LLM 的基本工作流程
为了简化理解,本文中 LLM 只表示文本式生成大语言模型。
LLM 本质上是一个 上下文 Token 序列 → 下一个 Token 的函数。
LLM 的参数本身不保存任何对话状态,所有 "记忆" 都依赖于每次调用时显式传入的 Token 序列,也就是我们常说的 Context Window(上下文窗口)。
同时,LLM 并不会一次性预测整段整句文本输出,它每次预测的基本单元是 Token——原始文本经过分词器(Tokenizer)切分后得到的最小语言单元,而非字、词或句子。
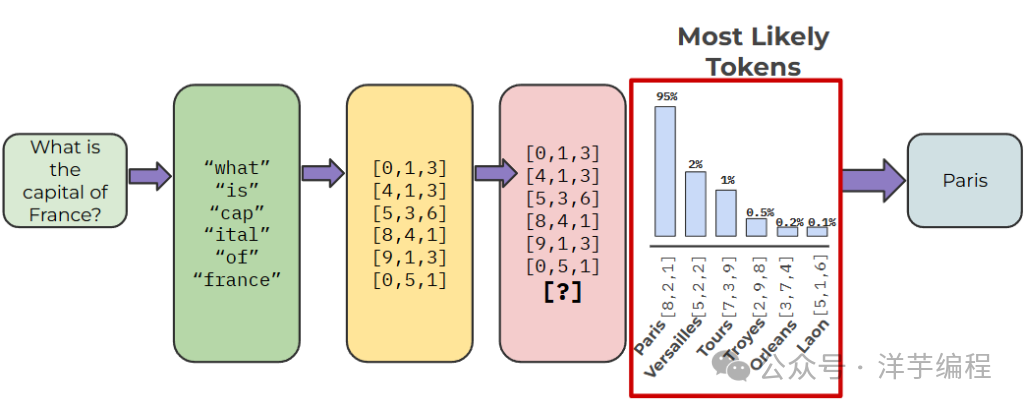
当用户向 LLM 发送一段 prompt 后,LLM 内部的工作流程可以简化为:
- Tokenization(分词)
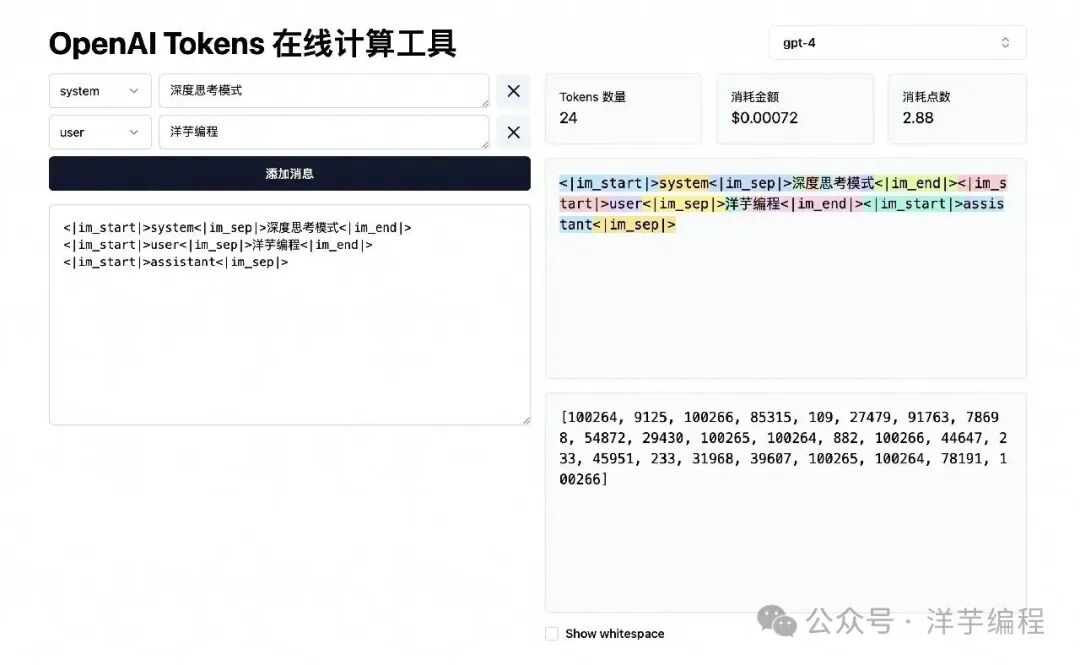
用户输入的 prompt 自然语言文本首先被 Tokenizer 切分为一个 Token ID 序列。
例如,"洋芋编程" 四个字可以转化为如下的 Token 序列:
- Embedding(嵌入向量)
每个 Token ID 被映射为一个高维稠密向量(Embedding),这种语义表示形式让 LLM 可以对输入 prompt 文本进行数学运算。
- 前向传播(Forward Pass)
Token 向量序列经过若干层 Transformer Block 的处理:
- Self-Attention:每个 Token 与上下文中所有其他 Token 计算注意力权重,捕捉全局中的语义依赖关系
- Feed-Forward Network:对注意力输出做进一步的非线性变换
- Layer Normalization & 残差连接:保证训练稳定性
- Logits 输出与概率采样
最后一层的输出向量经过线性变换映射到整个词表大小的 Logits 向量,再经过 Softmax 转换为概率分布。
LLM 从这个概率分布中采样(或取最大概率)得到下一个 Token。
- 自回归循环(Auto Regressive Loop)
将新生成的 Token 追加到输入序列末尾,重复步骤 ①-④,直到生成终止符(EOS Token)或达到 Context Window 的最大长度限制。
LLM 中的其他所有细节——微调、校准、安全层、工具使用等等,都是建立在这个看似简单却强大的流程之上。
这就是每个 LLM 的核心本质。
顺便一提,网上很多把 LLM 的工作过程类比并简化为基于概率的 "成语接龙"(结果不是 100% 正确),但这其中存在很大的误导性:成语接龙是首尾字衔接的规则游戏,强调的是最后一个字的 "局部匹配",而 LLM 的自回归生成是基于全部历史 Token 的联合概率分布来预测下一个 Token,强调的是全局上下文感知。这其中的核心就是 Transformer 中 Attention 机制对全局上下文的建模能力。
不足之处
当然,由于上述的工作机制,LLM 存在以下固有缺陷:
| 局限 |
具体表现 |
| 知识截止 |
对训练截止日期后的事件一无所知 |
| Context 上下文有限 |
Token 数量有硬性上限(如 4K / 128K Token),超出窗口的历史信息会被截断丢失,模型无法真正拥有"长期记忆" |
| 没有记忆 |
每次对话独立,不记得上次说了什么,多轮对话的"记忆"完全依赖将历史内容重新塞入 Context Window,这既消耗 Token 配额,同时也受限于窗口大小 |
| 没有行动能力 |
只能输出文字,不能操作外部系统 |
| 推理深度不足 |
模型逐 Token 自回归生成,本质是模式匹配与概率延续,复杂推理链条越长,多步骤任务更容易出错或中断 |
| 幻觉 |
LLM 本质上是在做概率预测,而非查询事实数据库,不知道的事情会编造,缺乏事实核查 |
| 对输入高度敏感 |
即使是相同语义、不同措辞的 prompt,都可能产生截然不同的输出 |
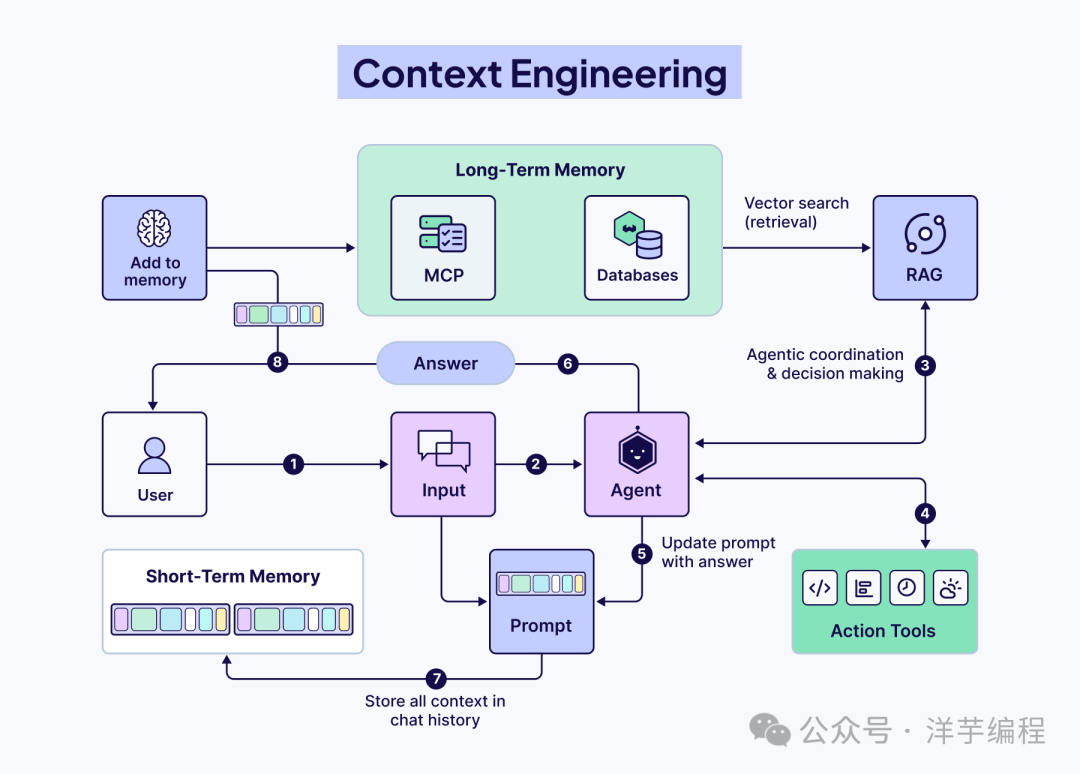
对 LLM 而言,上下文管理(Context Engineering)最为重要,合理利用好上下文,最终的 LLM 输出效果上会有质的飞跃。
权衡和调优
为了解决 LLM 这些固有问题,业界又分别引入了 Agent、Skill、Memory 以及 Harness Engineering。
四者紧密配合,通过 Harness Engineering 围绕 LLM 调用构建工程化封装层,精心设计输入结构、约束输出格式、管理 Context 上下文输入输出流,系统性地提升 LLM 的稳定性和可靠性。
- 知识截止 → 可以通过 Agent(主动搜索)、Skill(实时第三方 API)、Harness(注入实时上下文)等方法来解决
- 上下文有限和没有记忆 → 都可以通过 Memory(外部持久化存储 + 按需检索),典型的例如 RAG,同时还可以在这个基础上增加 Harness(用户对话历史管理)
- 没有行动能力 → Skill 提供具体的可执行工具(如内部二进制可执行文件),然后 Agent 完成决策和调用
- 推理深度不足 → Harness 统筹完成 Chain of Thought(思维链)注入,Agent 完成任务拆解 + 循环验证,Skill 负责子任务的具体执行,Memory 提供整个任务所有的中间状态数据存储
- 幻觉 → Harness 通过
System Prompt 实现结构化约束 + 重试,Agent 完成对结果进行外部验证,Skill 负责使用确定性的工具来替代 LLM 输出的概率预测,Memory 提供验证的基准锚点
- 输入高度敏感 → Harness 指导 Agent 进行多步纠偏
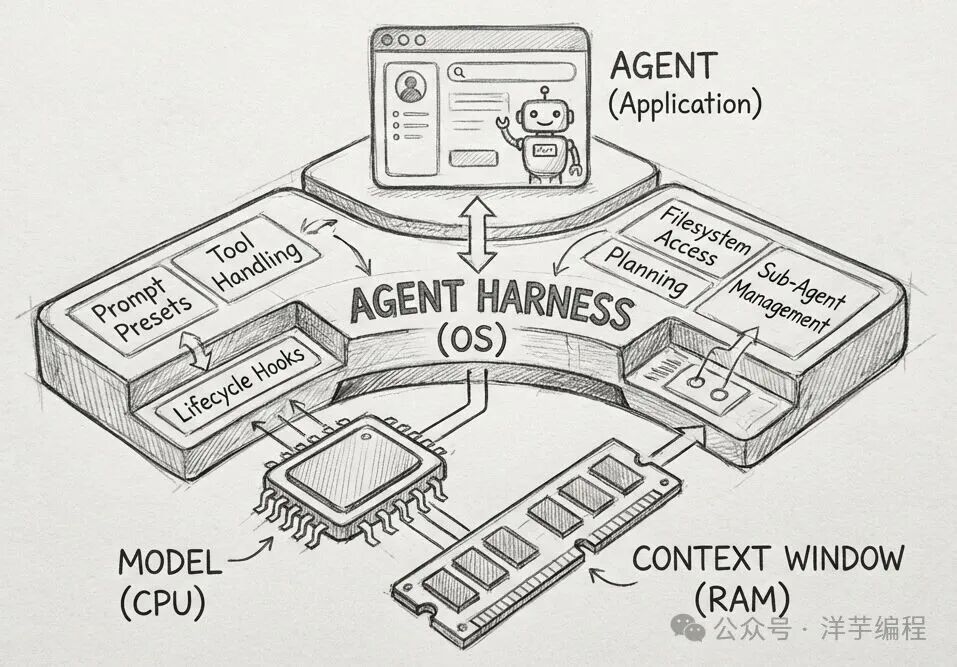
一个简单形象(但不是非常精确)的比喻是:LLM 是 CPU,上下文窗口是内存,Harness Engineering 是操作系统 + 标准库(libc),Agent 是应用程序,Skill 是动态链接库(.so / .dll)+ 系统调用(syscall)+ 开源组件库 + 第三方 API,Memory 是硬盘/持久化存储、外部数据库,关系型/KV/文档/向量等等数据库。
看到这里,是不是突然发现,很多高大上的新名词、新技术不过就是新瓶装老酒?就像古法编程中叫 DLL,后来叫 API,现在叫 MCP[^1] :-)
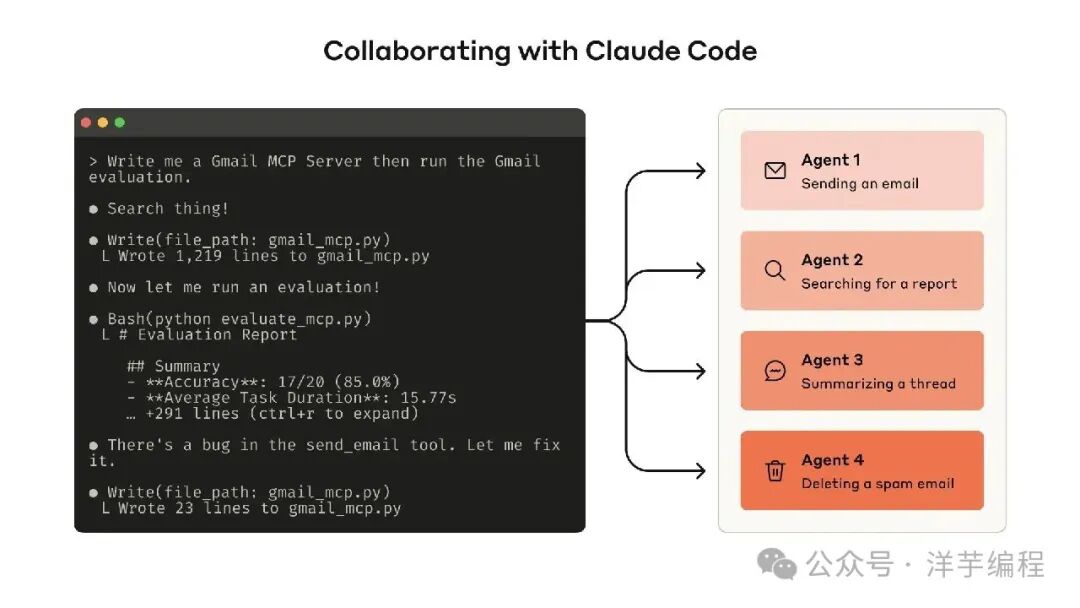
这里用一个业务场景来说明一下:
产品经理对 LLM 说:"分析一下上周我们产品的用户活跃数据,同时和跟竞品进行对比,写成报告发给我邮箱并抄送给运营"。
-
Harness Engineering
- 识别任务类型:数据查询 + 数据分析 + 竞品对比 + 报告生成 + 邮件发送
- 注入角色约束:你是一个数据分析助手
- 注入当前时间:2026-01-15,那么可以计算出上周时间 = 2026-01-06 ~ 2026-01-12
- 规定输出格式:结构化报告格式为 Markdown
-
Memory 检索
- 检索数据:知道产品是什么,数据库怎么查
- 检索竞品信息:知道怎么查询竞品数据(例如第三方 API)
-
Agent 开始 LLM 规划
- 子任务1:查询本产品上周留存数据
- 子任务2:搜索竞品最新公开数据
- 子任务3:对比分析
- 子任务4:生成报告
- 子任务5:发送邮件
-
Skill 执行
- 调用 MySQL Database Query Skill,返回精确留存数据
- 调用 Web Search Skill,返回竞品公开报告
- 调用 Python Code Skill,执行数据对比计算
- 调用 PDF Skill,根据数据生成报告
- 调用 Email Skill,发送最终报告
-
Harness 验证输出
- 报告格式符合指定格式?
- 邮件发送成功?
- 写入 Memory:本次报告结果存档,供下次对比使用
当然,一切没有银弹,这四种机制在解决旧问题的同时,也引入了新的复杂性:
- Agent 会导致反馈链路变长,错误可以级联放大,调用成本更高(需要消耗更多的 Token),甚至难以调试(如果人看不懂 AI 生成的代码),因为 Agent 是有状态的,错误会叠加,如果运行较长时间并且需要在多个工具调用中保持状态,一个微小的错误就可能直接把系统搞崩
- Skill 工具本身也可能执行失败或返回错误数据,出错的概率和工具数量成正比
- Memory 检索不准确时反而注入了不必要的噪音,如果涉及数据修改,还可能增加额外的安全风险
- Harness Engineering 中的 System Prompt 维护成本比较高,同时过度的约束反过来也会限制 LLM 的灵活性和能力边界
Agent

Agent 的核心作用就是把 LLM 从单次问答,变成一个持续规划和执行的 "控制程序"。
为什么需要?
传统的软件编码是通过条件规则(IF-ELSE, State-Machine ...)来控制 CPU 的逻辑执行流,Agent 可以处理更多不可预测的工作流程,例如决定什么时候查询数据库,什么时候通过第三方 API 来查询数据。
可以使用不同类型的 Agent,并且可以并发执行,更加符合人类团队的运作方式。
在面对不完整的数据时,Agent 可以自动整合信息并尝试自己解决。
例如在执行某个命令报错: command not found:,Agent 可以会尝试解决修复:根据当前的运行环境(例如 CentOS),执行对应的命令安装 yum install -y XXX(当然,这背后得益于 LLM 的能力)。
基于 Agent 的设计代表了应用软件开发在 LLM 的下一个演进,通过实现各种自动化工具和使用动态工作流程,Agent 能够处理固定硬编码中无法处理的复杂现实场景(虽然不知道是不是未来的主流,不过系统级别软件目前感觉好像还达不到?)。
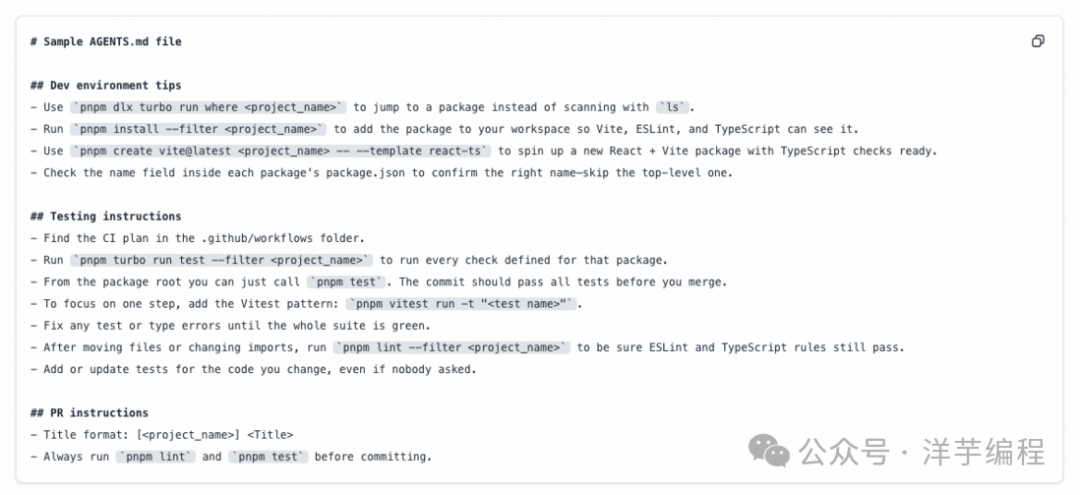
AGENTS.md
按照现代软件开发规范,既然项目中都已经有 README.md,为什么还需要再单独搞一个 AGENTS.md 呢?
因为 README.md 文件主要是给人看的,主要用于描述项目情况、QuickStart、如何贡献代码等内容。
而 AGENTS.md 是给 LLM 看的,主要用于给 Code Agent 提供精确的、足够的上下文:让 Agent 去实现编码、测试、CI/CD 等,同时在 Agent 的角度,对已有的 README.md 进行补充。
最重要的是,一个 AGENTS.md 可以同时调用多个 Agent。
一个典型的 AGENTS.md 文件内容如图所示:
同时,一个项目可以根据 Service、Module 等进行划分,然后附带不同的 AGENTS.md。

如果试图把所有 "重要" 的 Context 都写入 AGENTS.md 时,说明所有的 Context 都不重要。
AGENTS.md 的最佳实践是,不要将 AGENTS.md 视为百科全书,而是将其视为内容目录。
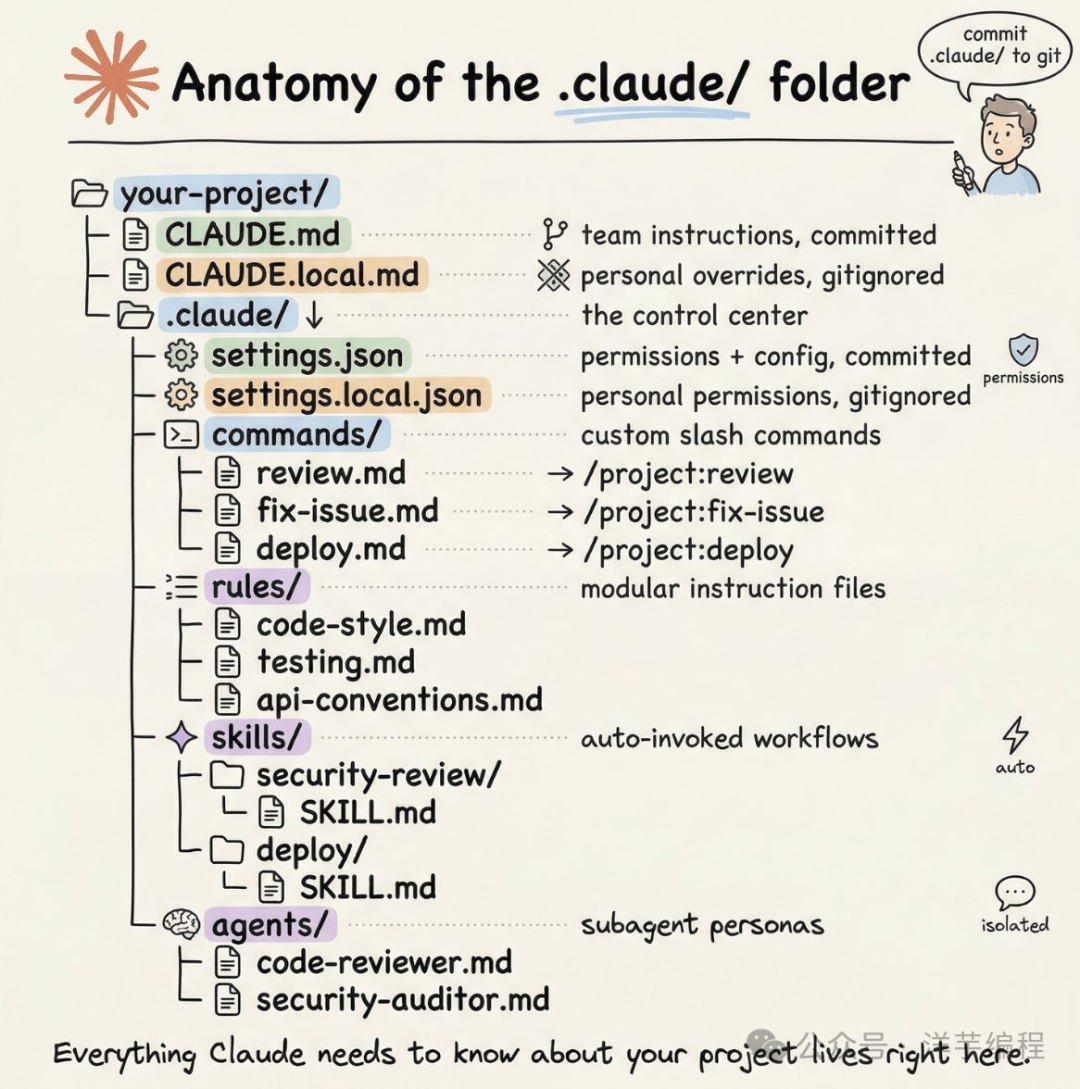
这篇文章[^2] 以 ClaudeCode Cli 为例,详细讲解了项目的目录文件风格布局。
高质量分享
ClaudeCode 官方分享的几篇高质量的 Coding Agent 博客:
- Building effective agents[^3]
- Writing effective tools for agents[^4]
- How we built our multi-agent research system
Cursor 官方分享的 Coding Agent 最佳实践[^5]
智普官方分享的 Coding Agent 最佳实践[^6]
Skill
SKILL 是一组行为确定、结果可预期的框架/工具/服务/脚手架,Agent 负责决策 "用哪个工具、传什么参数",工具本身的执行是确定性的,不存在概率。通过 Skill,就可以对重复的工作流程进行打包,并在不同的 Agent 中使用相同的 Skill。
例如,让 LLM 直接计算 sin(45°) 可能产生幻觉,但是直接调用 Python 命令行,可以直接计算出 0.7071067811865476。
一个 Skill 对应的文件布局形式就是:
my-Skill/
├── Skill.md # (必要文件): 元数据 + 指令 (prompt)
├── scripts/ # (可选文件): 存放可执行的自动化脚本文件,一般指代码
├── references/ # (可选文件): 存放针对功能/工作流的更详尽的文档
└── assets/ # (可选文件): 存放数据资源、数据模板等
例如,一个知名的用于测试 Python 代码的 Skill:
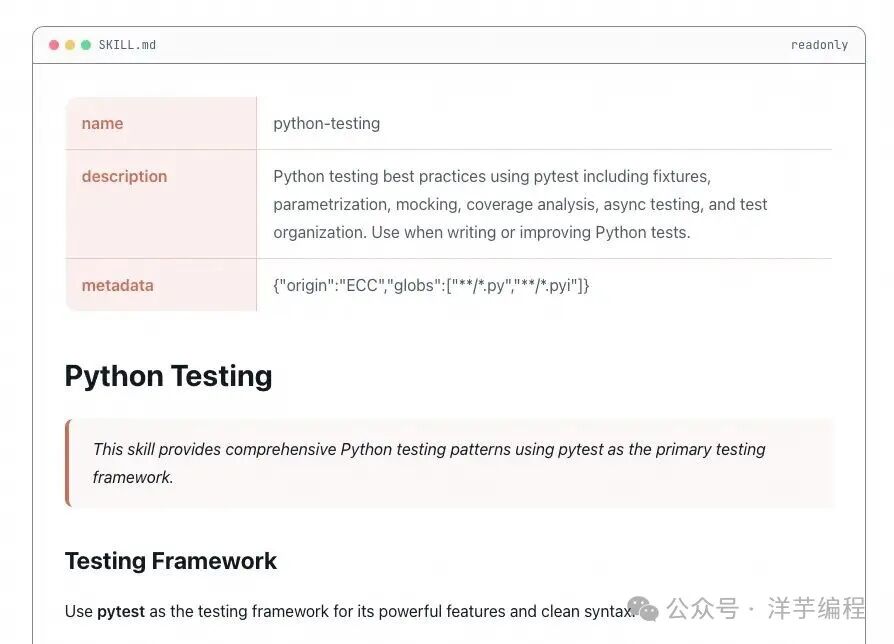
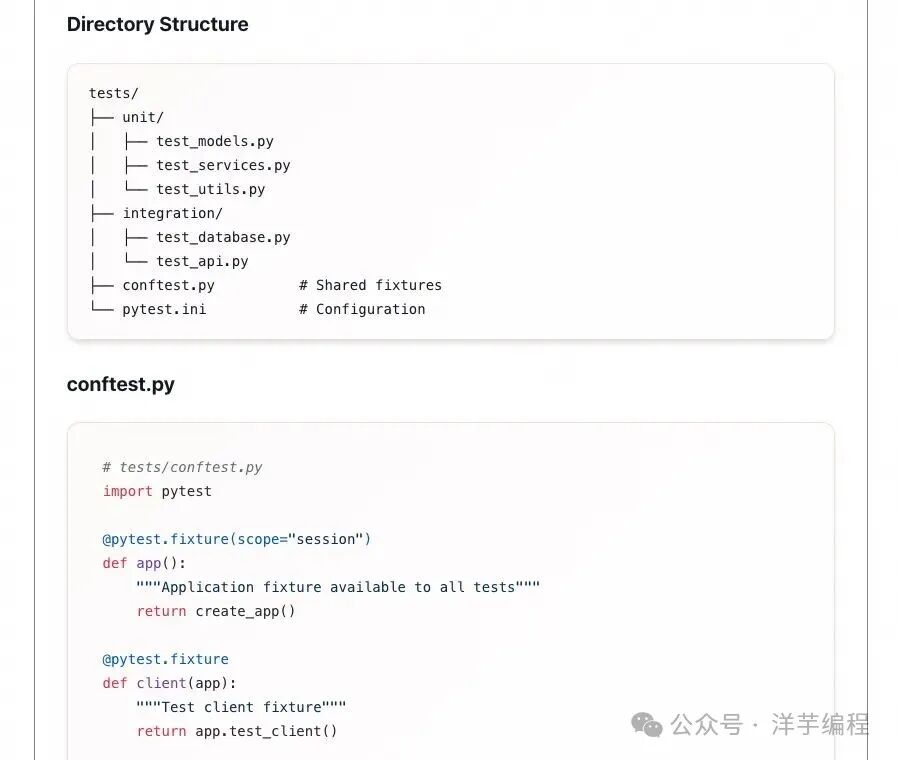
在 Skill 子目录中,又可以包含更多的 Skill 脚本:
最佳实践
因为 Skill 在 Harness Engineering 体系中属于相对独立和原子的部分,也是大多数开发者日常中编写最多的,所以这里专门留一个较长的篇幅出来,分享一下我的经验和心得(心急的朋友可以直接跳过,阅读后面的部分)。
写好描述信息
Skill 只有在被激活时才能发挥作用。
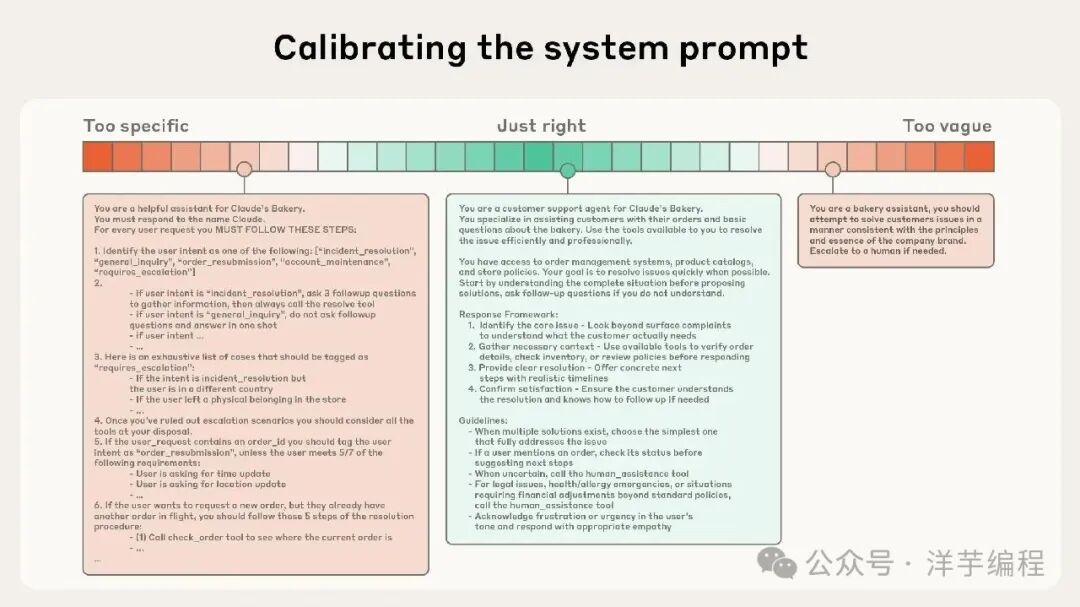
指令光谱
Skill.md 文件中的描述字段是 Agent 决定是否加载技能的主要机制,如果描述不够明确,意味着 Skill 可能不会触发;反过来说,过于宽泛的描述,也会导致 Skill 在不该触发时触发。
设计目标而非具体实现
不要过于笼统,也不要过于细节,努力平衡好自下而上和自上而下。
甚至对于不追求结果产出质量,只要求结果正确的任务,不要太在意过程,去掉洁癖,睁一只眼闭一只眼。
Talk is cheap, Code is cheap.
不要自以为是
既然 LLM 已经训练学习了人类绝大部分的显性知识,那么 Agent 的能力也必然是要大于我们的,那么最重要的就是要记住:
给 Agent 补充缺乏的、特定领域的知识,省略它所知道的通用知识。
Agent 不会知道的部分:项目的主要用户/客户、特定的测试用例、领域特定的流程、不是那么显而易见的边界情况,以及内部特有的工具或 API。
反过来也一样,你不需要向 Agent 解释什么是 PDF、HTTP 是如何工作的,或者数据库迁移是做什么的,但是你需要告诉 Agent 数据库迁移具体要做哪些工作,数据库和表之间的映射关系等,剩下的 LLM 自然知道怎么处理,而且很快就会举一反三。
例如,我们可以通过项目已经有的功能,给予 Agent 不同的反馈:
/health 接口正常情况下,应该返回 200- 数据表中的
created_at 字段不能为 NULL
- 这段代码的运行环境是单线程/多线程
流水线
尽可能将每个独立的功能放在一个 Skill.md 文件中,保持在 500 行和 5000 个 token 以内,这就需要我们不断精简,仅保留 Agent 每次运行所需要的核心指令。如果 Skill 确实需要更多内容,可以把详细的参考资料移到参考文件中。
这个也算是常见的软件工程优化方案了,提升性能和稳定性,通过尽可能小的 Skill 单位进行 "原子化" 组合,同时控制 "爆炸半径",将问题控制在局部。
例如像这样的串行流水线中,Skill 只需要描述具体需要执行的文件即可:
## 报告生成工作流
- [ ] Step 1: 分析脚本 (run `scripts/analyze_form.py`)
- [ ] Step 2: 数据字段映射 (edit `fields.json`)
- [ ] Step 3: 验证结果 (run `scripts/validate_fields.py`)
- [ ] Step 4: 生成结果 (run `scripts/fill_form.py`)
- [ ] Step 5: 验证输出格式 (run `scripts/verify_output.py`)
在此基础上,甚至可以像 Airflow 那样,定义更加复杂的 DAG 任务流水线:
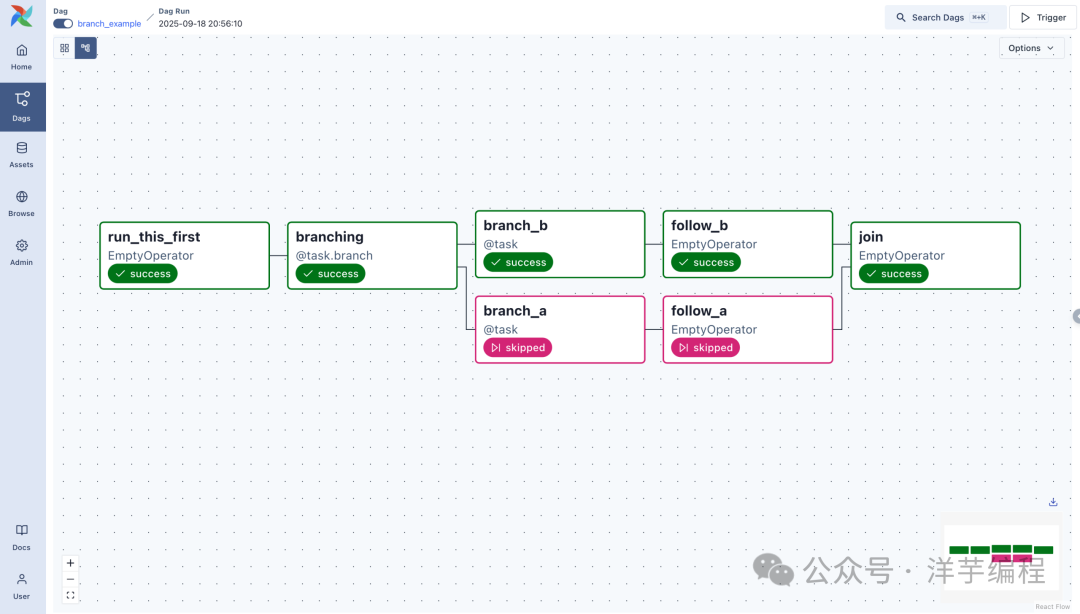
模板化
提供指定的模板。
这比人类文字描述的格式更可靠,因为 Agent 天然擅长和具体结构进行模式匹配。
例如将测试结果进行各种模板化配置,然后让 Agent 自动填充内容:
## 报告的固定文本结构
```markdown
# [标题]
## 概述
{一段文本内容}
## 各项指标
1. XXX
2. XXX
## 改进建议
1. XXX
2. XXX
不要为了 Skill 而 Skill
不要过度使用 Skill 来实现 Skill(递归了?)。
充分利用好已有的自动化工具,不要一想到自动化工具,就是新开一个 Skill。
例如在 CI 中,代码必须要通过 lint,这里直接调用编程语言对应的 lint 工具,就可以完成需要的代码风格/格式化审查工作。

另外,一个更加朴素的视角是,把 Skill 当作一个需要封装的 class, function 来看待,如果现成的工具(例如 Claude Code Cli, CodeX 等)已经实现了需要的功能时,或者只是需要处理一个临时的功能时,咱也别 Skill 了,直接用好现成工具就够了,不要重复造 Skill。
再比如,在开发环境中,常见的数据格式结构化通过 Unix 标准工具集(jq、cut、awk ...)就基本足够了,根本不需要再花时间让 Agent/LLM 处理。
自我验证与修正
Skill 本质上和人类学习知识的过程一样,高效的学习过程包括:
- 高质量、详尽的学习资料
- 正确的学习路线,例如大学专业课程表中常见(先后顺序)的拓扑结构,计算机编程语言 -> 计算机体系结构 -> 离散数学 -> 数据结构和算法
- 正反馈和负反馈
- 持续运行这个循环
我们可以模仿这个过程去编写 Skill,说起来,这个过程非常像 TDD(测试驱动开发):
# TDD workflow
1. 写点代码
2. 运行测试
3. 如果测试没通过:
- 查看报错
- 尝试修正
- 再次运行测试
4. 增加更多测试代码
5. 重复 1 - 4, 直到所有测试都通过
认真沟通和写字
曾经有位英语老师对我说:
不是你的英文不好,而是你的中文更差!
我自己写 Skill 的一个感受是:强调逻辑,而非强调语气和情绪,直接给出精确的执行指令即可,不需要说 "请" "帮忙" 等祈使句语气助词,不断调整/优化、消除太过 "宽泛" 或 "狭义" 的 Skill 指令。
写一个 Fibonacci 数列的实现,并加上单元测试。
问题:缺少语言/版本、接口形式、边界条件、测试框架、异常策略、性能要求等,LLM 输出容易跑偏。
请用 Python 3.11 编写 `fib(n: int) -> int`,必须使用递归且不能使用任何循环;当 `n<0` 时抛出 `ValueError("n must be non-negative")`;当 `n==0` 返回 0、`n==1` 返回 1;代码必须不超过 12 行(不含空行和注释);必须使用 `pytest==7.4.0` 写 9 个测试用例,测试函数名必须是 `test_case_1` 到 `test_case_9`;每个测试里只能有一个 `assert`;测试必须覆盖 n=0..7、n=-1、n=30;并且要求运行时间小于 1ms。
问题:约束太多且部分互相冲突/不合理(递归 + 大 n + 1ms),限制输出空间,导致难以得到高质量答案。
使用 **Python 3.12** 实现 Fibonacci:
1. 提供函数 `fib(n: int) -> int`,返回第 n 项(定义:fib(0)=0, fib(1)=1)
2. 当 `n < 0` 时抛出 `ValueError`
3. 实现应为迭代版(避免指数递归爆炸),能处理到至少 n=10_000(结果可用 Python 大整数表示)
4. 使用 **pytest** 编写单元测试,覆盖 n=-1 异常、n=0/1/2/10 的正确性、以及 n=100 的一个已知值校验(可在测试里写死常量)
5. 输出两个代码块:`fib.py` 与 `test_fib.py`,不需要其他额外解释
这个指令同时说明了:语言版本、接口定义、错误处理、实现策略、性能预期、测试框架与覆盖点、以及输出格式。
健壮的 Skill 指令,应该在大多数 LLM 上的大多数输出结果中基本保持一致;反过来,脆弱的指令,稍微变动,输出结果就截然不同。
语言的正确表述程度 * LLM 能力 = 需求/功能正确完成的概率 (%)
主流 Skill 聚集地
根据细节,选择适合你的品味的各种 Skill。
- Anthropic Skills[^7]
- Agent Skills io[^8]
- Agents-and-tools[^9]
- Skills map[^10]
- Skills so[^11]
- Skills sh[^12]
Memory
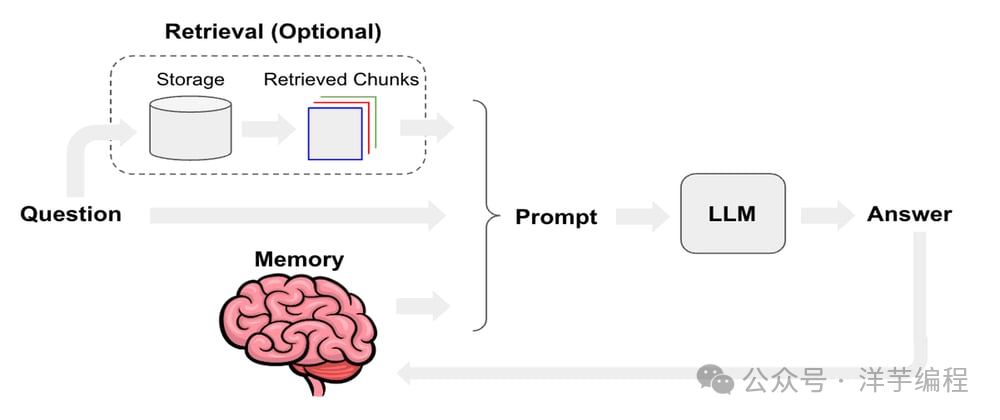
Memory 是将 LLM 天生无状态的特性,通过外部持久化存储系统来弥补,构建出跨对话、跨会话的持久记忆能力。
四种层次:
- In-Context Memory(上下文内记忆):直接放在 prompt 里,最快,但也受到上下文窗口大小限制
- External Memory(外部数据库记忆):关系型 / 向量 / KV Store / Graph 数据库
- In-Weights Memory(权重内记忆):Fine-tuning 直接把知识写进模型参数(矩阵)
- In-Cache Memory(KV Cache 记忆):缓存注意力计算结果,加速重复上下文计算
通过 Memory,可以解决 "记忆丢失" 的问题:
用户第一次对话:
"我叫洋芋,我在做一个 AI 前端项目,用 Next.js"
Memory 系统提取并存储:
{ user: "洋芋", project: "AI/前端", stack: "Next.js" }
过了三天,用户再次对话:
"昨天那个问题解决了"
Memory 系统检索注入上下文 ...
LLM 了解到:洋芋、AI 前端项目、Next.js、之前讨论过什么东西
同时,Memory 检索本身也需要成本,所以 Memory 也会按需检索,不会一次性把所有历史都塞进 Context Window,而是只检索和当前 prompt 最相关的内容。
例如,历史对话一共 10000 条(无法全部放入 128K 窗口),那么 Memory 会向量化存储到外部数据库;当用户提问:"Next.js 路由怎么配置?" 找到历史中与 Next.js、路由相关的 5 条记录,只注入这 5 条,这也是 RAG 的核心机制。

对 Memory 感兴趣的同学,可以看看这个开源项目[^13]。
Harness Engineering
Harness Engineering(也称为 Prompt Engineering、System Prompt Engineering)是围绕 LLM 调用的工程化封装层,精心设计输入结构、约束输出格式、管理上下文输入输出流,来系统性地提升 LLM 的稳定性和可靠性。
Harness Engineering 把用户提交的、自由不稳定输入,转化为经过工程化设计的标准输入。
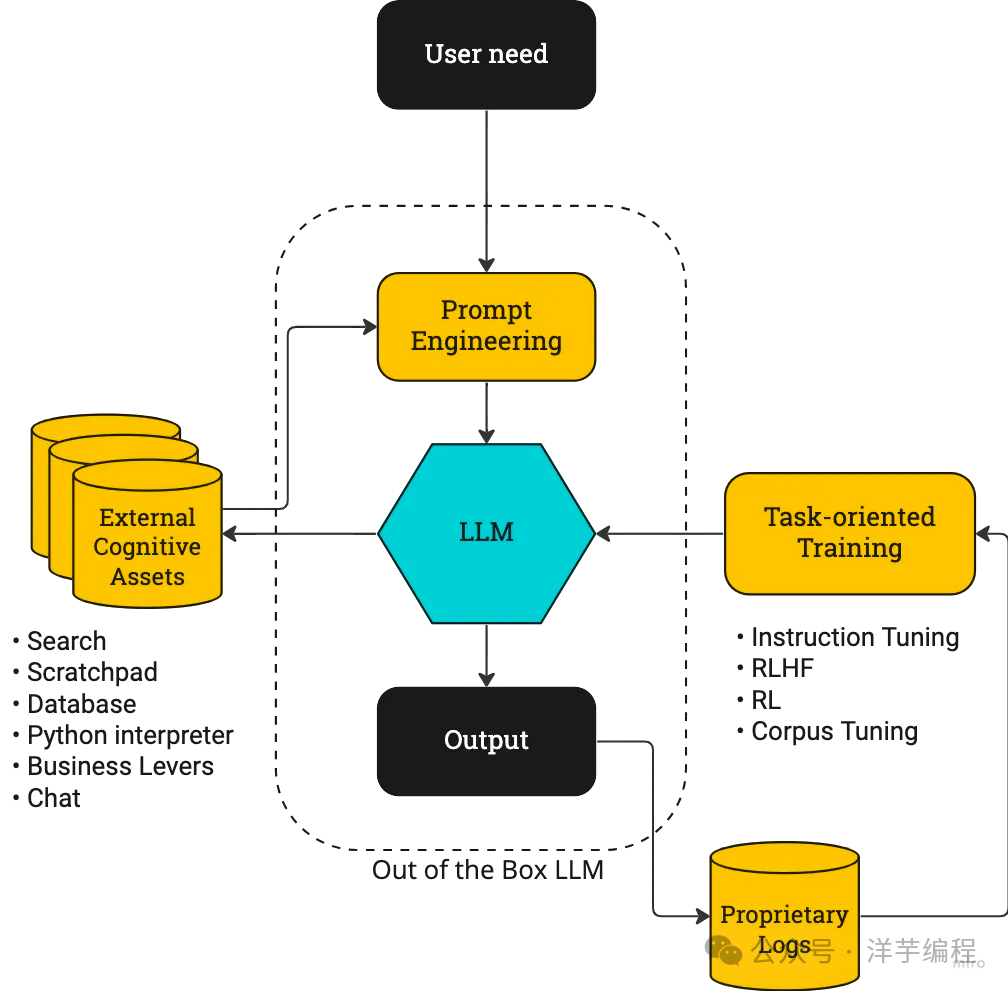
例如,一个最简单的只做输入/输出校验的 Harness 工作流程可以描述为:
- [ Harness 层 ]
- 接收用户原始输入
- System Prompt 注入角色和约束
- 历史对话压缩和管理
- 输出格式强制约定(例如 JSON Schema)
- 示例注入
- Chain of Thought 触发
- 安全过滤
- 等等
中间完成结构化 prompt 指令,然后 Agent 调用 LLM 处理,并接收结构化的输出。
- [ Harness 层 ]
最终返回可用的结果给到用户。
除此之外,在推理链条更长的情况下,Harness Engineering 会通过 Chain of Thought(思维链)主动进行注入,将问题分解为具体的步骤 1、步骤 2...,当对话历史过长时,Harness 自动对早期对话进行摘要快照(保留语义,减少 Token),动态分配 Token 预算给不同部分。
例如,我们可以给 Harness 增加非常明确的约束条件:
除非用户明确要求提供计划或其他明确表示不应编写代码的意图,否则应假定用户希望你进行代码更改或运行工具来解决用户的问题。在这些情况下,在消息中输出你提议的解决方案没有必要,你应该直接实施修改。如果遇到挑战或障碍,你应该尝试自行解决。
一个典型的项目的代码仓库,Harness Engineering 内部的知识文档存储,AGENTS.md 文件和目录布局,看起来就像这样:
AGENTS.md # 目录 Agent
ARCHITECTURE.md # 架构文档
docs/
├── design-docs/ # 设计文档目录
│ ├── index.md
│ ├── core-beliefs.md
│ └── ...
├── exec-plans/ # 计划文档目录
│ ├── active/
│ ├── completed/
│ └── tech-debt-tracker.md
├── generated/
│ └── db-schema.md
├── product-specs/
│ ├── index.md
│ ├── new-user-onboarding.md
│ └── ...
├── references/
│ ├── design-system-reference-llms.txt
│ ├── nixpacks-llms.txt
│ ├── uv-llms.txt
│ └── ...
├── DESIGN.md
├── FRONTEND.md
├── PLANS.md
├── PRODUCT_SENSE.md
├── QUALITY_SCORE.md
├── RELIABILITY.md
└── SECURITY.md
在 OpenAI 的分享中[^14],整个代码库全部由 Agent 生成,包括但不限于:
- 产品代码与测试
- CI 配置和发布工具
- 内部开发者工具
- 文档和设计历史
- 评估框架
- 审阅评论和回复
- 管理代码仓库本身的脚本
- 生产仪表板定义文件
分享中也提到了,生成的代码有时候不符合人类的风格偏好和 "品味",这也没关系。只要输出是正确的、可维护的,并且对未来的 Agent 运行而言清晰易读,就可以算作达标。Harness Engineering 要专注于界限、正确性和可重复性,在边界内,允许 Agent 在解决方案的表达方式上拥有尽可能大的自由。

ClaudeCode 官方分享的 Harness Engineering 工程实践[^15]
此外,对 Harness Engineering 感兴趣的同学,可以看看这个开源项目[^16],还有这个热门项目[^17]。
肢解龙虾
有了前文中所有的这些基础后,我们分分钟就可以 "肢解" 龙虾(OpenClaw),分析它的基本构造和实现,了解一下 "全民养虾" 背后的这只虾到底是什么。
龙虾一夜间爆火,是因为它有个聪明的想法——把上下文整个存储在一个大的文本文件里,并循环调用 LLM。
早期的用户几乎是夜间运行 Agent,疯狂燃烧 Token,层出不穷的新的 Skill 生态系统大大提升了使用效果。而且,只需买一台 Mac Mini 本地运行(一个开源的)LLM,你就能通过 iMessage 远程指挥,一切都是免费的,然后 Mac Mini 就开始了涨价和断供...

Mac Mini 配送周期
层层肢解之后,龙虾其实就只一个软件,一个套壳儿软件,一个 LLM 应用的包装。
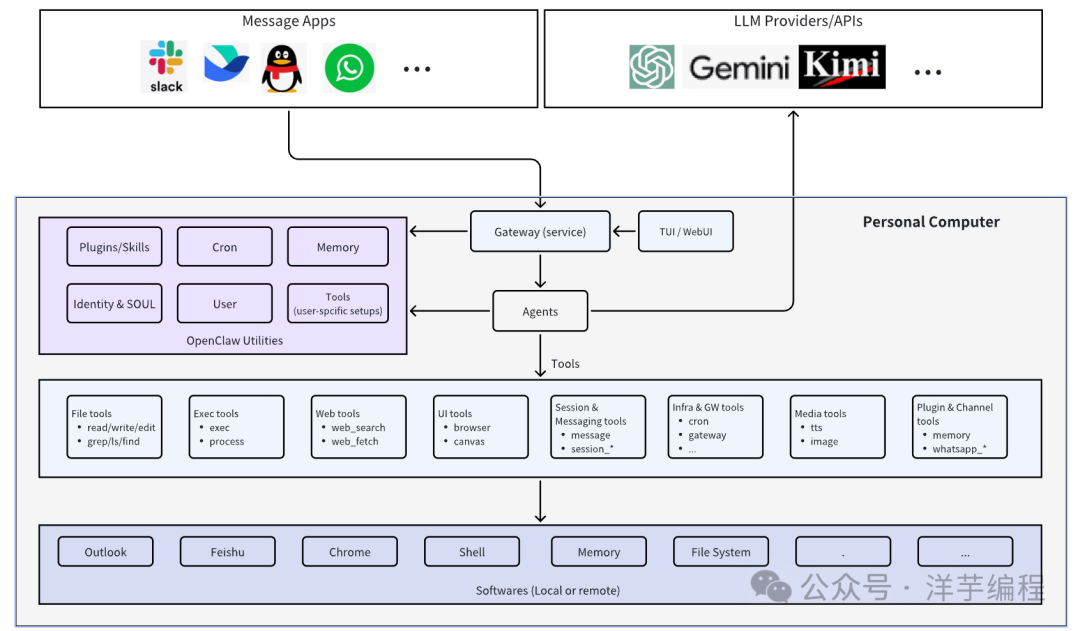
龙虾(claw agent) = Agent Core + Heartbeat(心跳机制) + Cron + IM chat + memory + soul
- Agent Core(核心大脑):不难理解,就是决策与推理中枢
- Heartbeat(心跳机制):定时向系统发送信号进行检测,保证系统 "正常活着"
- Cron(定时调度器):周期性自动执行任务,Agent 从被动响应变为主动执行
- IM Chat(即时通信接口):人机远程进行交互的接口,例如可以接入企业微信、飞书、公司内部的 IM 系统
- Memory(记忆系统):上文中提到过的持久化存储系统
- Soul(定义行为风格与价值约束):一个比较抽象的组件,但很重要,可以根据使用者的习惯偏好来定义行为准则、语气风格、决策边界等
总结
Agent 不知疲倦且能力可以吊打 99% 的程序员,但它的效能取决于你的应用,所以 "好代码" 依然至关重要啊,从这个角度来看,AI 会倒逼你产出更好的代码[^18]。
从行业的发展来看,LLM Code Agent 的这种模式,开始真正让软件开发正本清源,从需求、设计、文档、代码、测试等传统流程几乎全部可以交给 Agent,人只需要把必须做的事情做好——规划、决策、设计、流程化、验证等,剩下的全部交给 Agent。

从此没有屎山代码,没有一把梭,没有大力出奇迹,没有口口相传的文档(以前是人给人写文档,不想写,所以强制人给 Agent 写文档)。通过这个方法论,将软件工程中最充满不确定性的部分——人带来的负面作用——尽最大可能性彻底消除。
AI 是思维的工具,而不是思维的替代品,从小任务开始,逐渐学会将更大的任务交给它。
所以我对日常工作中的 Coding Agent 场景理解非常朴素,就是传统 TDD 中的结对编程(Copilot 最直接翻译),日常开发中依然遵从朴素的道理:健壮性稳定性是第一位的,性能是第二位的,毕竟,让一个准确的程序运行得更快,难度远远要小于让一个运行很快的程序变正确。
不管 Harness Engineering 是不是冷饭热炒的文字游戏,但是从本质出发,计算机科学也好,软件工程也好,AI 也好,算法也好,并不像文学、艺术作品那样具备 "柔性美感",可以为一千个人造就一千个哈姆雷特,工程的本质就是枯燥乏味且和多巴胺完全无缘的 "刚性艺术",所以任何 LLM 在大多数场景下,只要按照《代码大全》、《重构》、《设计模式》等经典软件工程书籍总结出来的最佳实践去写代码,最后的成品一定是优于人类的,这个最终结果和背后的原因也是显而易见的。
最终,不同的模型似乎在编码现实的方式上会基本趋于一致,因为本质上:
- 编程语言语法是相似(固定)的
- 每个编程语言的最佳实践是固定的
- 数据结构和算法是固定的
- 逻辑流是固定的
- 设计模式是固定的
- ...
开发者自己动手操作的经验在微观和宏观层面依然很重要:在微观层面,需要识别代码气味,给 Agent 建议更好的结构,并发现各种代码风险;在宏观层面,需要将业务/产品需求转化为具体的 Agent 实施任务,并根据 Agent 的能力进化不断调整。AI 写代码,自己也要写,这个过程和刷 LeetCode 很相似:
- 最差:直接复制粘贴题解的代码
- 看懂题解:复制粘贴,作用也不大
- 看懂题解:然后尝试自己解决,效果和时间相对折衷和高效的方案
- 尝试硬搓:效果最好,但是时间也可能是最长的
如果我们一直在原地踏步,工具很快就会和其他人一样,那么几乎不可能获得 AI 相关的洞见和 "超额收益",所以保证自己拥有的解决问题的方法越多,LLM / Agent(也包括职业道路)成功的可能性就越大,远超平均水平之上,进而产出更高质量的输入信息/指令和约束条件。所谓假书传万卷,真经一句话,如果当一个 Workflow / Context 中的所有指令都是 "真经",自然也就不再需要 Trade Off 和各种奇技淫巧了。
后记
周末花了将近 2 个小时,解决了家里的几个门长期以来的 "开关时的噪音" 问题,然后顺带把卫生间的马桶防水和洗手池防水重新做了一下,材料总费用 35 元,然后去某维修平台看了下报价,请工人师傅的话,费用要翻将近 10 倍,好家伙 :-)
碳基通缩,硅基通胀,珍惜当下!
参考资料
[^1]: MCP: https://modelcontextprotocol.io/docs/getting-started/intro
[^2]: 这篇文章: https://blog.dailydoseofds.com/p/anatomy-of-the-claude-folder
[^3]: Building effective agents: https://www.anthropic.com/engineering/building-effective-agents
[^4]: Writing effective tools for agents: https://www.anthropic.com/engineering/writing-tools-for-agents
[^5]: Coding Agent 最佳实践: https://cursor.com/cn/blog/agent-best-practices
[^6]: Coding Agent 最佳实践: https://docs.bigmodel.cn/cn/coding-plan/learning-resources/best-practice
[^7]: Anthropic Skills: https://github.com/anthropics/Skills
[^8]: Agent Skills io: https://github.com/agentSkills/agentSkills
[^9]: Agents-and-tools: https://platform.claude.com/docs/en/agents-and-tools/agent-Skills/best-practices
[^10]: Skills map: https://Skillsmp.com/
[^11]: Skills so: https://agentSkills.so/
[^12]: Skills sh: https://Skills.sh/
[^13]: 这个开源项目: https://github.com/aiming-lab/SimpleMem
[^14]: 在 OpenAI 的分享中: https://openai.com/zh-Hans-CN/index/harness-engineering/
[^15]: Harness Engineering 工程实践: https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
[^16]: 这个开源项目: https://github.com/walkinglabs/awesome-harness-engineering
[^17]: 这个热门项目: https://github.com/obra/superpowers
[^18]: AI 会倒逼你产出更好的代码: https://bits.logic.inc/p/ai-is-forcing-us-to-write-good-code
 发表于 2026-5-15 03:39:05
|
查看: 153|
回复: 0
发表于 2026-5-15 03:39:05
|
查看: 153|
回复: 0
