等了整整 15 个月,DeepSeek 终于交作业了。
从去年 1 月 R1 爆火之后,DeepSeek 安静了很久。中间虽然有过 V3.2 的小更新,但真正的下一代旗舰,一直没有正式交卷。市场等了一轮又一轮,从 2 月传到 3 月,又从 3 月等到 4 月。
这段时间里 OpenAI 发了 GPT-5.5,Anthropic 迭代到了 Opus 4.7,Google 推了 Gemini 3.1 Pro,竞争对手一个没闲着。
就在今天,DeepSeek V4 预览版正式上线,同步开源,MIT 协议。
还是那个 DeepSeek,还是一分钱不收地把模型权重全部放出来,商用零门槛。

先看几个硬指标。
- V4-Pro 总参数量 1.6 万亿,每个 token 激活 49B 参数,采用 MoE 架构。
- V4-Flash 是 284B 总参、13B 激活,定位更轻量,也更偏高效使用。
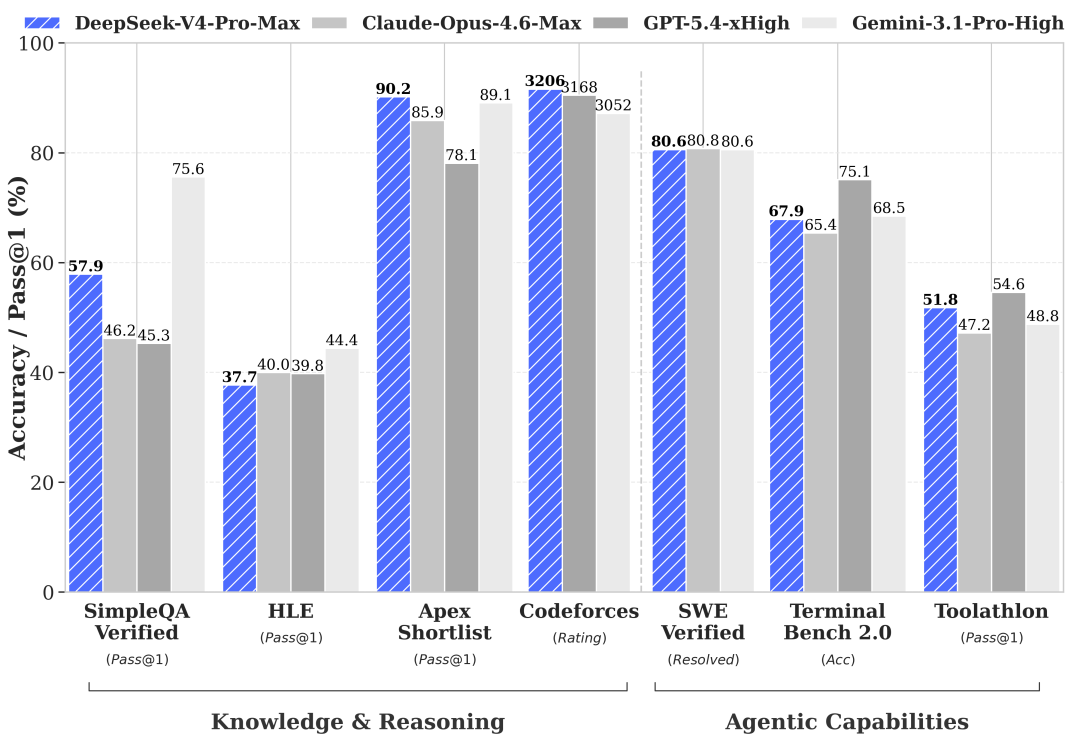
在跑分方面,DeepSeek-V4-Pro 的多项指标已经接近甚至追平当前顶尖闭源模型。
价格呢?Pro 输入 12 元、输出 24 元每百万 token,比海外闭源模型便宜了大概 60% 到 80%。
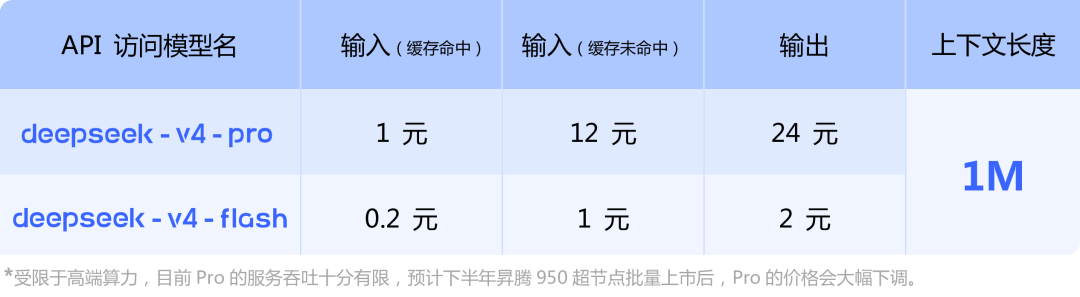
定价页面底部写了一行小字:受限于高端算力,Pro 目前的吞吐还比较有限。等下半年昇腾 950 超节点批量上市后,价格还会继续下调。
也就是说,现在看到的价格,大概率还不是最终态,后续一起期待一下。
但这次 V4 最让我兴奋的,不是参数量,而是百万 token 上下文成了标配。
Pro 和 Flash 都是 1M 上下文,不是高端付费版才有的特权,是所有用户的基础能力。
这个含金量有多高?
过去很长一段时间里,百万级上下文几乎都是顶级闭源模型的专属能力。别的厂商拿百万上下文当卖点,锁在最贵的版本里。DeepSeek V4 呢?Pro、Flash 全系 1M,直接给到每一个用户。曾经的顶配能力,现在是起步配置。
百万上下文对编程场景的意义尤其大。
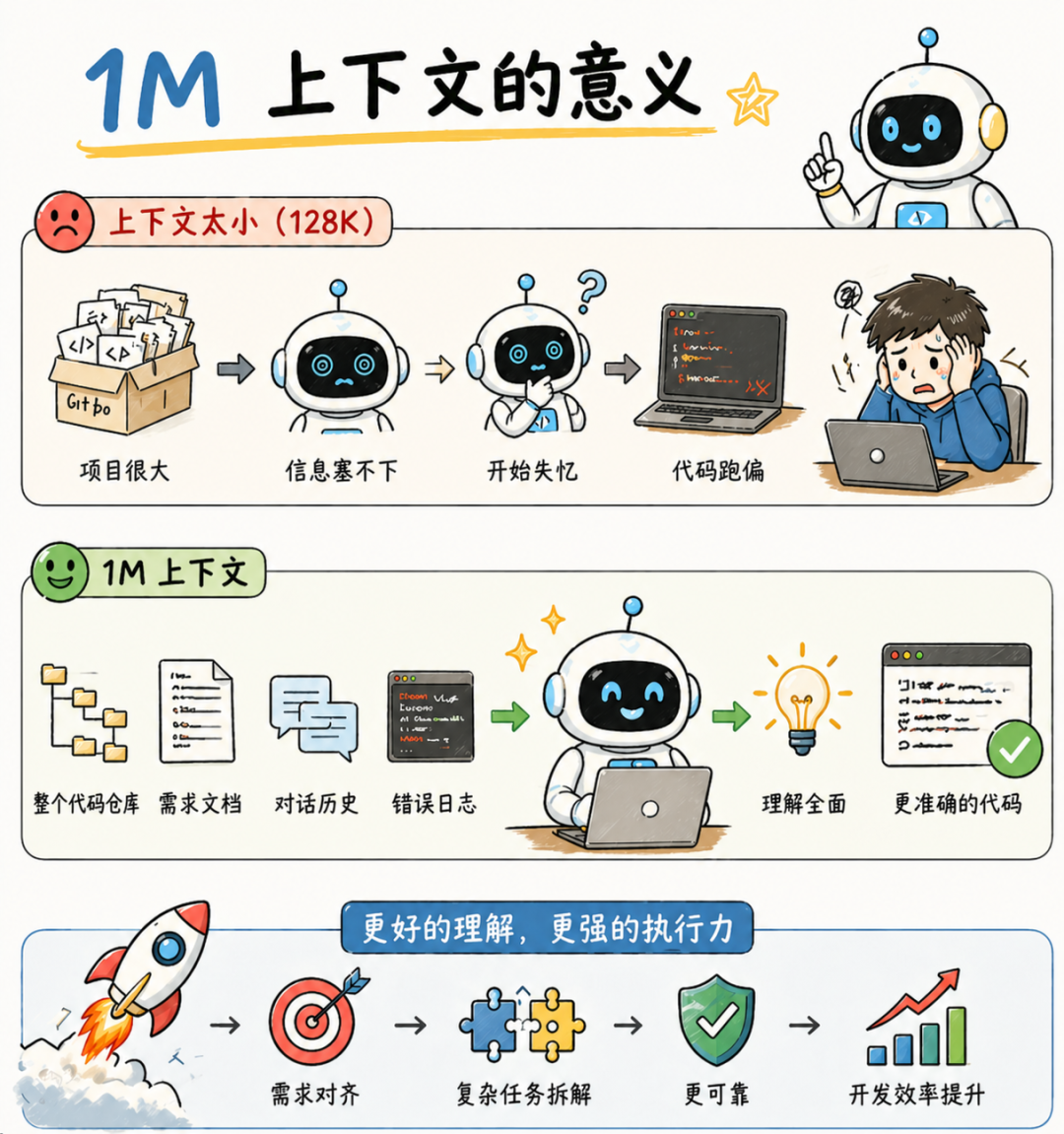
做过大项目的开发者都知道,真实的编码场景里,上下文消耗极快,项目结构、多文件依赖、之前的修改历史、错误日志,这些全部塞进去,128K 根本不够用。
上下文一旦溢出,模型就开始失忆,前面讲的需求后面就忘了,改着改着代码就跑偏了。
有了百万上下文,你可以把整个代码仓库、完整的需求文档、所有的对话历史一次性喂给模型,让它在完整的信息环境下工作。这对 Agentic Coding 来说,是真正的基础设施级升级。
说到 Agentic Coding,官方给出的说法是,DeepSeek 内部员工已经在用 V4 做 Agentic Coding。体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 的非思考模式。
它在 Arena 榜单上也往前冲了一大截。这个排名还是有含金量的,Arena 是真实用户盲测打分,基本没有刷榜空间。
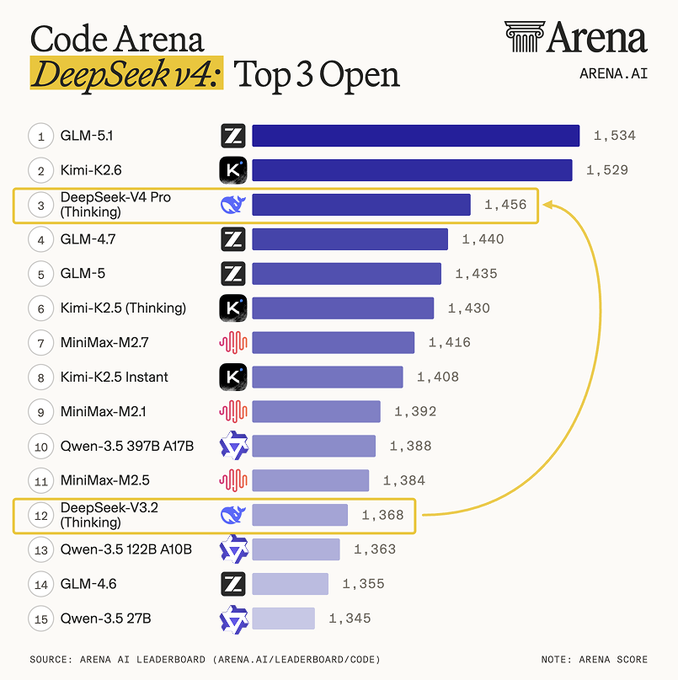
刚好,我 4 月初实测 GLM-5.1 的时候就很不错,那也是一个国产开源模型的代表。GLM-5.1 目前也是在 Arena 代码排行榜稳居第一。
所以 V4 一发布,我第一反应就是:把它和 GLM-5.1 拉到一起,在完全相同的条件下,正面对决一把。
GLM 走 Coding Plan,DeepSeek 走 API 挂进 Claude Code。我准备了四个案例,难度从中到高,看看它们的真实表现。
先给出我的 Claude Code 文件配置:
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "your-api-key",
"ANTHROPIC_BASE_URL": "https://api.deepseek.com/anthropic",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-v4-flash",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "deepseek-v4-pro",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "deepseek-v4-pro",
"ANTHROPIC_MODEL": "deepseek-v4-pro",
"ANTHROPIC_REASONING_MODEL": "deepseek-v4-pro",
"CLAUDE_CODE_ATTRIBUTION_HEADER": "0",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1"
},
"model": "opus[1m]",
"skipDangerousModePermissionPrompt": true
}
"model": "opus[1m]" 这个配置非常重要,不然是无法体验到 1M 上下文窗口的。
案例一:3D 象棋
首先我想他们做一个可以对弈的 3D 象棋,我提前写了一个 prd.md。

这个案例考验的是 AI 的复杂前端工程能力,尤其是三维空间理解、Three.js 框架落地、状态管理和规则推理能力。它不只是画出一个 3D 棋盘,还要让棋子能按象棋规则正确移动,并支持视角旋转、缩放和人机交互。
首先是 DeepSeek 做的效果:
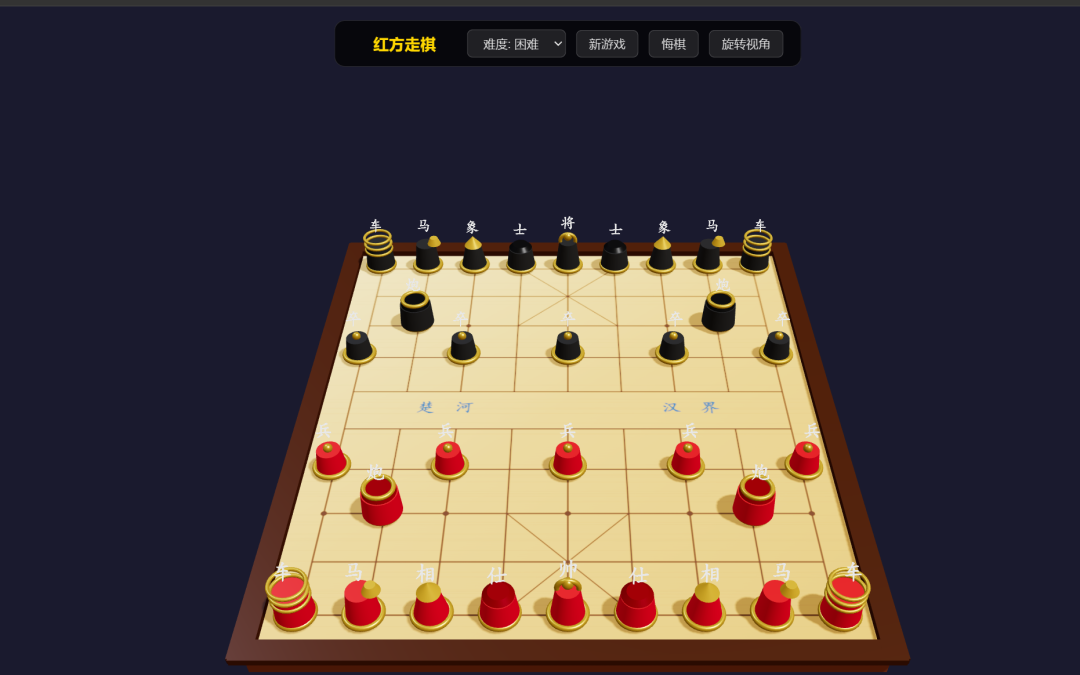
额,效果有点一言难尽,没有理解中国象棋到底应该是啥样子,开始一看我以为是国际象棋呢,但是又看到了楚河-汉界,整体棋盘是对的,但是棋子错得有点厉害了。
我也只能让 DeepSeek 继续优化了。
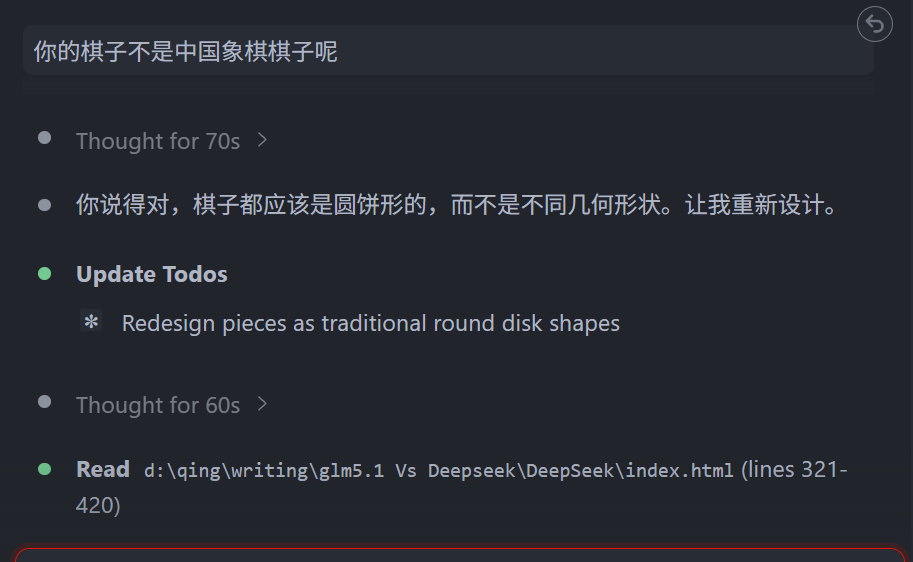
现在的效果还行了,但是我发现... 棋子压根下不出去。
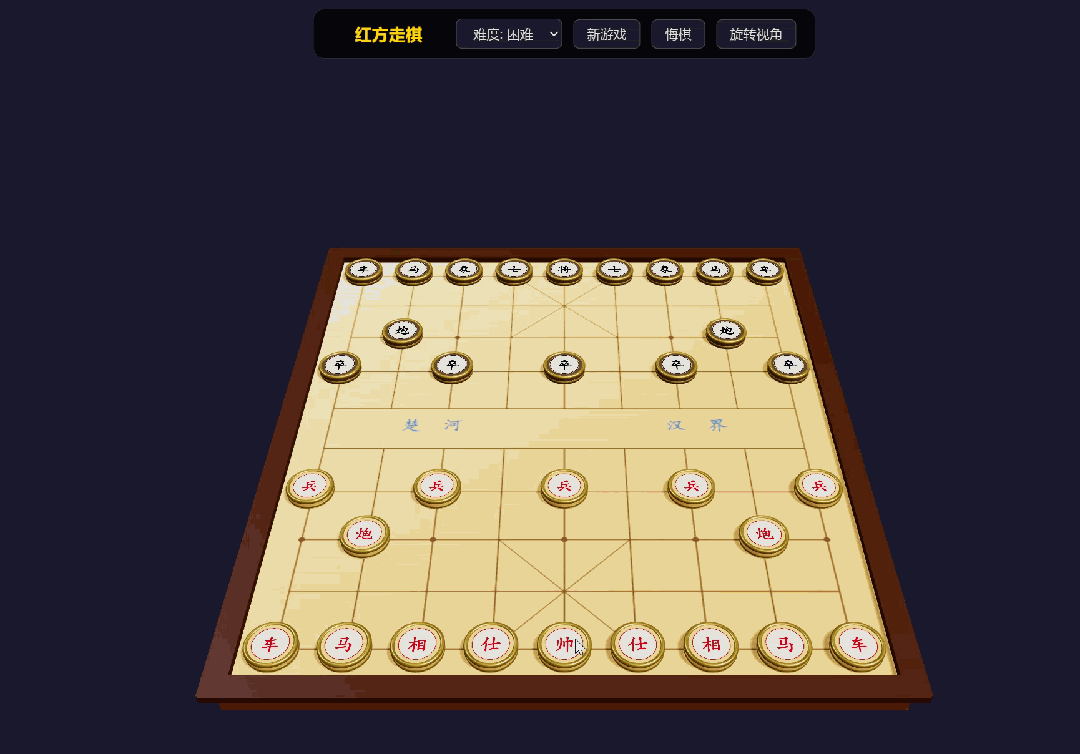
然后我把问题反馈给 DeepSeek,它又修了两轮,最终都以失败告终。
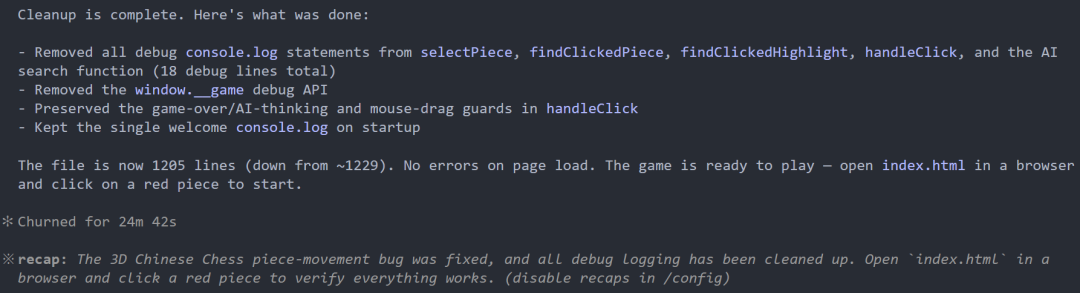
最终效果就是只能看、无法下的棋盘了。
然后是 GLM-5.1,同样的提示词,效果如下图:

初次提示词执行,除了象棋朝向错了外,其他看起来都比较符合我心意。我和 GLM5.1 对话几轮后,就是一个真正能上手的小游戏了。
DeepSeek 的前端能力还是比较差,反观 GLM 在象棋这个案例表现上非常出色。
案例二:氛围沉浸式网页
之前我在网上看到一个氛围感很强的网页,这里我也把同样的提示词交给它们,看看各自的成品。
Prompt:
你是一个精通 GLSL 与高阶交互美学的视觉专家,请帮我创建一个具有以下功能的氛围沉浸式编辑器,用户可以进入这个页面后自由上传背景图片或视频,画面叠加计算图形学专家在 Shadertoy 发布的《Heartfelt》的雨滴效果,请深刻理解该作品的 shader 技术,并还原仿佛雨水真实地附着在观者与世界之间的玻璃表面的核心体验,复现雨滴在停留、汇聚、滑落之间不断变化。保留一个可调节雨滴效果的极简操作台,初始状态为一个悬浮图标,允许用户调节雨势、雾气与折射率等参数。默认背景为双色的渐变流体,设置一个按钮让用户可以自由上传一张图片或视频替换背景。
GLM-5.1 在这个案例上的表现确实让人眼前一亮,这个雨滴效果太真实了,配上我上传的视频,效果绝了。

它真正理解了 Heartfelt 这个作品的核心:雨水附着在玻璃表面,停留、汇聚、缓慢滑落,背景透过湿润的玻璃被折射和模糊。
整个画面有很强的玻璃介质感,水痕的轨迹在不断动态变化,配合城市实景背景,氛围感拉满了。需求里说的那句「仿佛雨水真实地附着在观者与世界之间的玻璃表面」,GLM 完全做到了。
然后是 DeepSeek 做的效果,我这里专门配了 DeepSeek 的图标,整体视觉上还是不错的。

这种效果,配上这句话:「不诱于誉,不恐于诽,率道而行,端然正己」。可以说意境感拉满了!
这个案例比较吃 Shader 和图形学的知识储备,GLM-5.1 在这个维度上的理解更深入一些。两个模型给出了两种不同风格的答卷,整体上来说,我觉得 GLM-5.1 略胜一筹。
案例三:向量数据库
接着,我想再考一考它们的底层工程能力。向量数据库是个很适合的题目,它不只考代码生成,还会考模型对数据结构、索引、召回、存储和接口设计的理解。
我给两个模型下了同样的任务,然后等它们分别交卷。
我们再用 GLM-5.1 写个向量库性能对比平台,对比下他俩的性能。
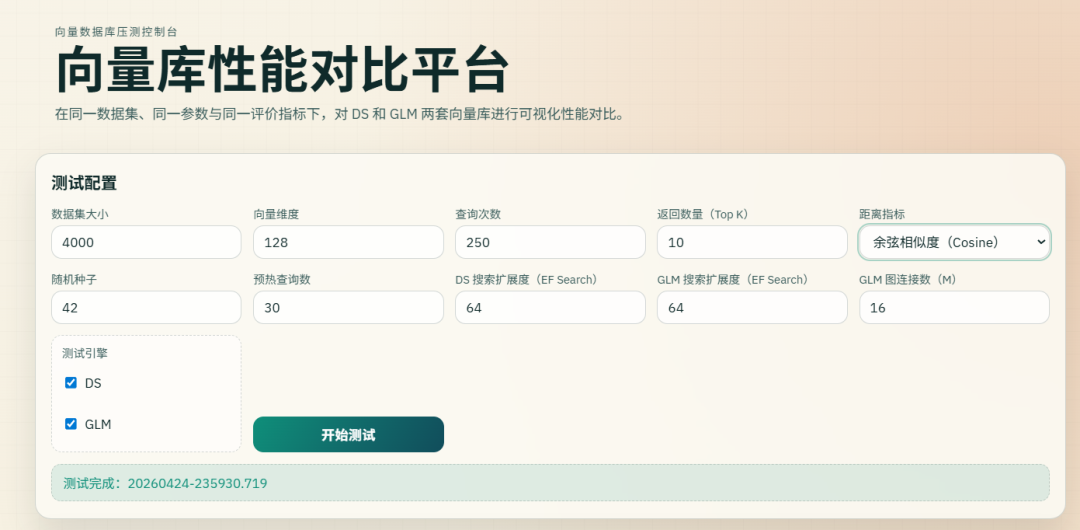
同一套数据和参数下,同时跑 DeepSeek 和 GLM 实现的向量数据库,我们先看看对比。
下面用 DS 和 GLM 代指他们实现的向量数据库

两套引擎的吞吐能力:上半部分看写入,DS = 618.52 ops/s,GLM = 462.03 ops/s,说明 DS 写入更快;下半部分看检索,DS = 917.11 ops/s,GLM = 1019.27 ops/s,说明 GLM 查询更快。
我还做了一个 P50、P95、P99、召回率的对比,可以看到最终 GLM 还是更占优一些。

最后看看总结。
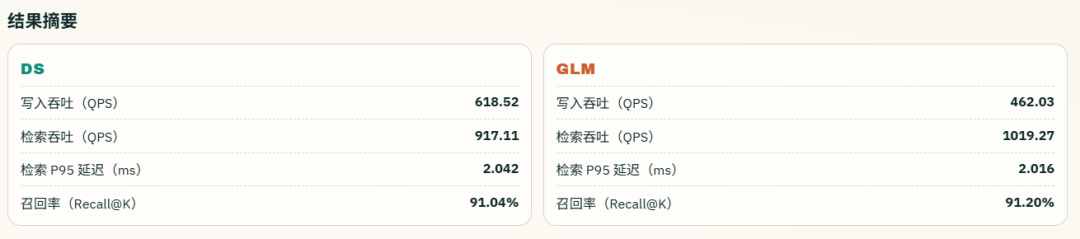
DS 的写入更猛,GLM 的检索更强,而且检索 P95 延迟更低一点,召回率也略高。
从实际业务看,向量库大多是检索远多于写入,真正影响体验的是查询吞吐、延迟和召回率。按这个主流使用场景来评估,GLM 的实现在检索侧表现更优,所以整体设计可以认为更好、更贴近实战需求。
案例四:小红书 Agent
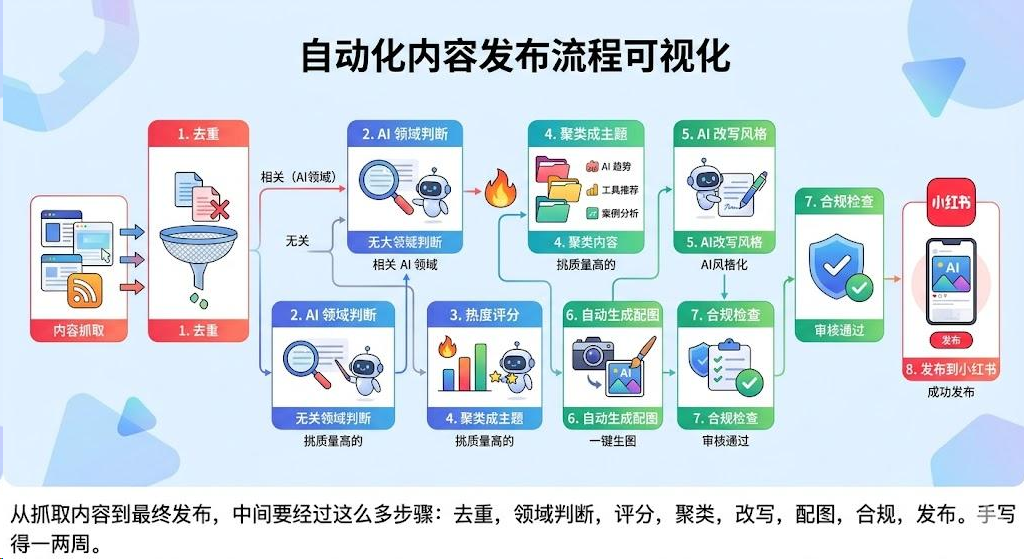
最后我想起来之前,还用 GLM-5.1 做过一个小红书一键爆款 Agent。从抓取内容到最终发布,中间要经过这么多步骤:
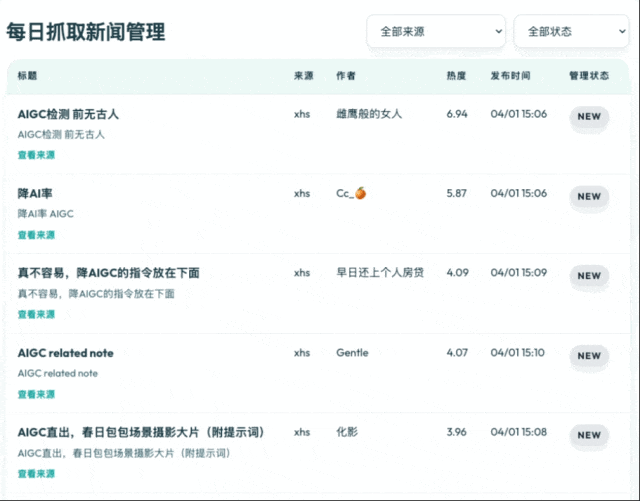
先带大家回顾上次 GLM-5.1 做的效果,首先是抓取到新闻放在管理页。
最后生成的图文库存页面,我们只需要去看看哪些需要发布的,点击发布就可以了。

那么我们也可用 DeepSeek V4-Pro 去实现下相同的功能,和 DeepSeek VibeCoding 1 小时总算做完了。
因为我的 Token 不多了,所以 Agent 实际运行时用的是 GLM 的 Coding Plan(仅运行环节,代码本身仍由 DeepSeek 生成)。

最后出来的结果,我们看看,功能也是一应俱全,就是界面没有 GLM 做得好看。
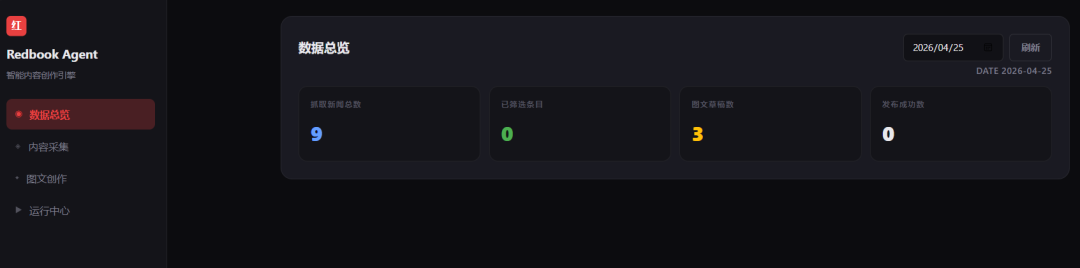
开始执行任务,完美完成,日志也非常清晰可见。
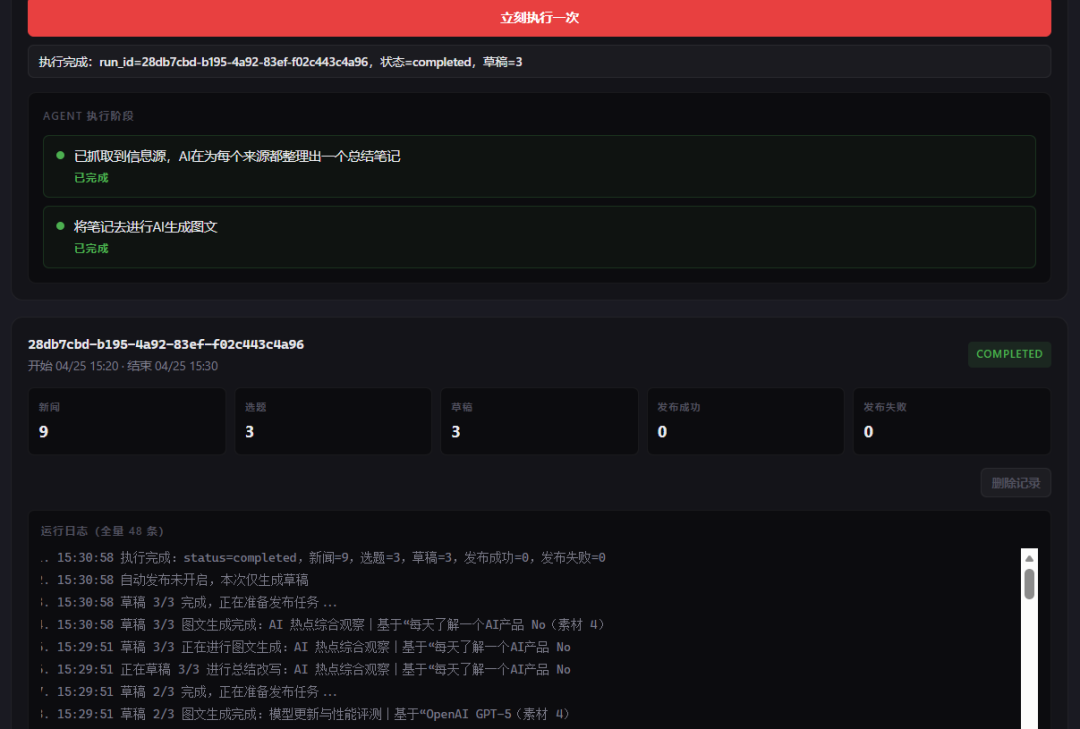
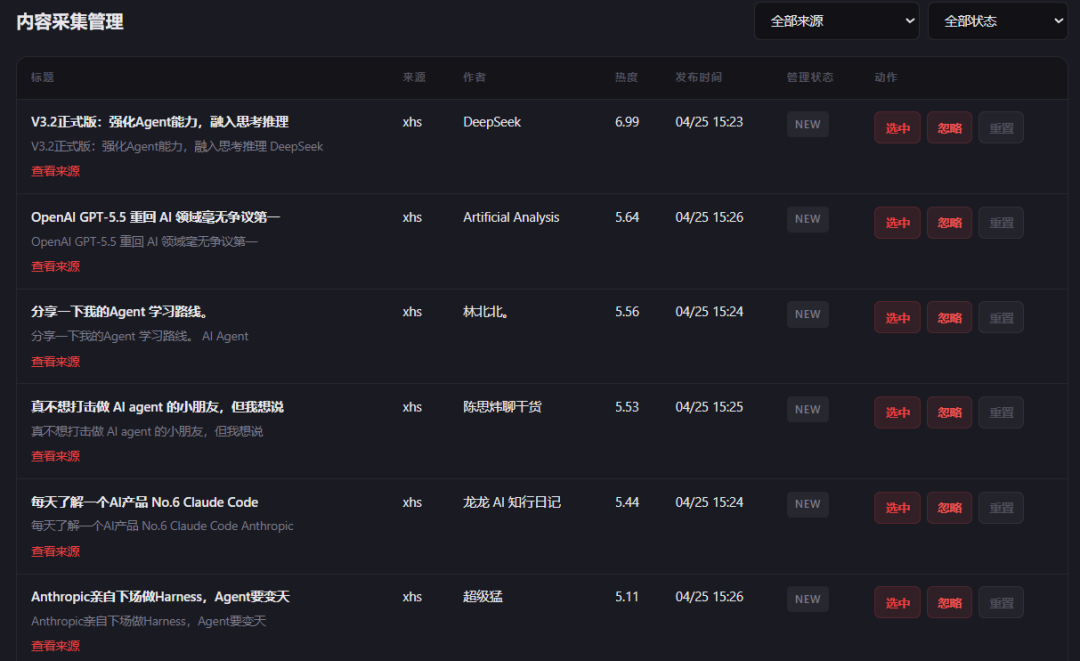
内容采集页面没问题,标题、来源、作者、热度等等都有了。
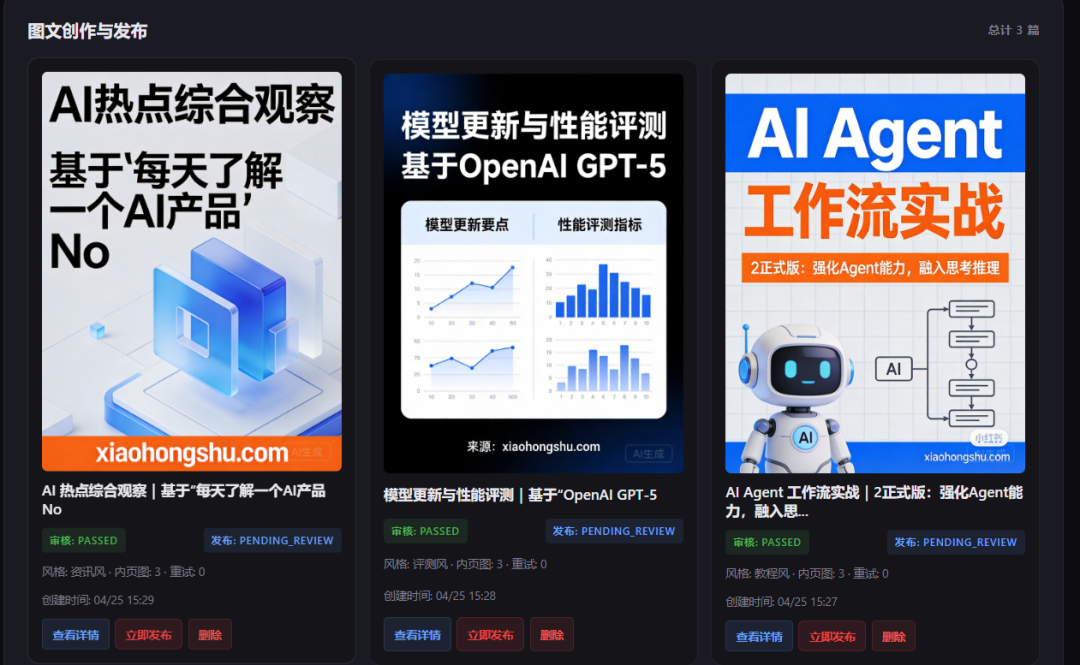
图文生成后也是一样都放在了库存页面,我们点击发布看看。
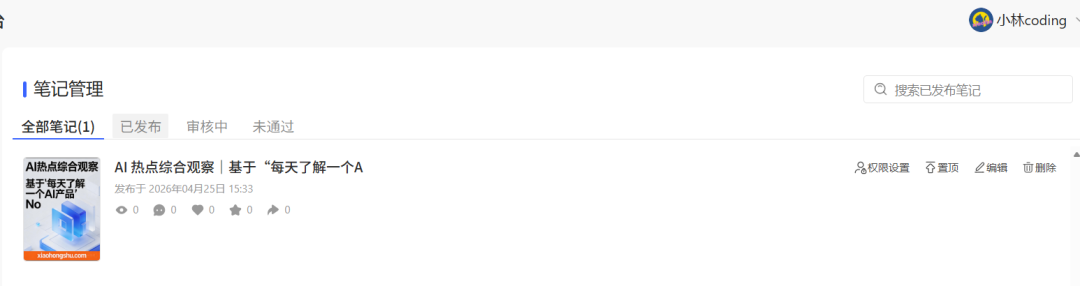
成功发布了,整个流程算是真正闭环了。
总的来说,两个模型都能把这个实用的 Agent 做出来,确实是国产之光。如果非要分个高下,GLM 的界面设计更有美感,整体完成度更高;而 DeepSeek 在过程中需要我多花几轮去指导和纠正,才最终把功能做完整。
一些感受
这次测评做下来,我最大的感受是:DeepSeek V4 是一次扎实的迭代,但还不是那种让人 Wow 的时刻。
15 个月的等待,开源、MIT 协议、百万上下文标配,这些都值得肯定。尤其是 1M 上下文真的好用,整个测评过程中几乎没遇到上下文压缩的问题,这在以前是不敢想的。
但落到实际编码场景,体感和跑分之间还是有落差。前端工程能力偏弱,象棋案例里棋子渲染出错、交互逻辑跑不通,反复修了几轮也没救回来。Shader 那道题交出了不错的视觉答卷,但和 GLM-5.1 相比,还是差了一口气。向量数据库的底层工程题,DS 写入快、GLM 检索强,各有所长,但考虑到向量库读多写少的实际场景,GLM 的实现更贴近生产需求。
四个案例跑下来,结论和 Arena 榜单的排名基本吻合,DeepSeek V4 目前确实还落后于 GLM-5.1。
最后,四个案例我根据主观感受,包含期间的 Coding 体验打一个分(满分 5 星)。

我和大多数人一样,对 DeepSeek 有期待,也有感情。但评测就是评测,花了真金白银的 Token,该说的还是得说。
好消息是,V4 还只是预览版,等昇腾 950 上量、吞吐打开之后,后续还有优化空间。
DeepSeek V4 的基建能力(开源、长上下文、低价格)依然领先,但模型的实际编码表现,尤其是复杂前端和图形学场景,还需要再磨一磨。期待正式版。
在云栈社区,我们也会持续关注这种前沿模型在智能 & 数据 & 云领域的实际落地表现,毕竟从数据处理到底层算力调度,每个环节都直接影响最终开发体验。像这种工程级的横向对比,正是我们最关心的——到底哪家模型在真实的后端 & 架构场景里更能打,才是开发者选型的硬指标。
完,我们下次见!
 发表于 2026-4-27 20:54:20
|
查看: 201|
回复: 0
发表于 2026-4-27 20:54:20
|
查看: 201|
回复: 0
