最近,Harness Engineering 这个词开始被越来越多人频繁提及。特别是做 Agent、AI 编程、自动化工作流的同学,应该会经常刷到。
OpenAI 在 2026 年 4 月 15 日那篇 Agents SDK 更新里,直接提到了 model-native harness。

LangChain 这边也一直在讲 Context Engineering。

Anthropic 那篇 Building effective agents 又把 workflow 和 agent 的边界讲得很清楚。
于是很多同学就懵了。Prompt Engineering 还没完全搞明白,Context Engineering 刚听说,怎么又冒出来一个 Harness Engineering?
这种感觉其实很普遍。AI 这两年的概念就跟雨后春笋似的:今天是 Agent,明天是 MCP,后天是 Context Engineering,过两天又是一个 Harness Engineering。如果你只想安安静静用 AI 干点活,看到这些词的第一反应大概率是头疼。
但是,跟不少同学深入聊过之后,反而觉得 Harness Engineering 这个词值得专门拆解一下。一来,最近真有同学在连续两个面试中被问到了:
二来,当初既然承诺了要整理一篇内容出来,那就不能再拖了。
Harness Engineering 的背后,其实暗含着一个非常重要的变化:AI 正在从聊天窗口,走向真实工作流。
以前我们最关心的是怎么让模型回答得更好(Prompt Engineering);后来开始关心怎么让它看到正确的信息(Context Engineering);现在我们终于开始关心,怎么让模型在一套可控的系统里稳定地干活——这就是 Harness Engineering。
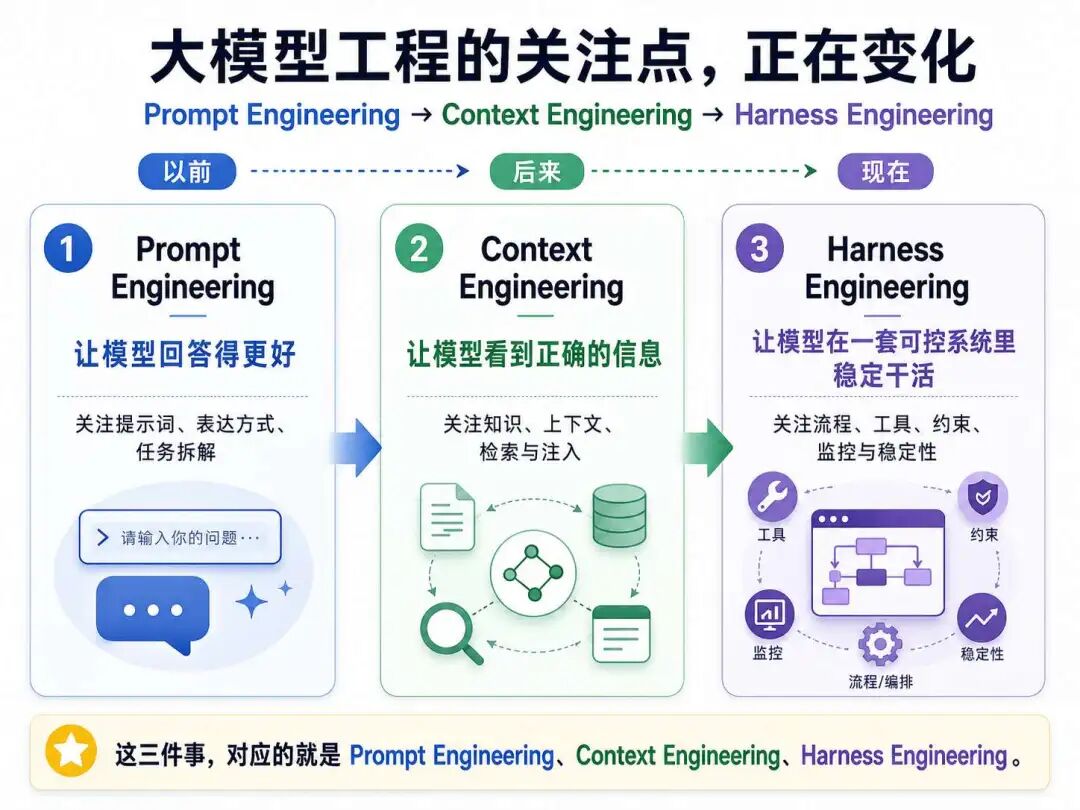
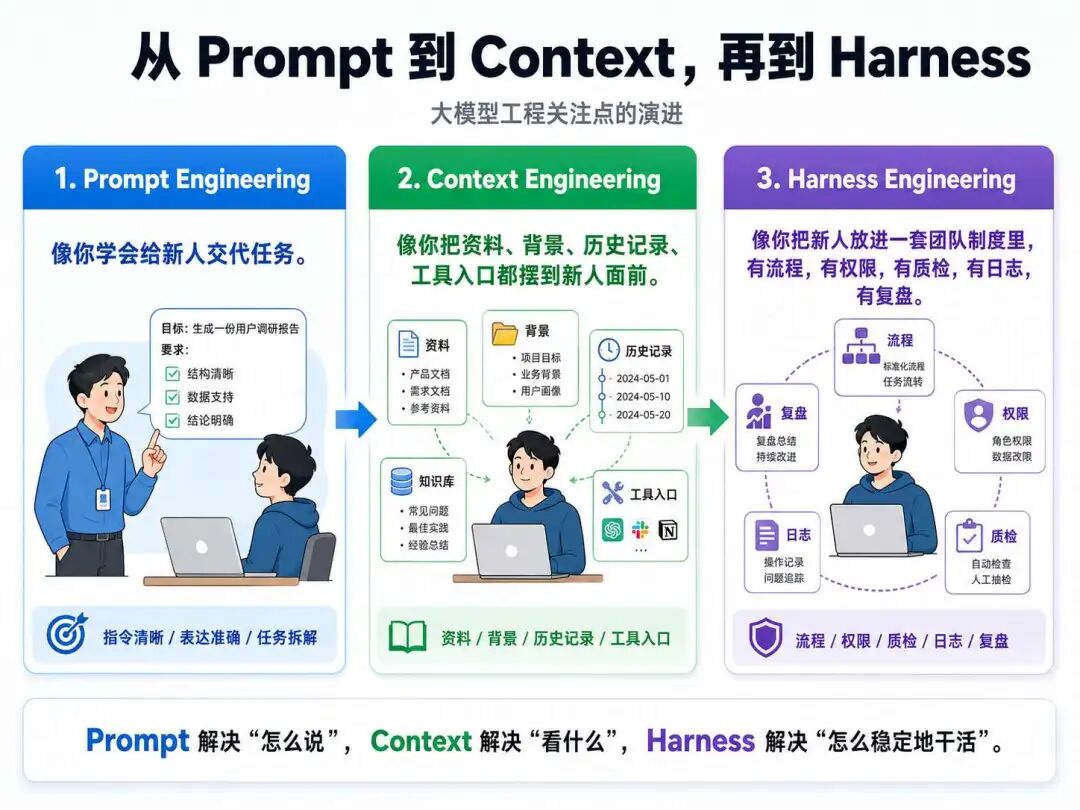
这三个 Engineering 是循序渐进的,是逐步发展过来的。大家可以记住下面这张关系图:
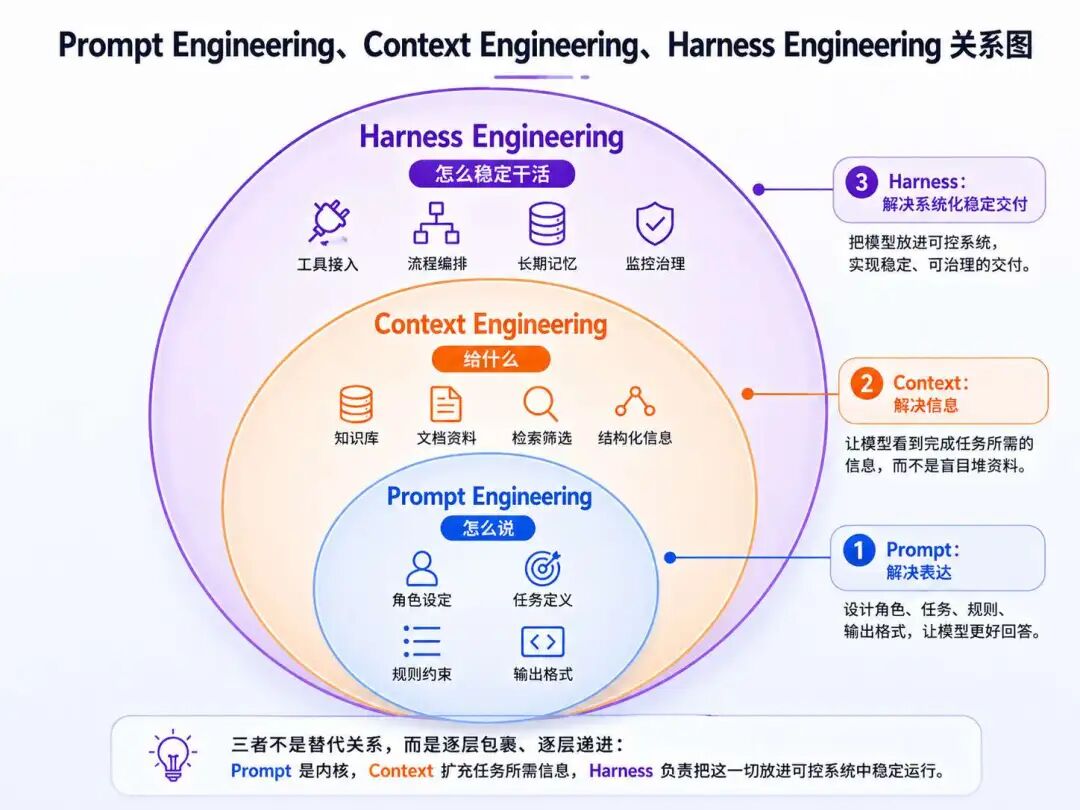
用个特别土的比喻来说明这三层:
- Prompt Engineering:你学会给一个新人交代任务。你不能只说“帮我弄一下这个”,然后期待他自动理解你的标准。你得告诉他这件事给谁看、目标是什么、做到什么程度、输出什么格式、哪些坑不能踩。说到底,它解决的是“任务交代不清”的问题。
- Context Engineering:你不光交代任务,还把新人干活需要的资料都放到了他面前。之前的方案、客户背景、历史聊天记录、业务规则、数据口径、可用工具……哪些是必看的,哪些是不能看的,你都帮他整理好。否则他再聪明也只能靠猜。它解决的是“新人不了解现场”的问题。
- Harness Engineering:你终于不再把这个新人当成一个临时工了,而是把他放进了一套真正的团队工作制度里。他能接什么任务、看哪些资料、调用哪些工具、什么动作需要审批、做完以后谁来验收、出了错怎么回滚、过程怎么留日志、下次怎么复盘……这些全都要提前设计好。它解决的是“聪明人进入生产系统后,怎么被管理、被约束、被验证”的问题。
同样,一图胜千言:
所以今天这篇内容,我们就从 Prompt Engineering 开始,一层一层讲到 Context Engineering,再讲到 Harness Engineering。重点不在于记住三个英文词,而是搞明白,AI 应用到底是怎么一步步工程化的。
Prompt Engineering
Prompt Engineering 最早火起来,其实特别合理。大模型刚进入大众视野时,大家面对的是一个很新的东西。它不像搜索引擎,丢几个关键词进去翻链接就行。它更像一个特别聪明但不了解你的人——你怎么说,它就怎么理解;你说得含糊,它就只能靠猜。
很多人第一次用 ChatGPT 时,最常见的提问就是“帮我写个方案”“帮我总结一下”“帮我优化这段话”。模型当然会写,而且往往写得还挺像回事。问题是,打开一看,全是正确的废话。这东西最烦人的地方就在这里:它不是明显错,而是看起来很完整、很礼貌、很像专业人士写的,但你就是用不上。
这时候,Prompt Engineering 出现了。它解决的第一个问题就是:别让模型猜。你得把任务、角色、格式、约束、示例和判断标准尽量讲清楚。
比如,你让模型总结会议记录。差一点的 Prompt 可能是:
帮我总结这段会议记录。
而好一点的 Prompt 会变成这样:
请把下面这段会议记录整理成给 CEO 看的 5 条结论。
每条结论包含事实,判断,下一步动作。
不要编不存在的数据。
如果会议记录里没有依据,就写待确认。
语气直接一点,不要写成新闻稿。
你看,关键点很简单:把话说得更清楚一点。就这么简单。
但就是这么一个简单的事情,依然有很多坑。我自己早期也踩过,曾经迷恋过各种 Prompt 模板,总觉得是不是多加一句“你是顶级专家”,模型就会突然开窍。后来才发现,真正有用的部分往往不是“顶级专家”这四个字,而是你有没有给清楚任务边界。这个边界包含:做什么、给谁看、基于什么材料、输出成什么样、什么不能做、什么结果算不合格。
给大家一个很落地的实践方法:你每次问模型之前,先写五行。

- 第一行,模型现在扮演什么角色
- 第二行,它要完成什么任务
- 第三行,它能使用哪些材料
- 第四行,它要按什么格式输出
- 第五行,哪些情况算失败
这五行写完,很多单次任务的质量会立刻变好。这就是 Prompt Engineering 的作用:它让模型从随便发挥,变成按你的要求发挥。
但是! Prompt Engineering 很快会遇到一个瓶颈:再好的 Prompt,也救不了缺材料的任务。
比如,你让模型判断一个客户会不会续费。你把 Prompt 写得再漂亮——“你是顶级 SaaS 客户成功专家,请从商业价值、使用深度、组织关系、风险信号四个维度判断客户续费概率”——听起来很专业。但如果模型不知道合同金额、不知道客户最近登录次数、不知道工单历史、不知道对接人有没有离职、不知道上次 QBR 发生了什么,它能怎么办?它只能编一个很像样的判断。这就危险了。
Prompt Engineering 解决的是“你怎么说”,但真实工作中,很多问题的症结不在于表达,而在于信息的缺失。于是我们走到了第二层。
Context Engineering
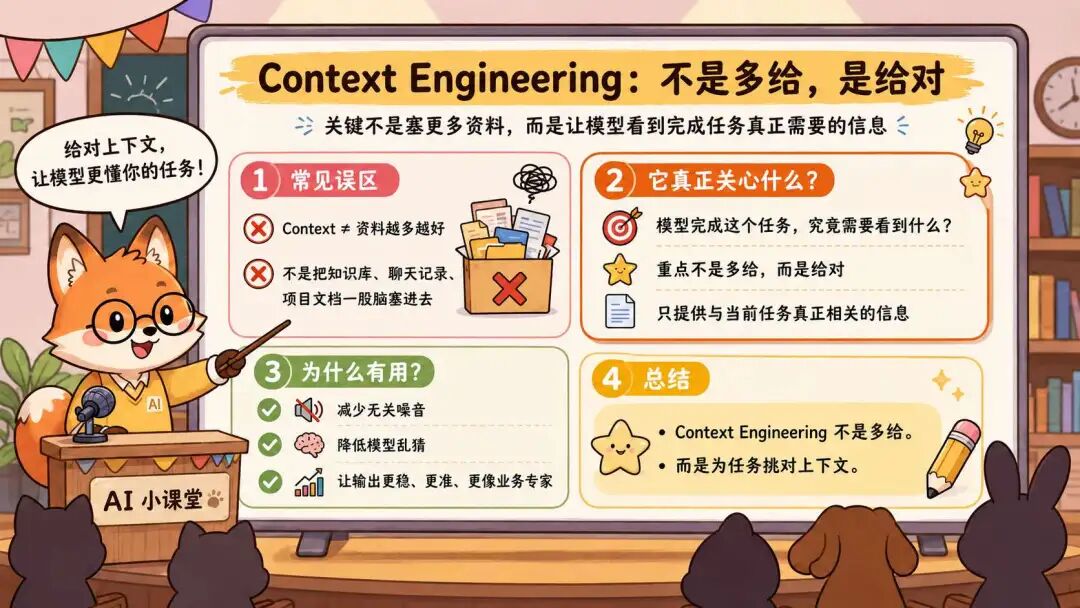
Context Engineering 这词最近也很火,但我总觉得它被讲得太玄了。很多人一听 Context,就以为是把更多资料塞给模型,比如知识库、聊天记录、项目文档,然后期待模型突然变成全知全能的业务专家。不是这样的。
Context Engineering 不是多给,是给对。它真正关心的是,模型完成这个任务,到底需要看到什么。不是你有什么就给什么,而是它需要什么,你才给什么。
LangChain 的 Harrison Chase 讲 Context Engineering 时有个观点我挺认同,大概意思是:给模型提供正确的信息、工具和格式,让它能完成任务。 这在 云栈社区 的技术文档板块有很多相关案例可以参考。

这比单纯堆 tokens 要准确得多。拿客服退款这个场景举例。用户问:“我这个订单能不能退?”
如果你只有 Prompt,可能会写:“你是一个专业客服,请友好、准确地回答用户关于退款的问题。”听起来没毛病。但模型不知道订单状态、商品类目、签收时间、用户有没有拆封、平台政策、用户之前有没有恶意退款记录……所以它只能说:“很抱歉给您带来不便,建议您查看退款规则或联系人工客服。”礼貌是挺礼貌的,但没什么用。
而 Context Engineering 会怎么做?它会精心组织这次回答需要的上下文,可能包括:用户订单号、商品类目、签收时间、是否支持七天无理由、当前退款政策、用户历史沟通记录、订单状态、可调用的查询与退款申请工具,还有一条重要的业务约束——如果政策冲突,以当前平台规则为准;如果信息缺失,必须追问,不能直接承诺。
当这些信息被准确注入后,模型的回答就会产生质变。这就是 Context Engineering 的价值——它解决的是模型看不见世界的问题。
- Prompt Engineering 让模型更理解你的话。
- Context Engineering 让模型更理解当前局面。
这里给大家一个好操作的练习方式:给任何一个 AI 任务做一张「上下文清单」(context map)。在任务开始前,把模型需要的信息分门别类列出来,明确它应该看到什么、不应该看到什么。这张清单可以分成五类:
- 用户这次输入了什么:刚刚问的问题、上传的文件、提出的限制。
- 系统已经知道什么:用户资料、历史订单、过往对话、项目文档、业务配置。
- 需要临时检索什么:最新政策、实时库存、数据库查询结果、相关代码文件。
- 工具调用会返回什么:订单状态、API 结果、报错日志,这些结果会成为下一步的新上下文。
- 哪些信息不能给模型:其他用户的数据、生产密钥、无关历史、过期政策。
前四类是为了避免模型“看不够”,第五类是为了避免模型“看太多、看错,甚至看到不该看的”。Context Engineering 真正要解决的,就是这个筛选问题。大家常说的 RAG 就是一个非常典型的 Context Engineering 实践。
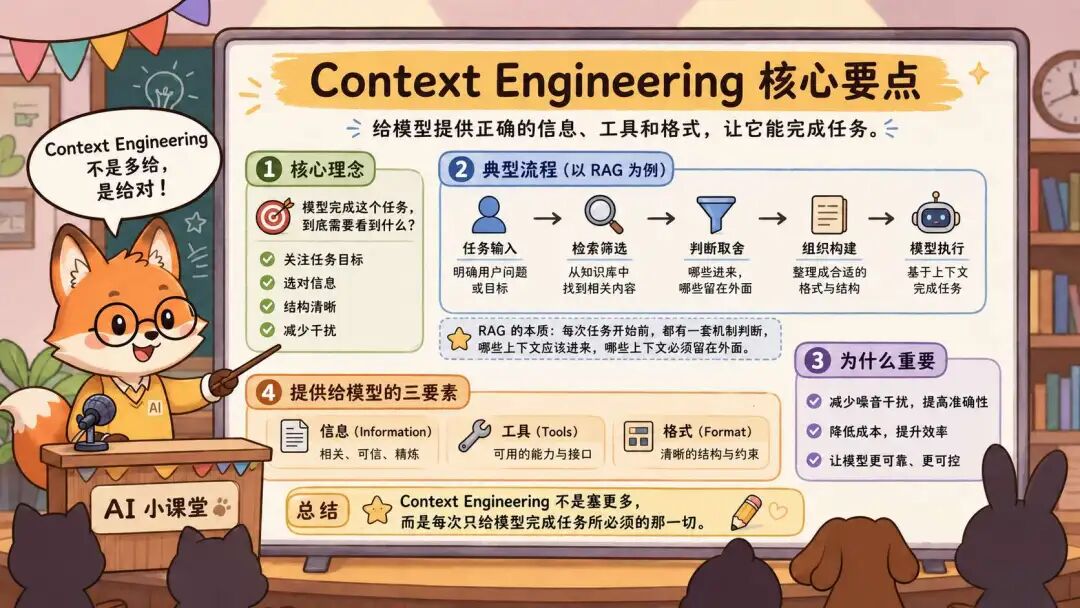
所以 Context Engineering 不只是检索,它还包括筛选、压缩、排序、隔离、权限控制、冲突处理。它开始有一些工程味了。但是,它仍然会遇到一个问题:它主要解决的是模型“看什么”,而没完整解决“怎么做”。
“看”和“做”之间,差得很远。一个模型知道退款政策,不代表它应该直接发起退款;一个模型读懂代码库,不代表它可以随便改文件;一个模型看完了公司内部数据,不代表它可以自动把报告发给客户。到了这一步,我们就不能只讨论输入了,我们要讨论执行。这就是 Harness Engineering 进场的地方。
Harness Engineering
Harness 这个词直译有点别扭,有马具、束带的意思。

放在 AI 里,我更愿意把它理解成一套让模型安全干活的工程“支架”。这套支架决定了模型能接什么任务、看什么上下文、调用什么工具、改什么东西、什么时候必须停下来、输出后怎么验、出错后怎么追踪。
说到底,Harness Engineering 关心的不是让模型单次回答更漂亮,而是让模型在真实工作流里可控、可验、可复盘地完成任务。这就是它和前两层最大的区别:
- Prompt Engineering 的对象,是一句请求。
- Context Engineering 的对象,是一次任务所需的信息环境。
- Harness Engineering 的对象,是一整条执行链路。
在这条链路里,模型只是其中一个环节。甚至很多时候,模型不是最重要的环节。工具权限、状态管理、检查器、人工闸门、日志追踪,可能比模型那一句回答更重要。
听起来有点抽象,我用大白话拆解一下:如果你要做一个能帮你处理退款的 AI 系统,Harness 里至少要有这些东西:
- 任务路由:先判断用户是咨询、退款还是投诉。
- 上下文组装:明确这次该查订单、政策还是历史沟通,而不是把所有资料都塞进去。
- 工具白名单:只能调用查询、退款申请等指定工具,不能随便改用户账户。
- 权限边界:低金额可自动处理,高金额必须人工确认。
- 执行状态:知道当前进行到哪一步了。
- 输出检查:确认回复里没有承诺违规、没有泄露内部规则、不以推测充当事实。
- 失败处理:工具超时是否重试,信息缺失是否追问,冲突是否升级人工。
- 日志追踪:模型看了什么、调用了什么、为什么做这个判断,都要能回溯。
- 评测集:每次改 Prompt、换模型、调检索策略,都要用固定案例跑一遍,看系统有没有退步。
你看,这已经不是聊天了,这是系统工程。一个模型能不能说出一段漂亮话,和它能不能进入真实业务系统,中间隔着一条很宽的河。Harness Engineering 就是在架这座桥。

它默认模型会犯错,所以提前设计犯错了怎么办;它默认工具会失败,所以提前设计重试、降级、人工接管。这才是 Harness Engineering 最核心的东西——让 AI 更像一个可以被管理的工作单元。
这也很容易跟 Agent 搞混。可以用一个不太严谨但好理解的公式来说明:
harness ≈ agent - model(大模型)
换句话说,harness + model(大模型)≈ agent。先把 Agent 里的模型能力拿掉,剩下那些让它能真正干活的工程结构,大概就是 Harness 要关心的东西。在 云栈社区 关于 AI 的讨论中,Agent 的落地一直是个热门话题。
没有 Harness 的 Agent,就像一个很聪明但没人管的实习生。它可能真能干活,但它看了什么、为什么这么做、有没有越权、结果有没有被验过——你一概不知。
具体来说,一个最小可用的 Harness,至少要有七个部分:
- 输入约定:系统先把用户混乱的自然语言,整理成结构化的任务。
- 上下文组装:决定模型这次应该看什么。
- 工具层:模型必须通过明确的工具操作世界,Harness 要规定权限、超时、是否需要确认。
- 执行控制器:决定任务是直接执行还是先计划,是否并行,失败后如何重试、何时停止或交给人。
- 检查器:对输出进行格式、数据源、政策合规等检查,确保不越权、不瞎编。
- 人工闸门:高金额、发邮件、删数据等高危操作,必须让人确认。
- 日志和评测:日志用于复盘,评测用于监控系统是否退步。每次改动都要用固定案例评估成功率和错误类型。
这才叫工程。很多人对 AI 工程化的理解,还停留在做一个漂亮的 Demo 上,但 Demo 和生产之间隔着可观测性、可控性、可恢复性。你能看到它做了什么吗?你能限制它不能做什么吗?它做错了你能恢复吗?这三个问题答不上来,系统就还没准备好。
Harness Engineering 火起来是很正常的。因为模型能力真的到了这一步——它不再只负责生成文本,它开始读文件、写代码、查数据库、调 API、发消息、跑命令。能力越强,边界就越重要。
同一个任务,Prompt、Context、Harness 的差别到底有多大
光讲概念可能还是有点飘。我们拿一个具体任务对比一下:假设你要让 AI 帮你写一份新能源汽车出海报告。这是一个很典型的知识工作场景,它需要资料、判断、结构和质量控制。
Prompt Engineering 版本
你会写一个相对完整的 Prompt:
请写一份新能源汽车出海报告。
读者是公司战略团队。
报告需要包含市场规模、主要区域、竞争格局、政策风险、渠道策略和结论建议。
语气专业但不要空泛。
输出 3000 字左右。
结论要具体,不要只写趋势向好。
这个版本比一句“帮我写报告”强很多,模型大概率能写出一份像样的报告。但问题也很明显:数据从哪来?区域判断准不准?政策有没有过期?你都不知道。它解决了表达问题,但不保证报告的可靠性。
Context Engineering 版本
你不光写 Prompt,还把材料给模型:公司过去的报告、公开市场数据、各区域政策资料、竞品价格页、内部销售反馈。你还会告诉模型,优先用 2025 年以后的资料,内部材料要匿名,数据冲突要标注。
此时报告质量会明显上去,因为模型终于有材料了,它不再只靠语言惯性写废话。但问题依然存在:如果材料有过期数据,它能识别吗?两个来源冲突,它按哪个?关键结论没来源,它会自己补吗?你下周更新了资料,报告质量退步了怎么办?这些问题,Context 本身回答不了,它只解决“看什么”,还没解决“怎么生产、怎么验收、怎么追责”。
Harness Engineering 版本
Harness 版本不会让模型直接写报告,而是先搭一条“最小生产线”。你可以先手工跑一遍,一个最小可用的 Harness 可以从 5 个东西开始:
- 任务卡:在动手前,把任务写成固定格式。
任务类型,行业研究报告
报告主题,新能源汽车出海
读者,公司战略团队
报告用途,辅助判断 2026 年重点区域
必须回答,市场规模、区域机会、竞品、政策风险、渠道建议
禁止内容,没有来源的数据,编造案例,暴露内部客户名称
风险等级,中
- 研究计划:不让模型上来就写正文,而是先生成研究计划。比如回答“市场规模怎么评估”“区域怎么划分”“政策风险看哪些维度”等。这一步的核心,是先让模型暴露思路,计划不对你还能改。
- 资料表:把所有资料整理成一张表,字段包括:资料名称、来源、发布时间、可信度、适合回答哪个问题、能否引用、是否含敏感信息。这不是把资料一股脑塞进去,而是先标记清楚哪些能用、哪些慎用。
- 上下文包:每次写某一段,只给它需要的材料。写欧洲市场就只给欧洲相关材料,并附上约束。
只能基于下面资料写
每个关键判断必须带来源
没有来源就写待确认
内部客户名称必须匿名
发现资料冲突时不要强行判断,列出冲突
- 检查清单:初稿出来,用固定清单检查。
有没有无来源数据
有没有过期资料
有没有编造案例
有没有暴露客户名称
有没有把推测写成事实
有没有缺少关键章节
结论有没有对应证据
检查不过就退回去改。如果是资料冲突,直接标记出来交给人选口径。这就是人工闸门。
你看,实操上并不神秘。第一版 Harness 甚至可以不用写代码:一个任务卡、一个研究计划、一张资料表、一个上下文包、一张检查清单,再加一个日志,记录用了哪些资料、改了几轮、哪里被人工确认了。这就已经是一个很小但能跑的 Harness 了。等这套手工流程跑顺了,再慢慢自动化。
而且你会发现,Harness 并没有抛弃 Prompt 和 Context。恰恰相反,它里面仍然有生成计划、写初稿、做检查的各种 Prompt,也仍然有资料检索、上下文组装和历史报告等 Context 工作。它不是替代前两者,而是把前两者放进一个更大的执行系统里。就像文章开头那张图一样:
总结
AI 以前像聊天对象,后来像助手,再往后会变成组织里的一个执行单元。而执行单元不能只靠聪明,它需要位置、权限、流程、考核和边界。人类公司就是这么运转的,AI 系统也会慢慢走向这里。
 发表于 2026-5-25 04:40:53
|
查看: 90|
回复: 0
发表于 2026-5-25 04:40:53
|
查看: 90|
回复: 0
