今天我们来聊聊操作系统里一个典型的“性能杀手”——内存泄漏。
内存泄漏就像一个潜藏在系统深处的“空间窃贼”:它在你日常使用时悄悄堆积无用数据,在系统闲置时缓慢扩张地盘,一点点蚕食宝贵的内存资源。直到某天,程序启动时突然弹出“内存不足”的警告——你的内存空间可能已被它悄然耗尽。
下面,我们就来系统地拆解内存泄漏,看看它是如何一步步“掏空”你的内存的。
1. 理解内存:程序运行的“高速仓库”
要定位问题,先要理解战场。对程序而言,内存并非一个简单的硬件配件,而是一个支持即时存取的“高效仓库”。所有运行中的程序都需要在这里临时存放和读取数据。如果没有内存,我们打开软件可能需要漫长的等待,而非如今的秒开体验。
进入这个内存仓库,你会发现两个核心区域:一个是共享的Page Cache(页缓存),另一个是程序私有的RSS(常驻内存集)。

这两个区域的管理规则截然不同,也直接决定了内存泄漏的“作案现场”。
1.1 共享临时货架:Page Cache
Page Cache 是内存的公共区域,主要用于缓存最近访问过的磁盘数据,例如刚读取的日志文件、已关闭的文档内容等。其核心目的是加速后续访问:当进程再次需要这些数据时,可以直接从内存读取,无需访问缓慢的硬盘。
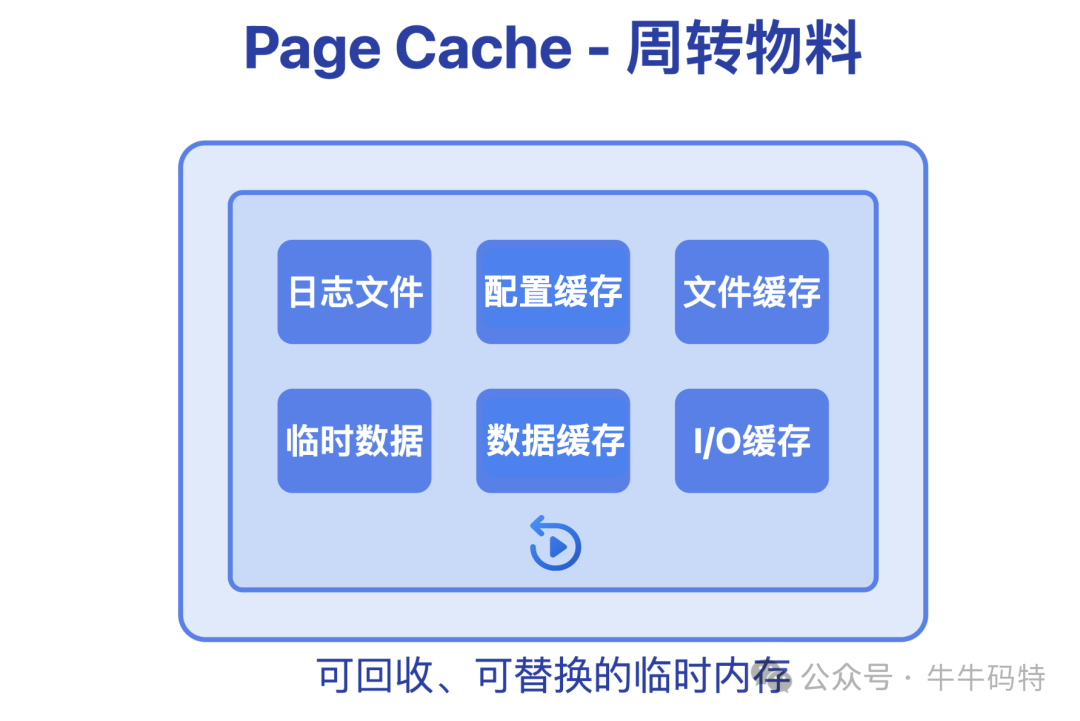
这个区域的关键特性是可回收。当系统内存紧张时,内核会主动扮演“清理员”的角色,将这部分暂时不用的缓存数据回收或写回磁盘,腾出空间给更紧急的任务使用。
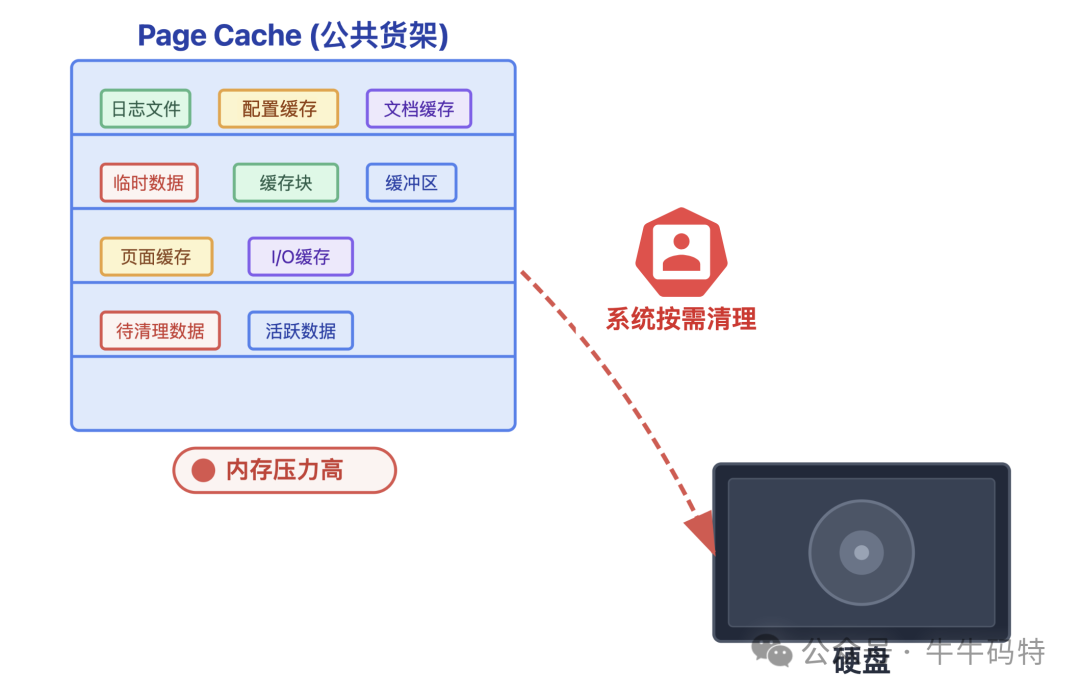
正因如此,内存泄漏通常不会发生在这里——系统定期的清理机制使得在此堆积无用数据等同于“自投罗网”。
RSS(Resident Set Size)是进程常驻内存集。顾名思义,它是分配给某个进程的专属、常驻的内存空间。里面存放着进程运行必需的“家当”:如加载的代码段、堆(Heap)中的数据、以及程序运行所依赖的库等。
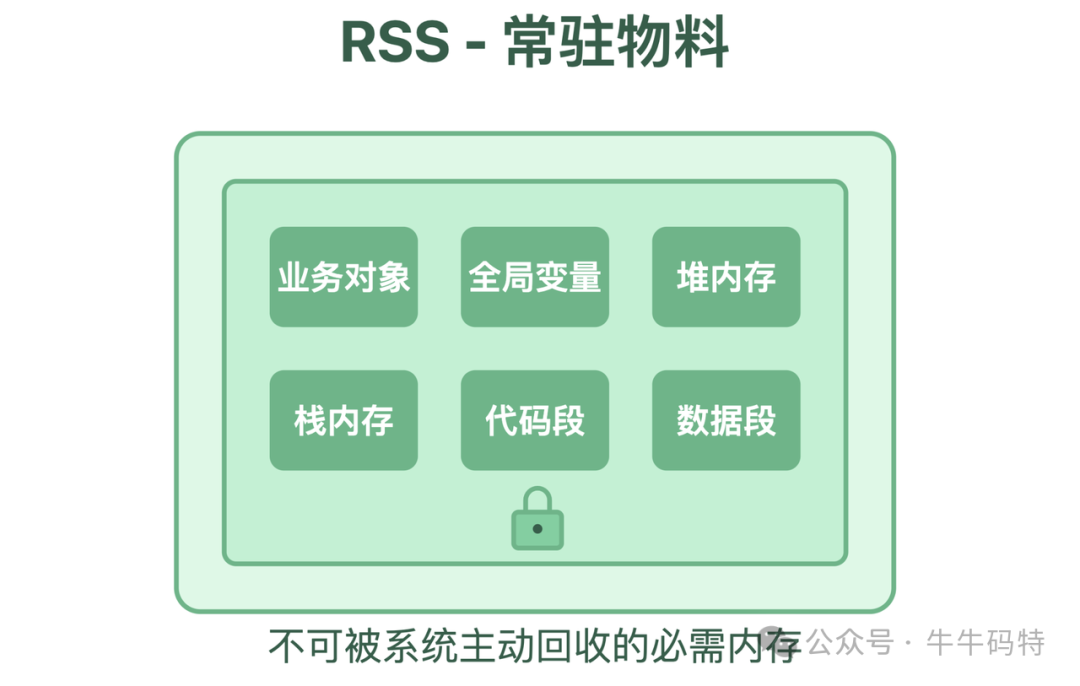
这里,恰恰是内存泄漏的“完美犯罪现场”,原因有二:
- 专属空间无监管:RSS是进程的私有领地,操作系统不会主动清理其中的内容。一旦无效数据被放入,就难以被系统自动移除。
- 空间占用稳定:进程会默认自己RSS中的所有数据都是有用的。只要泄漏的对象仍被引用(即使已无业务逻辑价值),它们占据的空间就不会被释放。这种“占住即拥有”的特性,让内存泄漏可以缓慢而稳定地增长。
由此可见,内存泄漏的核心战场几乎都在RSS这个私人货架上。
2. 内存泄漏的“四步作案”流程
内存泄漏导致程序卡顿并非一蹴而就,而是一个渐进的过程,通常可分为四个阶段。
第一步:潜伏观察期(程序初始化)
在程序启动初期,系统为其分配初始的RSS内存。程序加载必要的代码和数据后,内存占用会趋于稳定。此时,内存曲线平直,看似风平浪静。
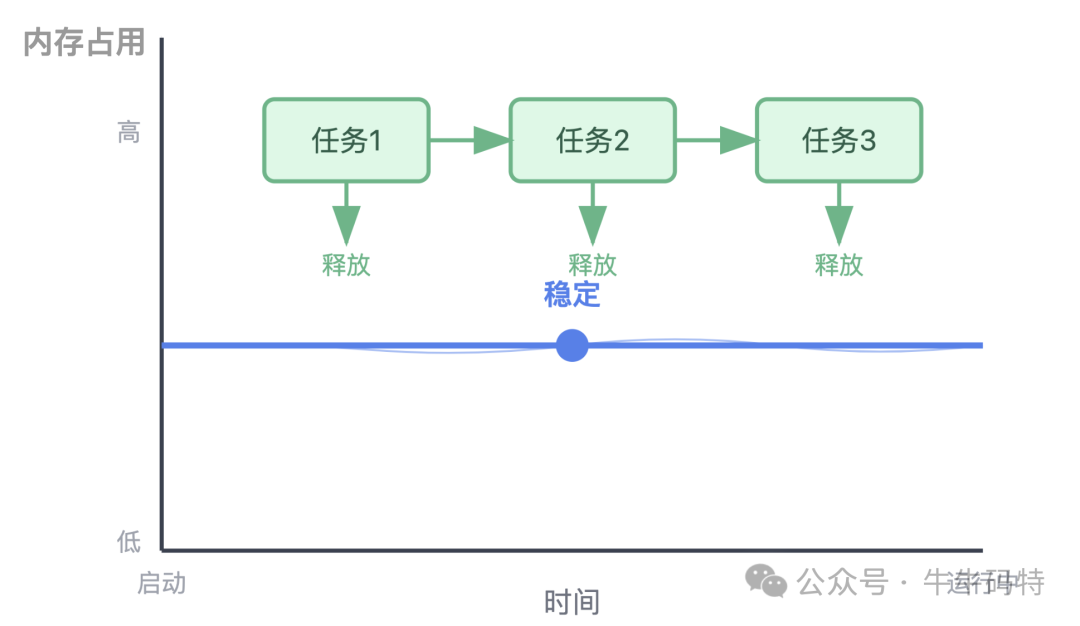
然而,潜在的泄漏点(如未关闭的资源句柄、全局缓存等)已经随着代码加载而潜伏,静待触发时机。
第二步:试探性下手(少量任务处理)
当程序开始处理任务时,泄漏点被激活。例如,处理完一批订单后,本应释放的临时对象(订单DTO、计算结果等)由于代码逻辑缺陷(如忘记置空引用、未关闭连接)而未能被回收。
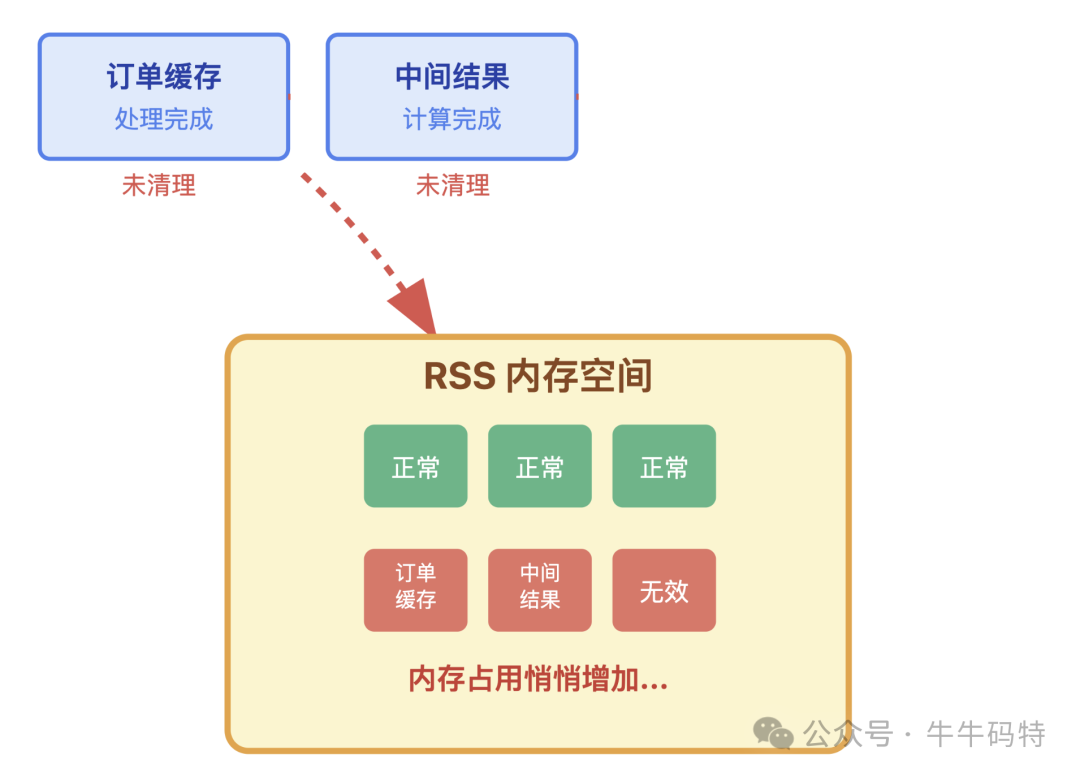
此阶段内存占用会小幅、阶梯式上涨。由于内存余量充足,程序性能感知不明显,异常容易被归咎于网络或系统负载。
第三步:疯狂囤积期(高负载运行)
当程序进入高负载状态(如流量高峰、批量作业),泄漏进入“规模化作案”阶段。每一个业务循环(如处理请求、生成报表)都会创建新对象,而旧对象因未被释放而不断累积。
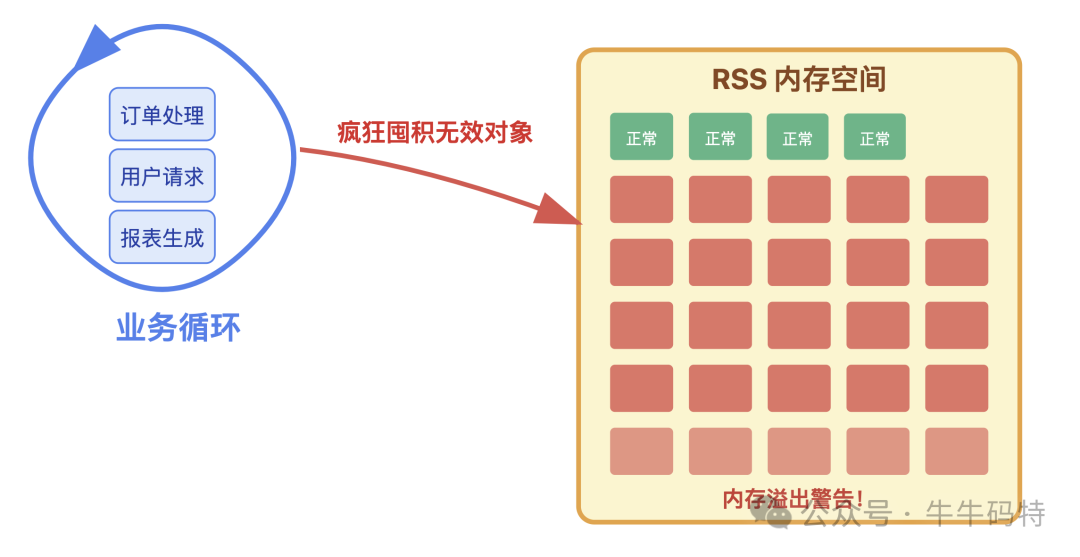
此时,RSS内存占用曲线呈陡峭上升趋势。外在表现开始明显:
- 应用卡顿加剧,响应变慢。
- 若为服务端程序,接口超时或错误率飙升。
操作系统会尝试清理Page Cache来腾挪空间,但对私有RSS无能为力。
第四步:空间耗尽与OOM Killer
当RSS被持续占满,可用内存见底,系统将触发最后的自我保护机制——OOM Killer。

为了防止整个系统因内存耗尽而崩溃,内核会评估并终止那个消耗内存最多且“可牺牲”的进程。此时,客户端应用会闪退,服务端进程会被强制杀死,并在系统日志中留下Out of memory: Killed process的记录。
3. 如何发现内存泄漏的“蛛丝马迹”
我们可以从进程自身和系统全局两个层面,捕捉内存泄漏的痕迹。
3.1 进程层面监控
-
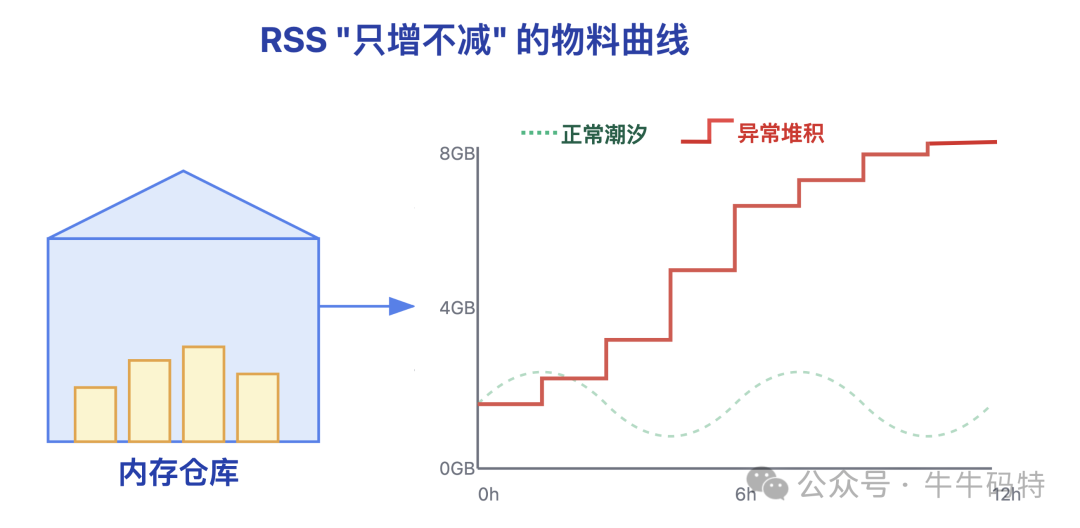
RSS“只增不减”:使用top(Linux)或任务管理器(Windows)观察目标进程的RSS。正常进程的内存占用如潮汐般起伏;存在泄漏的进程,其RSS趋势如同“爬山”,只见上涨,不见回落。
-
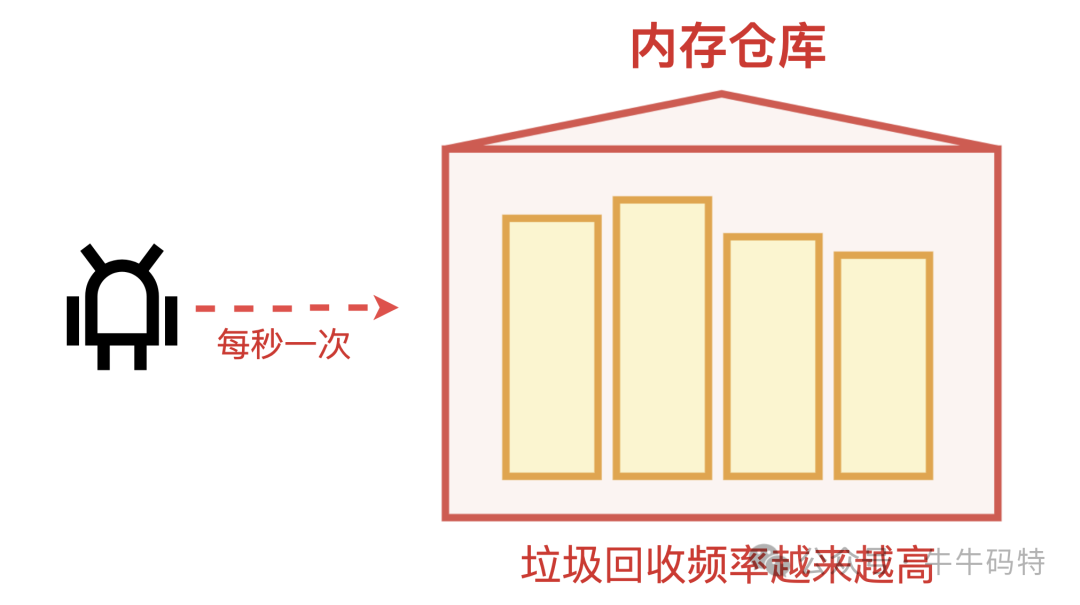
垃圾回收(GC)“忙而无效”:对于Java、Python等托管语言,可观察其GC日志。如果Full GC(完全垃圾回收)频率异常增高,但每次回收释放的内存越来越少,则表明大量对象因被错误引用而无法回收。
-
内存与工作量不匹配:执行相同的业务操作(如处理100个订单),对比不同时间段的内存消耗。如果消耗内存持续增长,则意味着有无用数据在堆积。
3.2 系统层面监控
- 可用内存循环递减:观察系统可用内存。关闭疑似进程后,内存应大幅回升;重启该进程后,内存又持续被消耗。这种循环是泄漏的典型标志。
- Swap使用率激增:当物理内存不足,系统会频繁使用硬盘上的Swap空间。由于磁盘IO速度远慢于内存,会导致系统整体卡顿。Swap使用率持续高于50%并增长,是内存紧张的重要信号。
- 系统日志出现OOM记录:在Linux下,使用
dmesg | grep -i oom命令查看内核日志。若发现OOM Killer杀进程的记录,则是内存耗尽的铁证。
4. 内存泄漏的“防盗”与治理手册
治理内存泄漏,应遵循“应急止损、日常监控、源头防治”的流程。
第一招:应急修复(抢回空间)
- 重启大法:最直接的方案。重启进程能彻底清空RSS,立即恢复内存空间。重启前务必设法保存内存快照(如Java的
jmap),以供后续分析。
- 临时扩容:若重启影响过大,可临时调整进程内存上限(如Java的
-Xmx参数)。但这仅是权宜之计,必须尽快跟进根治。
第二招:日常巡检(守住空间)
- 趋势监控告警:利用Prometheus等监控系统,对进程RSS设置告警规则(如“周增长率超过50%”),做到早期发现。
- 定期内存快照分析:在低峰期定期导出堆内存快照,使用MAT、JProfiler等工具分析,重点关注数量异常多的对象类型,提前发现泄漏苗头。
第三招:源头设防(杜绝泄漏)
- 资源即用即清:对文件流、数据库连接、网络连接等资源,务必使用
try-with-resources(Java)或with语句(Python)确保关闭,或在finally块中显式释放。
- 缓存容量管理:为所有缓存(如本地缓存、Redis)设置合理的容量上限和数据过期时间(TTL),防止缓存无限膨胀。
- 依赖库审计:定期升级第三方库至稳定版本,修复已知的内存泄漏漏洞。精简项目依赖,移除无用库,降低引入风险。
5. 结语
内存泄漏这个“空间窃贼”其实并不可怕,它在“作案”的每个阶段都会留下清晰的痕迹:持续攀升的RSS曲线、徒劳无功的GC日志、不断减少的可用内存。
从根本上防御它,关键在于像管理仓库一样管理内存——这从来不是可以无限挥霍的资源。通过遵守即用即清的编码规范、为缓存设置合理的边界、并建立持续的内存监控体系,我们就能让内存泄漏无处遁形,保障应用长期稳定、高效地运行。

 发表于 2025-12-13 00:25:52
|
查看: 250|
回复: 0
发表于 2025-12-13 00:25:52
|
查看: 250|
回复: 0
