Data Pump 是 Oracle 数据库用于高速移动数据和元数据的核心技术,包含两个命令行客户端:expdp(导出)和 impdp(导入)。本系列文章将从零开始,带你逐步掌握 Oracle Data Pump(数据泵),并深入了解 Oracle Database 19c 和 21c 版本的核心差异与新特性。
然而,很多人对它的使用往往停留在“会敲命令”的层面,对其底层机制一知半解。这导致在实际操作中,经常会遇到一些令人困惑的问题:
- 为什么明明在本地敲的命令,导出的文件却不在本地?
- 为什么总报 ORA-39002 目录权限错误?
- Data Pump 到底是在什么时候选择“直接路径”还是“外部表”?
本系列文章将基于 Oracle 19c 和 21c,带你由浅入深,从底层架构到高级特性,彻底掌握这一核心技术。第一篇,我们将从理解其服务器端执行这一核心机制开始。
一、核心机制:服务器端执行
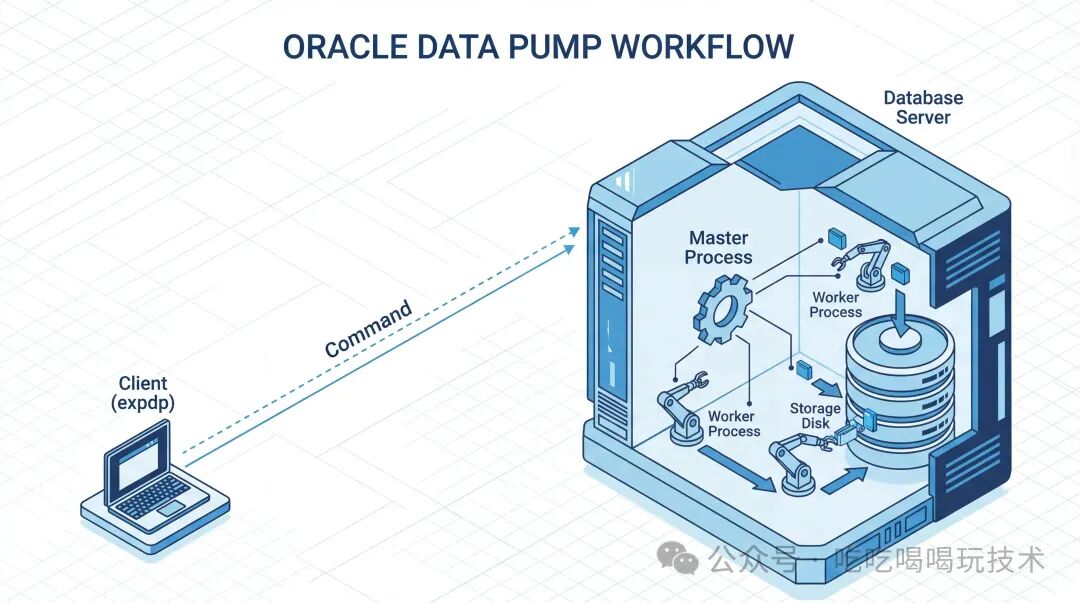
理解 Data Pump 的第一步,是明白它与传统客户端工具(如古老的 exp/imp)的本质区别:它是运行在服务器端的。
当你执行 expdp 命令时,你并不是启动了一个直接搬运数据的客户端程序,而仅仅是启动了一个“发令员”。整个数据泵作业的生命周期遵循以下流程:
- 客户端发起:
expdp 客户端连接数据库,发送导出请求和参数。
- 服务端执行:数据库内部的 Master Control Process 接收请求,并启动多个 Worker Process 进行实际的数据读取。
- 落盘:读取的数据由数据库服务器的进程直接写入到数据库服务器的本地磁盘(或挂载的存储路径)。
这种设计决定了 Data Pump 高效且健壮的特性,也引出了后续必须理解的“目录对象”概念。
二、必须掌握的三大核心组件
Data Pump 的强大功能由以下三个组件协同完成,理解它们有助于你更灵活地运用这一工具。
1. 命令行客户端 (expdp/impdp)
这是用户最常接触的交互接口,负责提交作业参数并监控状态。一个关键特性是:即便你中断了客户端连接(例如按了 Ctrl+C),服务器端的作业通常仍在继续运行。你可以随时通过 expdp ... ATTACH 命令重新连接并查看进度。
2. DBMS_DATAPUMP (PL/SQL API)
这是 Data Pump 的核心引擎。实际上,所有的导出导入逻辑都是通过调用这个 PL/SQL 包实现的。这意味着你完全可以绕过命令行,直接编写 PL/SQL 代码来创建和控制更复杂的数据泵作业,实现高度定制化的数据迁移流程。
这是元数据引擎。它负责将数据库对象(如表结构、索引、存储过程等)的定义提取出来,并转换为 XML 格式,存储到转储文件(.dmp)中。数据和元数据的分离,是 Data Pump 设计精妙之处。
三、必过的门槛:目录对象
正因为数据是由服务器进程直接写入服务器磁盘,数据库必须明确知道操作系统层面的写入路径。这就引入了 Directory Object(目录对象) 的概念。
它是连接“数据库逻辑层”与“操作系统物理层”的桥梁。你可以将它理解为一个数据库内部的别名(Alias),指向服务器文件系统上的一个具体路径。
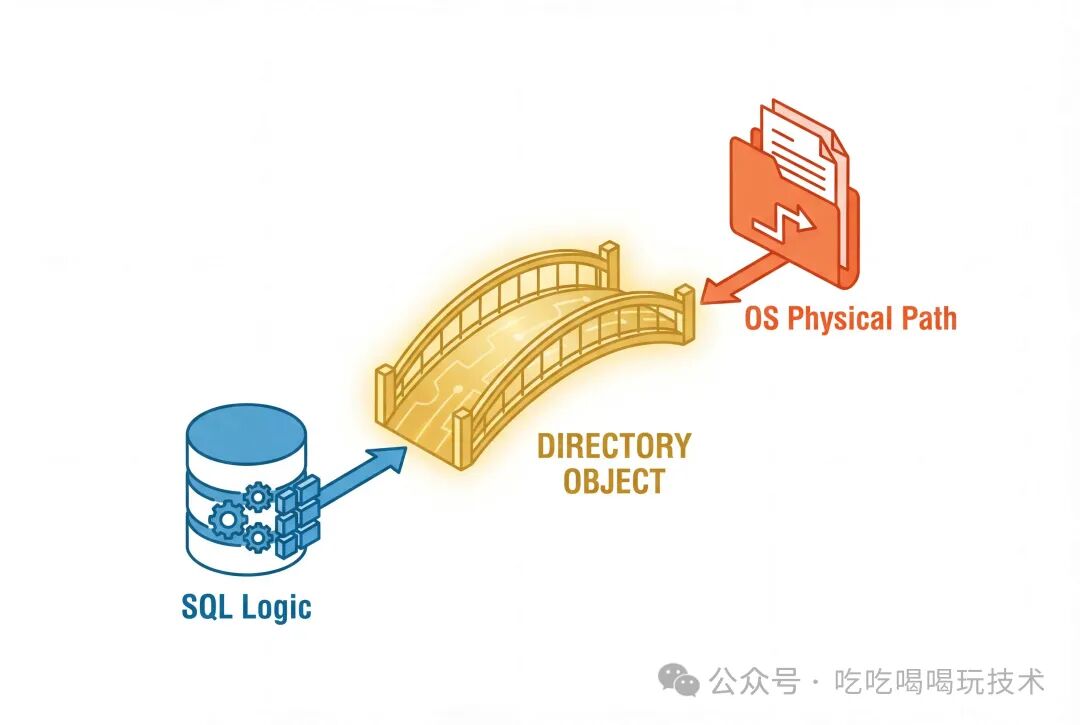
正确配置目录对象是使用 Data Pump 的“防坑”第一步,请遵循以下标准三步曲:
1. 物理层创建: 确保操作系统路径真实存在,并且运行数据库的操作系统用户(通常是 oracle)对该路径拥有读写权限。
mkdir -p /u01/app/oracle/admin/orcl/dpdump/
2. 逻辑层映射: 在数据库中创建目录对象,指向上述物理路径。
CREATE OR REPACE DIRECTORY dpump_dir AS '/u01/app/oracle/admin/orcl/dpdump/';
3. 权限赋予 (关键!): 非 DBA 用户(如业务用户 hr)要使用该目录进行导出导入,必须被显式授予读写权限。
GRANT READ, WRITE ON DIRECTORY dpump_dir TO hr;
许多常见的 ORA-39002 错误,根源就在于忽略了这第三步。
四、数据移动的四条“车道”
Data Pump 并非用一种方式处理所有数据。它会根据表的结构、数据类型等因素,自动选择最优的数据移动模式。了解这些模式,有助于你理解性能差异并优化作业。
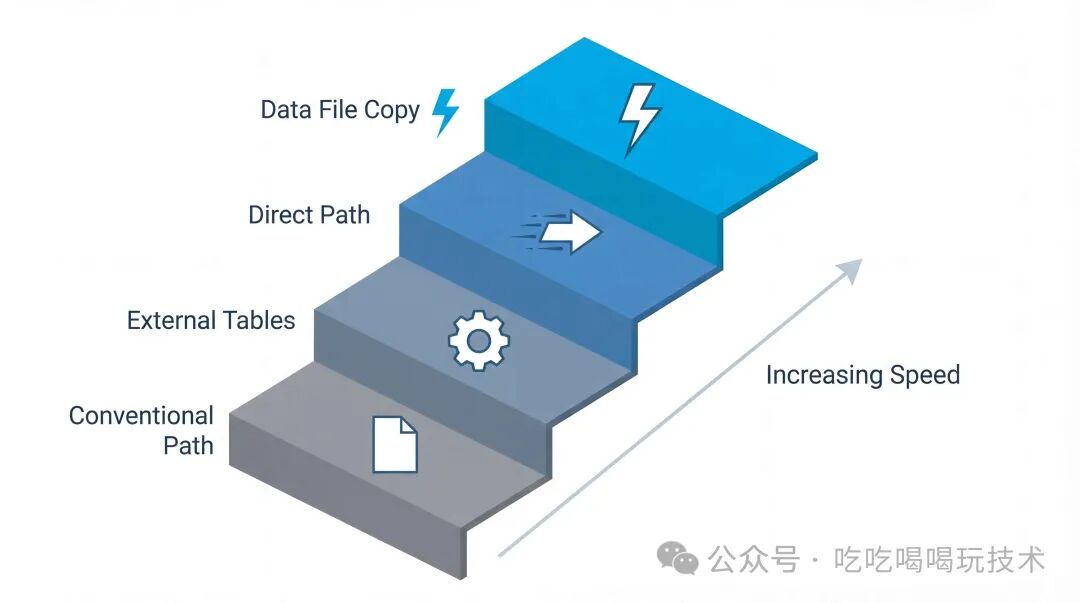
1. 数据文件复制: [极速]
直接在操作系统层面复制数据文件。这是“可传输表空间”特性的基础,速度最快,因为它跳过了数据提取和加载的过程。
2. 直接路径: [高速]
绕过 SQL 解析层和 Buffer Cache,直接读取数据块。这是 Data Pump 处理普通表时的首选模式,性能非常高。
3. 外部表: [中速]
使用 SQL 引擎,通过外部表机制加载或卸载数据。当表包含复杂数据类型(如 LOB、加密列)或不满足 Direct Path 条件时,Data Pump 会自动降级到此模式。
4. 常规路径: [慢速]
传统的通过 SQL 层处理(如 INSERT ... SELECT),性能最低,仅在极少数存在冲突属性的情况下使用。
五、定义你的导出范围
在启动导出任务前,你需要通过模式参数精准定义操作范围,避免导出不必要的数据。Data Pump 支持从全库到单表的不同粒度。
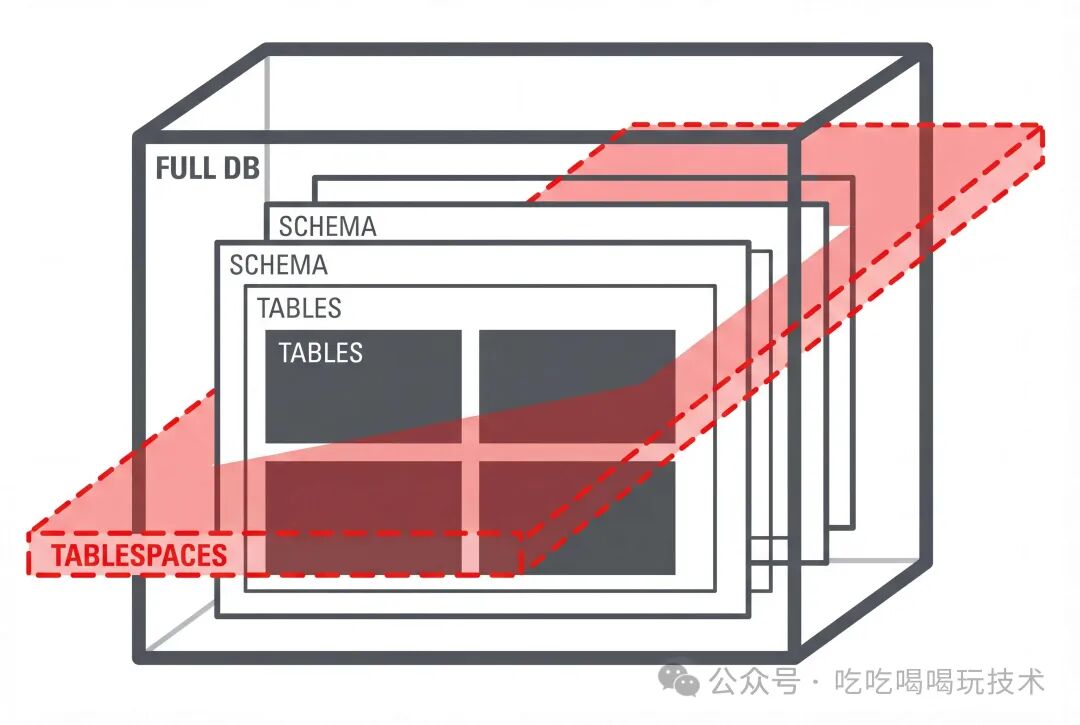
- Full (全库):
FULL=YES。导出整个数据库,通常用于全库迁移或灾备,需要特殊权限。
- Schema (模式):
SCHEMAS=hr, scott。默认模式,按用户(模式)导出,是最常用的方式。
- Table (表):
TABLES=hr.emp, hr.dept。仅导出特定的表,可以精确控制。
- Tablespace (表空间):
TABLESPACES=users。导出指定表空间内的所有对象。
- Transportable Tablespace (可传输表空间):
TRANSPORT_TABLESPACES=...。仅导出元数据,需要配合上述的“数据文件复制”模式使用,是实现跨平台大数据量迁移的利器。
本期实战与总结
建议在你的测试环境中完成以下操作,以验证对“目录对象”的理解:
- 环境准备:在数据库服务器上新建一个路径,例如
/tmp/dp_test。
- 对象创建:以 DBA 用户登录,创建 Directory 对象
TEST_DIR 指向该路径。
- 权限验证:创建一个仅有
CONNECT 和 RESOURCE 权限的新用户,尝试用该用户执行导出到 TEST_DIR。观察是否会报错 ORA-39002,然后通过 GRANT READ, WRITE ON DIRECTORY ... 修复它。
通过本文,你已经掌握了 Oracle Data Pump 最核心的架构思想:服务器端执行、目录对象桥梁以及四种数据移动模式。这些是理解后续所有高级特性和排查复杂问题的基础。
掌握了基础架构后,你是否好奇如何应对更复杂的生产需求?例如“如何只导出表中最近三个月的数据?”、“将生产库的数据导入测试库时,能否让表空间名自动改名以避免冲突?”。这些内容我们将在下期探讨。如果你在实践中遇到其他有趣的挑战,欢迎在 云栈社区 的数据库板块与大家交流分享。
 发表于 2026-1-25 07:07:49
|
查看: 183|
回复: 0
发表于 2026-1-25 07:07:49
|
查看: 183|
回复: 0
