2026上半年,Skill 数量井喷。许多团队急于将内部工作流全部 Skill 化,仿佛给大模型装上插件就能让它“立刻变专业”。
但当 Skill 数量从十几个膨胀到几百个,一个朴素的问题浮现出来:装上 Skill,是不是真的就一定更强?
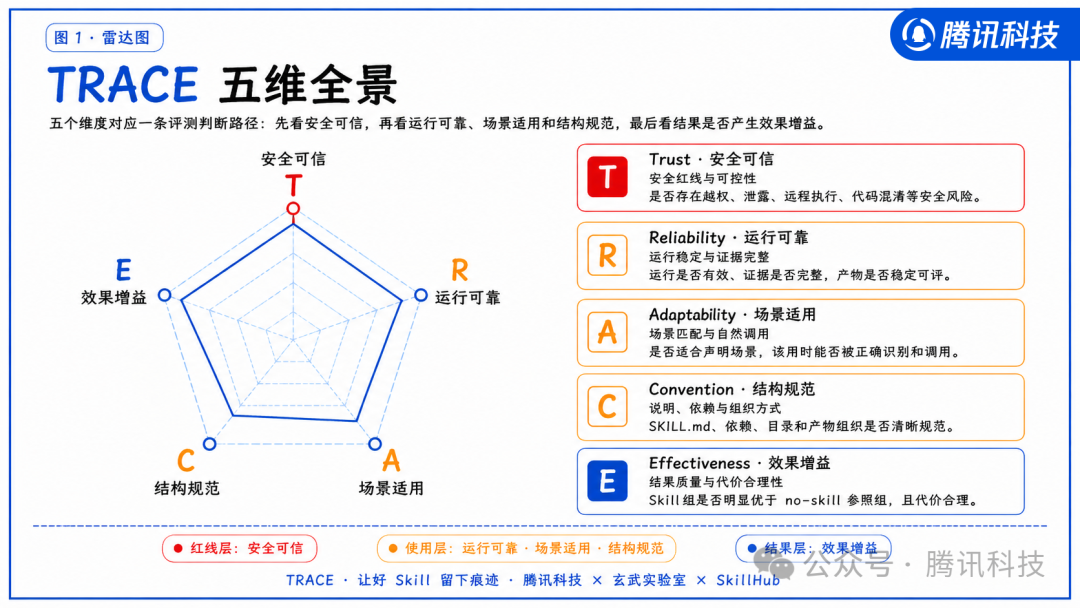
带着这个疑问,我们在 TRACE 严选评测 中做了一轮系统化的实验。我们没有采用“看下载榜”或“跑一次给个分”的轻量做法,而是在统一的 prompt、统一的裁判和统一的评测口径下,让每个 Skill 与“裸模型”(no-skill)完成:150 组任务级对比、30 个 Skill 的成本与稳定性分析、107 条规范性问题复查,以及一轮跨模型推理强度的可迁移性测试。
关于 TRACE 严选评测的详细介绍,可参考《3张图、5000字,认真聊聊什么才是好的skill》。
在持续评测 Skill 的过程中,我们整理出 7 个最值得关注的发现,并将实验数据、评测过程与机制解释集中公开。其中不少结论,与直觉相去甚远。
01 有 Skill 不一定效果更好
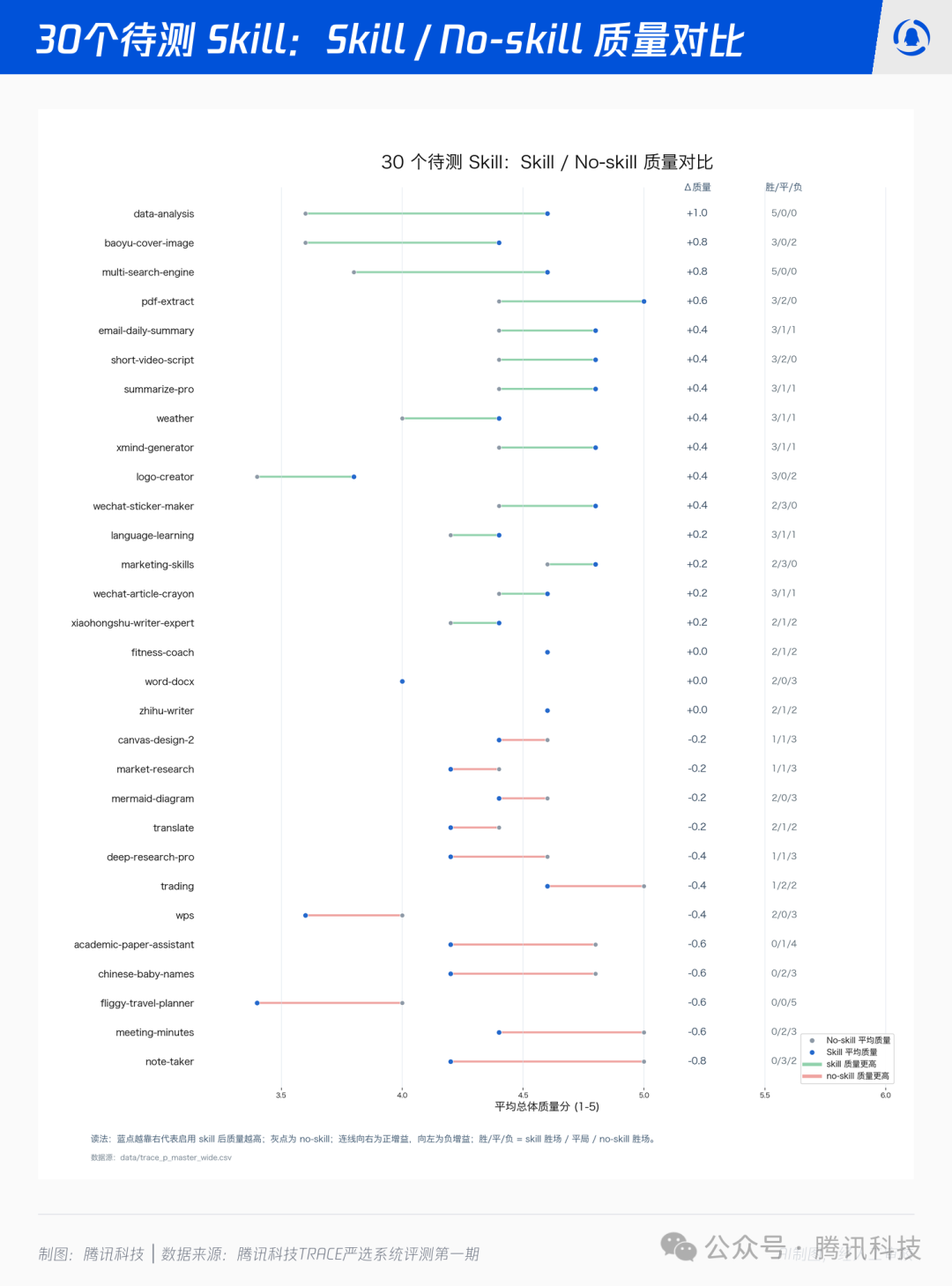
我们安装 Skill 的初衷是让大模型或通用 Agent 获得更强的专业能力。但在实验中,第一个被推翻的想法正是“装了 Skill 就更好”。
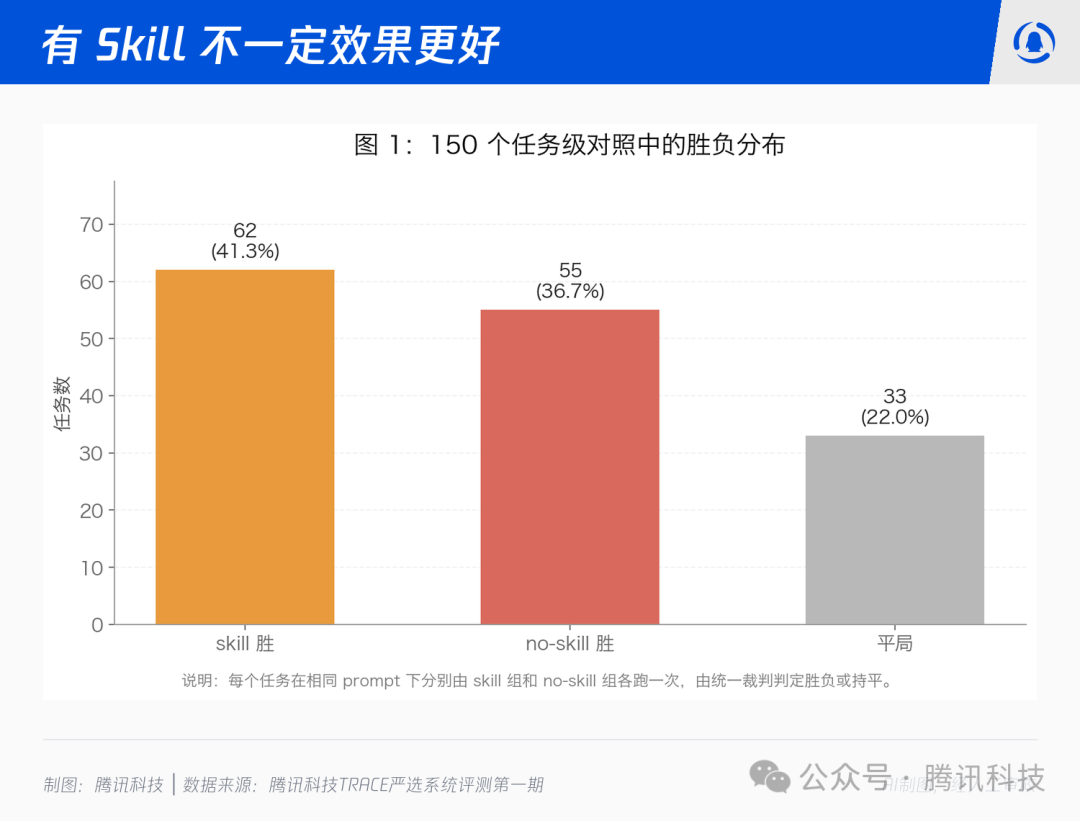
在 150 组任务级对照中,Skill 组胜出 62 次(41.3%),no-skill 组胜出 55 次(36.7%),平局 33 次(22.0%)。Skill 组只是略占优势,远谈不上压倒性。
更关键的是,差异在 Skill 之间剧烈分化:
- 稳定带来正增益的 Skill 包括:
data-analysis、multi-search-engine、baoyu-cover-image 等;
- 不如裸模型的 Skill:
note-taker、fliggy-travel-planner、meeting-minutes 等。
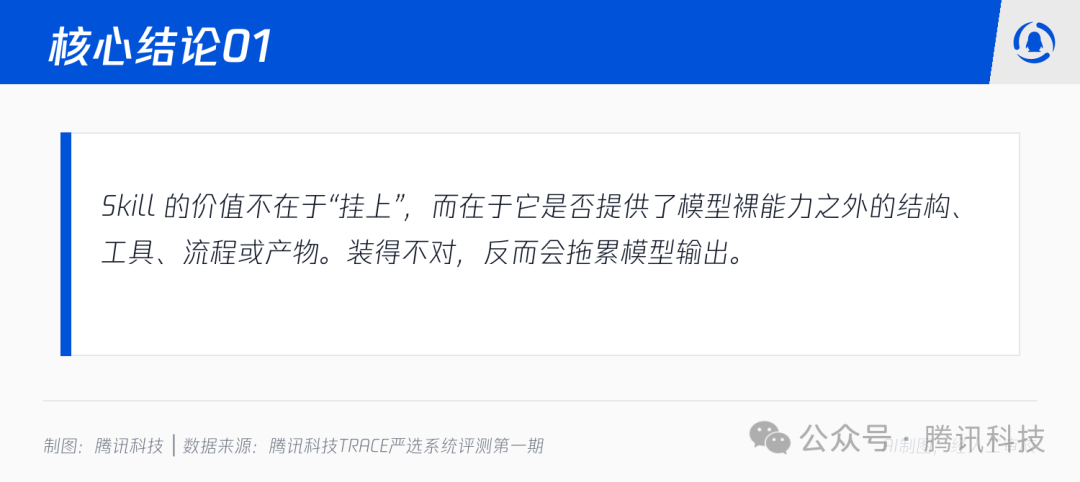
为什么会这样?我们把胜负样本一条条翻下来,规律其实很清晰:当 Skill 真正补充了模型裸能力之外的东西——比如一个清晰的输出结构、一组外部工具、一条受约束的工作流,或一份具体可交付的产物——它就是有用的;当 Skill 只是把模型本来就会的事情再用 Markdown 重写一遍时,它带来的更多是负担,而非增益。
02 Skill 存在虹吸现象
我们在 Skill 路由实验中观察到一个被称为“Skill 虹吸”的现象:有些请求本来很轻,裸模型直接回答即可,但只要语义上贴近某个 Skill,系统仍可能忍不住去读取这个 Skill。
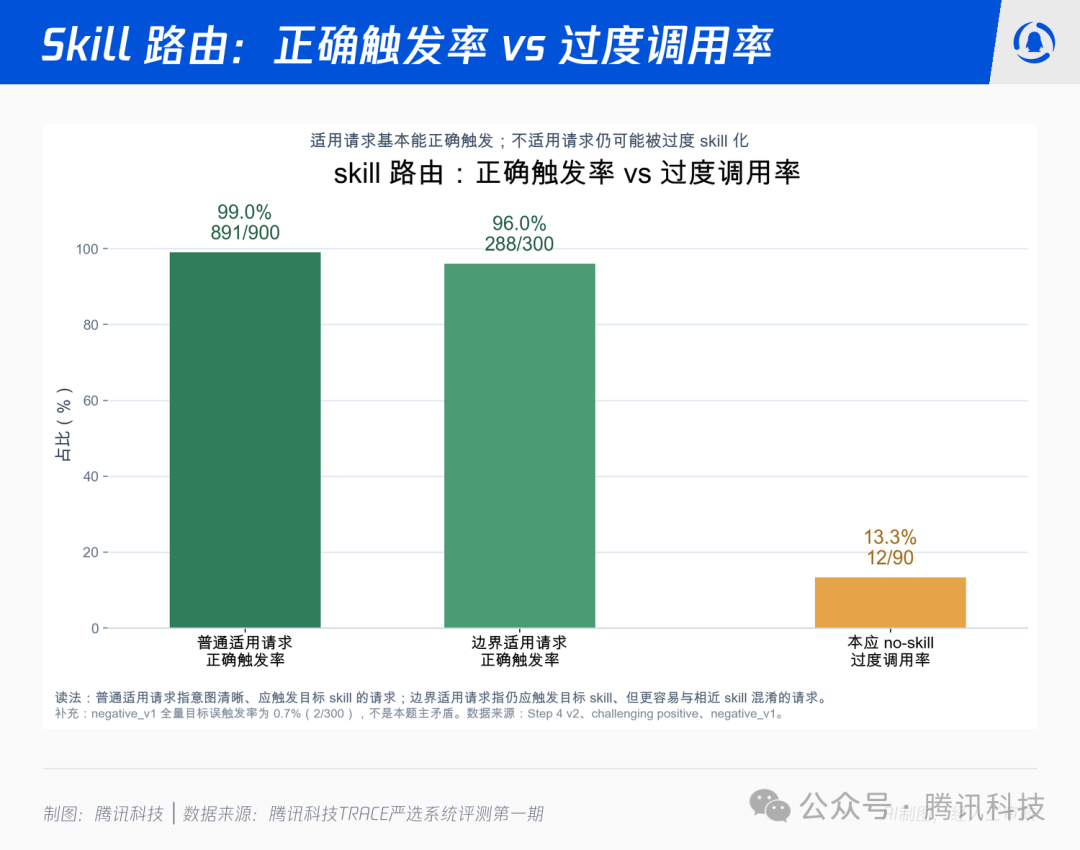
为了区分情况,我们设计了三类请求:
- 普通适用请求:用户意图明确,理当触发目标 Skill。
- 边界适用请求:仍应触发目标 Skill,但语义更接近相邻 Skill,用于观察干扰情况。
- 本应 no-skill 的请求:任务很轻,理论上裸模型可直接回答,不应调用任何 Skill。
结果显示,系统在“该用 Skill”时表现很好:普通适用请求的正确触发率为 99.0%(891/900),边界适用请求也达到 96.0%(288/300)。这说明它不是普遍找不到正确的 Skill。
真正的问题出现在“不该用 Skill”时:90 条本应 no-skill 的请求里,有 12 条仍读取了某个 Skill,过度调用率达 13.3%(12/90)。
两个例子很直观:
- 用户说:“不用上网,帮我想 5 个适合检索‘办公室绿植养护’的中文关键词组合。”
这本只是关键词头脑风暴,但“检索”“关键词”却把它吸进了搜索类 Skill(multi-search-engine)。
- 用户说:“把这句话改得更自然:我们通过更好的客户沟通来创造长期商业价值。”
这原只是单句改写,但“客户沟通”“商业价值”让它看起来像营销任务,于是被吸进了营销类 Skill(marketing-skills)。
因此,“Skill 虹吸”并非路由系统乱触发,而是一种更具体的偏差:该用 Skill 时,它很会召回;不该用时,有时却不够克制。当请求仅是简单改写、短语生成或概念解释时,只要出现 Skill description 中的相关领域词,就可能被吸进某个 Skill。
这种副作用会带来额外上下文和潜在的 token/时间成本,也会让本来一句话能完成的任务,被套进更重的专门工作流。

03 多数 Skill 并不能节省 Token 与时间
为了回答“装上 Skill 后是否更贵?”,我们定义了两个指标:
- token 倍率 = skill 组平均每任务 token / no-skill 组平均每任务 token;
- 耗时倍率 = skill 组平均每任务耗时 / no-skill 组平均每任务耗时。
1.0 表示与 no-skill 持平,大于 1.0 即更贵。30 个 Skill 的全样本实验结果如下:装上 Skill 后,token 消耗平均多了 48%,耗时平均长了 19%。
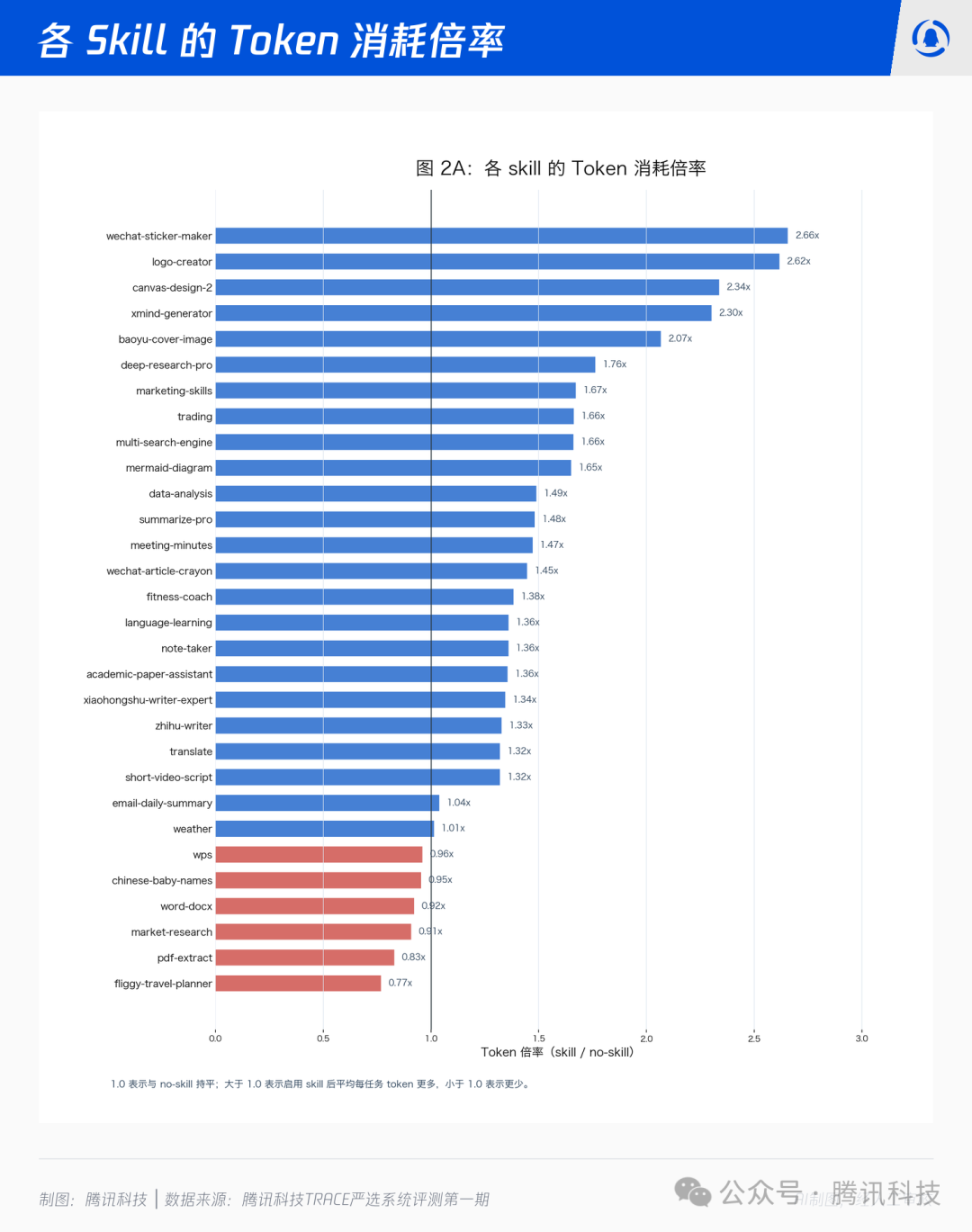
Token 的消耗上涨更明显。倍率最高的一批集中在多媒体生成、复杂产物组织、结构化交付场景。耗时的分布相对温和,但同样存在“极端拉长”时长的尾部 skill。
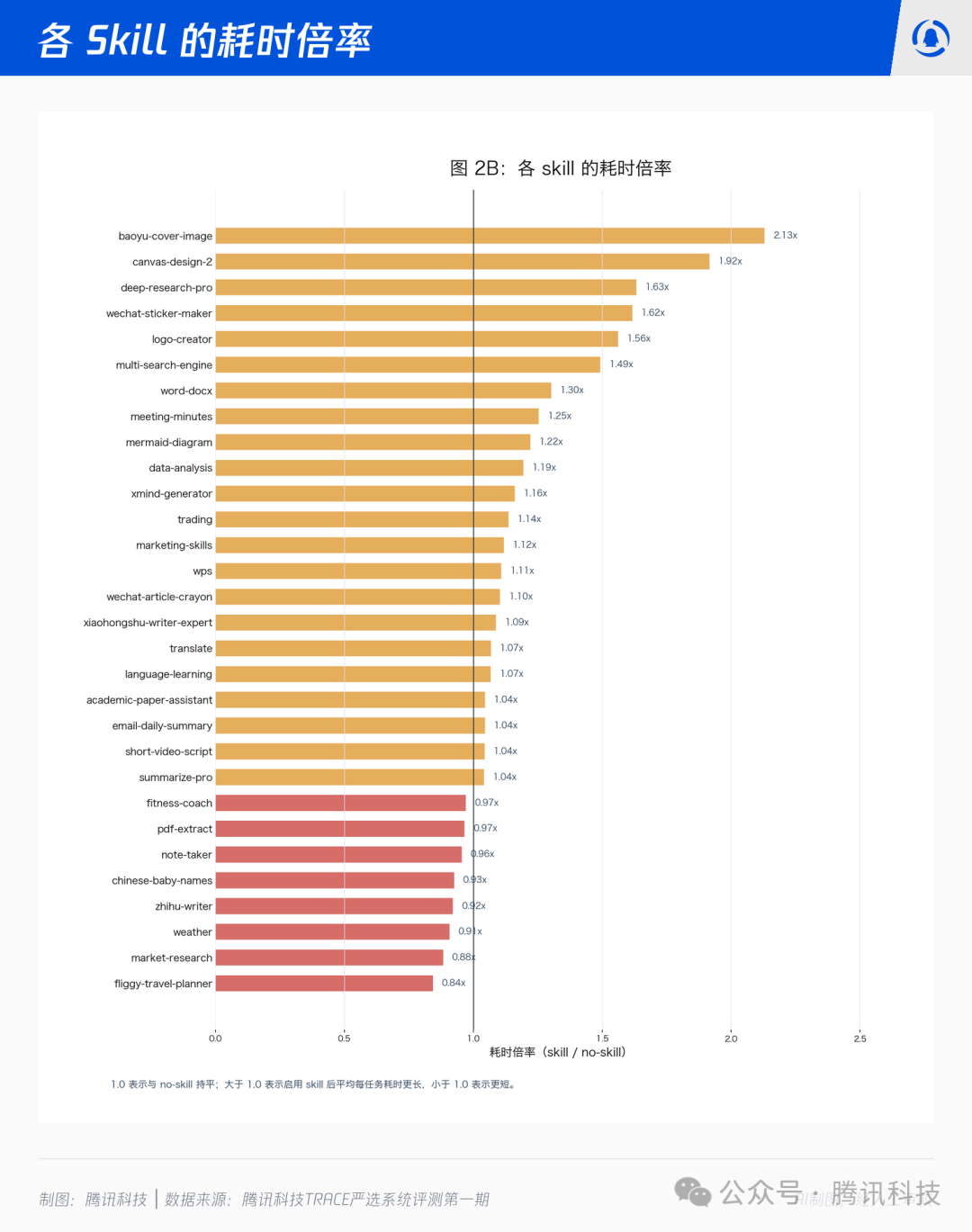
值得注意的是,Skill 不总是更贵。fliggy-travel-planner、pdf-extract、market-research、word-docx、chinese-baby-names 等 Skill 的 token 倍率反而低于 1.0;fliggy-travel-planner、market-research、weather、zhihu-writer、chinese-baby-names 的耗时倍率也低于 1.0。原因不难理解:当 Skill 给出了明确的流程、收束的输出边界、清晰的“该做/不该做”,模型反而减少了无效探索,整体消耗下降。但就整体而言,装上 Skill 后,token 和时间消耗都有所增加。

04 更耗 Token 的 Skill 通常也更慢,但二者并非严格绑定
我们把每个 Skill 的 token 倍率和耗时倍率画到同一张散点图上,看到一条相关斜线:Pearson r = 0.73。
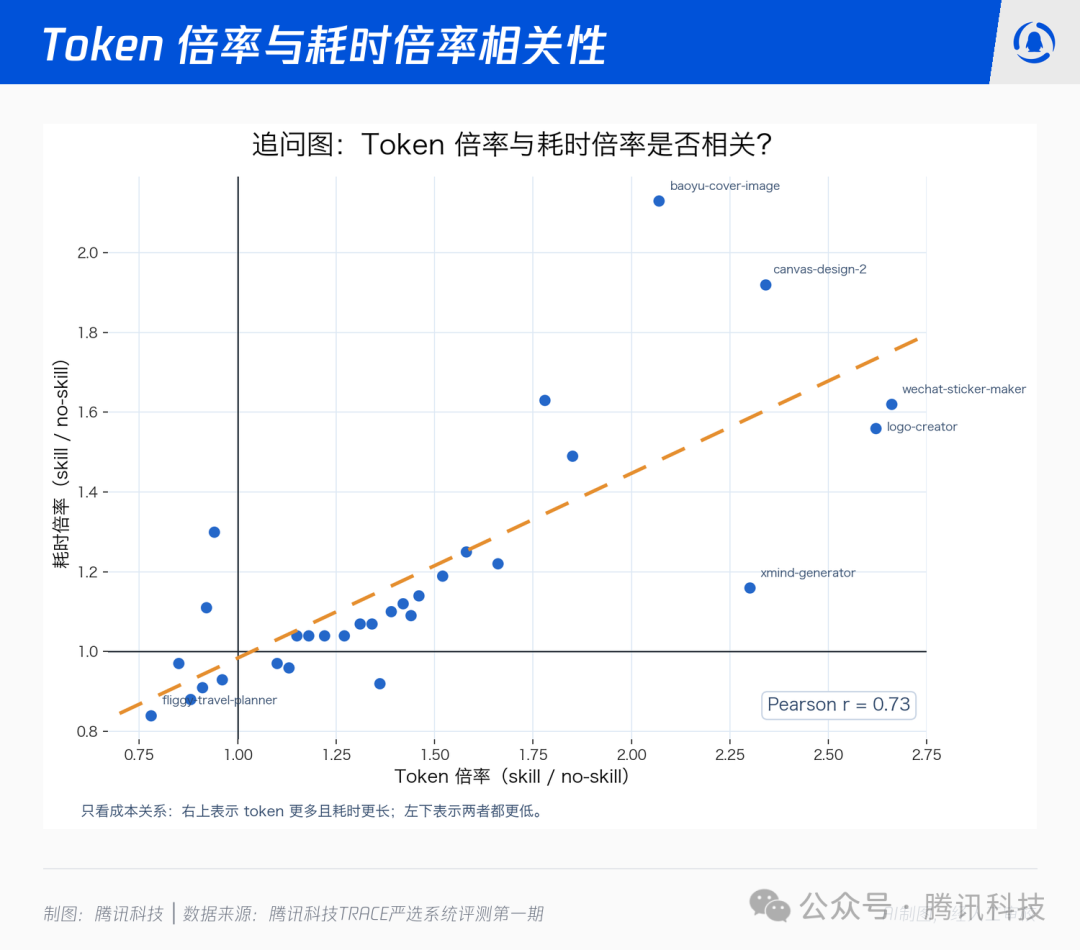
canvas-design-2、baoyu-cover-image、wechat-sticker-maker、logo-creator、deep-research-pro、multi-search-engine 都集中在右上角的“双高”区。这些 Skill 通常需要更长上下文、更多轮次或更复杂的工具调用。
有意思的是两组反例:
- token 高 / 耗时不高:
fitness-coach、note-taker、weather、zhihu-writer。Skill 让模型读了更多上下文、写了更长回答,但未增加外部等待和文件处理。
- token 不高 / 耗时高:
word-docx、wps。这类 Skill 的瓶颈不在语言模型,而在 Office/WPS 工具链、脚本执行、文件格式处理,这些时间在 token 维度根本看不见。

05 规范性问题主要集中在依赖、边界与资源组织
TRACE 中的 C 维度(结构规范)常被误读为“文档好不好看”,实际上它更接近于“工程债”。
30 个 Skill 的 C 维度复评共发现 107 条规范性问题。
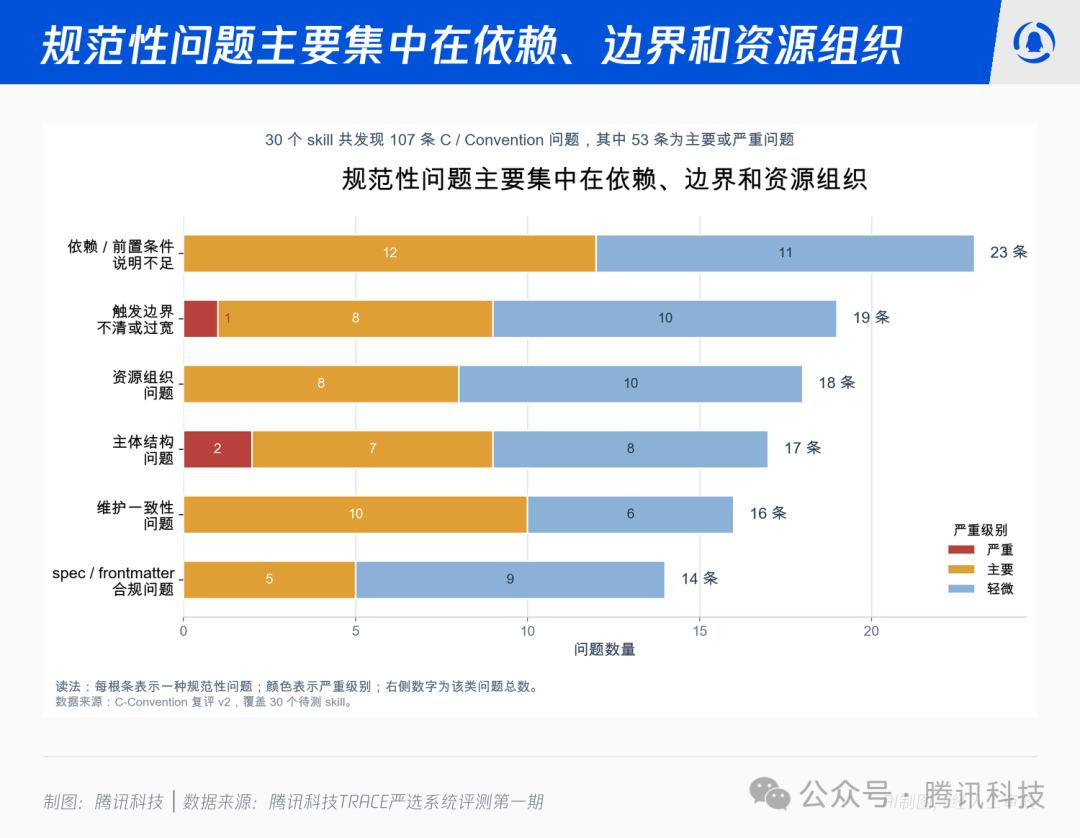
在依赖、维护一致性、资源组织、触发边界这四类里,都存在大量 major 级问题,意味着它们会直接影响 Agent 判断“什么时候用、怎么运行、需要什么工具、产物在哪里、文档与脚本是否一致”。
把这些问题串起来看,一个 Skill 可能效果不错,但只要依赖没写清、边界过宽、资源引用缺失或元数据漂移,后续复用、评测、自动化升级都会越来越脆弱。
06 稳定性风险来自工具链、长等待和反复修正
提起“Skill 不稳定”,第一反应往往是“模型答错了”。但合并历史运行风险与重复运行实验后,我们看到的结果正好相反——最常见的不稳定,并非来自模型本身。
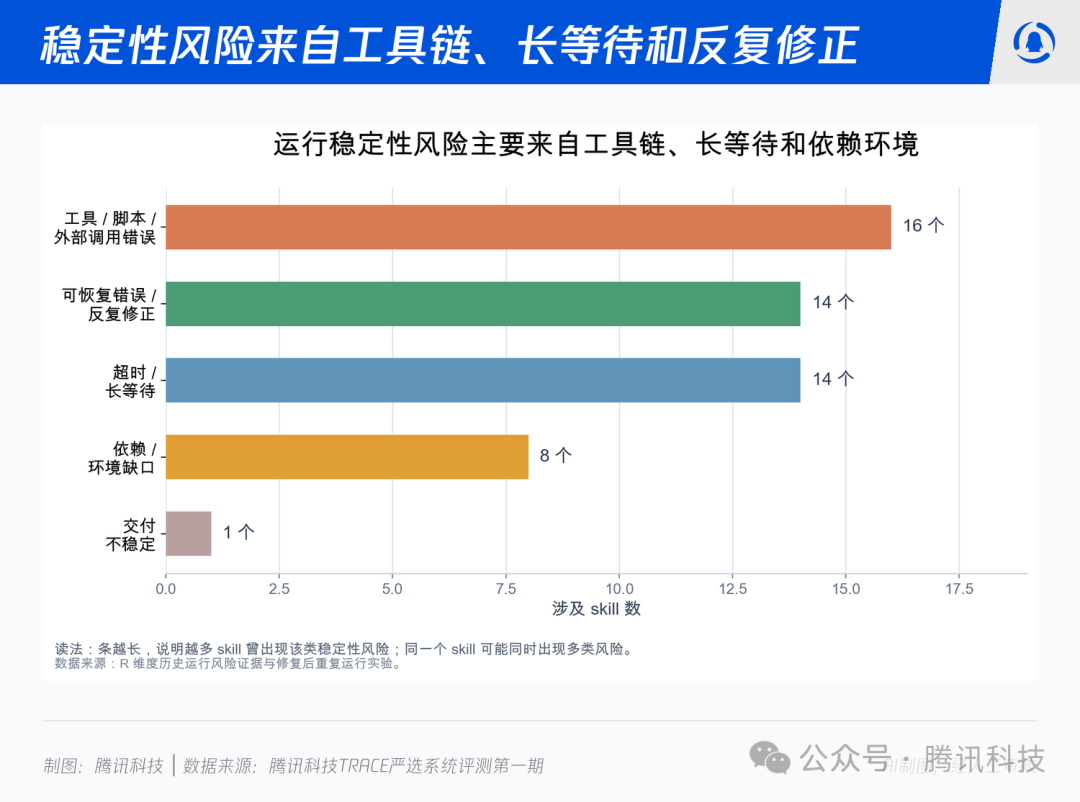
近一半的 Skill 都至少在工具链、外部调用、长等待或反复修正中遇到过问题。这指向一个被低估的事实:当 Skill 从“提示词”演变为“带工具、脚本、文件和外部服务的完整流程”,稳定性就不再是大模型的能力问题,而是一个工程链路问题。
越依赖多步骤工具链、外部 API 和长时间等待的 Skill,稳定性的暴露面就越大。
07 提高模型推理强度通常能改善 Skill 表现,但收益不均匀
最后一个发现来自 P-M1(Portability,可迁移性实验)。我们覆盖了首批推荐的 10 个 Skill,每个 Skill 选 5 个任务,分别在 low 与 xhigh 两档模型推理强度下运行,由顶级旗舰模型担任裁判。
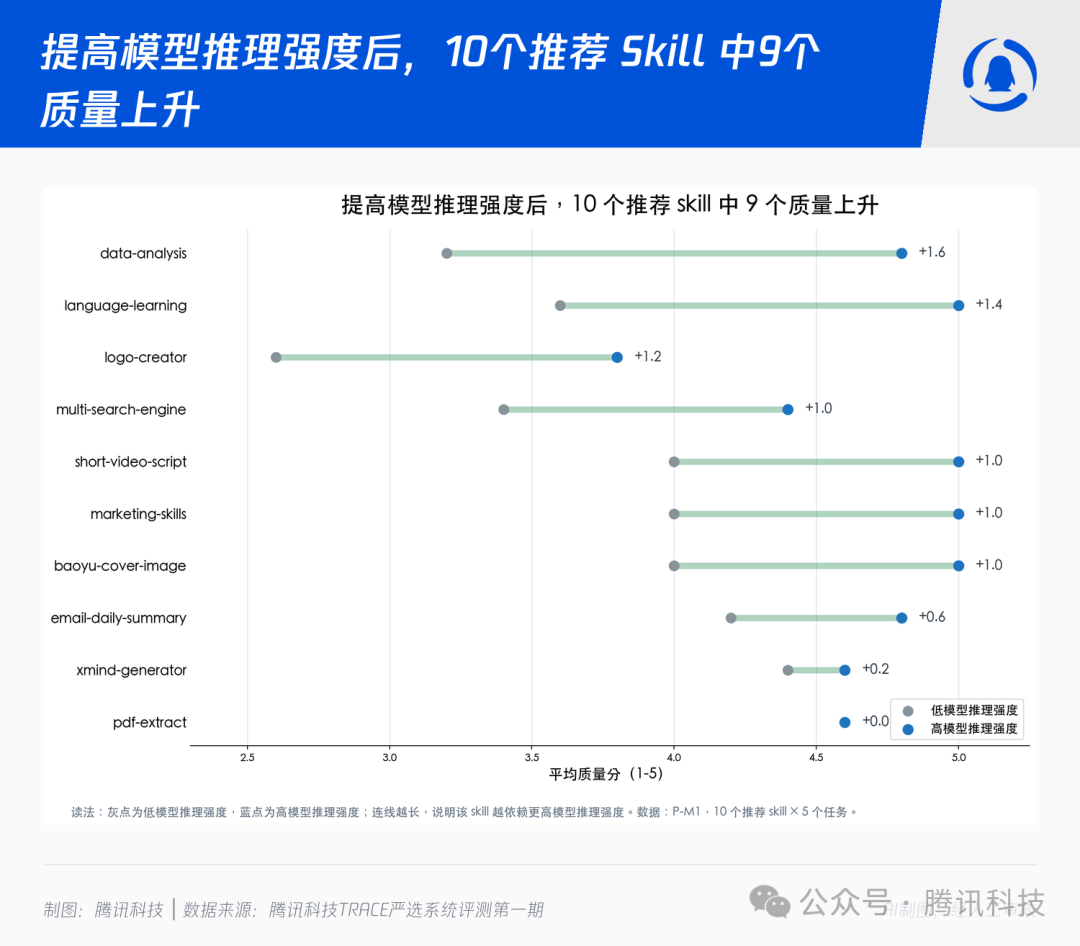
整体看,收益很显著:
- 平均质量分:low 3.80 → xhigh 4.70,平均提升 +0.90;
- 50 个任务级对比中:xhigh 胜 39,low 胜 5,平 6;
- 10 个 Skill 中,9 个在 xhigh 下质量上升,仅
pdf-extract 基本持平。
但收益分布并不均匀。对推理强度更敏感的,主要是这三类:
- 需要处理隐藏约束的(
data-analysis:业务规则、口径细节);
- 需要细节核对、多步交付的(
logo-creator、baoyu-cover-image、canvas-design-2:视觉细节、布局合理性);
- 强创作类的(
language-learning、deep-research-pro:长文质量、推理深度)。
而像 pdf-extract、xmind-generator 这种流程明确、结构性强的 Skill,本身就把“易错点”压缩进了固定流程,模型推理强度的变化反而拉不开差距。
需要强调,这一项实验不并入 TRACE 五维均分,只作为推荐风险的补充观察。但它给出了一个非常实用的指引。
08 给开发者的建议
基于以上实验结果,我们总结了几条给 Skill 开发者的建议:
- 先做 no-skill baseline,证明 Skill 真的有收益
- 写清楚适用边界,避免 Skill 虹吸现象
- 控制上下文和资源加载,避免 Skill 变成成本黑洞
- 把隐性约束写进流程,而不是寄希望于模型自己想起
- 关注工具链、文件和外部服务带来的工程稳定性
- 持续记录误触发、失败样本和异常耗时,像产品一样迭代 Skill
09 写在最后
这些实验结论,有的颠覆了我们对于 Skill 的认知。
眼下,关于 Skill 的未来,被讨论最多的是它能做什么——多一个 Skill,就像给模型多发一张技能卡。但这轮实验给出的提醒恰恰相反:在急着追问“还能加什么”之前,更值得先弄清楚它的技术边界在哪里。
这种边界感,对不同的人意味着不同的东西。对企业管理者,Skill 是一种诱人的杠杆,仿佛普通员工一夜之间就能获资深员工的产出;而对真正在使用它的人,Skill 更像一件趁手或不趁手的工具,装错了反而要花时间替它收拾残局。
两种期待之间的落差,正是今天大量 Skill“看起来很会、用起来一般”的来源。弄清楚一个 Skill 到底补上了模型的哪块短板、又在哪里只是徒增成本,比再多上架几个 Skill 更重要。
而眼下的难处在于,关于 Skill 的客观定量分析还太少。它的魔法和大模型本身的魔法缠在一起,效率、效果、稳定性,大多还是一个说不清的黑盒。整个行业更熟悉“它能做什么”的演示,却少有人深究“它到底值不值、什么时候反而碍事”。
期待越来越多人用客观审慎的眼光去评估“装上这个 Skill 是不是真的更好”,它才算从魔法,慢慢变回一种可以被检验、被复用、被信任的方法。
这一天到来之前,克制地问一句“它真的需要吗”,或许比急着再装一个,更接近答案。技术社区的每一次深度评测与开源贡献,也在悄然推动这种从黑盒到透明的转变。
 发表于 2026-5-22 21:39:45
|
查看: 133|
回复: 0
发表于 2026-5-22 21:39:45
|
查看: 133|
回复: 0
