上一篇我们对比了不同矩阵乘法的实现,虽然运行时长很直观,但总觉得不够透彻,无法定位系统真正的瓶颈在哪里。只有找到病根,才能对症下药。今天,我们就深入探讨硬件原理与系统瓶颈的关系,并分享使用 NVIDIA 性能分析工具 Nsight Compute(ncu)进行性能剖析(Profiling)的思路。
Roofline模型:性能的理论天花板
我们直观理解,计算分为两个步骤:搬运数据(访存)和进行计算。如果算得快但搬得慢,或者搬得快但算得慢,系统都会被卡住。这就引出了计算瓶颈和带宽瓶颈的概念。Roofline模型可以更深刻地解释这个问题。
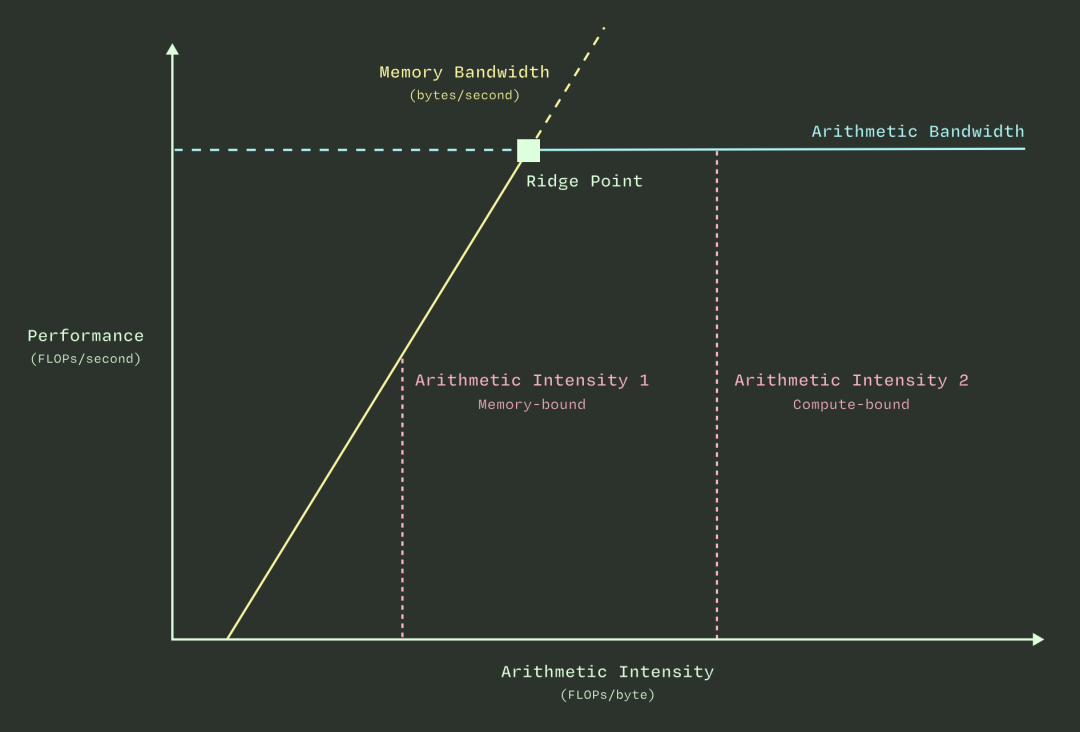
我们先看图的横纵坐标。
- 横坐标是计算强度,定义为每传输一个字节(byte)数据,需要做多少浮点计算(FLOPs)。你可以近似理解为:每拿到一个“原材料”,需要经过多少个步骤才能加工完成。
- 纵坐标是性能,定义为每秒能进行多少次浮点计算(FLOPS)。可以理解为每秒钟能干多少“活”。
当计算强度较低时,即使带宽被拉满,计算单元也还有余力,因此性能会随着计算强度的增加而线性提升(图中的上升斜线部分)。当计算强度高到触及计算单元的理论上限时,即使再传输更多数据,计算单元也处理不过来了。此时,系统达到了理论性能上限,曲线变成水平,公式表现为:性能 = 峰值计算能力 = 常数(即图中水平线)。
理解这个模型,是分析一切性能问题的计算机基础。
硬件原理:存储是优化的核心战场
大多数优化手段都围绕存储展开,因为数据在芯片内外的传输速度,相比计算本身要慢得多。下面我们来了解两种关键存储硬件的原理。
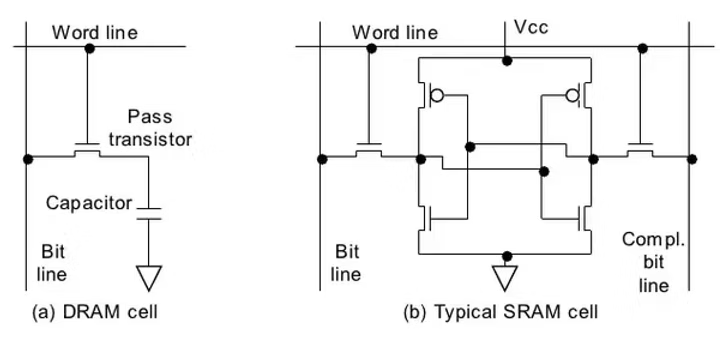
DRAM和SRAM在电路结构上有根本区别,一个是动态(Dynamic),一个是静态(Static)。DRAM电路简单,集成密度高(单位面积存储更多数据),但速度较慢,通常用作GPU的全局内存(Global Memory)。SRAM电路复杂,集成密度低,但速度快,常被用作共享内存(Shared Memory)。电路结构的不同直接导致了数据读取流程的差异,进而决定了各自的优化策略。
DRAM - 全局内存(Global Memory)
DRAM存储单元会组织成一个二维阵列。
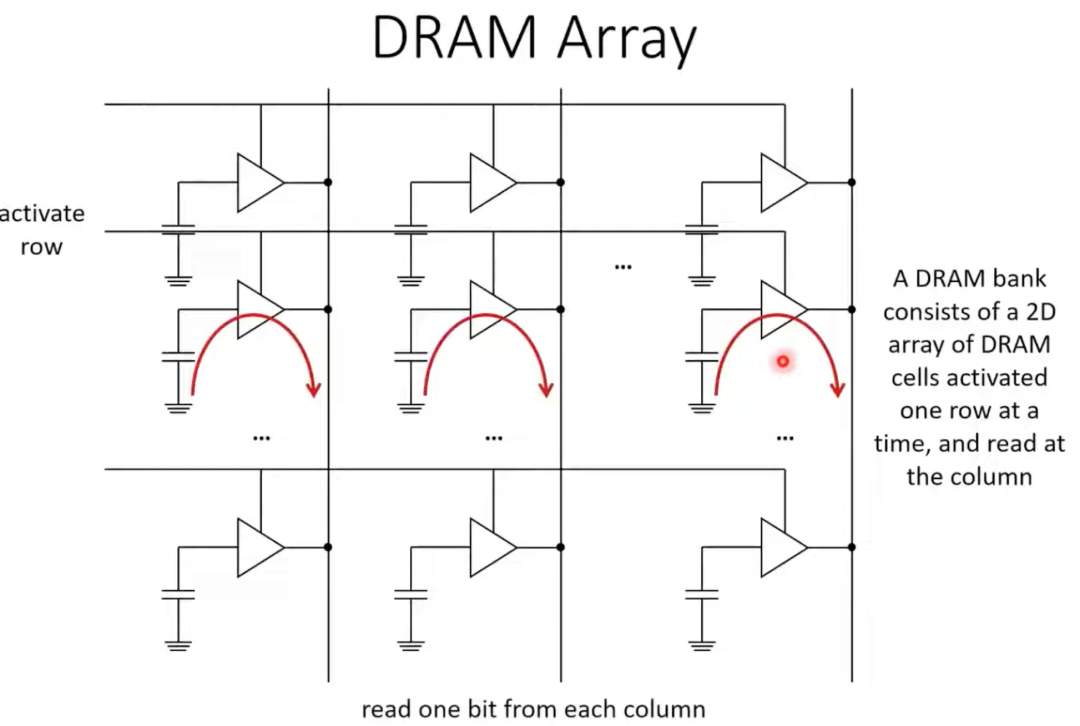
DRAM读取数据的过程可以分解为:首先激活(选中)一行,将该行所有单元的数据放大并锁存(同时会进行回写,因为DRAM的读取是破坏性的),数据被存放到列锁存器中,最后通过多路复用器(Mux)根据列地址选出需要的数据输出。
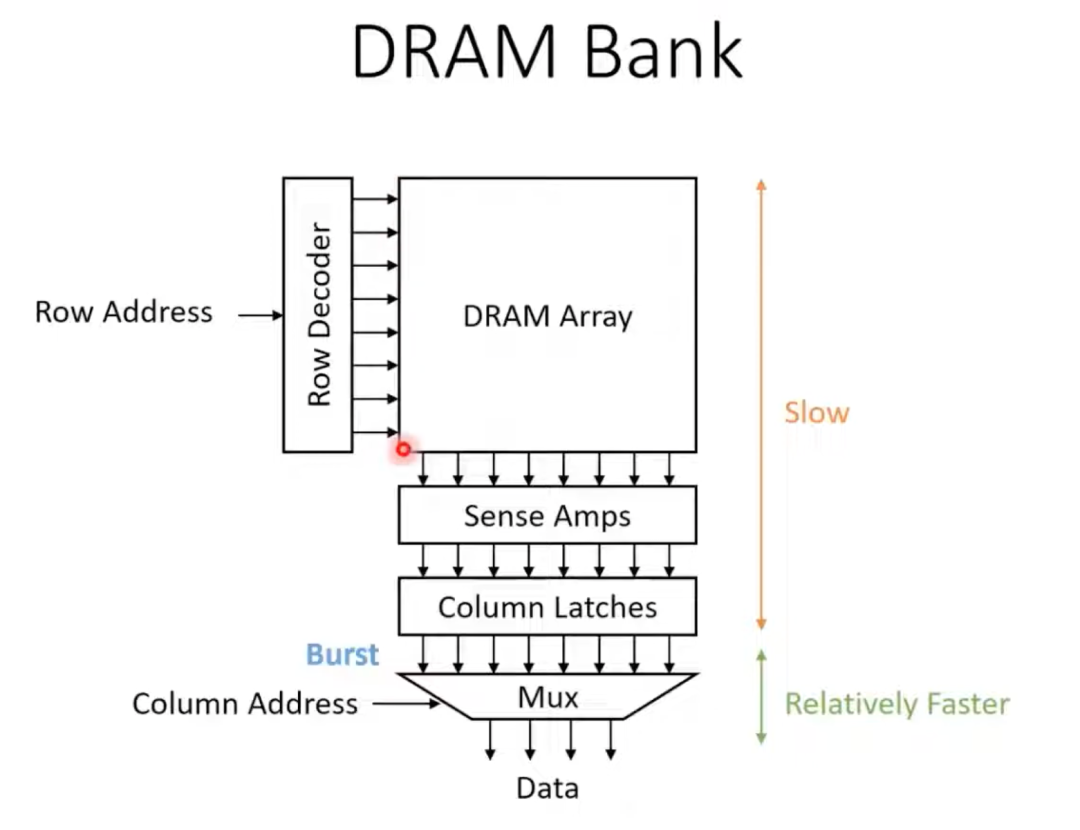
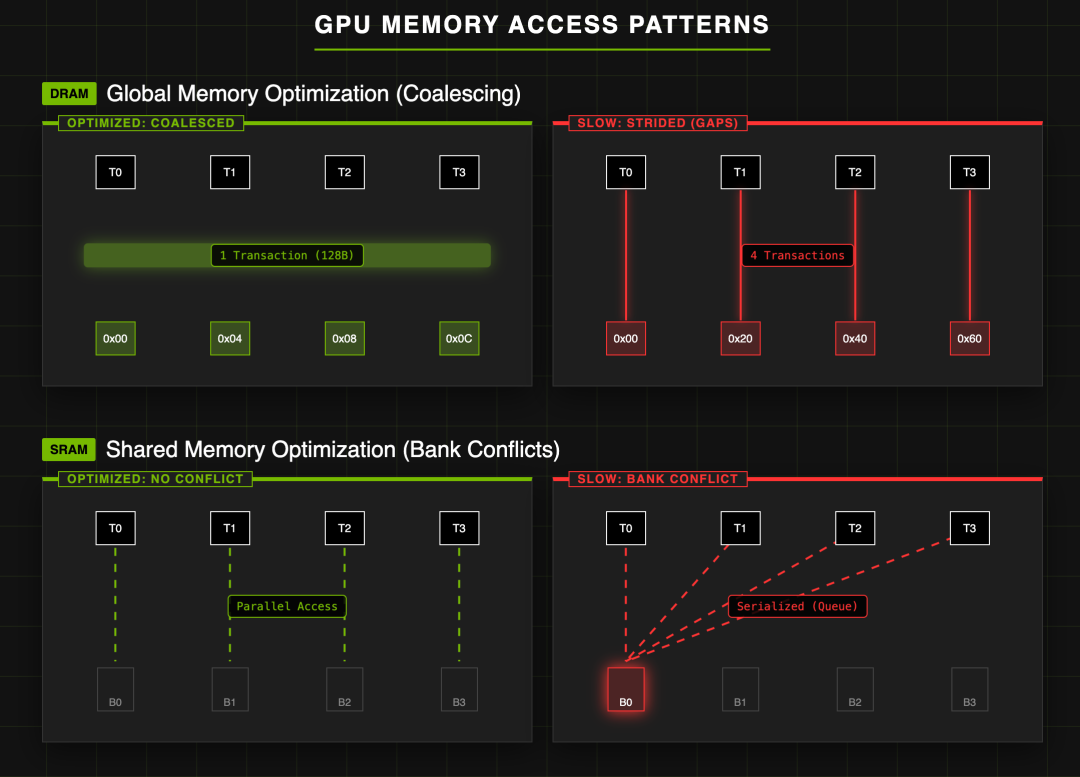
因此,DRAM最喜欢访问地址连续的数据,因为可以一次性读出一整行,效率最高。它最怕的是访问零散、地址不连续的数据,这会导致需要多次激活不同的行,带来巨大的充放电延迟开销。
SRAM - 共享内存(Shared Memory)
下图展示的是一个SRAM存储块(Bank)的结构。一个“8T”代表一个SRAM单元,存储一个比特(bit)数据。水平方向通常由32个8T单元组成,这被称为SRAM的宽度。垂直方向的数量则大得多,例如1024个。右侧的“10T”是冗余列,用于替换左边损坏的单元。
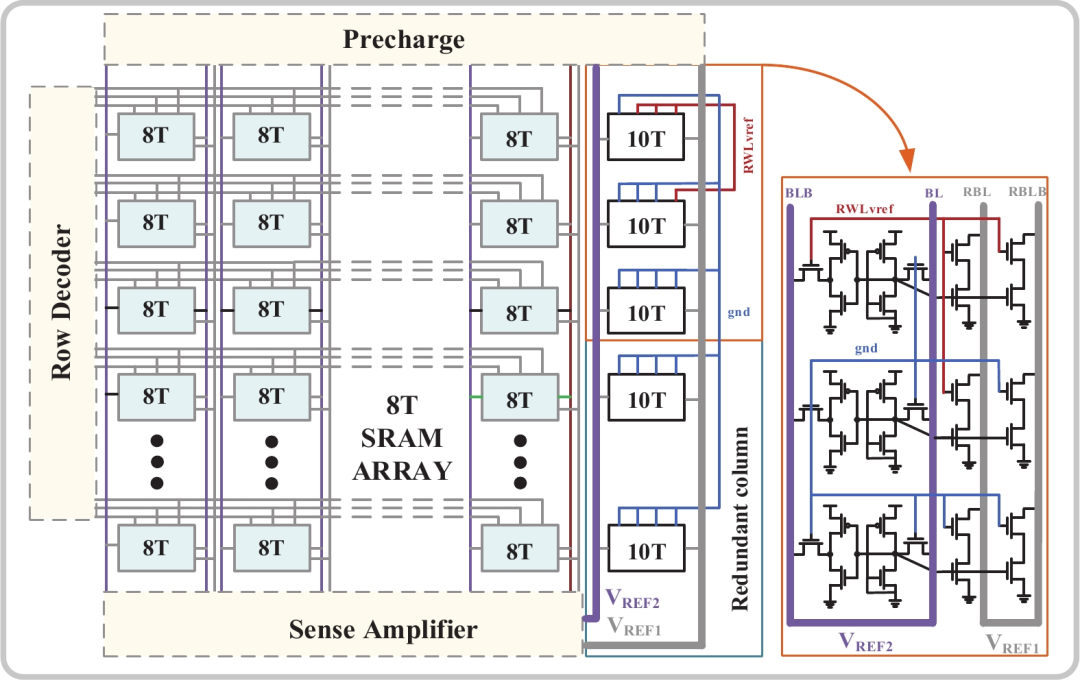
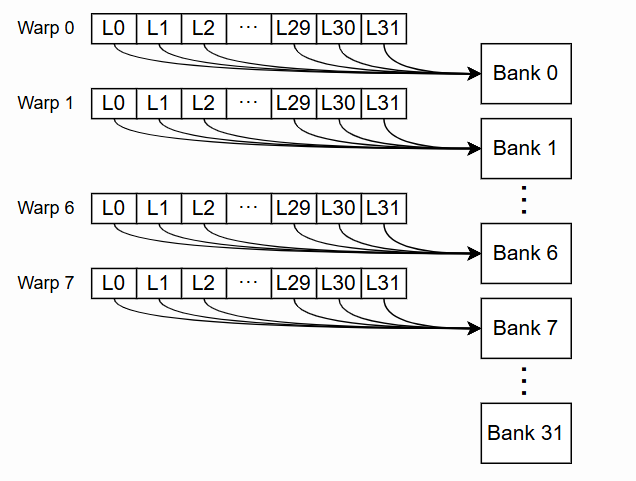
SRAM的硬件结构决定了,在同一个时钟周期内,一个Bank只能读取一行数据。如果一个Warp中的多个线程(Thread)需要访问同一个Bank中不同行的数据,就会发生Bank Conflict。最理想的情况是32个线程各自访问一个不同的Bank,实现完全并行。最糟糕的情况则是所有线程都挤到同一个Bank,导致访问被序列化。
DRAM 与 SRAM 访问模式总结
总结一下,优化策略因内存类型而异:
- 使用全局内存时,核心是关注内存合并,尽可能减少事务访问次数。
- 使用共享内存时,核心是避免Bank冲突,确保并行访问效率。
使用 Nsight Compute (ncu) 进行剖析
ncu是NVIDIA官方的内核级性能分析工具。需要注意的是,很多云平台(包括Colab)由于没有root权限而无法使用。即使ncu --version能执行,实际分析时也可能只返回 ==WARNING== No kernels were profiled.,无法获取有效信息。如果本地没有运行条件,可以尝试使用lightning.ai等支持该工具的云平台。
假设我们有一个CUDA源代码文件 coalesce.cu,可以通过以下命令编译并用ncu进行分析:
# 将代码编译成可执行文件
nvcc -o coalesce.bin coalesce.cu
# 执行可执行文件并进行性能剖析
ncu coalesce.bin
生成的报告通常包含以下几个主要部分:
- GPU Speed Of Light (SOL):总体性能概览,包括计算、访存吞吐量、耗时等。
- INF/OPT:工具给出的解读与优化建议。
- Launch Statistics:内核启动参数与硬件资源分配情况。
- Occupancy:占用率,反映线程并发执行效率。
- Workload Distribution:详细的负载分布情况,用于定位瓶颈。
阅读报告的一个有效思路是:先从SOL部分了解整体性能水位,查看INF/OPT的建议,然后通过Launch Statistics检查配置是否合理(这部分通常最容易调整),最后根据Occupancy和Workload Distribution深入分析代码层面的优化点。
下面我们来看一个实际报告的例子。
首先是程序启动信息,显示了进程ID。代码中有两个内核(kernel)被分析。内核 copyDataNonCoalesced 的 grid/block 配置为 (131072, 1, 1)x(128, 1, 1),计算能力(CC)为7.5,对应T4显卡的架构。
==PROF== Connected to process 10712 (/teamspace/studios/this_studio/lectures/lecture_008/benchmark.bin)
==PROF== Profiling “copyDataNonCoalesced” - 0: 0%....50%....100% - 10 passes
==PROF== Profiling “copyDataCoalesced” - 1: 0%....50%....100% - 10 passes
==PROF== Disconnected from process 10712
[10712] benchmark.bin@127.0.0.1
copyDataNonCoalesced(float *, float *, int) (131072, 1, 1)x(128, 1, 1), Context 1, Stream 7, Device 0, CC 7.5
在SOL部分,我们主要关注Compute和Memory Throughput。粗略来看,哪个数值更高,就可能成为瓶颈。Duration约等于我们手动用t2-t1计算的内核运行时间。INF部分给出了优化建议,提示我们应重点分析DRAM访问。
Section: GPU Speed Of Light Throughput
----------------------- ----------- ------------
Metric Name Metric Unit Metric Value
----------------------- ----------- ------------
DRAM Frequency Ghz 4.97
SM Frequency Mhz 584.97
Elapsed Cycles cycle 446922
Memory Throughput % 90.22
DRAM Throughput % 90.22
Duration us 764
L1/TEX Cache Throughput % 29.49
L2 Cache Throughput % 30.11
SM Active Cycles cycle 442967.55
Compute (SM) Throughput % 25.05
----------------------- ----------- ------------
INF The kernel is utilizing greater than 80.0% of the available compute or memory performance of the device. To
further improve performance, work will likely need to be shifted from the most utilized to another unit.
Start by analyzing DRAM in the Memory Workload Analysis section.
Launch Statistics部分与内核使用的硬件资源相关。Registers Per Thread = 16 表示每个线程使用了16个寄存器。寄存器使用越少,可同时活跃的线程就越多。Waves Per SM = 409.60 表示平均每个SM需要处理超过400波(Waves)的线程块,这说明SM的工作负载已经非常饱和。Shared Memory 为0,说明该程序未使用共享内存。
Section: Launch Statistics
-------------------------------- --------------- ---------------
Metric Name Metric Unit Metric Value
-------------------------------- --------------- ---------------
Block Size 128
Function Cache Configuration CachePreferNone
Grid Size 131072
Registers Per Thread register/thread 16
Shared Memory Configuration Size Kbyte 32.77
Driver Shared Memory Per Block byte/block 0
Dynamic Shared Memory Per Block byte/block 0
Static Shared Memory Per Block byte/block 0
# SMs SM 40
Threads thread 16777216
Uses Green Context 0
Waves Per SM 409.60
-------------------------------- --------------- ---------------
Occupancy部分关注线程束(Warp)是否真正在高效工作。即使给SM分配了大量线程块,也可能因寄存器或共享内存的限制而无法同时执行。
Section: Occupancy
------------------------------- ----------- ------------
Metric Name Metric Unit Metric Value
------------------------------- ----------- ------------
Block Limit SM block 16
Block Limit Registers block 32
Block Limit Shared Mem block 16
Block Limit Warps block 8
Theoretical Active Warps per SM warp 32
Theoretical Occupancy % 100
Achieved Occupancy % 84.07
Achieved Active Warps Per SM warp 26.90
------------------------------- ----------- ------------
OPT Est. Local Speedup: 15.93%
The difference between calculated theoretical (100.0%) and measured achieved occupancy (84.1%) can be the
result of warp scheduling overheads or workload imbalances during the kernel execution. Load imbalances can
occur between warps within a block as well as across blocks of the same kernel. See the CUDA Best Practices
Guide (https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/index.html#occupancy) for more details on
optimizing occupancy.
最后一个Workload Distribution部分评估了流水线各阶段的效率,下例显示DRAM部分活跃周期最长,是主要瓶颈。
Section: GPU and Memory Workload Distribution
-------------------------- ----------- ------------
Metric Name Metric Unit Metric Value
-------------------------- ----------- ------------
Average DRAM Active Cycles cycle 3425472
Total DRAM Elapsed Cycles cycle 30375936
Average L1 Active Cycles cycle 442967.55
Total L1 Elapsed Cycles cycle 17792384
Average L2 Active Cycles cycle 646922.66
Total L2 Elapsed Cycles cycle 20901664
Average SM Active Cycles cycle 442967.55
Total SM Elapsed Cycles cycle 17792384
Average SMSP Active Cycles cycle 443288.33
Total SMSP Elapsed Cycles cycle 71169536
-------------------------- ----------- ------------
常见优化手段实战分析
下面我们分析几个来自 https://github.com/gpu-mode/lectures/tree/main/lecture_008 的代码示例,通过ncu报告对比优化效果。
内存合并(Memory Coalescing)
对比连续内存访问与非连续内存访问的数据拷贝。
__global__ void copyDataNonCoalesced(float *in, float *out, int n) {
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < n) {
out[index] = in[(index * 2) % n];
}
}
__global__ void copyDataCoalesced(float *in, float *out, int n) {
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < n) {
out[index] = in[index];
}
}
报告对比分析:
- Duration:764 us vs 558.34 us。连续内存访问版本更快。
- Memory Throughput:NonCoalesced版本为90.22%,比Coalesced版本的82.75%更高。但这恰恰说明NonCoalesced版本取到了大量不需要的数据,做了更多无用功。指标高不一定代表性能好。
- Average DRAM Active Cycles:NonCoalesced为3,425,472, Coalesced为2,298,497。活跃周期更短,证明了Coalesced版本能更快完成任务。
- Achieved Occupancy:NonCoalesced 84.07% vs Coalesced 77.36%。再次说明高占用率不等于高效率。
- L1/TEX Cache Throughput:NonCoalesced 29.49% vs Coalesced 36.74%。缓存利用率更高,印证了Coalesced版本的高效率。
分支分歧(Divergence)
使用ncu时需要加上 --set full 参数才能看到指令级信息。
__global__ void processArrayWithDivergence(int *data, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
if (data[idx] % 2 == 0) {
data[idx] = data[idx] * 2;
} else {
data[idx] = data[idx] + 1;
}
}
}
__global__ void processArrayWithoutDivergence(int *data, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
int isEven = !(data[idx] % 2);
data[idx] = isEven * (data[idx] * 2) + (!isEven) * (data[idx] + 1);
}
}
报告对比分析:
- Duration:40.03 us vs 38.21 us。无分支分歧版本执行更快。
- Avg. Active Threads Per Warp:有分歧版本为29.18,无分歧版本为32。有分歧导致平均每个Warp有约3个线程闲置,硬件利用率不满。
- Excessive Sectors:有分歧版本为131,072 (33%),无分歧版本为0。分支分歧导致了严重的未合并访问,33%的显存带宽浪费在读取无用数据上,是性能下降主因。
- Executed Instructions:有分歧版本557,056条,无分歧版本491,520条。分歧迫使GPU串行执行if/else分支,导致指令总数显著增加。
- L1/TEX Hit Rate:有分歧版本66.62% vs 无分歧版本49.67%。有分歧版本的高命中率是对冗余数据的重复命中,高指标恰恰是低效访问的体现。
线程粗化(Thread Coarsening)
原始代码在小数据量下跑出了负优化,因为粗化加剧了硬件闲置。
__global__ void VecAdd(float* A, float* B, float* C, int n)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n)
C[i] = A[i] + B[i];
}
// Optimized: 1 thread per [COARSENING_FACTOR] elements
// Crucial Fix: Uses Strided Access to maintain Memory Coalescing
__global__ void VecAddCoarsened(float* A, float* B, float* C, int n)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
// By unrolling this loop, the compiler can issue multiple global memory loads
// before stalling for the first one (Instruction Level Parallelism)
// Access pattern: Thread 0 handles 0, 0+S, 0+2S, 0+3S
// Access pattern: Thread 1 handles 1, 1+S, 1+2S, 1+3S
// This ensures that for any iteration ‘i‘, the warp accesses contiguous memory.
for (int i = 0; i < COARSENING_FACTOR; i++) {
int realIdx = idx + i * stride;
if (realIdx < n) {
C[realIdx] = A[realIdx] + B[realIdx];
}
}
}
报告对比分析:
- Host Execution Time (Total):119.92 ms vs 113.93 ms (Speedup 1.05x)。虽然单次内核执行时间持平,但总时间减少。因为粗化减少了75%的线程块数量(65536 -> 16384),显著降低了GPU调度和主机端启动的开销。
- Memory Throughput:90.31% vs 90.67%。两个版本都达到90%+的显存带宽利用率,性能已被物理带宽锁死。
- Compute (SM) Throughput:23.40% vs 18.84%。粗化版本的SM利用率反而降低了,说明它用更少的SM资源完成了同样任务,提高了指令效率,减少了冗余计算。
- Achieved Occupancy:82.94% vs 93.74%。粗化版本占有率显著提升,调度更充分。
- Grid Size:65536 vs 16384 (减少了4倍)。这种“更少但更胖”的线程策略在大规模调度中更友好。
数据私有化(Privatization)
原始代码同样是负优化,因为将数据搬到共享内存的开销超过了直接利用全局内存缓存的收益。
__global__ void windowSumDirect(const float *input, float *output, int n, int windowSize) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int halfWindow = windowSize / 2;
if (idx < n) {
float sum = 0.0f;
for (int i = -halfWindow; i <= halfWindow; ++i) {
int accessIdx = idx + i;
if (accessIdx >= 0 && accessIdx < n) {
sum += input[accessIdx];
}
}
output[idx] = sum;
}
}
// Optimized Privatized Kernel: Handles Halo correctly and minimizes Global Memory reads
__global__ void windowSumPrivatized(const float *input, float *output, int n, int windowSize) {
extern __shared__ float s_data[];
int tid = threadIdx.x;
int g_idx = blockIdx.x * blockDim.x + tid;
int halfWindow = windowSize / 2;
int s_idx = tid + halfWindow;
// --- Phase 1: Load Data into Shared Memory (Global -> Shared) ---
if (g_idx < n) {
s_data[s_idx] = input[g_idx];
} else {
s_data[s_idx] = 0.0f;
}
if (tid < halfWindow) {
int left_g_idx = g_idx - halfWindow;
if (left_g_idx >= 0) {
s_data[s_idx - halfWindow] = input[left_g_idx];
} else {
s_data[s_idx - halfWindow] = 0.0f;
}
}
if (tid >= blockDim.x - halfWindow) {
int right_g_idx = g_idx + halfWindow;
if (right_g_idx < n) {
s_data[s_idx + halfWindow] = input[right_g_idx];
} else {
s_data[s_idx + halfWindow] = 0.0f;
}
}
__syncthreads();
// --- Phase 2: Compute using only Shared Memory (Shared -> Register) ---
if (g_idx < n) {
float sum = 0.0f;
for (int i = -halfWindow; i <= halfWindow; ++i) {
sum += s_data[s_idx + i];
}
output[g_idx] = sum;
}
}
报告对比分析 (windowSize = 21):
- Duration:98.88 us (Direct) vs 99.17 us (Privatized)。两者几乎持平,甚至优化版略慢。
- L1/TEX Cache Throughput:74.97% (Direct) vs 79.14% (Privatized)。两个版本L1吞吐都很高。直接访问版本虽然多次读全局内存,但因其访问是连续且有极高空间局部性,L1缓存完美地起到了“隐式共享内存”的作用。
- DRAM Throughput:~30% (Both)。两者显存带宽利用率都低,证明瓶颈不在显存带宽。私有化节省带宽的优化在没有瓶颈的地方自然无效。
- Achieved Occupancy:72.10% vs 91.26%。私有化版本占有率更高,但因其单线程指令变复杂,高占有率未能转化为高性能。
- Registers Per Thread:16 vs 28。私有化版本为处理复杂索引,寄存器压力大增。
这份报告揭示了一个经典现象:在现代GPU架构上,优秀的L1缓存往往能打败手写的共享内存优化,尤其是在访问模式非常规则的情况下。
优化思路总结
GPU计算的瓶颈通常在于计算或带宽。对于一个给定的算法,合理安排并行执行、充分利用计算单元通常并不困难。想要从根本上优化计算复杂度,需要从数学上重写算法,难度极大。因此,CUDA程序优化最大的发挥空间在于提高数据通信的效率。
在硬件已定的前提下,提高数据传输的绝对速度是不可能的。我们能做的是合理利用不同的存储单元(全局内存、共享内存、寄存器),通过延迟隐藏(latency hiding,即流水线思想)来让计算单元“忙”起来,而不是彻底消除延迟。
所有的优化手段都有其代价。我们希望收益大于成本,但现实往往并非如此。只有通过科学的性能剖析(Profiling),才能找到真正的性能甜蜜点,实现系统性能的有效提升。掌握这些分析工具和硬件原理,是你迈向高效C/C++ GPU编程的关键一步。
如果你对高性能计算、CUDA编程有更深入的问题或想分享自己的经验,欢迎来 云栈社区 的开发者论坛与大家一起交流探讨。社区内也有更多关于计算硬件、操作系统底层原理的深度内容。
参考链接:
 发表于 2026-2-5 03:03:17
|
查看: 289|
回复: 0
发表于 2026-2-5 03:03:17
|
查看: 289|
回复: 0
