那年,公司网关服务流量涨得厉害,老张被运维叫去看了趟监控。“老张,你们那个网关服务,CPU倒是不高,但线程数一直在涨,高峰期都破两千了,再这么下去机器要扛不住了。”
老张翻开代码一看,网关用的是最传统的BIO模型,一个连接起一个线程。业务高峰期并发连接上来了,线程数自然跟着飙。两千个线程时光上下文切换的开销就够系统喝一壶了。
这不是流量的问题,是 IO模型 的问题。从BIO到NIO,Netty高性能的秘密,今天从头聊清楚。
一、BIO的困局:一个连接一个线程
先看一段BIO服务端的核心代码。这段代码不复杂,但藏了BIO的所有问题:
ServerSocket serverSocket = new ServerSocket(9000);
while (true) {
// 阻塞点一:等待客户端连接
Socket clientSocket = serverSocket.accept();
// 为每个连接创建一个新线程
new Thread(() -> {
try {
byte[] bytes = new byte[1024];
// 阻塞点二:等待客户端发送数据
int read = clientSocket.getInputStream().read(bytes);
if (read != -1) {
System.out.println("收到数据:" + new String(bytes, 0, read));
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
代码里两个地方会让线程卡住。
accept()。服务端启动后调用这个方法,如果没有客户端连接进来,当前线程就一直等在这里。这倒还好,因为只有一个主线程在等连接,不会占用太多资源。read()。当某个客户端建立连接后,服务端为它创建一个新线程,专门处理这个连接的数据读写。这个线程调用 read() 时,如果客户端还没发数据过来,线程就卡住了,什么都做不了,只能干等。
问题就出在第二个阻塞上。 想象一个场景:一千个客户端连上了你的服务端,但只有十个客户端在频繁发数据,剩下九百九十个连上之后什么也不做,只是保持连接。按BIO的模式,服务端已经为这一千个连接各创建了一个线程。那九百九十个空闲连接的线程全部卡在 read() 上,什么都做不了,但线程本身的内存、内核栈、调度开销一个都不少。
这就是C10K问题的核心——单机如何同时处理一万个以上的客户端连接。对于BIO来说只能加线程,但线程不是无限的,操作系统能管理的线程数有上限,线程切换的上下文开销也随线程数增长而急剧上升。一台机器能撑的线程数到几千基本就到头了,再往上系统就开始抖。
二、NIO的破局:从阻塞到非阻塞
BIO的问题根源在于客户端连接和线程绑死了。解决思路:用一个线程管理多个连接。但要做到这一点,首先要让线程不再卡在 read() 上,这就是NIO的“非阻塞”。
在NIO里,连接用 SocketChannel 表示,监听端口用 ServerSocketChannel 表示,然后调用 configureBlocking(false) 把Channel设为非阻塞模式。
非阻塞是什么意思? read() 再也不会卡着线程了。如果客户端还没发数据过来,read() 立即返回0,不会等。线程读完这个连接,马上就能去读下一个,不需要为每个连接配一个专属线程。
最早期的NIO实现就是这么干的——把所有连接存到一个列表里,用一个线程循环遍历:
// 一个线程管理多个连接(但这种方式有严重缺陷)
ServerSocketChannel serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(9000));
serverSocket.configureBlocking(false); // 设为非阻塞
List<SocketChannel> channelList = new ArrayList<>();
while (true) {
// accept也是非阻塞的,没人连接直接返回null
SocketChannel newChannel = serverSocket.accept();
if (newChannel != null) {
newChannel.configureBlocking(false);
channelList.add(newChannel);
}
// 遍历所有连接,逐个读数据
Iterator<SocketChannel> it = channelList.iterator();
while (it.hasNext()) {
SocketChannel sc = it.next();
ByteBuffer buf = ByteBuffer.allocate(128);
int len = sc.read(buf); // 非阻塞,没数据返回0
if (len > 0) {
System.out.println("收到消息:" + new String(buf.array(), 0, len));
} else if (len == -1) {
it.remove(); // 连接断开
}
}
}
线程确实不阻塞了,但这段代码有一个严重的性能陷阱。假设现在有一万个连接,但只有十个连接有数据到达。这个 while 循环还是会老老实实把一万个连接全部遍历一遍,每个连接都调一次 read()。有数据的十个读到了数据,没数据的九千九百九十个返回0。返回0是很快,但调九千九百九十个 read() 本身就是在浪费CPU。这就是无效遍历的问题——连接越多,浪费越严重。
NIO真正的杀手锏不是非阻塞,而是接下来要讲的Selector(多路复用器)。
三、多路复用的精髓:Selector与epoll
Selector的思路用一句话说:把“哪些连接有数据”这件事交给操作系统去判断,程序只处理有数据的连接。
Selector怎么用
用法分三步,代码很清晰:
// 第一步:创建Selector
Selector selector = Selector.open();
// 第二步:把ServerSocketChannel注册到Selector上,监听“新连接”事件
ServerSocketChannel serverSocket = ServerSocketChannel.open();
serverSocket.configureBlocking(false);
serverSocket.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
// 第三步:阻塞等待,有事件发生才往下走
selector.select();
// 拿到所有就绪的事件,没有就绪的不会出现在这里
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> it = keys.iterator();
while (it.hasNext()) {
SelectionKey key = it.next();
if (key.isAcceptable()) {
// 新连接来了
SocketChannel client = serverSocket.accept();
client.configureBlocking(false);
client.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
// 这个连接有数据了
SocketChannel client = (SocketChannel) key.channel();
ByteBuffer buf = ByteBuffer.allocate(128);
int len = client.read(buf);
if (len > 0) {
System.out.println("收到:" + new String(buf.array(), 0, len));
}
}
it.remove(); // 处理完必须移除,否则下次还会拿到
}
}
对比之前的遍历方案,Selector有两个质变。第一,没有事件时 select() 阻塞,线程挂起,不消耗CPU。第二,select() 返回后,selectedKeys() 里只包含真正有事件发生的连接,不需要遍历全部连接。
操作系统视角:epoll是怎么做到的
Java的 Selector 在Linux下底层用的是 epoll——Linux内核提供的一套IO多路复用机制。理解它的内部结构,才能真正理解Netty高性能的根基。
epoll 有三个核心系统调用,对应Java里的三个操作。
epoll_create(),创建事件调度中心。 内核创建一个 eventpoll 对象,它有两个关键成员:一个是红黑树,用来存储所有被监视的Socket;另一个是就绪列表(rdlist),是一个双向链表,用来汇集已经发生事件的Socket。创建完后,内核返回一个文件描述符(epfd),程序后续所有操作都通过这个epfd找到对应的 eventpoll 对象。
Java中对应:Selector.open() 底层调用 epoll_create()。
epoll_ctl(),添加或删除要监听的Socket。 比如要监视一个Socket的读事件,就调用 epoll_ctl(epfd, ADD, socket_fd, EPOLLIN)。内核做两件事:一是把这个Socket的信息插入到 eventpoll 的红黑树里,方便后续增删改查;二是把 eventpoll 对象自己的引用加到Socket的等待队列上——注意,加的是 eventpoll,不是进程。这意味着数据到达时,内核先通知 eventpoll,而不是直接唤醒进程。
Java中对应:channel.register(selector, OP_READ) 底层调用 epoll_ctl()。
epoll_wait(),阻塞等待事件。 内核检查 eventpoll 的就绪列表。如果列表不空,说明之前已经有Socket就绪,直接把就绪列表返回,不阻塞。如果列表为空,内核把当前进程挂在 eventpoll 的等待队列上,进程进入休眠,几乎不消耗CPU,直到有事件唤醒它。
Java中对应:selector.select() 底层调用 epoll_wait()。
数据到达时发生了什么
这是 epoll 最精妙的地方。当一个Socket收到数据,流程是这样的:
数据通过网卡和DMA写入内存后,网卡发出中断信号。中断程序把数据写入Socket的接收缓冲区,然后检查这个Socket的等待队列。等待队列里有 eventpoll 对象的引用,于是中断程序直接把这个Socket的引用加入 eventpoll 的就绪列表。
接着检查 eventpoll 自己有没有进程在等(epoll_wait 挂起的进程)。如果有,就唤醒这个进程。进程醒来后,直接拿到 eventpoll 里的就绪列表,精准处理有数据的连接,整个过程没有一次遍历全部Socket的操作。
红黑树管“监视谁”,就绪列表管“谁就绪了”,两个数据结构各司其职。
顺便说说select和poll为什么不行
说完 epoll,再看早期方案为什么被淘汰,就一目了然了。
select的机制:每次调用 select,内核必须把进程加入到所有被监视Socket的等待队列上。任何一个Socket收到数据,进程被唤醒,同时又从所有Socket的等待队列上移除。进程醒来后只知道“有数据了”,不知道谁有数据,还要再遍历全部Socket用 FD_ISSET 逐个检查。加队列和移除队列各遍历一次,唤醒后再遍历一次,总共三次遍历。 默认最多监视1024个Socket,原因就是遍历成本太高。
poll的改进:把监视列表从数组改成链表,没有了1024的数量限制。但三次遍历一个都没少,连接多了性能一样差。
epoll 的质变:用红黑树管理监视列表,增删改查从 O(n) 降到 O(log n)。用就绪列表精准返回就绪Socket,唤醒后不需要遍历。监视和等待分离,epoll_ctl 只在建立和关闭连接时调用,频繁执行的 epoll_wait 只做等待这一件轻量的事。
四、架构借鉴:事件驱动调度
从BIO到 epoll,表层是API的换代,底层是调度模型的改变。
BIO的调度逻辑是面向连接的——来一个连接分配一个线程,连接和线程一一绑定。epoll 把这个逻辑翻了过来,引入一个事件调度中心,同时监视所有连接,线程只处理有数据的连接,空闲连接不占用线程。
把这个模型抽象出来,核心结构如下:
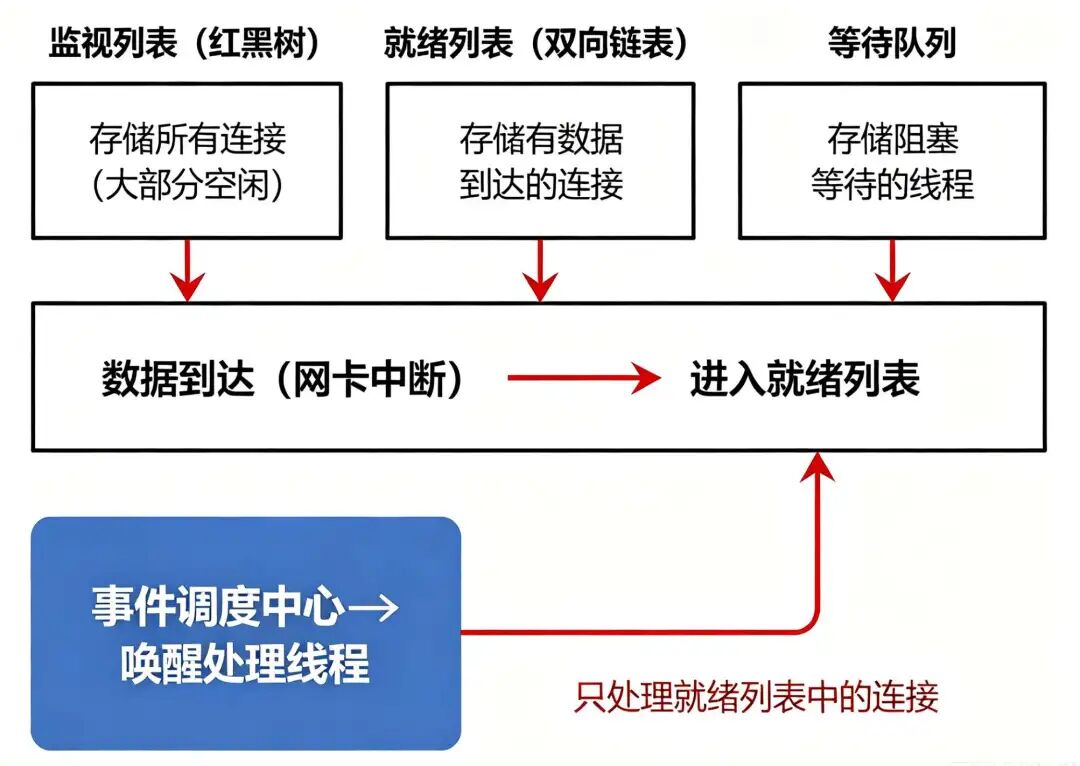
调度中心内部有三个关键部分,各管一摊。
监视列表 存所有被管理的连接,用红黑树组织,增删改查都是 O(log n)。连接建立时注册进来,连接关闭时移除。平时不参与事件处理,只管存量。
就绪列表 只存当前有数据到达的连接,用双向链表组织,插入删除都是 O(1)。网卡收到数据后,通过中断程序找到对应的 eventpoll,把当前Socket的引用加入就绪列表。线程被唤醒后直接从这里取连接,不需要去监视列表里遍历。
等待队列 存的是调用 epoll_wait 后阻塞等待的线程。没有事件时线程挂在这里休眠,CPU占用几乎为零。就绪列表不为空时,或者有新的数据到达时,内核唤醒等待队列中的线程。
整个数据结构配合上休眠、阻塞、中断触发等机制,从头到尾只操作了就绪列表和等待队列,没有遍历监视列表。
写在最后
老张把网关的IO模型从BIO切到NIO之后,高峰期线程数从两千降到了两位数,CPU反而更稳定了。
团队分享时老张说了一段话:“从BIO到epoll,表面看是在优化IO,本质上是在换调度模型。面向连接的调度,线程跟着连接走,连接越多线程越多。换成事件驱动的调度,线程只跟着事件走,连接再多线程也不涨。这个思路不只属于Netty,Redis、Kafka、Flink,凡是需要管理海量连接或海量任务的组件,都在用。以后再碰到线程数随业务量线性增长的坑,先看看能不能把调度模型从‘面向任务’换成‘面向事件’。”
更多关于底层IO模型的深入讨论,欢迎访问云栈社区。
 发表于 2026-5-17 03:07:16
|
查看: 148|
回复: 0
发表于 2026-5-17 03:07:16
|
查看: 148|
回复: 0
