在日常处理报表或合同文件时,有多少次你曾对着排版规整的PDF表格发愁——明明屏幕上线条分明,可一复制粘贴到Excel就糊成一团?这种纯体力搬运,不仅效率低下,还极易出错。有没有办法既保留本地隐私,又能像操作Excel一样“画个框”就把数据提出来?答案是可以的,而且方法比想象中简单。
Excalibur到底是个啥
Excalibur是一个基于Python3的网页界面工具,专门用来从文本型PDF里“挖掘”表格数据。它底层的核心引擎是Camelot,这个库在表格检测和自动校正方面已经做了大量工作。整个工具只在本地自托管运行,意味着你上传的所有文件和提取出的数据都不会离开自己的机器。
它的能力边界很清楚:
- 仅处理文本型PDF(可以用鼠标选中文字的那种),不碰扫描件
- 完全是网页操作,不需要写一行代码
- 安全自托管,商业文件也毫无外泄风险
它能解决哪些痛点
平时从PDF拿表格,最常见的痛苦无非这几样:
- 直接复制到Excel,行列结构完全对不上
- 遇到多页表格,手动框选、敲数又累又容易出错
- 市面上的在线服务要么担心数据隐私,要么处理量有限制还要收费
- 同一模板的季度报表,每次都要重复同样的选区操作
Excalibur给出的方案相当直接:
- 网页界面内可视化操作,支持拖拽选区,也可以一键自动检测表格
- 内置“Lattice”(基于线条)和“Stream”(基于空白间距)两种识别模式,能适应不同风格的排布
- 一旦调整好某个PDF的提取规则,直接保存下来,下次遇到同类文件就能一键复用
- 导出格式覆盖了CSV、Excel、JSON和HTML,数据分析师总能找到自己趁手的那一种
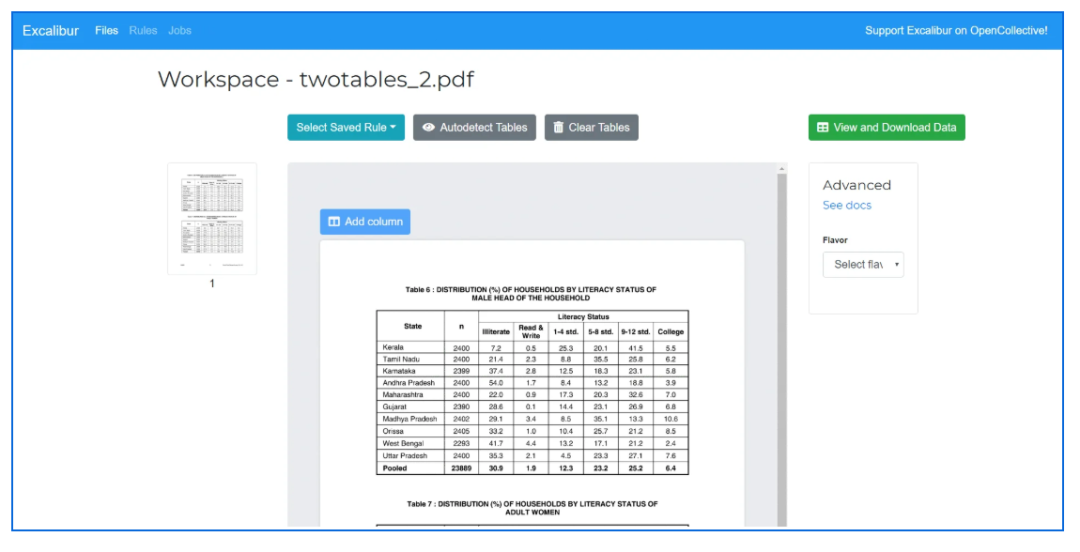
安装和上手指南
正式安装前,需要先准备好Ghostscript,因为它是Camelot的核心依赖。无论是Windows还是Linux,都可以直接下载对应的可执行包安装,想更灵活就走pip安装。
1. 通过pip一键安装Excalibur
pip install excalibur-py
2. 初始化数据库
excalibur initdb
3. 启动网页服务
excalibur webserver
服务启动后,在浏览器中打开 http://localhost:5000,就可以上传PDF了。指定目标页码范围,在预览界面上用鼠标框选表格区域,或者干脆点“Autodetect tables”让系统自动识别。随后,在“高级”选项中根表格线条情况选择Lattice或Stream模式,最后点击“View and download data”,挑选自己喜欢的格式,数据就到手了。
优缺点大盘点
下面的表格把它的适用边界理得更清楚一些:
| 优势 |
劣势 |
| 可视化界面,零门槛拖拽选区 |
仅支持文本型PDF,不识别扫描件 |
| 两种提取模式(Lattice/Stream)可选 |
大文件或复杂表格处理速度稍慢 |
| 规则可保存复用,对批量处理友好 |
必须预先安装 Ghostscript |
| 数据完全在本地处理,隐私安全 |
默认sqlite+多进程,分布式部署需额外配置 |
| 导出格式丰富:CSV/Excel/JSON/HTML |
界面可定制化程度有限 |
给你的总结
说真的,PDF表格提取这件事,很少有人不曾头疼过。Excalibur像一把趁手的“数据挖掘剑”,帮你一次性搞定大部分重复枯燥的操作。把它部署在本地或一台服务器上,你就有了一个稳定的私有表格提取站。
它尤其适合这几类场景:
- 经常与账单、报表、合同表格打交道的财务或审计同仁
- 需要批量处理同类型PDF表格的研发或数据分析人员
- 高度重视商业文件机密,绝不希望将其上传到任何云端服务的企业
当然,工具也不是万能的。遇到扫描件就直接绕道,表格框线极度复杂的文档偶尔也会识别不准。不过多数情况下,在Lattice和Stream两种模式间多试一次,或者手动微调,通常都能搞定。
如果你还在为PDF转表格这种体力活抓狂,不如现在就去试试这个开源实战中的好工具。自己实战一把,效率翻倍,数据提取再也不会是一团乱麻了。
项目地址:https://github.com/camelot-dev/excalibur
如果你对Python生态里的各种提效工具感兴趣,在云栈社区也常能找到同好们的深入讨论与避坑经验。 |  发表于 2026-5-15 02:51:42
|
查看: 111|
回复: 0
发表于 2026-5-15 02:51:42
|
查看: 111|
回复: 0
