很多人问我,Linux 进程上下文切换,内核到底在忙啥?
说真的,这玩意确实是面试必问,线上出问题十有八九也和它沾边,但很多人背了无数遍流程,真到啃源码、查 bug 的时候,还是两眼一抹黑。
一、内核切换的指挥官 context_switch
进程切换说白了就两件事。第一件,把新进程的内存映射给换上,说白了就是换页表。第二件,把内核栈和 CPU 寄存器的状态,全给换成新进程的(换寄存器状态 + 内核栈指针)。就这两件事,看着简单,我估摸着有80%的人不懂。
在 Linux 内核里,这俩活儿全塞进了 context_switch 这个函数。用户空间那部分靠 switch_mm,内核栈和寄存器靠 switch_to。
我第一次看这段代码的时候,脑子里全是问号:为啥要分这么细?为啥判断 next->mm 是不是空?
后来才反应过来——内核线程和普通用户进程待遇不一样,内核线程没有用户地址空间啊!它的 mm_struct *mm 就是 NULL。
那内核线程跑的时候用谁的页表?用前一个进程的 active_mm(其实就是借用)。这在操作系统里,其实就涉及到了 计算机基础 里关于内存管理与进程隔离的核心设计思想。
/*
* context_switch - 切换到新进程的内存地址空间和寄存器状态
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
/* 进程切换前的准备工作,架构相关的前置处理、调度器状态更新全在这 */
prepare_task_switch(rq, prev, next);
/*
* 半虚拟化相关的钩子,ARM上基本是空实现,不用太纠结
* x86上主要是把页表重载和切换后端合并成一个hypercall
*/
arch_start_context_switch(prev);
/*
* 这里是整个函数的核心分支,别死记硬背,就记4种场景:
* 内核线程 -> 内核线程 | 用户进程 -> 内核线程
* 内核线程 -> 用户进程 | 用户进程 -> 用户进程
*/
if (!next->mm) { // 要切到的是内核线程,它没有自己的用户地址空间
enter_lazy_tlb(prev->active_mm, next); // 进入懒TLB模式,ARM里默认是空实现
next->active_mm = prev->active_mm; // 内核线程直接蹭前一个进程的active_mm
if (prev->mm) // 前一个是用户进程,要给内存描述符的引用计数+1
mmgrab(prev->active_mm);
else // 前一个也是内核线程,把它的active_mm清掉,防止野指针
prev->active_mm = NULL;
} else { // 要切到的是用户进程,有独立的mm_struct
membarrier_switch_mm(rq, prev->active_mm, next->mm); // 内存屏障,保证membarrier系统调用的时序正确
/*
* sys_membarrier要求在设置rq->curr和返回用户态之间,必须有一个smp_mb()
* 下面的switch_mm_irqs_off会提供这个屏障;如果前后进程mm相同,finish_task_switch里的mmdrop也会提供
*/
// 核心!切换用户地址空间,ARM没实现专属的switch_mm_irqs_off,最终调用的就是switch_mm
switch_mm_irqs_off(prev->active_mm, next->mm, next);
if (!prev->mm) { // 前一个是内核线程,记录之前的active_mm,后面要释放引用
/* 这个mm的引用释放,会在finish_task_switch()里通过mmdrop()完成 */
rq->prev_mm = prev->active_mm;
prev->active_mm = NULL;
}
}
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
prepare_lock_switch(rq, next, rf);
/* 前面换完了内存地址空间,这里才是真正切换寄存器状态和内核栈! */
switch_to(prev, next, prev);
barrier(); // 编译器屏障,防止乱序,保证switch_to之后的代码一定在切换完成后执行
// 收尾工作,释放前一个进程的mm引用,处理调度器的剩余状态
return finish_task_switch(prev);
}
是不是看着分支有点绕?没事,我当年也绕了好久。
内核线程永远跑在内核态,根本用不到用户地址空间,所以内核线程没有自己的 mm,所以它借用上一个进程的 active_mm。从用户进程切到内核线程时,要 mmgrab 增加引用计数;反过来从内核线程切到用户进程时,就把 prev_mm 记下来,后面 finish_task_switch 里再 mmdrop。要是前一个也是内核线程,一定要把它的 active_mm 清掉,不然引用计数乱了,内存泄漏都是轻的,严重的直接 panic。
我以前写用户态代码的时候,从来没想过内核线程这么“寄生”。现在想想,调度器得时刻记得谁在用哪套页表,这活儿真不轻松。
二、内存管理机制:switch_mm
用户进程切换内存空间,主要靠 switch_mm(或者 switch_mm_irqs_off,x86 有专门实现,ARM 暂时没)。ARM 上,这本质就是把新进程的页表基址写进 TTBR0 寄存器。
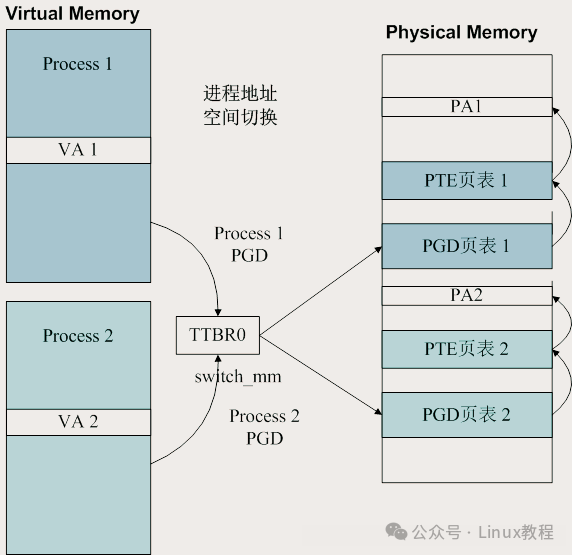
每个进程都有自己一套完整的虚拟地址空间,但物理内存是共享的。PGD(页全局目录)是最高层,下面是 PTE,最终指向物理页。不同进程的 PGD 不一样,所以地址空间天然隔离。
ARMv7 里,switch_mm 长这样(我只把关键部分贴了出来):
static inline void switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
#ifdef CONFIG_MMU
unsigned int cpu = smp_processor_id();
if (cache_ops_need_broadcast() && !cpumask_empty(mm_cpumask(next)) &&
!cpumask_test_cpu(cpu, mm_cpumask(next)))
__flush_icache_all(); /* 刷新CPU Core所有I-cache */
if (!cpumask_test_and_set_cpu(cpu, mm_cpumask(next)) || prev != next) {
check_and_switch_context(next, tsk);
if (cache_is_vivt())
cpumask_clear_cpu(cpu, mm_cpumask(prev));
}
#endif
}
先处理 I-cache。ARM 是哈佛架构,I-cache 和 D-cache 分开。当进程第一次被调度到某个核上,得把 I-cache 全刷掉,不然可能执行到旧指令。我以前在多核调试的时候,遇到过诡异的“代码没变但行为变了”的 bug,现在回想,可能就是 I-cache 没刷干净。
2.1 别让 I-Cache 拖后腿
在 ARM 世界里,switch_mm 的核心任务就是 改写 TTBR0(Translation Table Base Register 0)。这玩意儿就像是内存管理单元(MMU)的“导航仪”,指定了页全局目录(PGD)在哪儿。
但是,直接改 TTBR0 会出事吗?其实还有个更头疼的问题——缓存。
为啥切换进程还要刷新 I-Cache(指令缓存)呢?
原因很简单:哈佛结构。在 ARM SMP 架构里,L1 缓存分成了独立的指令缓存(I-Cache)和数据缓存(D-Cache)。
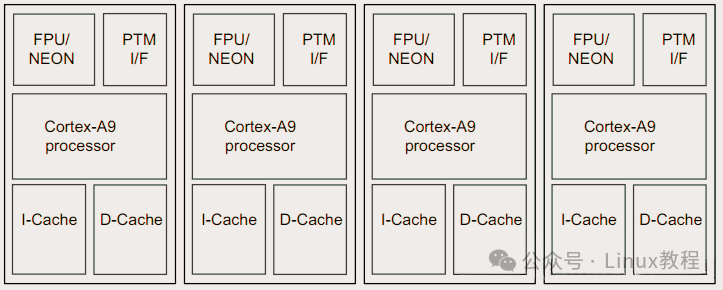
如果一个进程从 CPU A 迁移到了 CPU B,CPU B 的 I-Cache 里可能还留着旧数据,这能行吗?
不用担心,switch_mm 里有个骚操作:
static inline void switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
#ifdef CONFIG_MMU
unsigned int cpu = smp_processor_id();
/*
* 如果 next 进程刚迁移到这个 CPU,并且硬件需要广播 I-Cache 失效,
* 就把整个 I-Cache 炸掉。
*/
if (cache_ops_need_broadcast() &&
!cpumask_empty(mm_cpumask(next)) &&
!cpumask_test_cpu(cpu, mm_cpumask(next)))
_flush_icache_all(); // 这条指令会通过 CP15 的 c7 寄存器干掉 I-Cache
/* 把当前 CPU 设置到 next 的 cpumask 里,表示这个进程现在也在这个核上跑过 */
if (!cpumask_test_and_set_cpu(cpu, mm_cpumask(next)) || prev != next) {
check_and_switch_context(next, tsk); // 核心:处理 ASID + 切 TTBR0
if (cache_is_vivt())
cpumask_clear_cpu(cpu, mm_cpumask(prev));
}
#endif
}
_flush_icache_all 在 ARMv7 SMP 上实际执行的是:

#define __flush_cache_all_v7_smp() asm("mcr p15, 0, %0, c7, c1, 0" :: "r"(0))
MCR p15, 0, r0, c7, c1, 0 → CP15 协处理器的 c7, c1, 0 组合就是 ICIALLUIS(Inner Shareable 指令缓存全局失效)。

这就像给 CPU 下达了一个死命令:“把你的指令缓存全给我倒了,重新来!”
第一次看到这操作的时候我觉得:这也太暴力了吧?
但没办法,不暴力就会跑飞。
2.2 ASID 和 TLB:为啥 ARM 只给了 8 位?
TLB(快表),大家都知道它是为了加速地址转换的。但以前的 ARM 架构有个大毛病:进程一切换,TLB 就得全清。这就好比每次换台电视,都要把之前的记忆全抹掉,重新搜索信号,那速度能快吗?
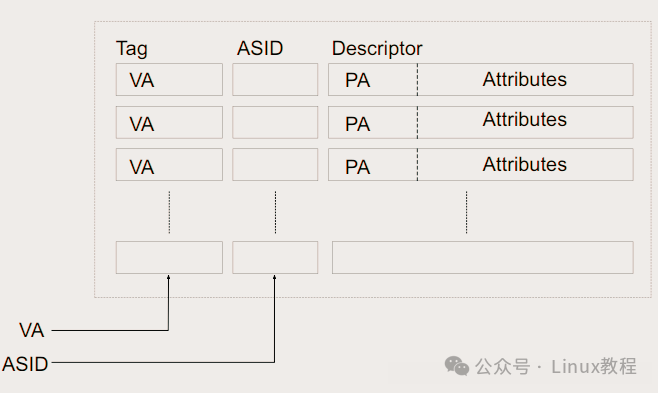
为了解决这个问题,ARM 引入了 ASID(Address Space ID)。
ASID 只有 8 位,这意味着最多只能有 256 个独立的 ID。它是怎么玩的呢?
它把 TLB 分成了两类:
- Global:属于内核的,谁来都不变(nG位为0)。
- Process-specific:属于用户的,靠 ASID 来区分。
这样一来,进程 A 和进程 B 的 TLB 项因为 ASID 不同,根本不会打架。切换进程时,只要换个 ASID,旧的 TLB 项依然有效!这设计,真的绝了。
不过,8 位 ID 总有发完的时候。这时候就得触发 ASID 溢出机制,重新分配 ID 并刷新 TLB。这算是这个机制唯一的“阿喀琉斯之踵”吧。
来看这个切换的核心逻辑:
void check_and_switch_context(struct mm_struct *mm, struct task_struct *tsk)
{
unsigned int cpu = smp_processor_id();
u64 asid;
/* * 因为更新页表基址和 ASID 没法做到原子操作,
* 所以咱们得先切到一个临时的保留状态,防止在这个间隙出岔子 [cite: 612, 622, 626]。
*/
cpu_set_reserved_ttbr0();
asid = atomic64_read(&mm->context.id); /* 拿出现在进程的 ASID [cite: 613, 627] */
/* 如果号没溢出,万事大吉,走快车道直接切 [cite: 614, 628, 630] */
if (!((asid ^ atomic64_read(&asid_generation)) >> ASID_BITS)
&& atomic64_xchg(&per_cpu(active_asids, cpu), asid))
goto switch_mm_fastpath;
/* 号不够用了?那就得加锁重分配,还得刷一遍 TLB 和分支预测器 [cite: 615, 631, 642, 643] */
raw_spin_lock_irqsave(&cpu_asid_lock, flags);
asid = new_context(mm, cpu);
atomic64_set(&mm->context.id, asid);
local_flush_bp_all();
local_flush_tlb_all();
raw_spin_unlock_irqrestore(&cpu_asid_lock, flags);
switch_mm_fastpath:
cpu_switch_mm(mm->pgd, mm); /* 真正去改页表基址寄存器 TTBR0 [cite: 649] */
}
local_flush_tlb_all 在 ARMv7 里实际是这条协处理器指令:
static inline void local_flush_tlb_all(void)
{
const int zero = 0;
const unsigned int __tlb_flag = __cpu_tlb_flags;
if (tlb_flag(TLB_WB))
dsb(nshst);
__local_flush_tlb_all();
tlb_op(TLB_V7_UIS_FULL, "c8, c7, 0", zero);
if (tlb_flag(TLB_BARRIER)) {
dsb(nsh);
isb();
}
}
展开 tlb_op => mcr p15, 0, r0, c8, c7, 0 CRn=c8,opc1=0,CRm=c7,opc2=0 → 查 ARM 手册就知道这是 TLBIALL,统一 TLB 无效化。也就是说一旦 ASID 用光,所有进程的 TLB 条目一起陪葬——性能会抖一下,但至少不会错。

三、 switch_to
前面都在说用户空间地址切换,但真正让 CPU 执行流的“灵魂”转移的,是 switch_to。
先复习下 switch_to 的宏定义,很多人搞不懂为啥要传三个参数,prev、next、prev。
#define switch_to(prev,next,last) \
do{ \
__complete_pending_tlbi(); \
last = __switch_to(prev,task_thread_info(prev), task_thread_info(next)); \
} while (0)
这里的核心是 __switch_to,纯汇编实现,也是整个进程切换的最终落脚点。
它把前一个进程(prev)的 CPU 寄存器状态保存起来,然后把下一个进程(next)之前保存的寄存器状态恢复出来,包括栈指针 sp 和程序计数器 pc。等 pc 寄存器被换成 next 进程的值,CPU 接下来就会执行 next 进程的指令,进程切换就彻底完成了。
ENTRY(__switch_to)
UNWIND(.fnstart )
UNWIND(.cantunwind )
@ 入参:
@ R0:prev进程的task_struct
@ R1:prev进程的thread_info
@ R2:next进程的thread_info
add ip, r1, #TI_CPU_SAVE @ ip寄存器 = prev进程thread_info里cpu_context的地址
@ 把prev进程的r4-sl、fp、sp、lr寄存器,保存到prev的cpu_context里
ARM( stmia ip!, {r4 - sl, fp, sp, lr} )
THUMB( stmia ip!, {r4 - sl, fp} )
THUMB( str sp, [ip], #4 )
THUMB( str lr, [ip], #4 )
@ 把next进程的TLS线程本地存储指针读到r4、r5里
ldr r4, [r2, #TI_TP_VALUE]
ldr r5, [r2, #TI_TP_VALUE + 4]
#ifdef CONFIG_CPU_USE_DOMAINS
mrc p15, 0, r6, c3, c0, 0 @ 读域访问控制寄存器DACR
str r6, [r1, #TI_CPU_DOMAIN]@ 把旧的DACR保存到prev的thread_info里
ldr r6, [r2, #TI_CPU_DOMAIN]@ 从next的thread_info里读新的DACR
#endif
switch_tls r1, r4, r5, r3, r7 @ 切换TLS线程本地存储
#if defined(CONFIG_STACKPROTECTOR) && !defined(CONFIG_SMP)
ldr r7, [r2, #TI_TASK]
ldr r8, =__stack_chk_guard
.if (TSK_STACK_CANARY > IMM12_MASK)
add r7, r7, #TSK_STACK_CANARY & ~IMM12_MASK
.endif
ldr r7, [r7, #TSK_STACK_CANARY & IMM12_MASK]
#endif
#ifdef CONFIG_CPU_USE_DOMAINS
mcr p15, 0, r6, c3, c0, 0 @ 把新的DACR写到寄存器里,完成域访问权限切换
#endif
mov r5, r0 @ 把prev进程的task_struct指针暂存到r5
add r4, r2, #TI_CPU_SAVE @ r4 = next进程thread_info里cpu_context的地址
@ 调用线程切换的通知链,内核里其他模块可以通过这个钩子感知进程切换
ldr r0, =thread_notify_head
mov r1, #THREAD_NOTIFY_SWITCH
bl atomic_notifier_call_chain
#if defined(CONFIG_STACKPROTECTOR) && !defined(CONFIG_SMP)
str r7, [r8] @ 更新栈溢出保护的canary值
#endif
THUMB( mov ip, r4 )
mov r0, r5 @ 把prev进程的task_struct指针放到r0,作为函数返回值
@ 核心!从next的cpu_context里,把之前保存的寄存器全恢复出来
@ 包括r4-sl、fp、sp、pc,sp恢复了,内核栈就切到next进程了
@ pc被赋值成next进程之前保存的lr,CPU就会跳转到next进程的执行流
ARM( ldmia r4, {r4 - sl, fp, sp, pc} )
THUMB( ldmia ip!, {r4 - sl, fp} )
THUMB( ldr sp, [ip], #4 )
THUMB( ldr pc, [ip] )
UNWIND(.fnend )
ENDPROC(__switch_to)
看到没,整个进程切换的最后一步,就靠 stmia 和 ldmia 这两条批量内存指令。stmia 把当前进程的寄存器全存到内存里。
最骚的就是最后一条 ldmia r4, {..., pc}。
sp 被换成了 next 的内核栈,pc 被换成了 next 上一次被切换出去时保存的返回地址。
于是 CPU 就神奇地开始在 next 的上下文里跑起来了。
我第一次看这段汇编时,盯着 pc 的变化愣了三分钟——
这不就是传说中的“魂穿”吗?
写到这里,又是几千字了。
说实话,ARM 的进程切换比 x86 清爽不少(至少没那么多段寄存器要折腾),但 ASID 只有 8 位这件事,每次想到都让我觉得有点像“当年设计寄存器的大佬喝了假酒”。
不过话说回来,256 个 ASID 在嵌入式场景也够用——毕竟谁没事在一颗 Cortex-A 上跑几百个进程啊?
你要真跑那么多了,那刷 TLB 的代价你就自己受着吧,反正 Linux 内核已经给了你选择:要么忍受 TLB miss 多一点,要么偶尔来一次全局冲刷。
最后送大家一句我踩坑总结的真理:
调试进程切换 crash,第一眼看 mm->active_mm 是不是 NULL,第二眼看 TTBR0 寄没寄。
别问我怎么知道的,问就是又写Bug了。
 发表于 2026-4-29 00:36:53
|
查看: 182|
回复: 0
发表于 2026-4-29 00:36:53
|
查看: 182|
回复: 0
