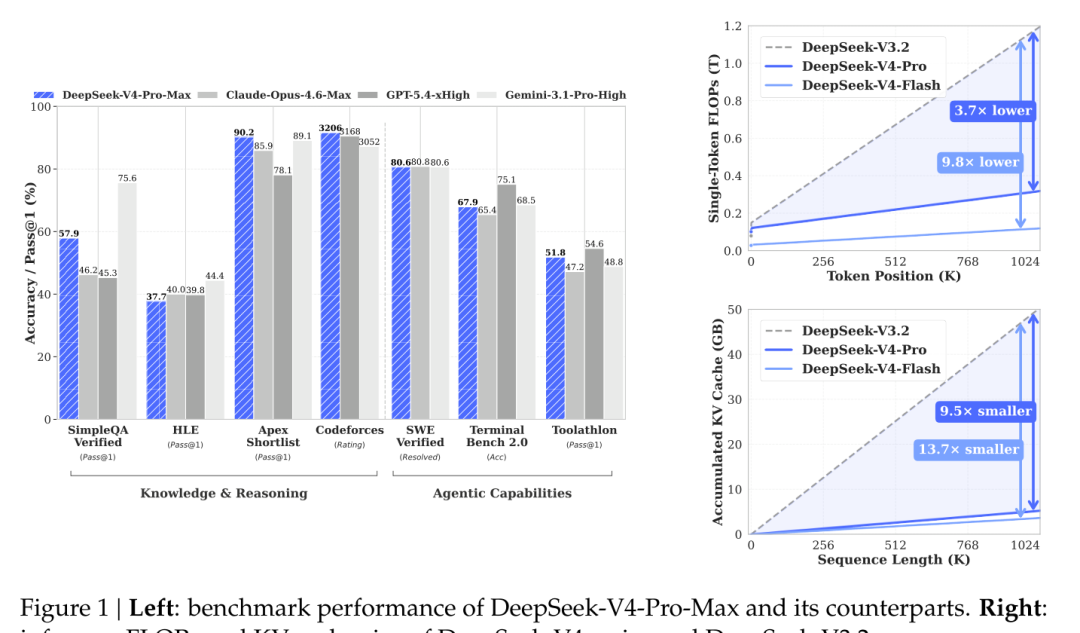
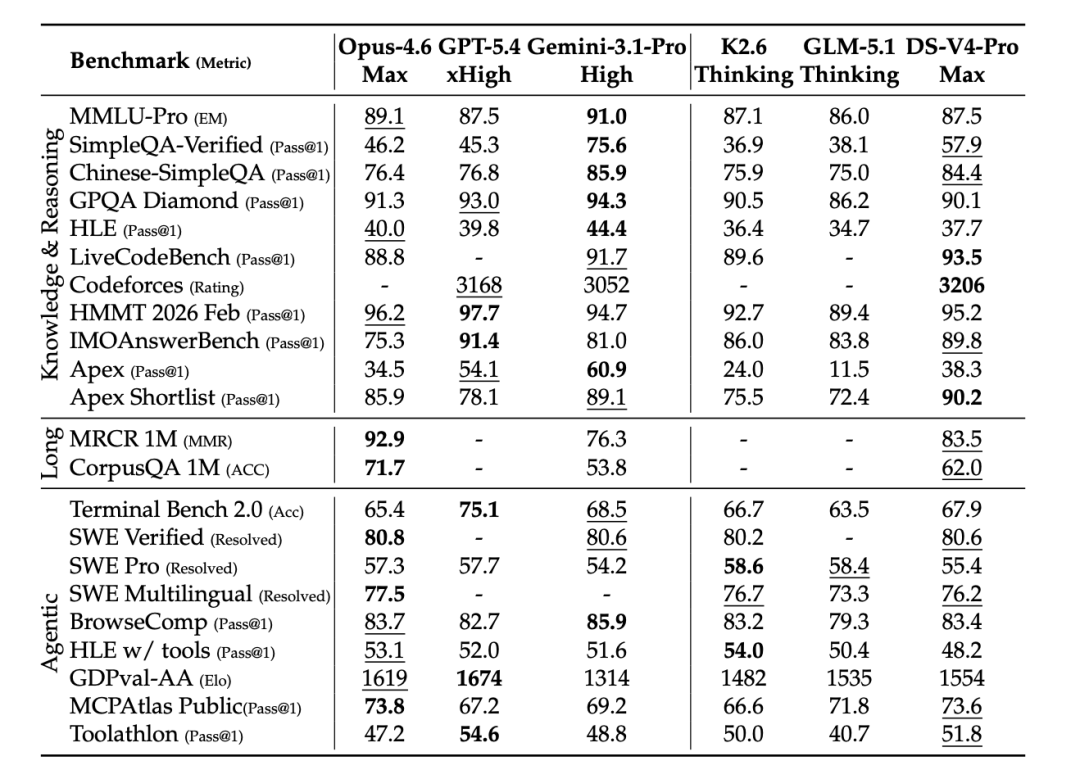
一年多的等待,终于等来了 DeepSeek 的全新模型。从 Benchmark 上看来,V4 的表现大概追平硅谷的上一代旗舰模型,但最近 Kimi 2.6、GLM 5.1 的整体表现都大概在这个水准之上,似乎惊喜并不大。在论文中 DeepSeek 团队也开诚布公地表示,DeepSeek-V4-Pro-Max 的表现小幅超越当前的领先开源模型,并高于 GPT-5.2 and Gemini-3.0-Pro,但仍然落后于 GPT-5.4 and Gemini-3.1-Pro,差距大概在三到六个月。
只看 Benchmark,原来曾经靠着 V3、R1 一枝独秀的 DeepSeek,似乎也突然泯然众人了。
一开始我觉得这是因为国内开源同行们追得太快,同时也是训练范式在这一年中强烈逐渐收敛后的必然。
第一个范式更新:折叠中的百万上下文
第一个范式级的更新是处理注意力压缩的 CSA/HCA。
它是 V4 最重要的一个技术革新,同时也是 DeepSeek 对 AI 发展下一个高地的判断。
对 DeepSeek 而言,长上下文,不再是一个简单的功能,而是下一代大模型的基础设施。
为什么?他们在技术报告中写道:「长视野场景和任务的涌现——从复杂的智能体工作流到大规模的跨文档分析——也使得对超长上下文的高效支持,对未来进展至关重要。」
这很合理。Test-time scaling 需要模型在推理时想很久,产生极长的思考链,上下文越长,计算量二次方爆炸。而当前关注长程任务的智能体工作流天然需要超长上下文,效率低就跑不起来,跑不起来就没有商业价值。
他们甚至不惜点名批评同行,说他们没有直面问题。论文中说:「尽管近期的开源努力(Kimi K2、DeepSeek-V3、MiniMax、Qwen)在推进通用能力方面取得了进展,但处理超长序列时这种核心的架构低效仍然是一个关键障碍,限制了 test-time scaling 的进一步收益,也阻碍了对长视野场景和任务的进一步探索。」
而做到了高效的长上下文处理,模型才能更好地做推理、完成长程任务、完成更复杂的在线后训练。
因此,谁做到了长上下文上的首先突破,谁就能更快地、更好地推进模型的训练发展。
在这个判断之下,V4 在决定上下文的核心技术,也就是注意力机制上进行了更激进的重构。
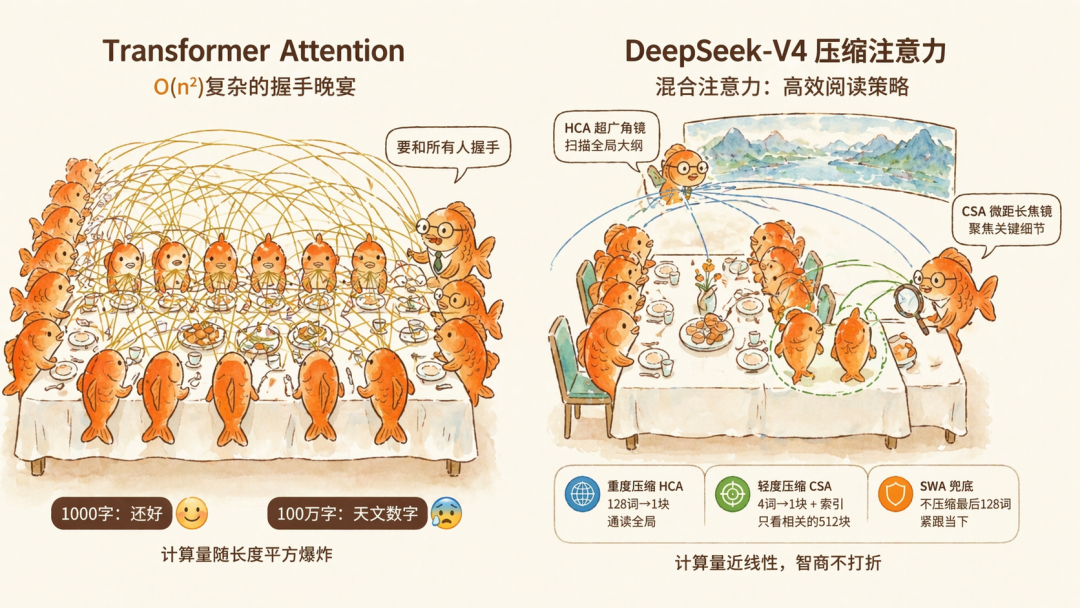
制约上下文的核心问题,其实就是 Transformer 架构中注意力机制(Attention)的复杂度问题。
重新定义「压缩」,从变薄到变短
在大模型圈,注意力压缩本身并不新鲜,但 DeepSeek-V4 这次是在下刀的维度上,走了一条创新之路。
注意力机制的计算工作量,其实由三部分组成,长度(文字的总数)× 宽度(大模型同时思考的注意力头数)× 厚度(每个词汇所蕴含的隐藏层维度信息量)。
在 V4 诞生之前,业界一直在宽度和厚度上做文章。比如 GQA(分组查询注意力)做的就是压缩宽度。它让大模型的多个思考线程(Query)共享同一组历史记录的键值(Key 和 Value)。这就像是把一份 100 万字的文件双面缩小打印后再让注意力去看,一个注意力看得就多了。
MLA(多头潜在注意力)则是意图压缩厚度,这是上一代 DeepSeek-V3 的核心技术。它嫌弃每个词的特征向量太长、太占地方,于是通过低秩映射(Low-Rank Projection)技术,把每个词压缩成了一个更短的潜在向量。这相当于发明了一种 token 的速记符号。
这两种方式的问题是,虽然压薄了、做窄了,但 100 万个速记符号依然是 100 万个计算单位,大模型还是得从头看到尾。
但到了 DeepSeek-V4 这一代,也就是核心的 CSA/HCA(压缩注意力),架构师们意识到只要文本的物理长度不减少,算力爆炸就永远无法停止。
于是,他们这次选择直接对时间/序列维度(长度)下刀。
V4 不再把 100 万个词当作 100 万个独立的实体,而是将它们强制融合。直接让小秘书把 100 万字的原著,揉碎重写成了一份不到 1 万字的执行摘要。大模型在后续推理时,只看摘要,绝不解压(No Decompression)。
传统的计算机压缩(比如压缩包),在读取时必须还原成原文件。但 V4 的压缩是一场「有损的语义融合」。它通过算法的权重分配,将几十上百个词的特征向量,按重要性比例像放进搅拌机一样揉碎后相加,形成了一个全新的「宏观概念超级 Token」。
这就像把多种水果打成了一杯混合果汁(融合),你再也无法把苹果和香蕉单独剥离出来(不解压),但果汁里依然包含了它们所有的营养(语义信息)。过去发生的事情,变成了这种浓缩的剧情大纲块。大模型在思考时,直接品尝这杯果汁(提取特征),彻底省去了将其还原回几十万字的算力灾难。
混合注意力的精细解剖
这么压缩的好处是极端省算力、省内存,但度怎么掌握呢?
DeepSeek-V4 并没有用一刀切的办法,而是设计了两把材质完全不同的手术刀交替使用。
先说 HCA(重度压缩注意力),它就是一个暴力的全局「超广角镜」,会极其暴力地大步长压缩。在 V4-Pro 中,它把连续的 128 个词,毫无缝隙地强行捏成 1 个超级概念块。当计算时,因为 100 万个词被压缩了 128 倍后,只剩下不到 8000 个块,这点长度对大模型来说不过是小菜一碟。所以它不做任何筛选,直接从头到尾通读这 8000 个块。
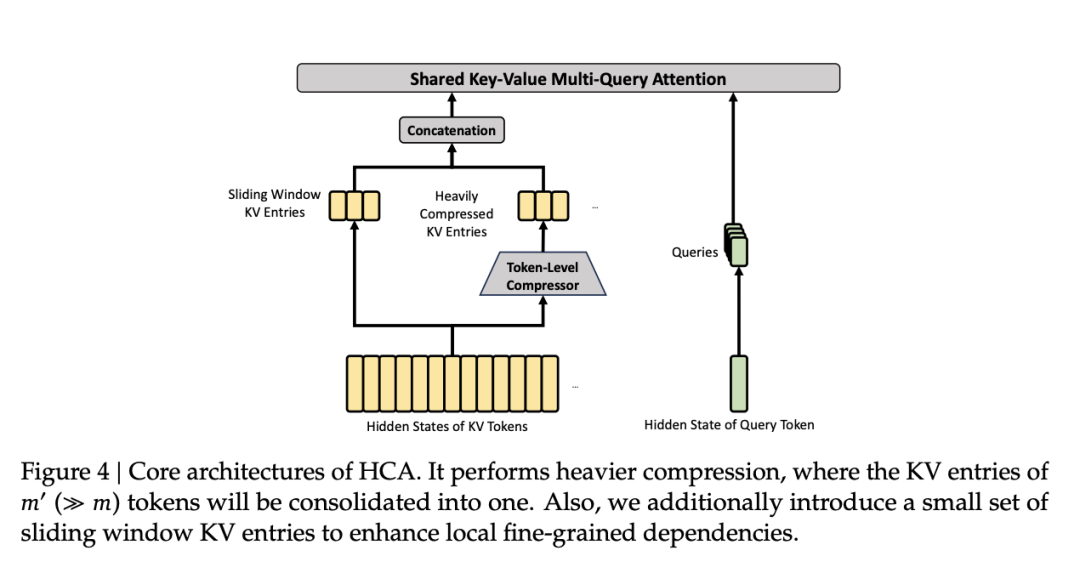
HCA 为大模型提供了一个极其廉价的全局底噪。这就像是侦探在脑海中随时挂着一幅「案件宏观时间线」,它确保模型在处理百万字时,始终锚定宏观语境,绝不跑题。
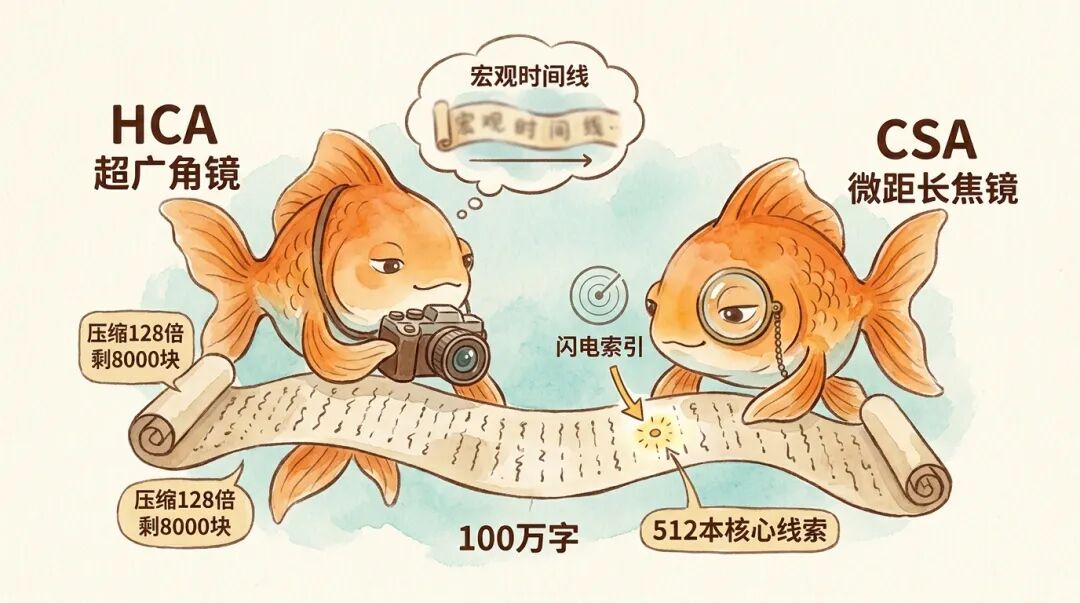
第二个压缩级别是 CSA(压缩稀疏注意力),它是个附带雷达的「微距长焦镜」。
如果只有宏观的 HCA,大模型就会变成一个只会敷衍大意、丧失精细推理能力的糊涂蛋。为了找回丢失的细节,CSA 登场了。它采用的是相对 HCA 的轻度压缩,仅把 4 个词融合成 1 个。并且为了防止相邻句子的意思被切断,它采用了带重叠的滑动压缩,保证了语义的平滑过渡。
在 CSA 下,既然压缩率低,那 100 万字压缩后依然有 25 万个块,如果全算一遍,算力依然会宕机。于是,V4 给它祭出了「微型雷达」闪电索引器。
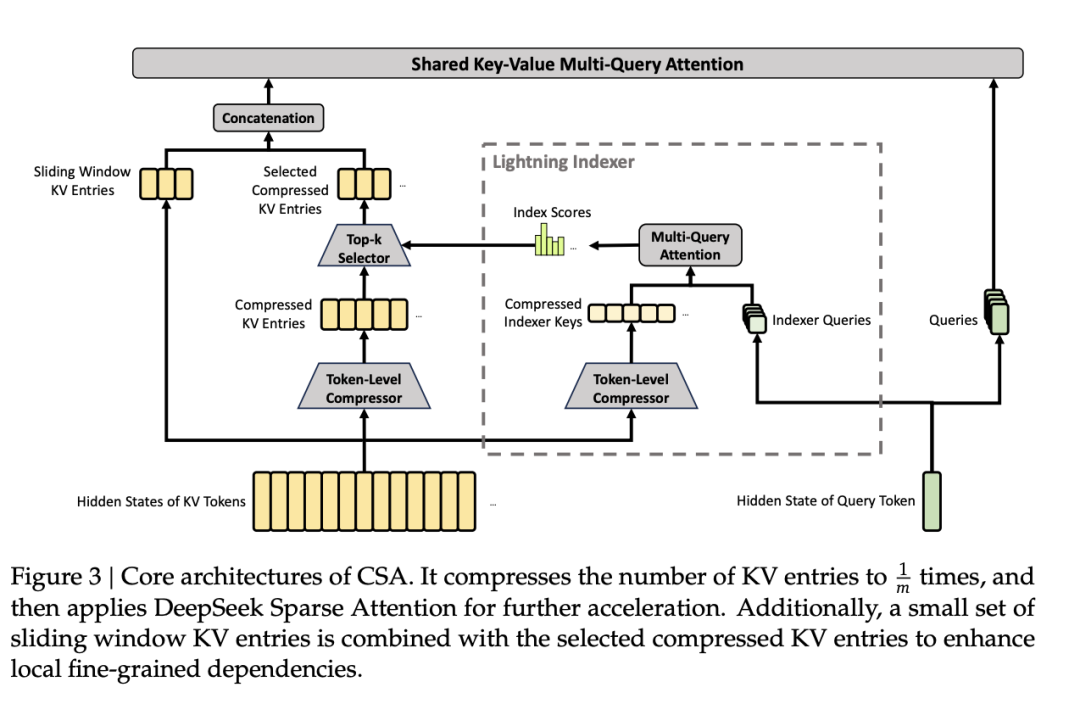
它把当前大模型的提问(Query)降维成一个极小的数据包,像雷达扫描一样飞速掠过这 25 万个压缩块,最后帮模型锁定最相关的 1024 本书(Pro版本)。这时,大模型只把注意力投入到这挑出来的几百本核心线索书上,进行深度的精准核对。
在 DeepSeek V4 的设计里,架构上这两种方法是一层叠一层的,时而用 HCA 扫视全貌,时而用 CSA 拿着放大镜聚焦线索。它基本完美复刻了人类阅读长篇巨著时略读与精读交替的高能效认知模式。
这种方法带来的是巨大的收益,靠着这种粗读方式,V4-Pro 的单 Token 推理计算量(FLOPs)仅为上一代 V3.2 的 27%,而极其昂贵的显存(KV Cache)占用仅为 10%。V4-Flash 更夸张,计算量仅占 10%,显存仅占 7%。
「深度补偿」的极限套娃游戏
这个世界上能量是守恒的。DeepSeek 用暴力压缩在长度上占了天大的便宜,难道就真的不会影响精度吗?
从常识上看,把 128 个字的庞大语义强行塞进原来只能装 1 个字的特征向量里,细节必然会被无情地挤碎。

所以为了保住大模型的智商,防止关键信息的流失,一定要有点补偿。DeepSeek 的架构师们开始在补偿中套娃,补偿的第一步是把特征向量强行加厚(Depth Compensation)。在 DeepSeek-V4-Pro 中,为了兜住这 128 倍压缩带来的信息洪流,架构师将大模型单个注意力头(Head)的隐藏维度(即容器的厚度)从常规的 128 维,丧心病狂地拉宽到了 512 维。这个加厚操作确实保住了信息的保真度,但它引爆了另一个计算炸弹。
在神经网络中,大模型同时工作的 128 个注意力头(就像 128 个独立思考的员工),在算完自己的结果后,需要把数据拼接在一起,向上级汇报(映射回模型的原始维度)。因为前面把每个头的维度加厚到了 512,这 128 个头拼起来的数据长度直冲 65536 维!如果不加干预,负责这次汇报的投影矩阵将吃掉惊人的 4.7 亿个参数。
看到这里,你可能会产生一个敏锐的疑问,既然为了兜住信息,把向量加厚到了 512 维,单次计算量变大了,那之前压缩长度省下来的算力,是不是里外里又被抵消了?
这笔账,其实完全算得过。大模型最耗时的操作,是那条二次方爆炸的长度曲线。因为把 100 万字的长度压缩到了不到 8000 个块,注意力机制省下的是数百亿次的浮点运算;而因为把维度加厚到 512 维,特征计算虽然增加了 4 倍,但付出的代价仅仅是几亿次浮点运算的倒贴。
所以它引发的不是计算能力的瓶颈,而是带宽的拥塞。如果每生成一个词,显卡都要在内存和计算单元之间搬运这近 1GB 的权重数据,显存带宽(高速公路)会被瞬间挤爆,推理速度将如同大塞车一般龟爬。
因此补偿进入第二层。为了填平这个坑,V4 引入了「分组输出投影」。这就好比一场科层制的企业管理改革,128 个基层员工不再直接把几万页的报告拍给大老板,而是被划分为 16 个小组;每个小组先在内部把报告浓缩为一份短小的小组总结,最后由 16 个中层领导统一汇报给老板。通过加入这层极薄的中层管理结构,投影矩阵的参数量断崖式暴跌近 60%,成功在数学层面上化解了带宽塞车的危机。
但就算在深度上补偿过了,深度本身也是一种压缩形式,重要的内容依然可能丢失。因此 DeepSeek V4 就开启了补偿第三步,即绝对兜底的滑动窗口注意力(SWA),它强制不压缩最后的 128 个 token。
它保证了模型在天马行空思考 100 万字大背景的同时,双脚始终牢牢踩在当下的现实中。
压缩的魔法,也许模型真的不用看得那么细
这种不断压缩、缝缝补补的架构,单纯从外部看挺不靠谱的。但从测试效果看,它换来的是实打实的智商飞跃。
因为不再受困于计算资源的限制,大模型展现出了更宏观的聚合视角。
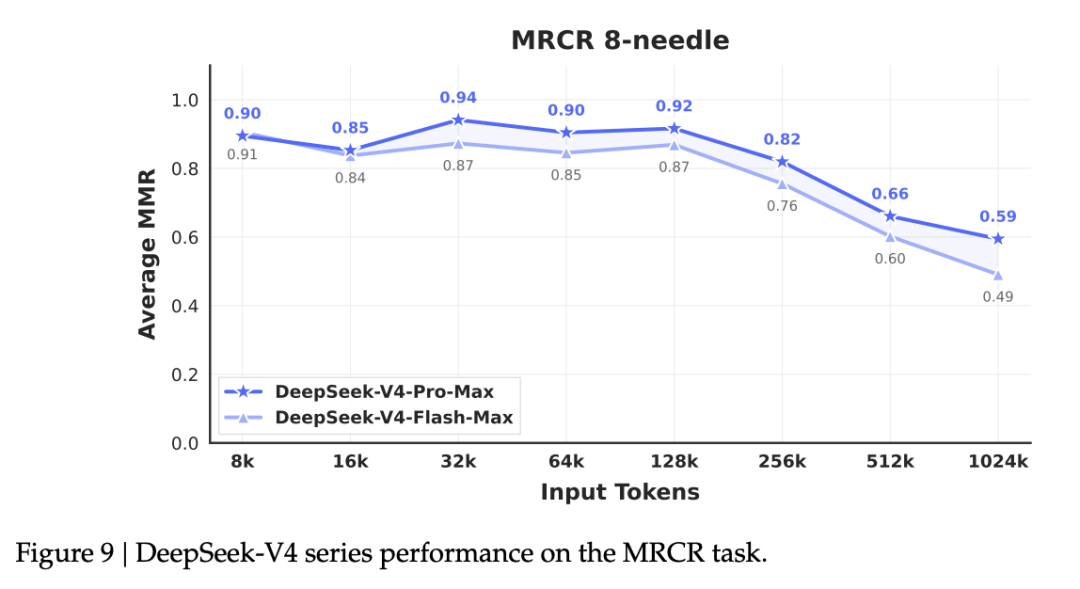
在 Codeforces 这种堪称人类脑力炼狱的编程竞赛中,V4-Pro-Max 以 3206 分的 Rating 首平了 OpenAI 的 GPT-5.4 等闭源顶流;在百万长度的大海捞针极限测试中,其检索表现甚至超越了 Gemini-3.1-Pro。
压缩和线性,哪条路更好?
在章节的开始,我们提到过以 Kimi (Moonshot AI) 为代表的线性注意力机制(Linear Attention)。和 DeepSeek 一样,它彻底抛弃了保留所有历史记忆的执念。但做法上与 DeepSeek 靠直接压缩不同,它不再做整本厚厚的读书笔记,而是只拿一张小卡片(状态矩阵)。每读到一个新词,就擦除一下卡片,把新意思融合进去,不断更新。
因此,它的计算复杂度是完美的一次方复杂度,这意味着,无论你给它看 100 万字还是 1000 万字,它生成每一个新词所需的算力和显存,就像死水一潭,永远不会增加。
从理论上限来看,它无可匹敌。
但把 100 万字的汪洋大海,全揉进一张固定大小的卡片里,必然会导致精细记忆的严重丢失。为了找回智商,当前的线性注意力(如 Kimi)被迫向现实妥协,采用了 3:1 混合架构——每读 3 层小卡片,就必须强行穿插 1 层传统的标准注意力机制来翻看原著回血。
而正是这剩下的 25% 传统层,依然要硬扛百万长度的算力大山,成为了拖累其整体起飞的木桶短板。
而 DeepSeek 的方法,从结果上比这种妥协模式更省(10% vs 25%)。更重要的是,它本质上依然是矩阵乘法(大规模的行列式计算),这正是当今英伟达等 GPU 芯片最适合的计算类型,其实际运行的硬件效率极高,对 infra 改造的要求比线性注意力要小。

因此,DeepSeek-V4 就是当前工业界更完美的现实主义最优解。为全世界提供了一个当下就能用、且用得起的百万级上下文引擎。
交错式思考,DeepSeek的Harness训练
除了主线的注意力改变之外,为了更好的应对百万级的 token 量,DeepSeek V4 还提出了一个解决上下文连贯性的 Harness 框架。
它就是 Interleaved Thinking(交错式思考管理)。
在 DeepSeek-V3.2 里,模型已经开始区分「工具调用过程中的思考」和「普通对话中的思考」,但它仍然有一个问题:当新的用户消息进来时,之前积累的 reasoning traces 会被丢弃。
对于普通聊天来说,这样做是合理的,因为大多数对话不需要背着一大串中间推理往前走,保留太多反而浪费上下文。
但对于复杂 Agent 任务来说,这就很致命。
一个真正的 Agent 往往不是一问一答,而是要经历搜索、读取、写代码、运行命令、观察结果、修正计划、再次调用工具的多轮循环。如果每一轮用户消息或工具结果之后,模型都要重新构建自己的问题理解,它就像一个每走几步就失忆一次的工程师。
上下文看似还在,但任务状态已经断了。
V4 的做法是,把这两种场景彻底分开。在普通对话场景里,它仍然丢弃上一轮的思考内容,保持上下文简洁;但在工具调用场景里,它会跨用户消息边界保留完整的 reasoning history,让模型能够把前面每一次搜索、每一次工具反馈、每一次失败尝试都纳入同一个连续的问题求解过程。
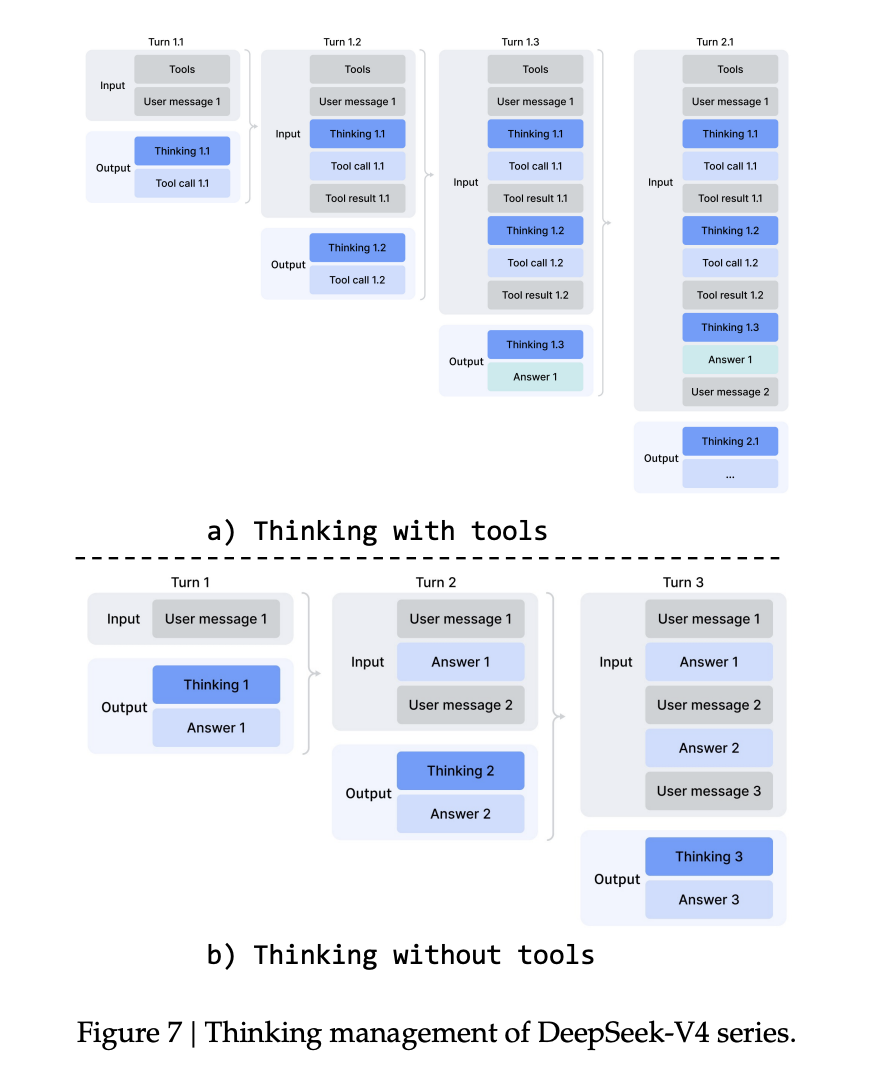
这就是为什么百万 token 上下文在 V4 里不只是一个「能塞更多文本」的功能。它变成了 Agent 的工作记忆。长上下文负责提供足够大的记忆空间,Interleaved Thinking 则决定这块空间怎么被使用。没有前者,复杂任务装不下;没有后者,复杂任务虽然装得下,但模型仍然无法稳定地沿着一条长链路持续推进。
所以从这个角度看,V4 的长上下文不是孤立的架构炫技,而是在为长程 Agent 工作流补齐一块基础设施。
CSA/HCA 解决的是百万 token 能不能算得起,Interleaved Thinking 解决的是算得起之后,模型能不能真的把这些历史变成连续的行动能力。
第二个范式更新:推翻传统后训练
在大家都还用 GRPO 作为后训练的基础的时候,发明了这一方法的 DeepSeek 先部分推翻了它。
这说明,在 DeepSeek 看来,后训练范式还远没有定型。
当下的后训练面对的最大的两个问题,一个是对齐税(Alignment Tax),另一个就是对非 RLVR 领域的拓展可能。
DeepSeek V4 这次对两个方向都发起了进攻。

用 OPD 携手多个老师消除对齐税
对齐税,指的是当我们试图让模型变得更听话、更严谨时,往往会以牺牲其原始的创造力或特定领域的灵动性为代价。这是因为 V3/V3.2 时代所采用的,现在也属于行业比较通用的 Mixed RL(混合强化学习)范式中,所有的目标(代码、数学、创意写作、指令遵循)都在同一个 RL 过程中被优化。
当模型试图同时满足数学的绝对严谨(Rule-based RL)和文学的优雅流畅(Preference-based RL)时,这两种截然不同的奖励信号会在参数更新中产生极其剧烈的冲突。结果往往是模型常见的平庸化,为了保住代码不报错,模型变得像个复读机;为了让语气更有亲和力,它的数理逻辑开始松动。每个值都达不到最好。
因此,V4 团队提出的第一条自救逻辑是,承认偏科的必然性,并将其工程化。他们首先独立培养了十几个领域的顶级专家。数学专家只需在数学沙盒中用传统的 GRPO 方式进行训练,而代码和 Agent 专家则在 DeepSeek 自己设计的一套任务锚定的 DSec 沙盒中通过百万次的编译反馈不断进化。这种物理层面的隔离,确保了每一种能力都能在不被其他领域干扰的前提下,触碰到当前参数规模下的性能天花板。
那在专家们各显神通之后,如何将这些灵魂重新注入一个统一的容器?用 OPD(On-Policy Distillation)。
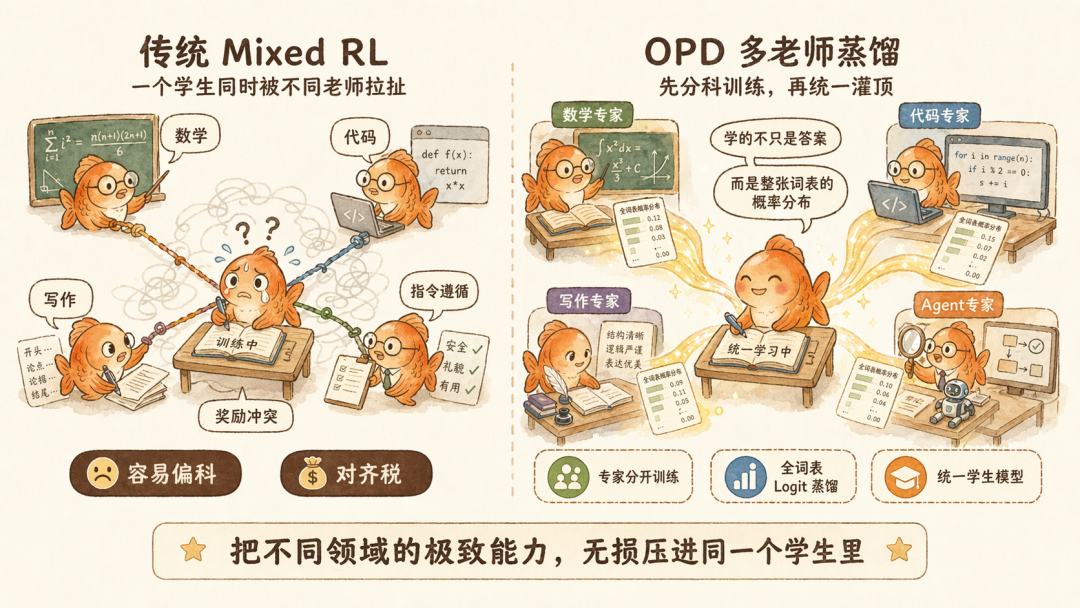
OPD 一直是大模型后训练中的一个明日之星,因为它就是可以统合不同的能力。但传统的蒸馏由于算力限制,没法蒸馏全部词表,往往只能做 Token 级别的对齐,或者为了省显存而只学 Top-K 的分布。这种管中窥豹的学习方式会让学生模型只学到皮毛(表层概率),而学不到教师模型深层的逻辑概率分布。
为了避免这种现象,DeepSeek 这次选择了全词表 Logit 蒸馏(Full-vocabulary Logit Distillation)。为了实现这种全量灌顶,DeepSeek 设计了一套极其巧妙的缓存替换策略。在前向传播时只存隐状态(Hidden States),在反向传播时动态重构 Logits。
这种方法让学生模型(最终的 V4)能够完美拟合所有专家模型在全词表上的输出分布。这不仅仅是学答案,而是学概率。由于学生模型在每一轮迭代中都在向这十几个顶尖专家对齐,它成功规避了上面提到的权重融合(Weight Merging)带来的性能退化,实现了真正意义上的无损大一统。
GRM,将「通用验证器」带入工业生产线
如果说 OPD 是解决如何合,那么 GRM(生成式奖励模型)就是解决怎么奖励的问题。
这个问题在后训练届也是由来已久的,过去我们训练的主要是那些有 Ground Truth 的领域,比如数学、代码(可以通过跑不跑得通验证),这类训练叫做 RLVR(即建立在可验证奖励上的强化学习)。它让模型的代码和数学能力一日千里。
但对于主观性极强的难以验证的任务(Hard-to-verify tasks),我们之前都是用传统的标量奖励模型(Scalar RM),它是一个黑盒,只能给出一个 0.8 或 0.9 的分数,却无法告诉模型「为什么这里写得好」。
这导致模型在 RL 阶段极其容易通过刷字数或特定语气模板来欺骗奖励函数(Reward Hacking)。
学界之前给出的解决方法就是希望建立一个 Universal Verifier(通用验证器),能给所有类型的任务都提供有效的奖励函数。
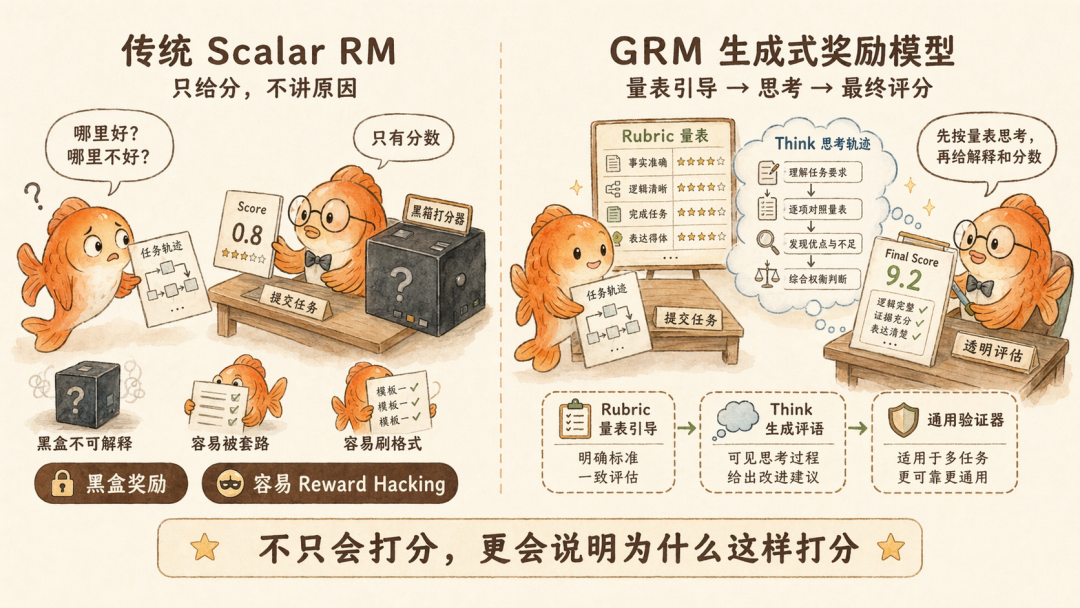
但主观的怎么给,有人用模型自己生成,结果发现效果不怎么样;有人则提出人来写规则,但人也不可能穷尽所有的规则,依然很难。
DeepSeek-V4 对此的逻辑是,结合并超越。GRM 的工作流程被设定为,评分量表(Rubric)引导 → 思考轨迹生成(Think)→ 最终评分。又有量表,又有模型判别。
同时,这个写判决的模型(GRM)和生成的模型是同一个模型,并且联动优化。过去单独训练一个小一点的评分模型,导致评价水平低的问题,也被解决了。
不光如此,通过联合优化,Actor 生成模型在数理逻辑训练中练就的「肌肉」,被直接借用到了 GRM 的评估过程中。这意味着,当模型评估一个 Agent 的轨迹时,它不再是靠感觉,而是动用了它在代码和数学训练中获得的因果推演能力。
而这种因果能力,在一定程度上又抑制了评价模型自己过于自信的可能。
这种推理赋能评估的机制,让 GRM 从过去工业论文中比较实验性的尝试,第一次变成了一个鲁棒的、能够指挥万亿参数模型进行对齐的「工业级通用验证器」。
最终结果:拒绝「偏科怪物」,走向能力均一化
还记得 GPT 5.4、Claude 4.7 被吐槽最多的点吗?就是编程行,但不说人话。这正是目前许多追求极限 RL 模型的通病。
靠着上面这套新的后训练范式,论文中对 V4 最终表现的自评,是 Uniform Performance(表现均一性)。
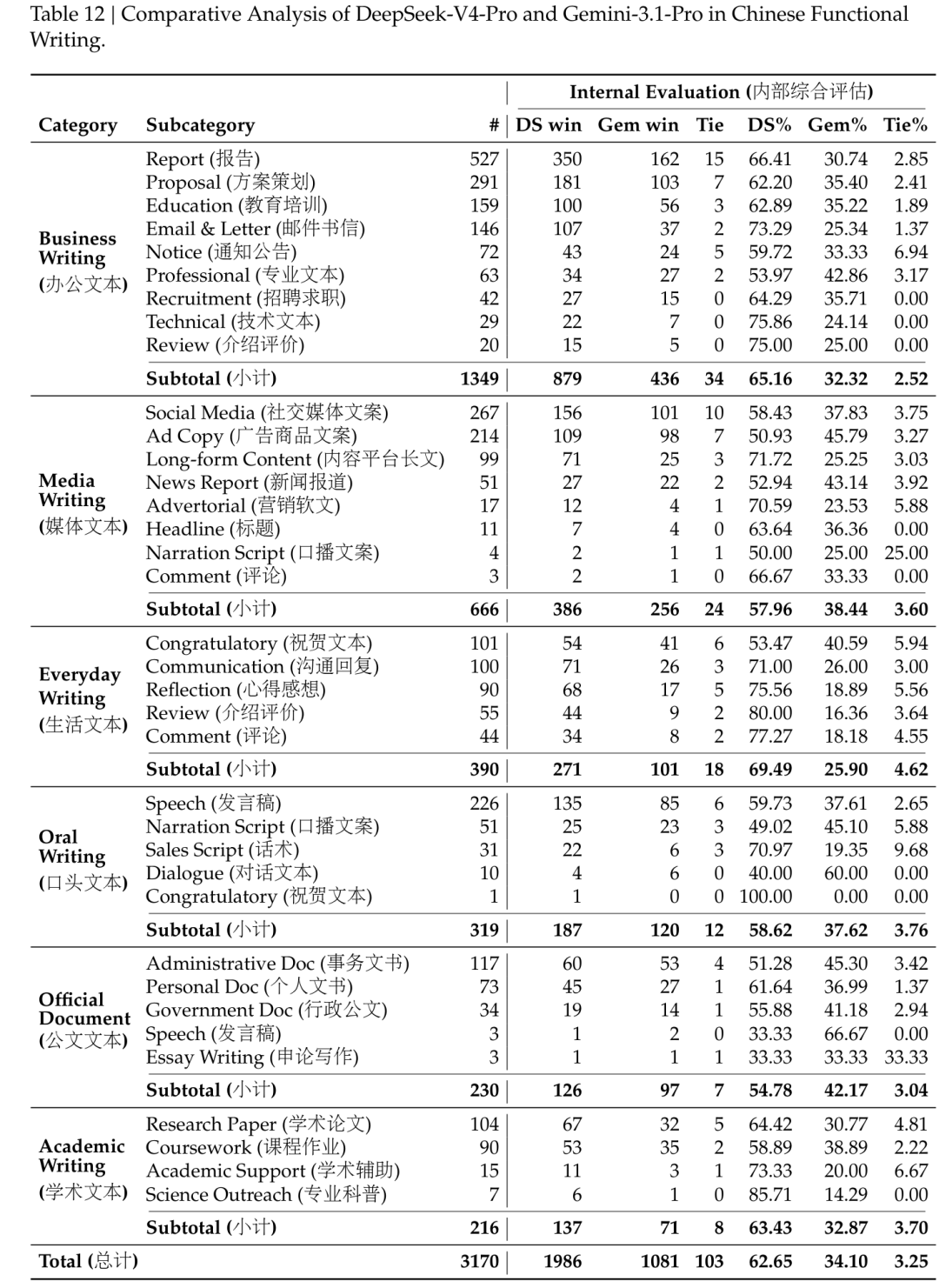
在高阶白领任务(White-Collar Task)中,在包含金融、教育、法律等 13 个行业的复杂中文任务(深度信息分析、长文档生成、精细编辑)中,V4-Pro-Max 直接对标了闭源的 Claude Opus 4.6 Max,并且拿下了 63% 的不败率(胜+平)。中文写作(Chinese Writing)中,V4-Pro 以 62.7% 的胜率碾压了基线模型 Gemini-3.1-Pro(后者胜率仅为 34.1%);在创意类写作的「写作质量」指标上,胜率更是高达 77.5%。而硬核代码研发智能体(R&D Coding Agent)也没落下,在收集自内部工程师的 200 多个真实复杂研发任务(涉及修 Bug、重构、多语言栈)中,V4-Pro 的通过率达到了 67%,远远甩开了 Claude Sonnet 4.5(47%),并且逼近了 Claude Opus 4.5(70%)。
这套方法论其实就是 RL 的下一轮转型信号。大模型的下一阶段,拼的不再是简单的 RL 算力堆砌,而是谁能用最优雅的工程结构,把分布在不同领域的极致智慧,毫无损耗地压缩进同一个参数空间里。
第三个范式更新:mHC 带来的残差流的「稳压器」
mHC 因为之前 DeepSeek 单独发过论文,所以很多文章都对它进行了一些讲解。但这次开源的 V4,让它的具体落地方法更明确了,依然有必要再细说说。
残差,模型之间的通信管道
想讲明白 mHC,就得先讲明白 HC(超连接),想讲明白 HC,得先从残差连接开始。
大模型的世界里,每一层 Transformer 都在做同一件事。就是把输入的数据做一次复杂的非线性变换,然后传给下一层。数据从第一层流到最后一层,要经过几十次这样的加工。这听起来像是一条顺畅的流水线,但实际上,随着网络越来越深,这条流水线会从根部开始腐烂。
问题的根源出在梯度上。当模型做反向传播、从最后一层往回更新权重的时候,梯度要经过几十次连乘。只要有一点点微小的误差被放大,梯度就会直接变成零即梯度消失,或者变成一个天文数字即梯度爆炸。一旦发生这种情况,模型的训练会瞬间崩溃,之前几周的训练成果全部化为乌有。
何恺明提出的残差连接(Residual Connection),就是为了解决这个问题。它的想法其实挺简单的。在标准的前馈网络里,第 l 层的输出是 F(x),即一个复杂的变换函数。残差连接干脆在旁边加了一个加号,把公式改成了,输出 = x + F(x)。
这个加号就是那条「水管」。它的意义就是,即无论 F(x) 这一层的变换有多离谱、提取的特征有多没用,模型至少还能拿到一份最原始输入的完整拷贝,不至于让信息在顶层彻底失真。
从反向传播的角度看,这个加号更像是一条「应急车道」。梯度不用非得钻过 F(x) 那堆复杂的权重矩阵,它可以顺着这条直通的水管直接流回底层。只要这条水管还在,哪怕中间的层学得一团糟,底层的梯度也能顺顺畅畅地流回去,保证训练不会断掉。
这就是残差连接最核心的价值,即它保住了深度网络的生命线。
但残差连接有一个天生的缺陷。它的「水管粗细」即通道数,跟模型的隐藏层维度(Hidden Size)死死绑定在一起。因为要做 x + F(x),F(x) 的输出维度必须跟 x 的维度完全一致,否则根本加不起来。
这意味着,如果你想让这一层提取更多的特征、表达更复杂的信息,你只能整体加大隐藏层的维度,而这会直接推高整层整层的计算量和显存消耗。
残差流本身没有独立的设计空间,它完全被 F(x) 的内部结构给绑架了。
超连接,把单车道强行改成四车道
Hyper-Connections(HC)的提出,就是觉得这种「强制对齐」太浪费了,它在拖模型的后腿。HC 的核心想法是,凭什么残差流的宽度要被隐藏层维度限制住?为什么不能单独把残差流拉宽,让它变成一条真正的信息高速公路?
具体做法是,HC 在残差流进入每一层之前,先用一个「输入映射矩阵」把窄的残差流投影到一个更宽的空间;等到 F(x) 算完之后,再用一个「输出映射矩阵」把宽的 F(x) 压缩回原来的残差流维度。
这样一来,F(x) 内部可以随便设计得又宽又复杂,完全不拖累残差流的维度。残差流自己则独立地变宽。
这相当于把单车道强行改成了四车道。
更多的独立通道意味着残差流可以同时、并行地传递更多样、更细粒度的原始信息。底层捕捉到的某个细微特征,不用跟其他特征挤在一起。
它有自己专属的车道,可以毫发无损地直接流淌到最顶层。从信息论的角度看,HC 打破了残差流和隐藏层之间的维度死结,提供了一个全新的「缩放轴」,即在不改变模型计算量(FLOPs)的前提下,仅仅通过拉宽残差流,就能大幅提升模型的信息交换效率。
但 HC 在自己的成功里埋下了毁灭的种子。它只管把路修宽,却完全没想过宽路上如果不设红绿灯、不限速、不划车道,车流会在半路发生什么。
当四车道变成车祸现场
HC 的训练不稳定问题,根源在于它对残差映射矩阵的参数没有任何约束。输入映射、残差变换、输出映射,这三组矩阵的全部权重都是自由学习的。这会带来两个致命的后果。
第一个后果是信号抵消。如果残差变换矩阵里的权重符号不统一,有的正、有的负,那么在高层进行矩阵加法的时候,不同的特征通道就会发生严重的相消干涉。好比两股劲使反了,力气越大,残差里的有效信息反而被抵消得越干净。
你以为拉宽了四车道能让更多信息传递过去,但实际上,这四股车流可能在半路迎头撞上,最后啥都没剩。
第二个后果是梯度爆炸。因为映射矩阵是自由学习的,没有谱范数(Spectral Norm)的任何约束,随着网络越来越深,这些矩阵在向前传播时会被反复连乘。一旦某个矩阵的模稍微大于 1,经过几十层的堆叠,输出值就会呈指数级膨胀。等到数据流到顶层的时候,激活值直接冲进无穷大,Loss 变成 NaN,训练瞬间崩溃。
这就像水压太大且没有控制,水流在几十层楼之间来回放大或叠加,最终要么互相激荡导致水流莫名其妙地消失,要么压力过大直接把整栋楼冲垮。
这就是为什么 HC 虽然被证明有潜力提升模型性能,却始终没法扩展到极深的网络。它不是不够强,它是太强且完全失控。
HC 修了一条没有护栏、没有限速、没有交通规则的超级高速公路,车速越快,翻车的概率就越高。
mHC,给超级高速公路装上智能交通管制系统
Manifold-Constrained Hyper-Connections(mHC)的出现,就是要把这头脱缰的野兽重新关回笼子里。给 HC 加 Harness 了属于是。方法也和 Harness 很相似,就是直接对残差映射矩阵施加流形约束,让它永远无法脱离安全区间。
mHC 的关键,是强制要求中间的残差映射矩阵 W_res 必须满足「双随机矩阵」(Doubly Stochastic Matrix)的性质。翻译成人话就是,这个矩阵的所有元素都必须是非负数,而且每一行的和等于 1,每一列的和也等于 1。听起来这就是个归一化,但它很好用。
一个矩阵如果是双随机的,那么数学上可以严格证明,它的谱范数(L2 诱导范数)最大只能是 1。这意味着,无论数据怎么流过这一层,输出的能量(模长)绝对不可能超过输入。这就相当于给信号的放大倍数焊死了一个硬上限。不管矩阵内部的权重怎么变,它都不可能变成一个「膨胀器」。
这是从数学根源上铲除了梯度爆炸的可能性。
更有意思的是,双随机矩阵的集合(数学上叫 Birkhoff 多面体)在矩阵乘法下是封闭的。这意味着,即使你把几十个这样的矩阵连乘起来,结果依然是一个双随机矩阵,谱范数依然不会超过 1。
这就保证了,哪怕网络堆到 61 层、121 层,信号在整条链路上的传播依然是绝对稳定的,不会因为层数加深而出现累积性的数值漂移。
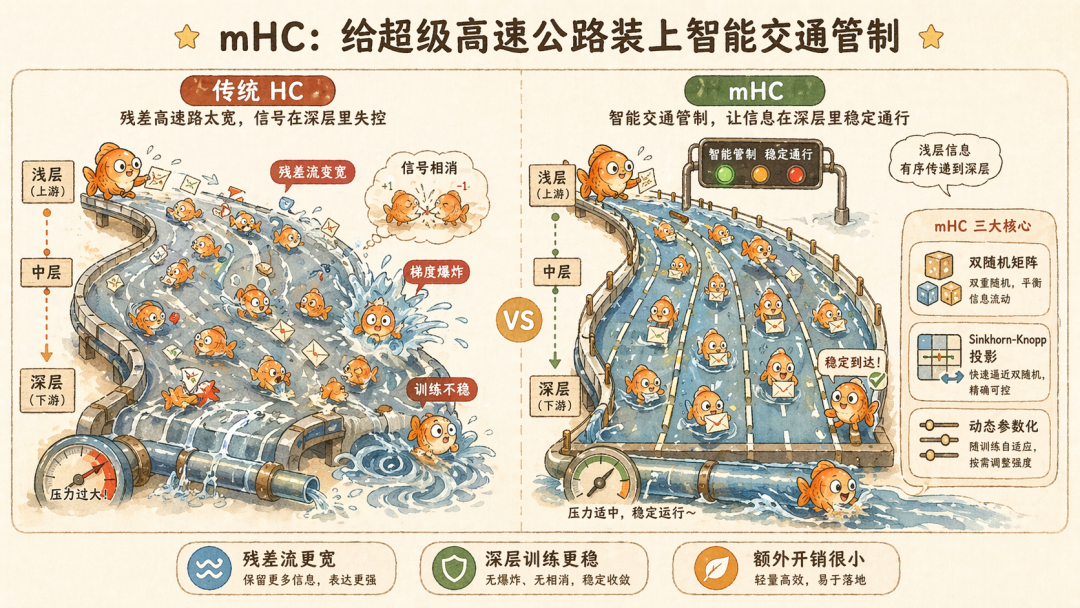
除了核心的残差映射,mHC 还对输入和输出的映射矩阵也动了手脚。它用 Sigmoid 函数把这两个映射矩阵的权重死死压在 0 到 2 之间。这保证了信息在进出残差流的时候,永远是正增益或者温和衰减,再也不会出现正负号打架导致的信号抵消。
这就像在每条车道上装了单向阀和限速器,确保车流只能往前走,而且速度永远在一个安全范围内。
DeepSeek 的极致性价比再次出现
但这套做法里,强行把一个任意的矩阵变成双随机矩阵,这计算量岂不是巨大?
这对于擅长搞稀疏化的 DeepSeek 来讲并不难。mHC 用了一个非常巧妙的近似算法,叫 Sinkhorn-Knopp 迭代,来高效地完成这个投影。首先,对残差映射矩阵的每个元素取指数(exp),保证所有元素都是正数。然后,像「天平称重」一样,先让每一行除以行和(行归一化),再让每一列除以列和(列归一化)。这样来回迭代,通常只需要 20 次(DeepSeek V4 中 T_max=20),矩阵就会收敛到双随机状态。
它不需要做任何昂贵的矩阵分解,只需要做简单的逐行、逐列除法,完全可以写成高效的 CUDA 核函数。而且,由于 Sinkhorn-Knopp 迭代是高度可并行的,mHC 可以把多组映射矩阵打包到一起,用一次大的矩阵运算批量完成投影,最大化 GPU 的硬件利用率。
除了流形约束,mHC 还引入了一个叫「动态参数化」的设计。它让残差映射的矩阵参数变成「动态」的,即根据当前输入的数据特征,临时生成一份专属的映射矩阵(动态分量),再叠加上一份不变的底版(静态分量)。这样做的目的是,在享受流形约束带来的稳定性的同时,还能保留模型对复杂数据的拟合能力。如果映射矩阵全是死板的数字,模型可能会学不动,动态参数化则给了 mHC 足够的表达力余量。
mHC 的引入,从原理上看是在「增加」计算量和显存消耗的。每一次前向传播,都要多算三组矩阵映射,还要跑 20 轮 Sinkhorn-Knopp 迭代。每一次反向传播,都要多传三组矩阵的梯度。更何况,拉宽后的残差流本身就会占用更多的激活显存,在流水线并行(Pipeline Parallelism)时,还会增大跨 GPU 的通信量。
但 DeepSeek V4 的论文数据表示,mHC 带来的额外时间开销,被死死压在了仅占流水线 Stage 总耗时的 6.7%。这意味着,mHC 几乎是在「免费」运行。
从结果来看,DeepSeek 的团队几乎是把底层 CUDA 编程的潜力榨干到了极致,才让这套复杂的流形约束系统能够在实际训练中实用化。
mHC 到底带来了什么
严格来说,mHC 的首要目的不是「高效」,而是「可能」。在没有 mHC 这样的流形约束之前,HC 那种拓宽残差流的设计,根本没法在极深的网络上稳定训练。你要么接受残差流被绑死的窄水管,要么冒险用宽水管但随时准备面对训练崩溃。
mHC 出现之后,这个二选一的困局被打破了。你现在可以放心地把残差流拉宽,放心地往深了堆 Transformer 层,因为 mHC 已经用数学硬约束把整条链路的水压和流向给焊死了。
这种「稳定」带来的,是质变级的能力提升。
因为 mHC 把这条宽阔但极度危险的残差流彻底驯服了,模型现在可以放心地在第一层和第六十一层之间传递极其复杂的逻辑特征,而不用担心中间失真。
在 DeepSeek V4-Pro 里,残差流的扩展因子 r_hc 被设为 4,意味着残差流比隐藏层维度宽了四倍。这多出来的通道,承载的是底层捕捉到的细微推理线索,即一段代码的语法依赖关系,或者一段长文的因果链。这些信息可以原汁原味地直接流淌到最顶层的预测头,不会被中间几十层的复杂变换给稀释掉。
这就是为什么 V4-Pro 在仅有 49B 激活参数的情况下,逻辑推理能力能够直接逼近满血版 Claude Opus 4.5 和 GPT-5 级别模型的核心原因。
它不是靠堆参数堆出来的性能,而是靠把信息传递的通路彻底打通、把信号损耗降到最低,才在参数效率上实现了对同级别模型的降维打击。
从更广阔的视角看,mHC 解决的是一个被整个行业低估了的问题,即当大模型走向极深度、极长上下文的时候,信息传递的效率瓶颈,可能比计算量的瓶颈来得更致命。
大家的注意力都放在了怎么减少注意力层的计算量、怎么压缩 KV 缓存,却很少有人意识到,如果残差流这条路本身不通畅,再强的注意力机制也救不了顶层的信息失真。
DeepSeek V4 用 mHC 给出了自己的回答。这套看起来朴素的「稳压器」,让 61 层的深层网络能够像浅层网络一样稳定训练,让百万 token 的上下文信息能够像流进浅溪一样顺畅地流淌过整个模型。
结合之前 DeepSeek 对长上下文的信仰,这个改变的意义就变得更加意义深远了。
范式革新外的工程优化
除了上面提到的三层范式级别的革新外,DeepSeek V4 在工程上的优化依然和之前一样可圈可点。它们和上边提到的 mHC 一起,形成了训练稳定和高效的基石。这就是这篇技术报告在长上下文和后训练改革外的第三个主线。也是 DeepSeek 一直以来都在构筑的,高效训练框架。
Muon 优化器的工程迭代
首先是对 Muon 优化器的使用。DeepSeek V4 并不是第一个用 Muon 优化器训练的万亿模型,但它解决了过去它存在的一个重要工程难题,让它更容易被在工程界广泛推广。
Muon 优化器本身其实很重要。它可能会直接重写未来所有大模型的「炼丹说明书」。
训练模型最重要的是什么?就是做梯度下降,梯度下降的又好又稳,那这个模型训练就非常顺滑。但梯度(现实和生成的差距)在那儿,怎么调整模型参数才能让它能很好地接近现实呢?这里面可能涉及的可调整项非常多。我们把这些可调整项想象成旋钮,负责决定怎么去拧这些可调整按钮的指挥系统,就叫优化器(Optimizer)。
之前,全世界都在用一个叫 AdamW 的老牌指挥系统。它的工作逻辑是各自为战。它会让每个旋钮只看自己的历史记录,「我过去主要往左扭」,「我过去扭得猛不猛」,然后每个旋钮独立决定下一步怎么动。这在小模型上没问题,但在万亿级模型上,因为大家不看彼此的配合,最后会导致旋转发力极度不均匀。有的旋钮都拧已经冒烟了,有的旋钮还一点不动。这让训练效率大打折扣。
2024 年,学术界提出了 Muon 优化器,它的核心思想就是,不要让按钮自己决定怎么旋,我们要有一个全局的视角!在每次调整前,Muon 会先通过一个复杂的数学操作(正交化),把所有旋钮的协同关系算得清清楚楚。经过 Muon 调配后,所有参数维度的更新步长变得非常均衡。大家整齐划一,没有谁掉队,也没有谁冒进。

业界(比如 Kimi 的 K2 论文)已经证明了它的威力,在同样的计算资源下,换上 Muon 后,模型的错误率(Loss)下降速度极快,训练极其稳定。这等于你花同样的电费,练出了更聪明的模型。
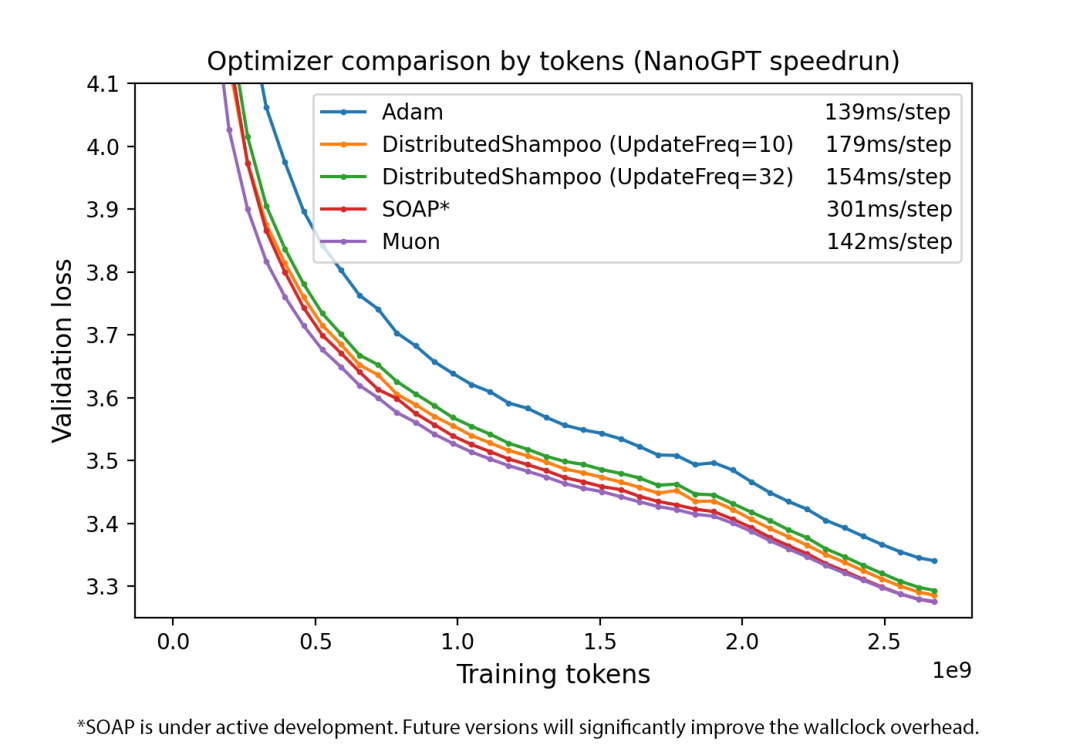
既然这么好,为什么以前大厂都不用?因为 Muon 身上带了一个工业级绝症。
Muon 的全局统筹有一个硬性前提,它必须一眼看到完整的梯度矩阵(所有旋钮的状态)。但现代大模型训练,根本不可能把所有参数放在一张显卡上。业界通用的做法(叫 ZeRO 技术)是把庞大的参数矩阵像切豆腐一样,切成成千上万块,散落在几千张显卡上。AdamW 觉得无所谓,反正参数是各自为战,切得多碎它都能算。但 Muon 傻眼了。它需要统筹全局,但现在每个人手里只有一块拼图。如果每次更新都要让几千张显卡停下来,把拼图凑齐了再算,那个通信延迟和堵车程度,会直接把训练速度拖垮为零。
这就是为什么过去一年,大家都知道 Muon 理论上很牛,但在真正的万亿大模型上,谁也用不起来。
Kimi 是第一个把 Muon 强行按在万亿大模型上并证明有效的团队。他们在算法上打了很多极具价值的补丁。比如加入了防止死记硬背的机制(Weight Decay);加入了更聪明的惯性系统(Nesterov 动量),让收敛更快;搞定了参数兼容(RMS Rescaling)让 Muon 算出来的大小,可以直接套用原来 AdamW 的超参数,免去了重新调参的噩梦。
但是,Kimi 的论文没有教大家怎么彻底解决拼图散落一地(ZeRO)的工程绝症。他们在自己的系统里硬扛了过去,但没有给出一套标准答案。
DeepSeek-V4 在用 Muon 时候,就给出了一套收纳解决法,解决了这个问题。为了不让矩阵被切得太碎,DeepSeek 先设一个上限(比如最多切 8 份,而不是 64 份)。这样保证每个 GPU 上拿到足够大的一块,Muon 可以对这块做正交化。为了保证 8 份儿就能装下所有,DeepSeek 用了一套「背包算法」决定哪个参数矩阵放在哪张卡上。就像装行李箱,尽量把完整的小件装在一个箱子里,绝不把一件衣服剪成两半放两个箱子。最后稍微塞点填充物(Padding),保证所有箱子一样重(开销极小,不到 10%)。这样既省了内存,Muon 也能看到完整的局部矩阵。
Kimi 证明了 Muon 不是纸上谈兵;而 DeepSeek 给出了一份写满注释的实战说明书。
这两家中国顶尖 AI 公司的接力,完成了 Muon 优化器从一篇有趣的学术论文到工业级应用的跨越。
MegaMoE 的车间法则
让 GPU 不闲着,是 DeepSeek V3 里的一个拿手好戏。
在 V4 中,这个极致压榨 GPU 的模式被提升到了整个 MoE 的层级上。
MoE(混合专家模型)处理数据的五个标准步骤,第一步是 Dispatch(分发),即把流水线上的零件(Token/数据)分发给不同的专家医生或车间。后三步,Linear-1 → SwiGLU → Linear-2(加工),这三个是专家车间内部的具体加工步骤(神经网络的计算和激活)。最后一步,再 Combine(合并),把各个车间加工好的零件重新组装起来,送往下个环节。

以前,这 5 个步骤是各自独立的。每做完一步,工人都要把零件放回总仓库(GPU 显存),下一步的工人再去仓库拿。这种频繁的存取操作极其浪费时间,成了最大的性能瓶颈。
DeepSeek V4,Fusion Kernel,把这五个流程全塞进一个算子里,拆掉了这 5 个车间之间的墙。
现在,零件从进入 Dispatch 开始,就在一条无缝衔接的流水线上飞速流转,中途绝对不回总仓库,只在这个 Kernel 里进行。数据直接在 GPU 内部最快的高速缓存(SRAM/寄存器)里完成所有加工,最后一次性输出(Combine)。
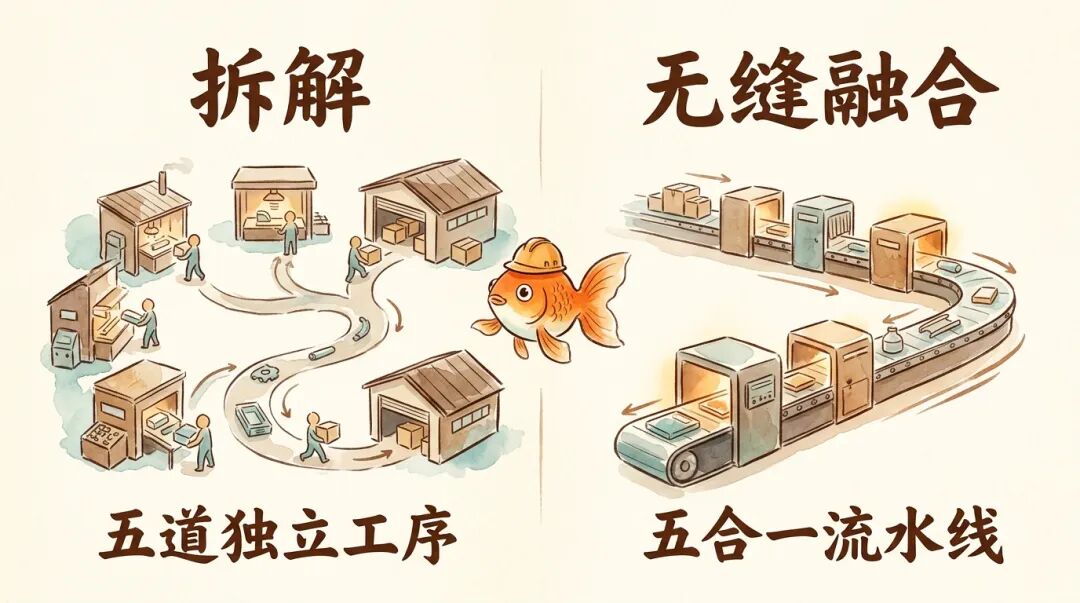
这是 MoE 架构优化中的圣杯,第一次被系统性地完美解决,从而实现了 1.92 倍的训练加速。
FP4 量化感知训练(QAT)
这也是 DeepSeek 在 V3 上工程的一个延续。他们在 V3 上测试的是 FP8,现在在 V4 上就开始测试 FP4。
FP 就是参数储存的位数。一个参数可以用不同位数表达,精度(FP)越高,储存的信息越多,但占据的空间和计算量也越大。
因此压缩 FP 就是减少计算量和存储量的一个非常好的手法。
但因为精度丢失,它并不适用于所有场景中,有的场景精度就很敏感,有的就不行。改在哪里省,得靠试。
但这需要一整套训练,让模型在低精度下也能学会做对事。
具体的做法,就是训练时就模拟 FP4 会带来的误差。让模型在训练过程中学会适应这种粗糙数值这样,最后真的部署成 FP4 时,掉点更少。
这就是说,不是考完试才把眼镜摘掉,而是平时训练就戴着一副低清眼镜,让你习惯在低清条件下工作。
和过去一样,在真正训练时,DeepSeek v4 通过 FP4-to-FP8 的方式复用已有 FP8 mixed precision 框架,同时保留 FP32 的参数。也就是说,不是所有训练计算都彻底 FP4,而是在关键路径上让模型适应 FP4 表示。
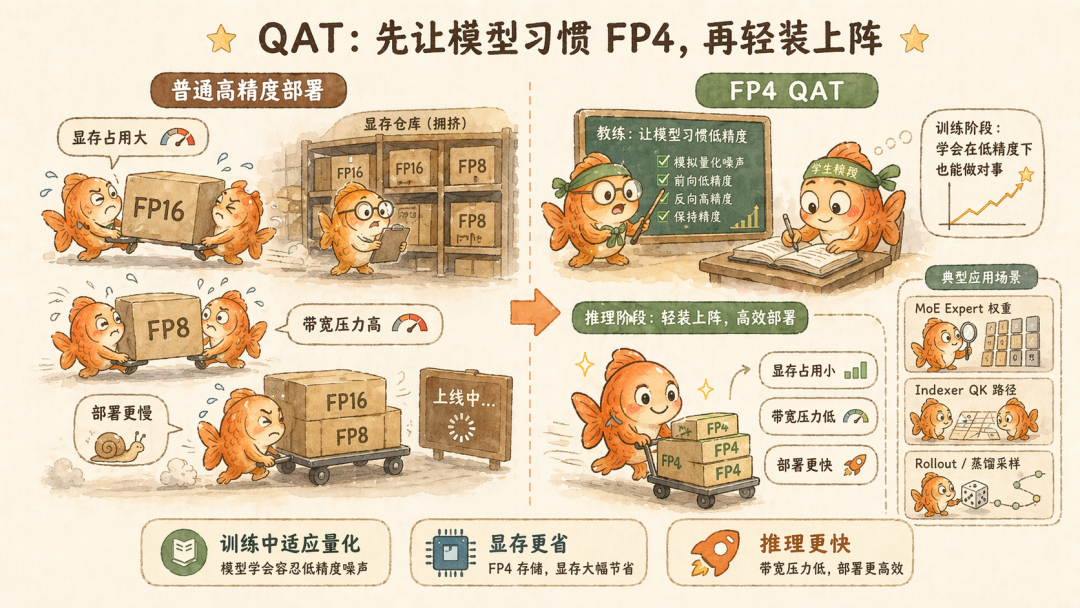
这次的 FP4,DeepSeek V4 主要用在了两个位置上。
MoE Expert 权重,在大规模混合专家架构中,MoE 的专家权重是占据 GPU 显存绝对大头的罪魁祸首。通过将路由专家参数量化为 FP4,模型在部署时的显存占用被成倍压缩。
Indexer QK 路径,还记得第一个范式更新中的压缩稀疏注意力(CSA)机制中有个闪电索引吗?DeepSeek 让这一步的 Query-Key (QK) 激活值完全在 FP4 精度下进行缓存、加载和矩阵乘法。这直接在超长上下文(如 1M token)场景下,大幅加速了注意力分数的计算。
在训练过程的 Rollout(采样)过程中,因为不用做梯度,DeepSeek V4 也用了原生 FP4。这大幅减少了内存加载负担,带来了实打实的加速和显存暴降。
尤其在上面提到 OPD 的全词表蒸馏阶段,由于需要同时跑十几个庞大的 Teacher 模型,FP4 量化极大地缓解了显存读写压力并降低了采样延迟。
可以说,FP4 是 OPD 能够落地的隐性前提。
看完技术文档,回来讲讲 DeepSeek 到底在做什么
在这个大模型赛道似乎已经高度同质化、当整个行业都在为了 Benchmark 上那零点几的百分点卷生卷死时,DeepSeek 到底在做一件什么事?
DeepSeek V4 用这 58 页的技术报告告诉我们的是,比起刷榜,他们更有兴趣选择冲击那些真正卡住下一代智能脖子的真问题。
而这其实已经变成了一种开源行业整体的趋势。当我们把视角拉宽,会发现其实很多中国顶尖 AI 力量在技术上做了类似的尝试和严谨的。
比如在后训练范式(如 OPD)的探索上,Qwen、智谱、小米都在持续投入,其中前两家已经通过相关路径有效缓解了模型在对齐过程中的通用能力遗忘,小米则和 DeepSeek 的路线高度一致;在构建类似 Rubic 的通用验证器系统上,智谱和小米也早有自己的尝试与布局;针对底层信息通路和残差结构的处理,字节跳动此前也提出过自己的一套解决方案;而在解决长文本算力与记忆瓶颈的维度上,月之暗面(Kimi)对于 Linear(线性注意力结构)的深刻探索,同样为整个行业在超长上下文的延伸上提供了极其宝贵的解法。
如果说 Test-Time Compute 的范式是由 OpenAI 率先开启,由 DeepSeek 领衔揭秘,造就了一时瑜亮。那么在今天的中国 AI 社区里,个个公司都已跨越了盲人摸象或单纯跟随的阶段,开始各自在核心难点上做出实质性的底层创新。
在这个百花齐放的生态中,DeepSeek 的独特之处,在于它展现出了一种极为系统化的工程魄力和深沉的技术品味。
它并非在哪一个单点上闭门造车,而是将这些散落在行业各处的探索方向,最深入、最彻底地统合进了一套切实可用的训练体系里。
从 V4 的这 58 页技术报告中,我们清楚地看到,DeepSeek 的技术选择始终有一条清晰的主线。它没有哪里热就去追哪里,而是围绕着未来的长视野智能体、深层因果推理以及极限算力效率,量身定制了一套完整的基础设施路线图。
这大概就是在这个周期里,中国开源行业最让人兴奋的地方。创新的红利不再只属于某一家公司,而是化作了整体赛道的共同进步。
而 DeepSeek,依然是这场集体进阶中,把长期主义和系统性思考践行得最透彻、也最优雅的之一。
 发表于 2026-4-27 19:01:14
|
查看: 210|
回复: 0
发表于 2026-4-27 19:01:14
|
查看: 210|
回复: 0
