IO模型真的有必要搞这么复杂吗?
如果你学过操作系统,或者写过一点网络程序,那你大概率见过这几个词:select、epoll、io_uring。问题是,你真的能一句话讲清楚它们的区别吗?
网上关于 IO 模型的文章其实已经多到离谱了。但很长一段时间里,我发现一件很尴尬的事:我看懂了,但我讲不明白。尤其是这个问题:为什么 epoll 看起来只是换了个 API,却能在高并发场景下把 select 按在地上摩擦?
于是我意识到,问题也许不在原理不够复杂,而在于解释方式不对。所以这篇文章,我们不从“什么是文件描述符”、“什么是阻塞/非阻塞”这些教科书起手式开始。
我们换一种方式。我们去一家餐厅。
场景设定:你是一家网红餐厅的服务员
想象周六晚上的海底捞(或者你家楼下最火的那家烧烤店):
- 顾客很多(应用程序)
- 每个人都在点菜(发起 IO 请求)
- 厨房做菜需要时间(磁盘/网络 IO)
- 而你,是那个“倒霉”的服务员(线程/进程)
你的任务只有一个:哪道菜好了,就第一时间端给对应的顾客。问题来了:你怎么知道,哪道菜做好了? 这,就是 IO 模型要解决的核心问题。
接下来,我们就用这家餐厅,来看看:
select 像什么样的餐厅?epoll 做了哪些关键优化?io_uring 为什么被称为 IO 的未来?- 以及一个反直觉的问题:为什么 OLAP 数据库(ClickHouse/StarRocks)反而很少用它们?
如果你能跟着这家餐厅走完全文,那么下次再看到 select/epoll/io_uring,你脑子里出现的就不再是函数名,而是一整套工作画面。
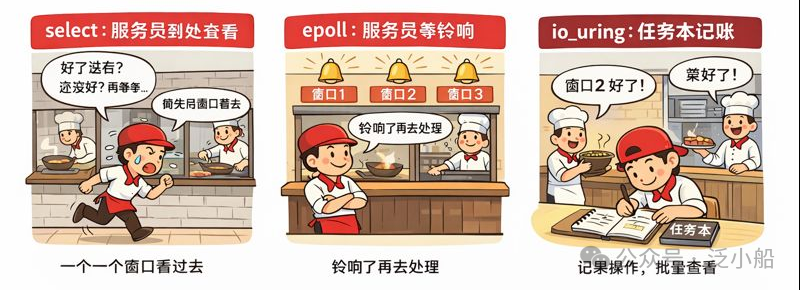
第一章:select —— 跑断腿的服务员
餐厅形态:人工巡逻队
在 select 模型下,餐厅是这样的:厨房有 100 个出菜窗口,每个窗口对应一道菜(一个文件描述符)。你作为服务员,完全不知道哪道菜会先好。于是你的工作方式极其朴素:每隔几秒钟,把所有窗口挨个看一遍。
“1号桌的羊肉串好了吗?没有... 2号桌的麻辣香锅好了吗?没有... 3号桌的... 欸 3 号好像好了!端走!... 好了继续看 4 号...”
即使 100 个窗口里只有 3 道菜做好了,你也必须全部检查一遍。
代码世界的长这样:
// 伪代码:select 的工作日常
while (餐厅还开着) {
// 1. 把所有顾客的订单(fds) Copy 给厨房(内核)
copy_to_kernel(all_fds);
// 2. 问厨房:这些菜哪个好了?(遍历检查)
ready_fds = select(all_fds);
// 3. 端菜给对应的顾客
for (fd in ready_fds) {
serve(fd);
}
}
痛点吐槽
这位服务员看起来是不是傻傻的?但这正是 select 的工作方式:
- 每次调用都要复制所有 fd:用户态和内核态之间疯狂复制数据(就像你每次巡逻都要带一张写着所有菜单的A3纸)。
- O(n) 遍历:fd 越多,检查成本线性增长(窗口一多,你 90% 的时间花在“无效奔波”上)。
- 还有 1024 道菜的上限:这家餐厅有个奇葩规定,最多只能同时接1024道菜(
FD_SETSIZE 限制),多了直接拒单。
所以 select 的核心问题不是慢,而是“蠢”。它就像一个勤勤恳恳但完全不懂变通的老实人,fd一多就累瘫。这种设计在需要管理成千上万连接的现代高并发服务器面前,显得力不从心。
第二章:epoll —— 装了“出菜铃”的智能餐厅
终于,老板看不下去了,对餐厅进行了一次关键升级:每个出菜窗口装了一个电铃。
你提前告诉厨房:老板,我关心 1、5、7、9 号窗口,这 4 个窗口如果菜好了,按铃叫我,其他的我不管。
接下来流程变成:你在休息室摸鱼(阻塞等待)→ 铃响了(事件通知)→ 你冲过去看是几号窗口 → 只去那个窗口端菜 → 回来继续摸鱼。
发生了什么变化?
- 不用巡逻了:没有铃响的时候,你可以休息(线程阻塞,不占用 CPU)。
- 精准打击:铃响了,说明真的就绪了,不需要遍历其他 99 个窗口。
- 没有 1024 限制:想监控几万个连接?只要内存够,随便加(当然,太多也会有其他问题,但那是后话)。
技术黑话翻译
这正是 epoll 的核心思想:
- 注册机制:通过
epoll_ctl 把 fd 提前注册进内核的红黑树(告诉厨房“我关心这些窗口”)。
- 就绪队列:内核维护一个“就绪链表”,谁的数据来了,就加到链表里(按铃)。
- 事件驱动:
epoll_wait 直接返回就绪的 fd,不需要遍历全部。
epoll 的优势不在于“单次 IO 更快”,而在于:当窗口很多、但同时出菜的很少时,还能高效工作。 这就是为什么 Nginx、Redis、Netty 这些高并发神器都用 epoll。它们要处理 10k、100k 个连接,但可能只有 1% 的连接在真正传输数据。epoll 正是解决此类网络服务器核心痛点的利器。
第三章:io_uring —— 服务员和厨房共用一本“任务小本”
到了 io_uring,餐厅的工作方式发生了根本变化。
这一次,服务员和厨房共用一本环形任务本(Ring Buffer),就放在厨房窗口。流程变成了:
- 点菜:你把“我要什么菜”直接写进本子(Submission Queue),不需要敲门问厨师(减少系统调用)。
- 做菜:厨师看到本子有新订单,直接开始做。
- 完成:菜做好了,厨师把结果写回本子另一边(Completion Queue)。
- 取餐:你有空的时候批量看一眼本子:“哦,5号、8号、12号好了”,一次性端走。
这有什么厉害之处?服务员在记录菜单后,可以立马去干其他事情,比如算账、收拾桌子、招呼客户,当然也可以休息。
对应到系统层面:
- 极少的系统调用:以前你每秒要喊厨师 1000 次(
read/write 系统调用),现在你只要写本子,批量处理。
- 真正的异步:甚至可以把“把生肉做成红烧肉”这件事异步化(Direct I/O),而不只是等着菜做好。
- 零拷贝:数据可以直接从厨房到顾客桌子,不需要先经过你的手(减少数据拷贝)。
io_uring 的本质是:减少来回跑动本身的成本。 当 IO 极其密集时(比如高速 SSD、万兆网卡),这种优化才会显现出巨大价值。它是 Linux 5.1 才引入的新机制,被称为“IO 的未来”。
站在餐厅角度的总对比
| 模型 |
餐厅形态 |
工作方式 |
效率 |
适合场景 |
select |
人工巡逻 |
挨个窗口问 |
低 |
fd < 1024,简单任务 |
epoll |
电铃通知 |
谁好谁叫我 |
中 |
高并发服务器(C10K/C100K) |
io_uring |
智能任务本 |
批量提交/收割 |
高 |
IO 极度密集,追求极限性能 |
第四章:为什么 OLAP 数据库(ClickHouse)不爱用这些?
如果你已经理解了前面的餐厅模型,这里我们可以直接换一家完全不同类型的餐厅。
如果说网络服务器像是:外卖店(高并发 + 单点小菜),那 OLAP 数据库更像是:单位食堂 / 自助餐厅 / 大锅饭。
OLAP(数据分析)查询的 IO,有几个非常反直觉的特点:
- 不是零碎点菜,而是一锅一锅盛:查询通常是“把上个月所有用户的点击数据拿出来”,一次读几百 MB。
- 菜品排得非常整齐:数据按列存储,文件组织高度有序(顺序读)。
- 厨房提前知道要炒什么:IO 模式几乎是可预测的,没有“突然来个客人点变态辣”这种随机事件。
ClickHouse:我根本不需要你帮我盯着
在 ClickHouse 里,查询执行通常是这样的:
- 每个查询启动少量线程(比如 8 个)。
- 每个线程负责顺序扫描一大段列文件(几十 KB 甚至几 MB 起步)。
- 每次
read/pread,都是给我从第 1000 块开始,读 1000 块。
换成餐厅比喻就是:厨房已经决定好了——接下来 10 分钟,就一直炒这一大锅菜。服务员要做的不是盯着菜好了没,而是端着大托盘,站在出菜口等整锅出来。在这种情况下:
select/epoll 的“谁好了通知我”:没意义,因为我知道我要等的是整锅菜。io_uring 的极致异步:提升空间也很有限。因为顺序 IO 本身就已经是磁盘最擅长的事情了,再用复杂的异步机制收益不大,反而增加代码复杂度。
实际上,曾经有人尝试在 ClickHouse 中引入 io_uring,希望进一步提升性能。但压测发现:性能收益不明显,反而在极端场景下引入了稳定性问题。所以 ClickHouse 的态度非常工程化:默认不用,真要用,自己改参数开启。
StarRocks:我更关心“怎么算得快”
StarRocks 的选择更现实,它的优化重心在:
- 向量化执行(SIMD 指令)
- Pipeline 执行模型
- Cache 命中率优化
- 批量 IO
对 OLAP 来说,IO模型只是地基,数据怎么放、怎么算,才是上层建筑。 当你已经做到:顺序读、大块读、IO可预测,那 select/epoll/io_uring 的差距,远不如“数据布局 + 执行模型”来得重要。
总结:记住这三句话就够了
最后,记住这三句话就够了:
select:“我一个一个问你们,好了没有?”(轮询,O(n),有上限)epoll:“谁好了,自己喊我一声。”(事件驱动,O(1))io_uring:“别喊了,写本子上,我一会儿批量看。”(异步提交,零拷贝)
技术没有绝对的先进,只有适不适合当前场景。
- 写网络服务,
epoll / io_uring 是利器。
- 写 OLAP 引擎,数据布局比 IO 模型重要得多。
- 写小工具 / 客户端,
select 可能已经是最优解。
希望这个“餐厅服务员”的比喻,能帮你更直观地理解这些核心的 Linux IO 模型。如果你想了解更多底层原理或实践案例,欢迎在云栈社区与其他开发者交流探讨。
参考资料:
- https://github.com/ClickHouse/ClickHouse/pull/36103
- https://github.com/ClickHouse/ClickHouse/issues/10787
 发表于 2026-2-5 02:56:17
|
查看: 147|
回复: 0
发表于 2026-2-5 02:56:17
|
查看: 147|
回复: 0
