
项目卡片
- 项目:awesome-persona-skills[^1]
- 状态:1638 Star / 185 Fork / 创建于 2026-04-06,日增 PR 活跃
- 一句话判断:Persona Skill 生态的社区入口,一份“蒸馏万物”的中文 Skill 合集,覆盖面从巴菲特到前任,质量参差但窗口价值明确
四月初,一个叫“同事.skill”的仓库上线,一两周内冲到几百 Star。紧接着“前任.skill”、“老板.skill”、“巴菲特.skill”、“金刚经.skill”也陆续冒了出来。再然后,有人把所有这些东西收集到了一起 —— tmstack/awesome-persona-skills,一个 Persona Skill 社区合集。
上线不到一个月,1638 Star。翻完整个列表的第一个念头是:中文 AI 用户想往 Agent 里装的东西,远比预想的要多得多。
一个 Skill 长什么样
Persona Skill 是 Claude Code 生态里一类特殊的 Skill:它的输入不是代码任务,而是一个人。
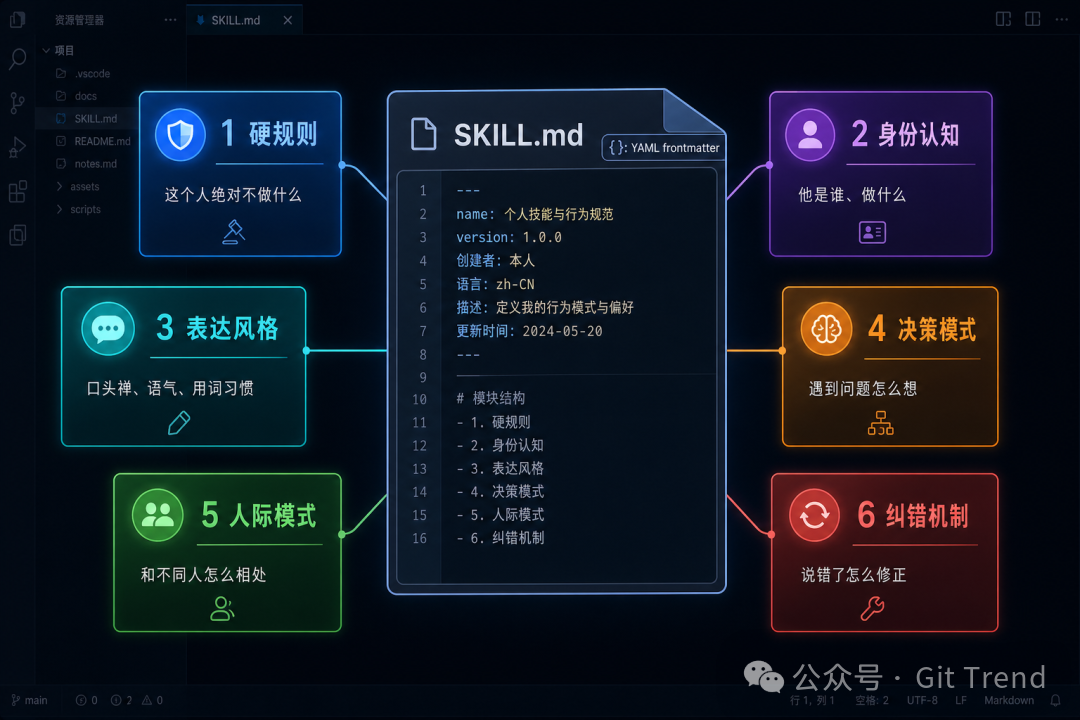
技术上其实很简单——一份名为 SKILL.md 的文件,前端是 YAML,后面是 Markdown 指令。AI Agent 在运行时读取这份文件,按描述调整自己的行为模式、表达风格和决策倾向。一个“同事.skill”的产出大概长这样:
# Persona: 张三
## 身份认知
前同事,后端工程师,曾在 X 团队共事两年
## 表达风格
- 喜欢用“其实吧”开头
- 讨论技术时习惯画架构图再说话
- 不确定的事会说“这个我得再想想”
## 决策模式
- 先问“影响范围多大”
- 偏好最小改动方案
- 对新技术持“能跑就行”态度
AI 读完这份文件,跟你对话时就会像那个同事——语气像,思维像,连口头禅都像。
蒸馏和扮演的区别
普通的 AI 角色扮演靠的是一段描述,让 AI 凭空模仿。Persona Skill 的搞法更重——它从真实数据出发:微信聊天记录、会议纪要、邮件往来、社交媒体内容,通过一个多阶段流水线提取人格特征,最后组装成结构化的 Skill 文件。
同事.skill 的开源作者设计了一套完整的六阶段流水线:数据收集 → 特征提取 → 框架构建 → Skill 组装 → 忠实度验证 → 持续进化。生成的 Skill 通常包含六个模块——硬规则(这个人绝对不做什么)、身份认知、表达风格、决策模式、人际模式,以及纠错机制。
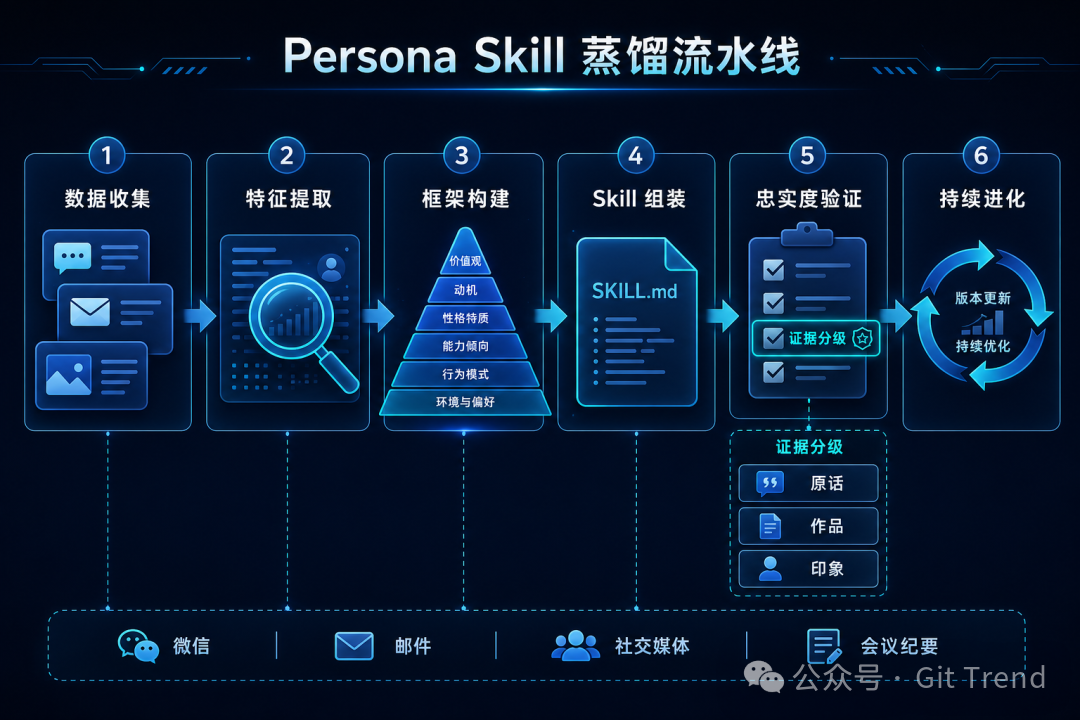
“永生.skill”的做法更值得玩味——它引入了证据分级:原话(verbatim)> 作品(artifact)> 印象(impression)。“这个人像不像”不再是纯靠感觉,而是可以逐条追溯到原始材料。你觉得这种基于证据的复刻,能算是一种数字世界的“复活”吗?
五十多个 Skill,覆盖了什么
awesome-persona-skills 收录了 50 多个 Skill,分成了九大类:
- 职场与学术:同事、老板、导师、大学老师、师兄,还有“反蒸馏.skill”——专门教你怎么应付公司让你交 Skill 的要求。
- 人际关系:暗恋对象、初恋、前任、现任、父母、兄弟,以及“相亲.skill”——项目介绍说是“通过消耗 AI token 节省真人 token”。
- 自我成长:自己、数字人生、永生、Relic(不止人,宠物和地点也能永生)。
- 商业思维:巴菲特、段永平、乔布斯、马斯克、芒格、费曼、纳瓦尔、塔勒布、齐泽克、特朗普、张一鸣。
- 网络名人:郭德纲、峰哥、张雪峰、童锦程、户晨风、凉兮。
- 传统文化:赛博算命、月老、佛教大师、金刚经、毛选、新青年、永乐大典。
- 情感陪伴:追星搭子、逝去亲人重逢、舔狗。
- 工具类:女娲(通用蒸馏器)、达尔文(优化 Skill 的 Skill)、博主蒸馏器(自动爬小红书)。
- 合集收藏:指向另一个 100+ Skill 的合集。
数量不算惊人,但情感光谱覆盖得相当全面。从“巴菲特的投资框架”到“分手后再也不想说出口的话”,从“金刚经”到“舔狗的情感策略”——几乎穷尽了中文互联网用户想把什么东西装进 AI。
怎么装、怎么用
安装一个现成的 Persona Skill,跟装普通 Skill 没啥区别:
# 克隆到全局 skills 目录
git clone https://github.com/titanwings/colleague-skill ~/.claude/skills/colleague-skill
# 或用 npx 一键安装
npx skills add titanwings/colleague-skill
Claude Code 启动时会自动扫描 ~/.claude/skills/ 下的 SKILL.md。如果你想蒸馏自己或身边的人,那流程就复杂一些了:得先用工具解析聊天记录之类的原始数据,再生成 Skill 文件。colleague-skill 自带了 Python 工具链,支持微信聊天记录导出和自动解析,是目前最完整的开源实现。
生成的 Skill 文件通常会被 gitignore 掉——这是个人数据产物,不适合进公共仓库。
翻完列表后,有几个值得优先尝试的:
- 女娲.skill:通用蒸馏器,能把任何人的公开资料蒸馏成 Skill,相当于一个 Skill 生成工厂。
- 同事.skill:最成熟的开源实现,有完整的工具链和六阶段流水线。
- 自己.skill:蒸馏自己的流程最轻量,不需要外部数据也能跑。
- 博主蒸馏器.skill:自动爬小红书全量笔记来生成 Skill,对内容创作者有实际用途。
坑点也提一下:名人这类 Skill(巴菲特、乔布斯)大部分基于公开资料,信息密度还算可控;但人际关系类的(前任、暗恋)更偏向情感产品,实际效果非常依赖你喂进去的数据质量。Skill 质量参差不齐,有些仓库只有一个 SKILL.md 框架,没有配套工具链。
生态和局限
awesome-persona-skills 背后是 openskills.cc 收录的 1767+ 个 Skill 的大生态,以及 Claude Code 的 AgentSkills 开放标准。SKILL.md 格式最初由 Anthropic 开发,现已作为开放标准发布,OpenClaw、Codex 等 Agent 平台也能加载同格式文件。
社区活跃度确实不错——最近一周的 PR 包括新增风骚律师 Skill、相亲 Skill、博主蒸馏器等,隔一两天就有新贡献。列表本身还在快速膨胀。
但我有一个保留意见:这些 Skill 本质上是把个人信息交给 AI 处理。聊天记录、邮件、社交媒体内容——数据经过谁的手、存在哪里、谁能看到,这些东西在安装之前值得认真想清楚。特别是人际关系类 Skill,它涉及的不光是你一个人的数据,还牵扯到别人。
如果你对这类将个人经验结构化的技术感兴趣,在云栈社区里也能找到不少关于 AI Agent 和开发工具的深入讨论。此外,构建和使用这类 Skill 时,查阅相关的技术文档有助于避开配置上的坑。
引用链接
[^1] awesome-persona-skills: https://github.com/tmstack/awesome-persona-skills
 发表于 2026-5-5 17:17:48
|
查看: 168|
回复: 0
发表于 2026-5-5 17:17:48
|
查看: 168|
回复: 0
