前几天我又被一个需求狠狠干了一下。
需求不大:给老项目补一个导出功能,顺手修两个历史遗留 Bug。听起来像是“半小时搞定”的那种活儿,结果一打开仓库,代码像一锅粘了锅底的粥,谁也别笑谁,反正都不好看。
我本来想自己硬扛,后来手一抖,打开了 OpenCode。
再后来,我又装上了 Oh My OpenCode。
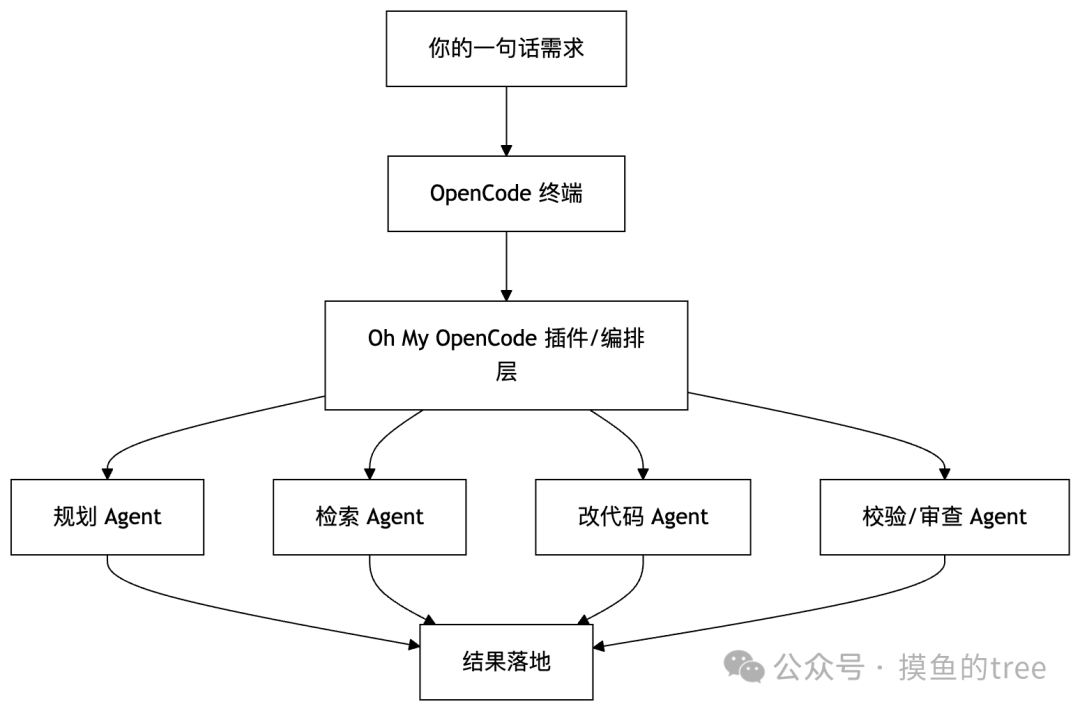
然后这事就变味了。原本是我自己吭哧吭哧修代码,后来变成了终端里一群 AI 帮我分工:一个负责看项目,一个负责查文档,一个负责想方案,一个负责改代码。说人话就是:我从搬砖的,直接变成了项目经理。
这篇文章,我就把这套组合拳讲明白:OpenCode 是什么,Oh My OpenCode 是什么,怎么装,怎么配,怎么用,怎么避坑。
先把概念捋直
OpenCode 你可以理解成一个终端里的 AI 编程助手。它能在命令行里跟你对话,能读代码、改代码、做计划、回滚修改,还能接不同的模型提供商。
Oh My OpenCode 则更狠一点。它不是单纯“再加一个壳”,而是把 OpenCode 直接武装成一个更像团队协作的 agent harness。
它干的事大概是这些:
- 给 OpenCode 加上更强的多智能体编排
- 自动分配背景任务,减少主对话上下文压力
- 提供更完整的 agent、skill、hook、MCP、LSP 体系
- 把“我一句话,它自己跑完”的体验推到更极致
你可以把它理解成:
OpenCode 是车,Oh My OpenCode 是把车改成了战车。
第一步:先装 OpenCode
官方最省事的方式,就是一条命令。
curl -fsSL https://opencode.ai/install | bash
如果你是包管理器党,也可以选别的路:
npm i -g opencode-ai
bun install -g opencode-ai
pnpm install -g opencode-ai
yarn global add opencode-ai
brew install anomalyco/tap/opencode
装完以后,先跑起来:
opencode
第一次进来,你会看到一个 TUI 界面。黑底白字,没花里胡哨的按钮,像极了那种“看起来很朴素,实际很能打”的老练选手。
第二步:把模型接上
OpenCode 本身不替你提供模型。它更像一个统一入口,所以你得先接一个 provider。
最常见的做法是在 OpenCode 里执行:
/connect
然后按提示选择 OpenCode、Claude、OpenAI、Gemini 或其他 provider,填 API key。
如果你是新手,我建议你先别折腾太多花样,先让它跑起来再说。工具这玩意儿,最怕的不是不会用,最怕的是一上来就把自己配晕。
第三步:给项目建一份 AGENTS.md
这个步骤特别重要。很多人 AI 用不好,不是模型不行,是它压根不知道你项目的规矩。
在项目根目录里运行:
/init
OpenCode 会分析你的仓库,生成一份 AGENTS.md。
这份文件的作用很简单:告诉 AI 这个项目怎么玩。
比如:
- 用什么技术栈
- 什么命名风格
- 怎么测试
- 哪些目录不能乱碰
没有它,AI 就像新来的实习生,啥都敢写,啥都敢改,最后最忙的还是你。
第四步:安装 Oh My OpenCode
这里开始进入正题。
Oh My OpenCode 官方现在的仓库名是 oh-my-openagent,但大家很多时候还是习惯叫它 Oh My OpenCode。为了方便搜资料,我下面继续沿用老名字。
官方推荐的安装方式之一是:
bunx oh-my-opencode install
它会根据你当前可用的模型提供商,帮你生成一套默认配置。
安装完后,通常会在这些位置看到配置:
~/.config/opencode/oh-my-opencode.json- 项目内:
.opencode/oh-my-opencode.json
如果你想手动控一下模型分配,也可以这么写一个 JSONC 配置:
{
"$schema": "https://raw.githubusercontent.com/code-yeongyu/oh-my-opencode/master/assets/oh-my-opencode.schema.json",
"agents": {
"atlas": { "model": "anthropic/claude-sonnet-4-5" },
"librarian": { "model": "anthropic/claude-haiku-4-5" },
"explore": { "model": "opencode/gpt-5-nano" }
},
"categories": {
"quick": { "model": "opencode/gpt-5-nano" },
"unspecified-low": { "model": "zai-coding-plan/glm-4.7" }
}
}
你会发现它的思路很直接:
- 大任务交给更强的模型
- 便宜活交给便宜模型
- 检索、规划、审查各司其职
这就对了。别让一个模型从头干到尾,容易累死,也容易跑偏。
第五步:真正开始用
OpenCode + Oh My OpenCode 最爽的地方,不是“能不能用”,而是“怎么用才像开挂”。
方式一:直接丢需求,让它自己跑
你可以直接这么说:
ulw 帮我给这个项目加一个用户导出功能,要求兼容现有权限体系,顺手把相关测试补上。
这里的 ulw 或 ultrawork,就是 Oh My OpenCode 里那个魔法词。
它的意思很粗暴:别问了,自己研究,自己规划,自己落地,自己验收。
适合这些场景:
- 新增功能
- 修 Bug
- 重构一段老代码
- 批量清理 lint
- 补测试
方式二:复杂任务先规划,再执行
如果你碰的是那种一动就牵一串的需求,别上来就让它开改,先切到规划模式。
在 OpenCode 里按 Tab,进入 Plan / Prometheus 风格的规划流程,先让它问你问题、拆任务、列风险。
然后再执行。
这个流程的好处很明显:
- 先确认需求,减少返工
- 先看边界,避免乱改
- 先出方案,心里有数
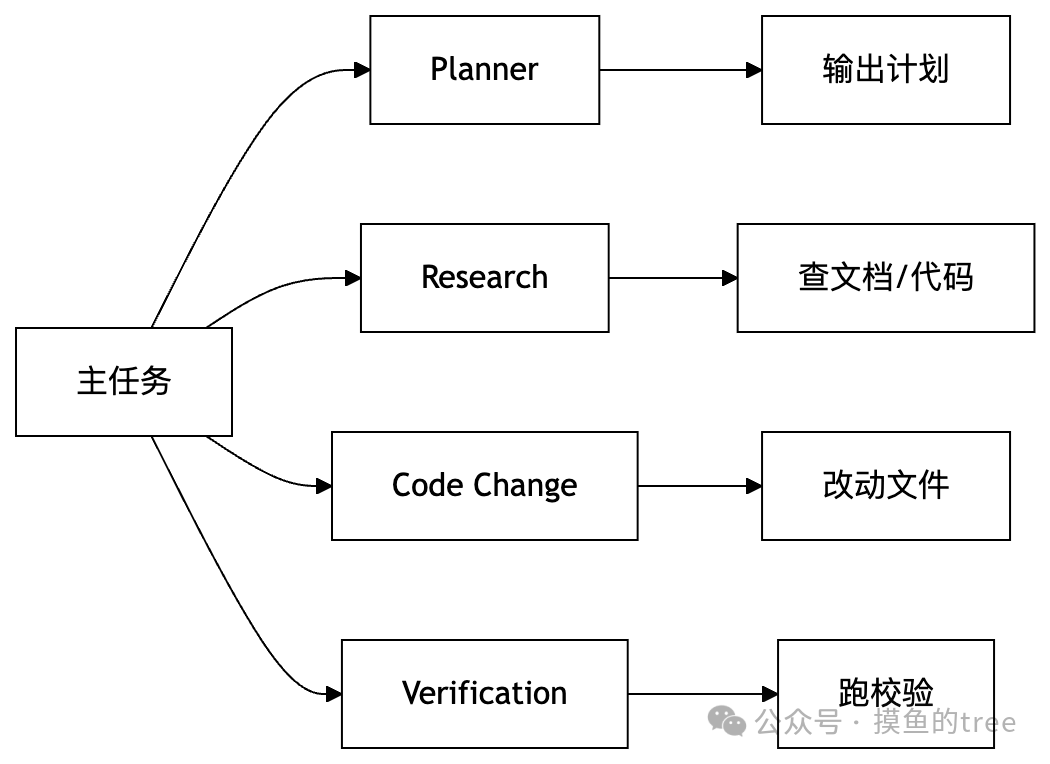
方式三:让它像团队一样分工
Oh My OpenCode 最狠的地方,就是它不把 AI 当成“一个万能打工人”,而是当成“一个小团队”。
你能明显感觉到:
- 有人负责看全局
- 有人负责查资料
- 有人负责改代码
- 有人负责验证结果
这比让一个模型从头单挑,稳定得多。
我建议你这么配
别一上来就追求“全家桶拉满”,先用最稳的方式跑通。
| 场景 |
推荐做法 |
原因 |
| 日常改代码 |
ulw 直接干 |
省心,效率高 |
| 多文件重构 |
先 Plan 再 Build |
防止误伤 |
| 新项目上手 |
先 /init 生成 AGENTS.md |
让 AI 先懂规矩 |
| 模型分配 |
主任务用强模型,检索用轻模型 |
省钱又稳 |
手把手跑一遍完整流程
如果你是第一次上手,我建议你照这个顺序来。
1. 先确认环境
OpenCode 走的是终端路线,所以别拿老古董终端硬怼。官方建议的思路很简单:用一个现代一点的终端,比如 WezTerm、Ghostty、Kitty 这类。
你不需要把环境搞成航天发射中心,但至少得保证这些东西没问题:
- 能正常运行
opencode
- 能连上你选的模型 provider
- 项目里有可读的
AGENTS.md
2. 先让 OpenCode 认识项目
进项目目录后先执行:
cd /path/to/project
opencode
然后输入:
/init
这一步非常值钱。它不是装饰品,它是在给 AI 建项目认知。
3. 再装 Oh My OpenCode
安装后别急着写大需求,先看看它有没有把配置写好。
重点关注这些点:
- 是否生成了用户级配置
- 是否识别到可用模型
- 是否能正常切换 agent
- 是否支持
ulw 这类快捷指令
4. 用一个小需求试车
不要一上来就说“给我重构整个订单模块”。先丢一个小需求,看看链路是否顺。
比如:
ulw 给我把这个项目里所有重复的日志打印统一成一个工具方法,并补一下说明。
如果它能:
那就说明这套组合已经活了。
你会真正用到的几个核心能力
1. 规划能力
复杂任务最怕什么?不是难,是乱。
OpenCode 的 Plan 模式配合 Oh My OpenCode,最大的价值就是先把任务拆开。它会把“一个大坑”拆成几个小坑:
- 先定位现有实现
- 再确认依赖关系
- 然后修改代码
- 最后跑验证
这个顺序很朴素,但特别稳。
2. 检索能力
Oh My OpenCode 很强调背景任务和检索。对于老项目,这玩意儿特别救命。
你经常会遇到这种场面:
“这个逻辑到底在哪?”
以前你得自己全仓库翻;现在可以让 agent 先帮你摸清楚脉络。
3. 审查能力
不是所有代码都适合直接改。有些场景你只是想先看方案。
这时候就切只读/规划思路,让它:
这比“先改再说”靠谱太多了。
一个真实一点的使用姿势
假设你要给 Spring Boot 项目加一个导出接口。
你可以这么干:
ulw 帮我实现一个用户导出接口,要求:
1. 保留现有权限校验
2. 导出字段和列表页一致
3. 支持 CSV
4. 补单元测试
5. 先告诉我你的实现计划,再开始改代码
这类提示词的关键,不是写得多,而是写得准。
你要把这些东西说清楚:
- 目标是什么
- 约束是什么
- 输出格式是什么
- 先做什么,后做什么
你给得越清楚,它越像个靠谱同事;你给得越模糊,它越像实习生。
进阶一点:怎么让它更听话
把规则写进 AGENTS.md
别把所有规矩都靠嘴说。
例如你可以写:
## 代码规范
- Controller 只做参数校验和调用 Service
- Service 负责业务逻辑
- Mapper 不写业务判断
- 所有新增接口必须补测试
- 涉及删除操作必须先确认影响范围
把常用命令写进去
## 常用命令
- 启动:mvn spring-boot:run
- 测试:mvn test
- 打包:mvn clean package
- 格式化:mvn spotless:apply
这样 AI 不会每次都问你“怎么跑测试”。它自己就知道流程。
把禁区写清楚
## 禁止事项
- 不要修改数据库表结构,除非明确要求
- 不要改线上配置
- 不要删除已有接口
- 不要随便引入新依赖
这类规则能救命,真的。
如果你是老项目,建议这样切入
老项目最大的问题,不是代码多,是规则烂、历史包袱重、大家都怕动。
这时正确姿势不是“全量重构”,而是:
- 先让 OpenCode 用
/init 看懂项目
- 再用 Oh My OpenCode 的规划能力摸清主流程
- 先改一条链路,别一次性碰太多模块
- 每次只提交一个小步子
这种方式慢吗?不慢。因为你少返工。
你可以把它当成什么
它不是 IDE 的替代品,也不是 ChatGPT 的替代品。
它更像一个:
- 终端里的项目助手
- 会自己拆任务的执行器
- 会查资料的协作者
- 会帮你收尾的工兵
如果说普通 AI 工具像“会聊天的搜索框”,那这套组合更像“能接活的开发小组”。
常见坑,别踩
1. 没有 AGENTS.md
AI 不是读心术选手。你不告诉它规范,它就只能猜。
2. 一上来就追求最复杂配置
别把自己先配死了。先能跑,再优化。
3. 让一个模型干所有活
这和让一个人既写需求、又写代码、又做验收没啥区别,最后大概率会乱。
4. 误以为插件能替代模型
Oh My OpenCode 不是模型本身,它是把 OpenCode 的调度能力做强。模型还是得选,API 还是得接。
最后说人话
如果你只是想要一个“能问问题的 AI 终端”,OpenCode 够了。
但如果你想要的是:
- 会规划
- 会分工
- 会查资料
- 会改代码
- 会自己把活干完
那 Oh My OpenCode 这类 harness 就很值得上。
它最大的价值不是“炫技”,而是把 AI 从“聊天工具”推进到“干活工具”。这一下,区别就很大了。
以前你是一个人盯着屏幕硬刚;现在你是一个人指挥一支 AI 小队。说夸张点,这就是程序员的生产力外挂。
真香。
如果你对这种终端里的 AI 协作模式感兴趣,不妨到云栈社区和更多折腾派一起聊聊。
参考资料
 发表于 2026-5-25 04:24:28
|
查看: 134|
回复: 0
发表于 2026-5-25 04:24:28
|
查看: 134|
回复: 0
