很多国产数据库都把“兼容 Oracle”当作核心卖点。说实话,我以前对这事儿一直不太感冒,甚至觉得这可能是个伪需求——改动业务代码有那么难吗?直到最近,我碰到了一个极其特殊的情况,才让我对这个功能有了新的认识。
一个没有源码的 JAR 包
最近接了个挺有意思的活儿。客户是某家500强车企,他们有一套跑在 EDB(EnterpriseDB 出品的、带 Oracle 兼容的 PostgreSQL)上的系统,版本是 9.1。
9.1 是什么概念?这是2011年发布的版本,距今已经整整 15年 了。这套系统部署在某个云平台上,出过好几次大故障(比如用500 IOPS的云盘跑22TB的生产库)。客户实在忍不了了,于是找到我,希望帮忙升级。
从 9.1 升级到现在的 PostgreSQL 18,中间差了十五个大版本,这个跨度本身就很大。但真正要命的不是版本,而是他们的应用——源码丢失了。
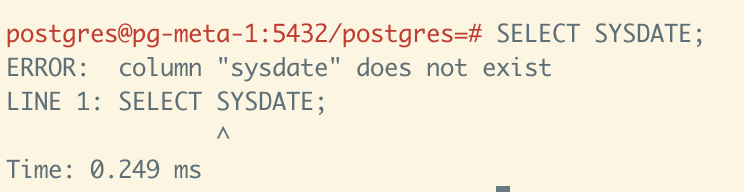
没错,就剩下一个编译好的 JAR 包,里面的 SQL 代码都写死了,完全无法修改。更要命的是,这些 SQL 里用了 EDB 提供的 Oracle 兼容语法,比如 SYSDATE。
不过,有一点让我感到震撼:除了 SYSDATE 这个“历史遗留的尾巴”之外,这套祖传业务代码从15年前的旧版 PostgreSQL 升级到最新的 PG 18,竟然没有任何其他不兼容的地方。
为什么 SYSDATE 如此棘手?
SYSDATE 在 Oracle 中是一个内置关键字/变量,用于获取当前时间戳,类似于 PostgreSQL 里的 current_timestamp。
你可能会想:这有什么难的?建个自定义函数不就行了吗?
CREATE FUNCTION sysdate() RETURNS timestamp(0) AS
$$
SELECT clock_timestamp()::timestamp(0)
$$ LANGUAGE SQL;
问题没那么简单。应用代码里写的不是 sysdate() 这种函数调用语法,而是直接使用了 SYSDATE 这个光秃秃的标识符。在 PostgreSQL 的解析器(Parser)看来,这东西既不是函数调用,也不是已知关键字,它压根不认识,直接就会报语法错误。
你无法通过编写扩展来解决这个问题。PostgreSQL 的可扩展性很强,你可以自定义类型、操作符、索引方法,甚至存储引擎。但唯独语法规则,是不允许通过扩展来定制的,这是其可定制性上一个小小的遗憾。
要让 PostgreSQL 认识 SYSDATE 这个 Token,你必须去修改内核源码中的语法规则文件。
如果应用有源码,这事儿就太简单了——现在用 AI 做个全局替换,把 SYSDATE 改成 clock_timestamp()::timestamp(0),分分钟搞定。但源码没了,JAR 包里的 SQL 字符串字面值无法修改,这条路彻底堵死了。难道要去反编译 JAR 包然后修改字节码中的字符串?这听起来就不靠谱。所以你看,所有脏活累活最后都堆到了数据库这一层。
IvorySQL:开源的 Oracle 兼容内核
虽然需求听起来有点“扯”,但既然是客户的活儿,总得想办法解决。琢磨了一下,能在 PG 内核层面提供 Oracle 语法兼容的方案就那么几种。
做得最好的是商业版的 EDB,继续用它自然没问题,但客户这次就想换到开源方案。国内有不少声称兼容 Oracle 的数据库,但客户对此并不感兴趣。最终,我发现 IvorySQL 是完成这个任务的最佳选择。
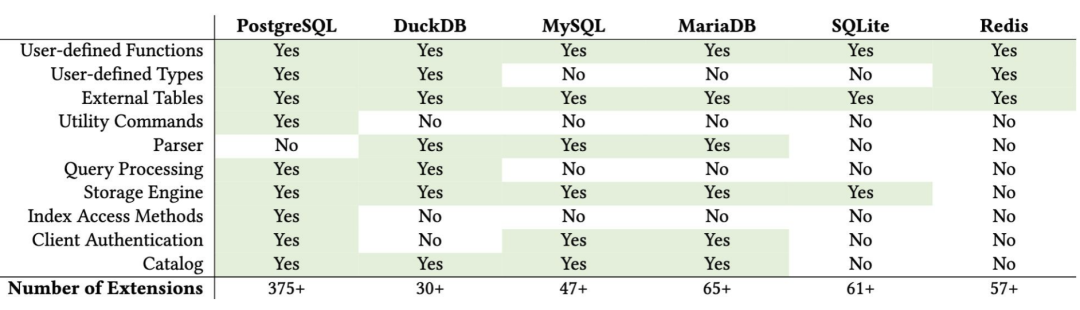
IvorySQL 是一个基于 PostgreSQL 内核的开源项目(Apache 2.0 协议),它提供了包括 PL/SQL、Oracle 语法、内置函数、数据类型、系统视图等在内的兼容性。最新的 IvorySQL 5.1 与 PostgreSQL 18.1 保持同步。
需要说明的是,IvorySQL 的兼容是 SQL 语法层面 的,而不是线缆协议兼容。客户端仍然使用标准的 PostgreSQL 驱动连接,连接后可以执行 Oracle 风格的 SQL。这么设计很明智,毕竟 Oracle 的法务在业界是出了名的严格,规避协议层面的直接模仿是明智之举。
更关键的是:IvorySQL 只是一个内核,而 Pigsty 能把它变成一个功能完整的 RDS。
高可用、备份恢复、监控、基础设施即代码(IaC)——所有这些能力都与 Pigsty 原生集成。部署一套生产级的、使用 IvorySQL 内核的 RDS 服务,听起来复杂,实际上却简单到令人发指。找一台 Linux 服务器,执行以下命令:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./configure -c ivory # 使用 IvorySQL 配置模板
./deploy.yml
三条命令,一套 Oracle 兼容的 PostgreSQL RDS 就部署完成了。添加从库、配置备份、启用监控,全都预先集成好了。
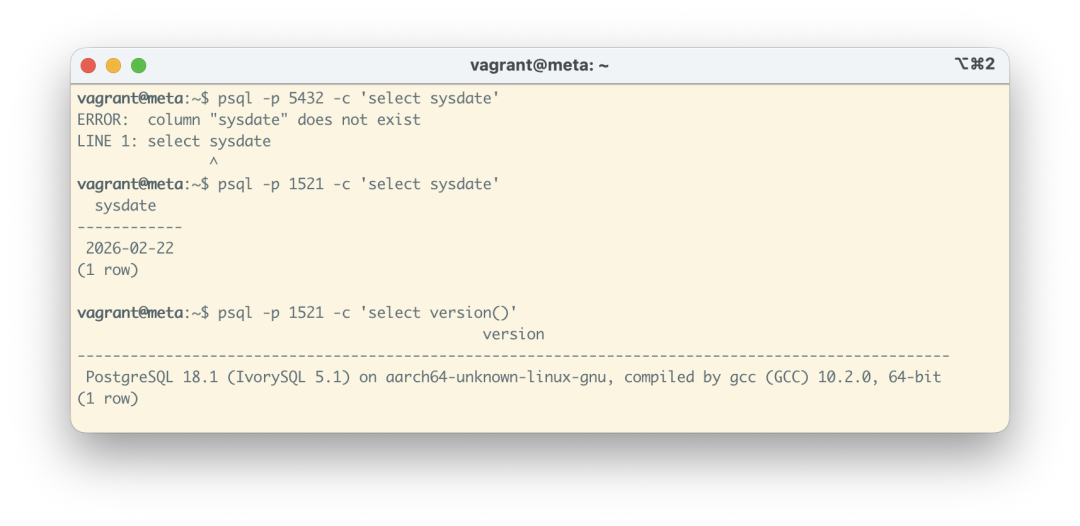
实际测试一下:连接默认的 5432 端口,执行 SELECT SYSDATE 会报错;而切换到 IvorySQL 提供的 1521 端口(Oracle 兼容端口),查询成功执行。
这套方案完美地解决了这个历史遗留的、无源码应用迁移的难题。这也让我意识到,虽然这是一个相对小众的生态位,但确实存在着真实且强烈的用户需求。相比商业数据库昂贵的订阅费,这样的开源方案为客户节省了巨大成本。
Pigsty:一个“元发行版”的思考
通过 IvorySQL 这个案例,也顺便聊聊 Pigsty 最近在内核多样性上做的一些工作。Pigsty 的有趣之处在于,它不仅仅是一个 PostgreSQL 发行版,更是一个 “元发行版”。
内核重建与更新:
- Babelfish 内核:这是 AWS 出品的 SQL Server 兼容内核。我们按 Pigsty 标准重建了其打包流程,使其脱离第三方依赖,支持全平台,并升级至基于 PG 17。
- Cloudberry 内核:这是基于 Greenplum 7 的开源数据仓库。在官方未提供广泛二进制包支持的情况下,我们为其打包了涵盖主流 Linux 发行版(EL 8-10, Debian, Ubuntu)及 x86_64/ARM64 架构的 RPM/DEB 包。
- 此外,像 OrioleDB、Percona PGTDE 等内核也保持了同步更新。
这意味着,在 Pigsty 提供的统一平台能力(监控、高可用、备份、IaC)之上,你可以根据需求灵活选择内核:
- 想要 Oracle 兼容 → IvorySQL 内核
- 想要 SQL Server 兼容 → Babelfish 内核
- 想要 极致 OLTP 性能 → OrioleDB 内核
- 想要 透明数据加密 → PGTDE 内核
- 想要 数据仓库 → Cloudberry 内核
- 想要 分布式扩展 → Citus 内核
内核可以更换,但平台提供的能力保持不变。 这才是现代数据库发行版应该做的事情——降低用户对不同数据库内核的运维复杂度,让大家能更专注于业务逻辑本身。

这次经历让我看到,技术方案的“有用与否”往往取决于具体的场景。那些看似边缘或小众的需求,在关键时刻可能成为决定项目成败的关键。作为开发者或架构师,保持技术视野的开阔,了解像 Pigsty 这样的“元发行版”或 IvorySQL 这样的兼容方案,或许就能在未来某个棘手时刻,找到一条优雅的解决路径。如果你对这类数据库生态的实践和探索感兴趣,欢迎来 云栈社区 交流分享。
 发表于 2026-2-23 01:24:04
|
查看: 189|
回复: 0
发表于 2026-2-23 01:24:04
|
查看: 189|
回复: 0
