在GPU编程中,有效的错误管理是确保程序稳定性和可调试性的关键。与传统的CPU编程不同,CUDA操作的错误反馈具有独特的异步和“粘性”特性,理解这些机制对于编写健壮的高性能计算程序至关重要。
CUDA错误检查基础
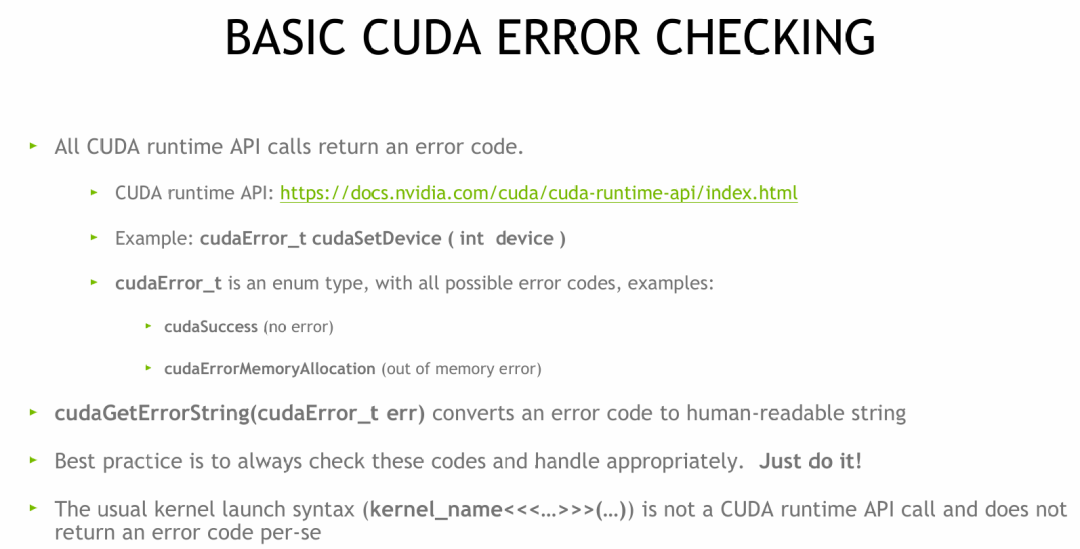
所有的CUDA运行时API函数都会返回一个类型为 cudaError_t 的错误码。例如,调用 cudaSetDevice(int device) 后,应检查其返回值。
cudaError_t 本质上是一个枚举类型,不同的数值对应不同的错误状态。例如,在内存分配操作中,可能返回:
cudaSuccess (无错误)cudaErrorMemoryAllocation (内存不足)
我们可以使用 cudaGetErrorString(cudaError_t err) 函数将错误码转换为可读的字符串描述。
然而,核函数启动语句 kernel_name<<<...>>>(...) 并非一个运行时API调用,因此它本身不会返回错误码。
- 核函数启动时的错误(如Grid/Block尺寸非法)会被延迟到后续的CUDA API调用时触发。
- 必须通过
cudaGetLastError() 或 cudaPeekAtLastError() 来主动检查这类启动错误。
因此,在CUDA编程中务必养成检查每一次API调用返回值的习惯:
- GPU操作失败(如内存不足、设备不可用)通常不会导致程序立即崩溃,而是可能使后续操作产生难以追踪的异常。
- 及时的错误检查能快速定位问题根源,例如
cudaErrorMemoryAllocation 可直接指向内存分配失败。
CUDA错误的异步特性
CUDA核函数的启动是异步的,这体现在:
- 核函数被放入设备的任务队列,不会立即开始执行。
- 主机线程在启动核函数后不会等待其完成,而是继续执行后续代码。
如果核函数在执行过程中发生错误(例如,设备端代码访问空指针),该错误不会立即通知主机端。它会延迟到下一次调用CUDA运行时API函数时,才被触发并返回。

核函数错误检查详解
CUDA核函数启动可能产生两类错误:
- 同步错误 (Synchronous Errors)
- 在启动瞬间即可被检测到的错误,例如Grid/Block尺寸非法、参数不匹配。
- 可通过启动后立即调用
cudaGetLastError() 或 cudaPeekAtLastError() 来检查。
- 异步错误 (Asynchronous Errors)
- 核函数在设备端执行过程中产生的错误,例如访问非法内存、数组越界。
- 错误会延迟触发,必须通过同步操作(如
cudaDeviceSynchronize())强制主机等待设备完成后,才能检测到。
cudaGetLastError() 无法直接捕获异步错误,因为当核函数还在运行或未开始时,设备端的错误尚未产生或报告给主机。
错误检查方案
1. 同步错误检查
在核函数启动后立即调用检查函数:
myKernel<<<gridDim, blockDim>>>(...);
cudaError_t err = cudaGetLastError(); // 检查启动时的同步错误
if (err != cudaSuccess) {
fprintf(stderr, "核函数启动错误:%s\n", cudaGetErrorString(err));
}
2. 异步错误检查
检查异步错误需要同步操作,但这会破坏异步执行的并发优势。一种常见的实践是通过调试宏来控制:
myKernel<<<…>>>(…);
cudaError_t ret = cudaGetLastError(); // 检查同步错误
if (debug) {
ret = cudaDeviceSynchronize(); // 强制同步,检查异步错误
}
3. 调试辅助方案
设置环境变量 CUDA_LAUNCH_BLOCKING=1:
- 这将使所有核函数启动变为同步(主机等待执行完成)。
- 可以立即捕获设备端执行错误,但会显著降低程序性能,仅建议在调试阶段使用。
“粘性”错误与“非粘性”错误
非粘性错误 (Non-Sticky Errors)
- 典型代表:同步错误,如参数错误导致的内存分配失败
cudaMalloc(...)。
- 特性:不会破坏CUDA上下文,属于可恢复错误。仅导致当前API调用失败,后续CUDA调用可正常执行。
- 处理:捕获错误后,可调整参数(如减少申请内存大小)后重试。
粘性错误 (Sticky Errors)
- 典型代表:核函数执行时发生的致命错误,如内存越界、非法指令。这类错误在大规模AI模型训练或高性能计算中尤其需要警惕。
- 特性:会破坏当前进程的CUDA上下文,导致该进程中所有后续CUDA API调用均失败(返回相同的错误)。
- 处理:单进程内无法恢复,必须终止进程并重启。在涉及复杂计算的云原生应用架构中,可以通过多进程隔离设计来规避——将CUDA任务封装在独立子进程中,单一进程崩溃不影响主服务。
注意:并非所有异步错误都是粘性的。例如,单个 cudaMemcpy 因地址错误而失败(异步非粘性),可能不会破坏上下文,后续操作仍可继续。
实践案例与检查宏
考虑以下代码片段:
int shared_mem_size = 32768; // 试图申请 32768*8 字节共享内存
myKernel<<<1024, 1024, shared_mem_size*sizeof(double)>>>(...); // 同步错误:共享内存超限
cudaError_t err1 = cudaGetLastError(); // 会捕获到错误
cudaError_t err2 = cudaPeekAtLastError(); // 可能返回成功,因为cudaGetLastError清除了错误记录
cudaMemcpy(dptr, hptr, size, cudaMemcpyDeviceToHost); // 同步错误:方向错误
cudaError_t ret = cudaMemcpy(dptr2, hptr2, size2, cudaMemcpyHostToDevice); // 可能成功,前一个错误被“掩盖”
关键点:
cudaGetLastError() 会获取并清除最后一个错误信息。cudaPeekAtLastError() 会获取但不清除最后一个错误信息。- 如果前一个API调用出错但未检查,后续成功的API调用会“掩盖”之前的错误,导致调试困难。
因此,建议将错误检查封装成宏,并机械地在每个CUDA调用后使用:
#include <stdio.h>
#include <stdlib.h>
#define cudaCheckErrors(msg) \
do { \
cudaError_t __err = cudaGetLastError(); \
if (__err != cudaSuccess) { \
fprintf(stderr, "Fatal error: %s (%s at %s:%d)\n", \
msg, cudaGetErrorString(__err), __FILE__, __LINE__); \
fprintf(stderr, "*** FAILED - ABORTING\n"); \
exit(1); \
} \
} while (0)
// 使用方式
myKernel<<<...>>>(...);
cudaCheckErrors("Kernel launch failed");
cudaDeviceSynchronize();
cudaCheckErrors("Kernel execution failed");
 发表于 2025-12-13 02:15:46
|
查看: 189|
回复: 0
发表于 2025-12-13 02:15:46
|
查看: 189|
回复: 0
