今天在 X 上看到一篇有意思的文章,叫《How To Cut Your AI Coding Bill by 80%》。作者 DeRonin 说自己把每月的 Vibe Coding 账单从 4200 美元压到了 312 美元,没换工具、没少干活,靠的全是对 token 的理解和一套路由方法。

我现在每天要消耗几个亿的 token,多项目并行,动不动就用 Agent Teams 开团。偶尔也会跑一下 npx ccusage@latest 看看账单,但 DeRonin 的文章确实给了我一些启发,有些细节我之前没认真想过。
他说,95% 的 Vibe Coding 用户从没深入研究过 token 经济学。这个词算是新概念,说白了就是算清楚 token 这笔账。
本文会把那篇文章的核心认知讲透,更重要的是,每一步具体怎么操作都写出来,你看完就能直接照着做。
Token 消耗的组成结构
先说一个反直觉的结论:你的 Claude Code 账单贵,大概率不是模型单价高,而是你在为那些根本没必要的重复内容反复买单。
DeRonin 文章里最关键的一句话是——你不是在为 token 付费,你是在为 context 付费。
我们把一次会话拆开来看。
一次 API 调用,账单上其实有四类 token。输入 token 是你发给模型的所有内容:prompt、系统提示、文件内容、对话历史。输出 token 是模型返回的代码和解释,单价通常是输入的 3 到 5 倍。缓存 token 是之前发过、被标记缓存下来的输入,计费大约只有正常输入的十分之一。还有一类思考 token,是模型在扩展思考模式下的内部推理,你看不到但它一样计费。
这四类 token 的底层机制,我在一篇关于 token 的技术科普:从一次 Claude Code 会话说起里详细拆过,这里只从账单的视角来说。
这四类里真正容易失控的就是输入 token。输出和思考是模型干活的必要消耗,而输入里藏着大量浪费。
举个最常见的例子:你在 Claude Code 或 Codex 里改一个 bug,把仓库里几十个文件一股脑全塞进去,大几万 token 起步。模型读完,发现实际只需要改一个小文件的 10 行代码。
问题是,这几十个文件大部分根本没变化。下一轮你再问另一个不相关的问题,它可能又会把这些文件重新塞进上下文,token 再次消耗一轮。一天来回五十轮,同一批内容的 token 就重复消耗了五十次。
在 Agent 场景下,上下文是滚雪球式累积的——每往前走一步,都要把之前所有的任务和回应重读一遍。有研究统计,生产环境中的 Agent,平均每生成 1 个 token,背后就要吞掉大约 100 个上下文 token;Agentic 任务消耗的 token 量,大概是普通对话式编程的一千倍。
所以 token 经济学的第一层认知就是:你的账单里,相当一部分钱买的是重复上下文的 token,不是智能。模型其实没那么贵,是我们让它把同样的东西读了太多遍。
养成查 Claude Code/Codex Token 账单的习惯
动手省钱之前,先搞清楚钱到底花在了哪儿。
如果你用 Claude Code,直接在终端输入 npx ccusage@latest 就能看到 token 消耗明细。用 Codex 的话,输入 npx @ccusage/codex@latest 即可查看 GPT-5.5 模型的消耗明细。
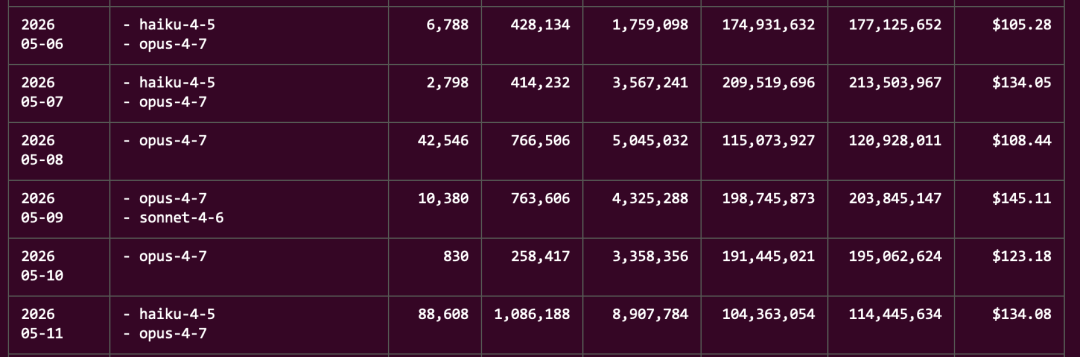
工具会把每天的 token 拆开来展示:输入、输出、缓存命中各占多少,省了多少钱。重点看缓存命中的比例。
这里没有官方标准线,但社区有个可参考的经验值:在同一个项目里多轮对话时,缓存读取的占比通常能达到七八成以上。如果你长期只有三四成甚至更低,基本可以断定缓存没怎么命中,会话结构有问题——这就是你第一个要堵的漏洞。
我自己的习惯是,每个项目跑一段时间,就扫一眼上下文缓存比例。一旦缓存命中率掉下来,马上就意识到当前在跑的任务上下文没编排好。
Vibe Coding 时如何省 Token
看清账单之后,开始堵漏。我按性价比从高到低来说。
最该先做的,是别把 prompt caching 的优势浪费掉。
好消息是,prompt caching 现在基本不用你手动开启。Claude Code 和 Codex 都带默认的自动缓存机制,系统提示、工具定义、CLAUDE.md、对话历史这些东西都会被自动缓存,命中后计费打一折。Codex 这边也一样,OpenAI 的接口对 GPT-5 系列默认自动缓存,命中的输入 token 同样差不多只按一折计费;Codex CLI 还会特意把系统指令、工具定义等固定内容按相同顺序排好,就是为了保住这个稳定前缀。
但自动开着,不代表你就吃到了。缓存的原理是复用相同的前缀——前缀一变,缓存就失效。所以真正要做的,是别去随便破坏这个前缀。
具体来说就两件事:第一,把项目里稳定不变的东西——目录结构、技术栈约定、开发规范——全部沉淀进 CLAUDE.md,让它以一个稳定前缀的身份待着,而不是每次在对话里临时重新交代。第二,别在会话中途频繁修改 CLAUDE.md,你每改一次,后面的缓存就得重建。这个 trick,去年 Manus 的一篇上下文工程文章里也提过。
缓存默认有五分钟的有效期,而且每次命中都会刷新倒计时。也就是说,只要你五分钟内一直在用,它就一直续着;一旦停下来超过五分钟才过期,下次就得重建。所以同一类工作尽量集中做完,别断断续续的。(这个五分钟是 2026 年 3 月才从一小时调下来的默认值,如果你直接调 API,还可以选一小时的扩展缓存,代价是写入更贵。)
如果你是直接调 API,那么就在请求体里给稳定的内容块加上 cache_control 标记,把系统提示和固定上下文标成可缓存的。
然后是 grep 先行的习惯。
不管不顾地把文件往上下文里塞,是输入 token 浪费的重灾区。不确定模型到底需不需要这个文件就塞进去,一个“改个 bug”的请求可能就吃掉 10 万 token。
DeRonin 的做法是先用 ripgrep 搜,再决定发什么。比如你要改一个跟 useUserAuth 有关的 bug:
rg "useUserAuth" --type ts -l # 先看符号在哪些文件里
rg "useUserAuth" --type ts -B 5 -A 20 # 再看具体调用,带上下文
搜出来的才是模型真正需要的,没搜到的文件它根本用不上。
你还可以在 CLAUDE.md 里写一句,要求它改代码前先 grep 定位、不要整文件读取,把这个习惯固化下来。
长会话记得及时压缩。
一个会话聊到后面,前面几百轮历史全挂在上下文里,每问一句都带着这一大坨。
用好 Claude Code 的 /compact 命令,它会把当前会话压成一份摘要,保留关键结论,丢掉冗余过程。我的习惯是每干完一个完整的小任务、或者每隔十几轮,就手动 /compact 一次。这个方法我在 如何管理 Claude Code 100w 上下文?Anthropic 官方推荐的五种使用指南里也详细写过。
最后,杂活、小任务,完全可以交给本地部署的小模型。
补全、生成样板代码、改个语法——这种活根本不需要云端大模型,本地跑个小模型就够,一分钱不花。
DeRonin 给的方案是用 Ollama,三条命令:
brew install ollama
ollama pull qwen3 # 具体规格去 Ollama 模型库挑个小参数的
ollama serve
不过我个人不太喜欢本地部署小模型,更倾向把简单任务丢给国产模型处理。
CCMR 多模型路由
知道怎么省 token 之后,还有一招是模型路由:按任务类型,把活分发给不同档位的模型。粗活、清理活用便宜模型甚至本地模型,日常实现用中档国产模型,最关键的决策才上顶配。
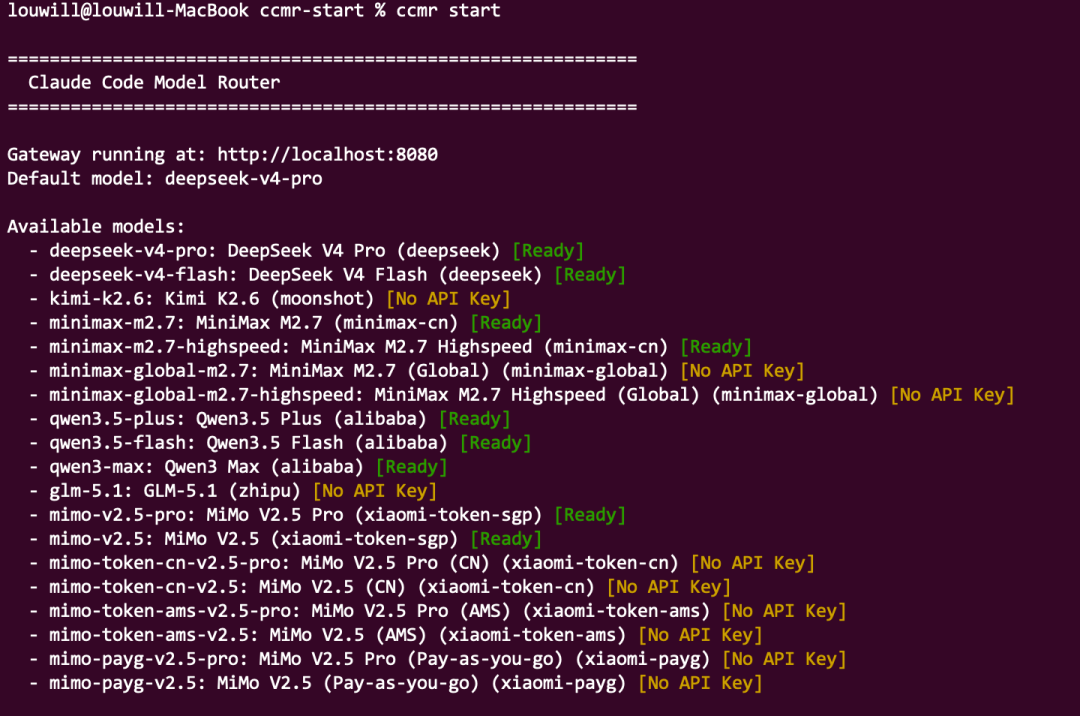
DeRonin 在原文里给了一份路由配置,但说实话写得比较敷衍。这块我正好有现成的工具,是我去年自己用 Claude Code Vibe 出来的,叫 ccmr,全名 Claude Code Model Router。更详细的内容参考:ccmr 更新,同步支持 DeepSeek V4/Kimi K2.6/MiMo v2.5 Pro 等六大国产模型任意切换。
它解决的就是这个痛点:Claude Code 订阅用户配了国产模型 API 之后,整个 Claude Code 就被国产模型接管了,没法再切回 Opus。ccmr 把第三方模型单独走一个网关,跟你的 Claude 订阅完全隔离,互不干扰。
用起来就三步。先装:
npm install -g claude-code-model-router
然后初始化,这一步会生成一个 .env 文件,把你在各家模型平台拿到的 API key 填进去:
ccmr init
最后启动网关,再开一个新终端进入:
ccmr start
ccmr claude
进去之后用 /model 切模型,比如 /model deepseek-v4-pro[1m] 切到 DeepSeek V4,/model kimi 切到 Kimi。而你原来走订阅的 Claude Code 终端,照常用 Opus、Sonnet,两边完全隔离。
但路由这件事,我得提醒一句:砍浪费和砍模型,是两件不一样的事。
砍浪费砍的是重复,砍模型砍的可能是判断力。我之前在 20 刀是大多数人愿意为 AI 付费的上限 里表达过一个观点:为了省一点钱,用一个 90 分的模型替掉 100 分的模型,省下的是钱,浪费掉的却是你最稀缺的判断力和时间。
DeRonin 自己也给了一条挺到位的规则:给模型定价,要按出错的代价来定,不是按这次调用的价格来定。一个架构决策错了,可能让你搭进去一整周;一个格式化错了,三十秒就能修回来。
所以路由的时候,架构设计、安全审查、复杂重构这种一步错步步错的活,老老实实留给顶配模型,这个钱省不得。
token 经济学说到底,是一种把账单看明白的能力。先用 ccusage 看清楚 token 消耗分布,再把缓存、grep、压缩、本地模型这些漏洞一项项堵上,最后用路由把活分给对的模型。DeRonin 那篇文章标题写的是省掉 80% 的账单,但你真的照着做会发现,省下来的大头不是因为你变抠了,而是因为你之前花的那部分,本来就不该花。
但是话又说回来,肯定有很多富哥跟我一样,每天的 token 消耗不完,即使每天 5 亿的量,仍然用不完,那么请移步右上角,关闭本文,这篇文章对你没有参考价值。想交流更多省钱技巧?来云栈社区和开发者们一起聊聊。
 发表于 2026-5-15 02:26:40
|
查看: 143|
回复: 0
发表于 2026-5-15 02:26:40
|
查看: 143|
回复: 0
