客户反馈,一套Oracle 11g集群在本周内出现整体性的性能下降问题。
对比历史及当前的AWR报告TOP等待事件,可以发现log file sequential read、db file scattered read等待事件的DBTIME占比显著提升,System I/O平均等待时间几乎翻倍。
问题时间(8月15日周五17:00-18:00)AWR片段:
20250815(周五)17:00-18:00
Top 10 Foreground Events by Total Wait Time
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Event Waits Total Wait Time (sec) Avg Wait (ms) % DB time Wait Class
------------------------------ ------------ ---- ------- ------ ----------
log file sequential read 2,223,733 177.3 80 79.6 System I/O
db file scattered read 384,111 20.9 54 9.4 User I/O
DB CPU 8890 4.0
db file sequential read 1,092,125 6853 6 3.1 User I/O
control file sequential read 827,641 6166 7 2.8 System I/O
...
Wait Classes by Total Wait Time
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Wait Class Waits Total Wait Time (sec) Avg Wait (ms) % DB time Active Sessions
---------------- ---------------- ---------------- -------- ------ --------
System I/O 3,102,616 183,436 59 82.4 51.4
User I/O 1,945,398 30,187 16 13.6 8.5
基准时间(8月8日周五17:00-18:00)AWR片段:
20250808(周五)17:00-18:00
Top 10 Foreground Events by Total Wait Time
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Event Waits Total Wait Time (sec) Avg Wait (ms) % DB time Wait Class
------------------------------ ------------ ---- ------- ------ ----------
enq: MN - contention 4,069,734 25.3 6 52.9 Other
log file sequential read 1,036,220 9203 9 19.2 System I/O
DB CPU 7116 14.9
control file sequential read 5,032,787 2655 1 5.6 System I/O
db file scattered read 808,945 1722 2 3.6 User I/O
...
Wait Classes by Total Wait Time
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Wait Class Waits Total Wait Time (sec) Avg Wait (ms) % DB time Active Sessions
---------------- ---------------- ---------------- -------- ------ --------
Other 6,451,726 25,636 4 53.6 7.1
System I/O 6,115,082 11,875 2 24.8 3.3
DB CPU 7,117 14.9 2.0
User I/O 5,674,785 3,381 1 7.1 0.9
问题分析
通过AWR报告初步判断,造成整体性能下降的主要原因指向IO性能劣化。接下来需要从操作系统资源占用及进程层面进行深入排查。
1. 检查单块磁盘IO情况
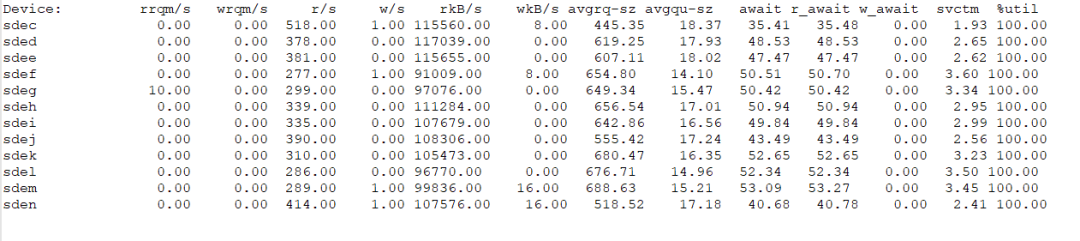
操作系统监控显示,多块数据盘的读IO吞吐量很高,平均在100MB/s左右;读延迟达到约50ms,远超avctm(平均服务时间),这表明不仅有高延迟,读请求排队也异常严重,磁盘繁忙度已达100%。
2. 排除RMAN备份任务影响
排查发现当时存在数据库备份任务在执行。但在停止备份任务后,磁盘IO负载并未下降,因此可以排除RMAN备份任务这一常见因素。

3. 检查占用IO高的系统进程
使用iotop等系统命令检查当前占用IO较高的后台进程,发现主要IO消耗来自于名为oraclexxxdb2 (LOCAL=NO)的进程,属于lisbak实例的非本地连接。
Actual DISK READ: 2.67 G/s | Actual DISK WRITE: 160.11 K/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
12732 be/4 oracle 629.71 K/s 0.00 B/s 0.00 % 98.10 % oraclexxxdb2 (LOCAL=NO)
48005 be/4 oracle 608.24 K/s 0.00 B/s 0.00 % 96.91 % oraclexxxdb2 (LOCAL=NO)
19714 be/4 oracle 1017.02 K/s 0.00 B/s 0.00 % 81.42 % oraclexxxdb2 (LOCAL=NO)
11377 be/4 oracle 5.60 M/s 0.00 B/s 0.00 % 80.09 % oraclexxxdb2 (LOCAL=NO)
...
这类系统级监控是运维/DevOps工作中定位性能瓶颈的关键步骤。
4. 关联数据库内部进程
通过操作系统进程ID(SPID=16742)反查其在数据库内部的会话信息。
SQL> select addr,pid,spid,pname,username,program from v$process where spid=16742;
ADDR PID SPID PNAME USERNAME PROGRAM
---------------- ---------- ------------------------ ----- ---------------
0000000C70AC0F88 84 16742 grid oracle@rac-1
SQL> select sql_id,program,machine,event,schemaname from v$session where paddr='0000000C70AC0F88';
SQL_ID PROGRAM MACHINE EVENT SCHEMANAME
------------- -------------------------------- -------------------- ------------------------------ ---------------
6x6s6490zj2dg JDBC Thin Client tcs-10-1-76-204 log file sequential read DAAS_LISBAK
查询结果显示,该进程正在执行的等待事件正是log file sequential read,与AWR报告中的主要等待事件吻合。
5. 分析执行的SQL语句
进一步检查该SQL_ID对应的完整文本。
select sql_fulltext from v$sql where sql_id='6x6s6490zj2dg';
SELECT SCN, SQL_REDO, OPERATION_CODE, TIMESTAMP, XID, CSF, TABLE_NAME, SEG_OWNER, OPERATION,
USERNAME, ROW_ID, ROLLBACK, RS_ID, STATUS, INFO, SSN, THREAD#, DATA_OBJ#, DATA_OBJV#,
DATA_OBJD# FROM V$LOGMNR_CONTENTS WHERE SCN > :1 AND SCN <=:2 AND
((OPERATION_CODE IN (6,7,34,36) OR
(OPERATION_CODE = 5 AND USERNAME NOT IN ('SYS','SYSTEM') AND INFO NOT LIKE 'INTERNAL DDL%'
AND (TABLE_NAME IS NULL OR TABLE_NAME NOT LIKE 'ORA_TEMP_%')) ) OR
(OPERATION_CODE IN (1,2,3,255) ))
这是一个典型的LOGMINER日志挖掘查询语句,用于从归档日志中抽取数据变更信息。
6. SQL执行历史分析
分析该SQL的历史执行情况,发现其执行计划未改变。但在问题发生时间点(8月11日)之后,出现了以下变化:
- 执行频率降低。
- 单次执行扫描的行数(逻辑读
BUFFER GETS)显著增高。由于该SQL是对V$LOGMNR_CONTENTS的动态视图进行全表扫描,其效率直接取决于需要挖掘的日志条目数量。
- 单次执行的响应时间随之增高。
7. 归档日志生成量分析
考虑到LOGMINER处理的数据量与归档日志量直接相关,我们检查了近期归档日志的生成情况,发现生产量同比变化不大,排除了日志量暴增导致负载变化的可能。
分析结论及处理建议
分析结论
通过从数据库AWR报告到操作系统进程,再关联回数据库/中间件内部会话与SQL的层层溯源,可以确定本次IO性能问题的直接原因是LOGMINER日志挖掘任务。
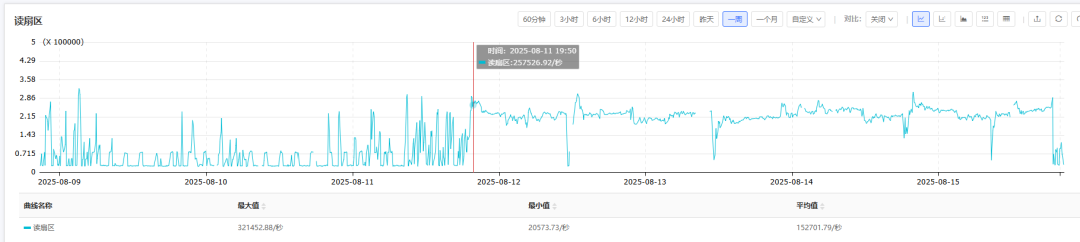
硬件层面的IO监控峰值与数据库层面观察到的性能变化时间点基本吻合。LOGMINER挖掘任务的执行模式发生了改变:执行频率降低,但单次任务需要处理的日志条目(扫描行数)和消耗的资源大幅增加,从而导致磁盘IO成为系统瓶颈。
处理建议
本次IO性能问题主要由外部系统通过LOGMINER进行日志挖掘的行为变化所引发。鉴于其执行统计信息(频率、效率)发生了明显改变,建议联系使用LOGMINER进行数据抽取的对应应用厂商,协同排查其当前的日志抽取逻辑或调度策略是否存在调整,从而从根本上解决IO负载过高的问题。
 发表于 2025-12-13 00:29:03
|
查看: 200|
回复: 0
发表于 2025-12-13 00:29:03
|
查看: 200|
回复: 0
