好不容易得到样本,上来一看:
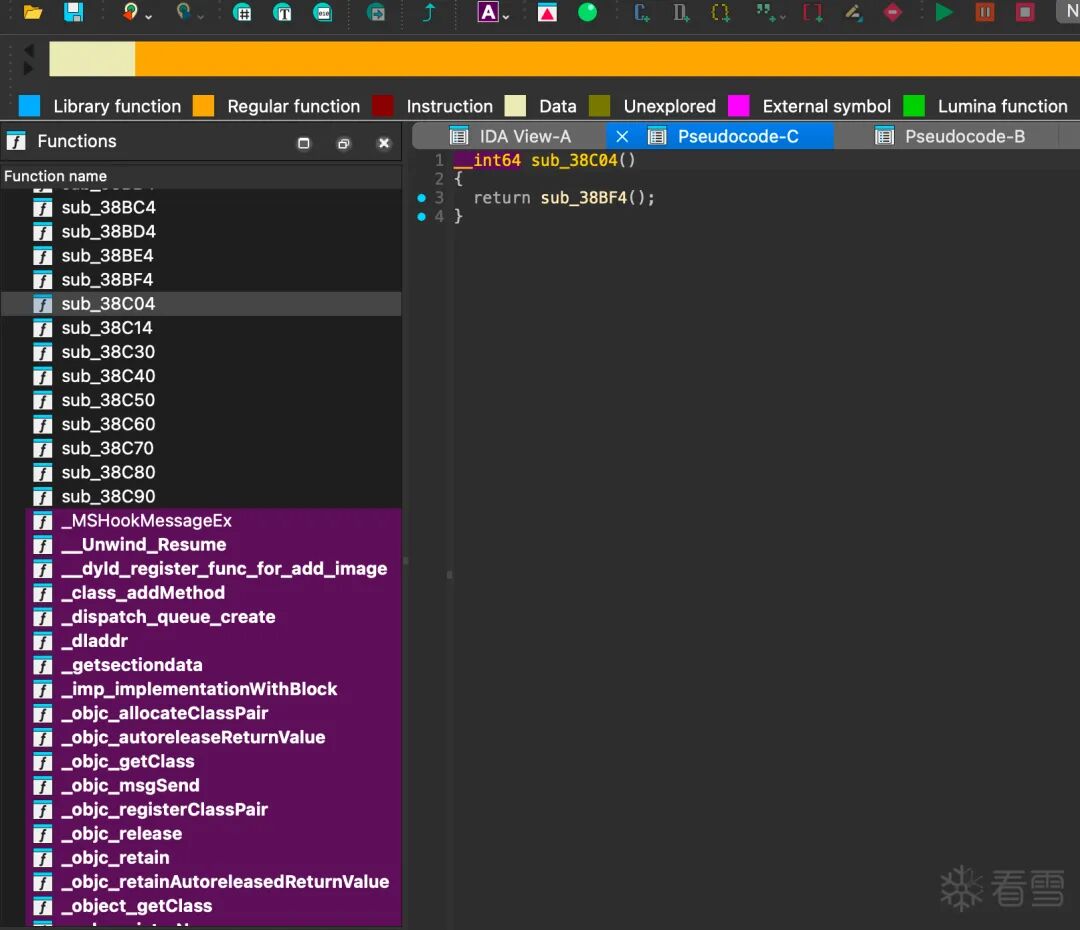
看着就像 ollvm,全是些 sub 函数,逻辑肯定都藏在里面了。我暗自希望这是个 ollvm 标准版,于是打开插件准备一把梭哈。
没用,说明是标准 ollvm 的变体。服了,直接开始硬啃吧。
1. 第一锤子:确认是 OLLVM CFF
我对比了两个普通函数的开头,sub_49C4 和 sub_87B0:
; sub_49C4 开头 ; sub_87B0 开头
CMP W8, W25 MOV W9, #0xB1EA1D76
CSET W9, LT CMP W8, W9
STR W9, [SP,#arg_CDC] CSET W9, LT
LDR X10, [X20,#0xC50] STR W9, [SP,#arg_88C]
LDR X9, [X10,W9,UXTW#3] LDR X10, [X20,#0x800]
BR X9 LDR X9, [X10,W9,UXTW#3]
BR X9
这个模板太眼熟了——OLLVM Control-Flow Flattening 的标志五件套:
CMP W8, <state_const>:比当前 state 与魔数CSET Wx, LT:把比较结果布尔化STR Wx, [SP, #...]:暂存到栈,加数据流复杂度LDR X10, [X20, #table_off]:取分发表基址LDR X9, [X10, Wx, UXTW#3]:索引乘 8 取目标BR X9:间接跳转,丢失静态分析目标
字节级完全一致。除了 cmp 常量(W25 vs #0xB1EA1D76)和 X20 偏移不同,指令序列、寄存器编号、移位形式一模一样。这种“骨架相同、只换立即数”的模板化代码,只可能出自混淆编译器。可以肯定用了 obfuscator-llvm 或它的衍生版(Hikari、Pluto-LLVM、Snake-LLVM 这些)。
BR X9 这行的杀伤力值得多看一眼。BR 是 ARM64 的间接跳转,目标地址在寄存器里,IDA 的递归下降反汇编无法静态确定它跳到哪。每碰到一个 BR Xn,IDA 默认就把这当成函数边界——因为再往下的字节它无法保证是不是新函数的开头。这就是这个 dylib 出现 1492 个 sub_XXXX 的原因:作者把所有原本的条件分支全部翻译成 BR,IDA 看到一片 BR 就在每处砍一刀,把一个完整的大函数切成上千段。这是 OLLVM CFF 的副作用,但作者很可能就是冲着这个来的。
入口函数里出现的三个立即数:
W22 = 0xFD6886DF # 4019357919
W28 = 0xD8128E13 # 3625422867
W25 = 0x3664924A # 912495690
我当时第一反应是字符串解密密钥,准备拿去试 XOR。32 位整数,出现在入口函数,看起来像 key——好像未知魔数。我甚至写了一段 Python:把 __data 段密文按 4 字节切片,跟这三个值挨个 XOR,看输出里有没有可见 ASCII 模式。结果当然是没有。
后来才明白这就是 OLLVM CFF 的 dispatcher state 初值,每个函数有独立的随机 state。在平坦化的 while-switch 结构里,这些值只是 case 的索引常量,没有任何密码学意义。看到入口函数装载几个高熵 32 位常量,先不要假定是密钥,先看它们在后续指令里怎么被消费——如果是 CMP W8, Wxxx 这种直接比较,99% 是 dispatcher state;如果是 EOR W?, W?, Wxxx、UMULL、MADD 这种算术参与,才有可能是 key。
接着发现 sub_4000(入口)和 sub_32F14(普通函数)都引用了同一张分发表 off_42DA0。这个细节在当时不起眼,后面证明是关键——朴素 CFF 是每函数独立 dispatch table(每个函数有自己专属的 state→target 大表),这里是全局共享 dispatch table,意味着不能简单用 IDA 脚本对单函数解 CFF,必须全局重建 dispatch graph。这种共享方案的好处是省体积:朴素 CFF 会让 .text 和 .const 急剧膨胀,共享 table 让所有函数共用一张大表,自己只取一段。坏处是反混淆的工程量提高,但这正是混淆器作者乐见的。
2. 迷局一:1492 个函数到底是什么
CFF 看清楚之后,我准备开干——先把 dispatch table 解出来,然后逐函数还原 CFG。
但搞到一半就感觉不对。问题出在数量上:1492 个函数,如果每个都是独立的 OLLVM CFF 函数,那 trampoline 数量应该跟函数数差不多。我数了一下,典型 trampoline 模板的实例只有两百多个。剩下 1200 多个“函数”是什么?
带着这个疑惑我又看了一眼 __cstring,84 字节;再看 __data 加密区,0x40328 字节。如果 1492 个函数大部分是真业务函数,那 __cstring 应该有几百到几千字节的明文残留(C 字符串字面量、调试串、__FUNCTION__ 这些总会漏一些),不可能压到 84 字节;反过来,如果 1492 个全是 trampoline,加密区也用不上 263 KB。这两个数字加起来给我的感觉是:真正的业务代码体量根本没到 1492 个函数,我对“函数”的计量方式是错的。
那能不能先反编译一个看起来普通的函数,看它到底长什么样?我挑了 sub_8794,因为它在数据交叉引用里出现频率特别高。在大量同质化的混淆函数里,挑高频节点反编译是一个被严重低估的姿势——任何一个被反编译干净的样本都会暴露整套混淆协议,因为协议必须自洽,一个样本就是一个完整切片。
sub_8794 反编译出来非常短,前几条指令长这样:
LDAR WZR, [X0] # atomic load,丢值,纯内存屏障
ADRP X8, dword_41DCC@PAGE
LDR W8, [X8,#dword_41DCC@PAGEOFF]
ADRP X9, dword_41DD0@PAGE
LDR W9, [X9,#dword_41DD0@PAGEOFF]
ORR W8, W8, W9
MOV W9, #0xA96EA1AD
ORR W8, W8, W9
SUB W8, W8, W10 # W10 是上层留下的!
;; ... 一堆 MBA 计算 ...
LDR W8, [X29,#-0xDC] # 这一行让我愣住了
LDR W8, [X29, #-0xDC]——从栈上读 W8。
我之前一直以为 W8 是 dispatcher 的 state 寄存器,顺着指令流传递。但这里赤裸裸地从栈帧读,意味着:W8 的值不在寄存器里持续传递,而是每次进 trampoline 都从栈上读、算完再存回栈。
这件事的后劲挺大。它解释了之前的困惑:在 lldb 或者 IDA 调试视图里盯 W8,你永远看到它“不停被覆盖、没有规律”,因为 W8 在跨 trampoline 的层面根本不是状态,只是临时 cache。真正的状态藏在栈上的某个固定 offset(这里是 [X29-0xDC])。OLLVM 这一手把“状态”从寄存器移到栈,对人工逆向是降维打击——大多数逆向者下意识把寄存器当 first-class、把栈当 second-class,跟踪状态时盯的是寄存器视图,根本不会去看栈帧的某个固定 offset。
更狠的是,sub_8794 没有自己的 prologue。它没有 STP X29, X30, [SP, #-0x10]! 这种栈帧建立。也就是说,sub_8794 不是个真正意义上的“函数”,它是某个母函数(就是 sub_4000)栈帧上的一段代码,通过尾调用链一路 BR 跳过来的。函数体里的 X29 不是它自己建立的,是从调用方继承来的;它读 [X29-0xDC] 实际上读的是调用方栈帧上的某个位置——这个位置由调用方的调用方填充,可能再往上一层才是真正的源头。
顺手把它 ORR 进来的两个全局 dword_41DCC 和 dword_41DD0 也查一下,加上它前面的 LDAR WZR, [X0] 用到的 atomic flag 地址,跑一遍 globals_probe.json 落盘:
[
{"name": "dword_41DC4", "addr": "0x41DC4", "segment": "__data",
"init_value": "0xBE732599", "description": "MBA seed key"},
{"name": "dword_41DC8", "addr": "0x41DC8", "segment": "__data",
"init_value": "0x43FFD974", "description": "MBA seed key"},
{"name": "dword_41DCC", "addr": "0x41DCC", "segment": "__data",
"init_value": "0x2338FB04", "description": "MBA seed key"},
{"name": "dword_41DD0", "addr": "0x41DD0", "segment": "__data",
"init_value": "0xF690C74D", "description": "MBA seed key"},
{"name": "dword_41DD4", "addr": "0x41DD4", "segment": "__data",
"init_value": "0x8B27A32A", "description": "MBA seed key"},
{"name": "dword_41DD8", "addr": "0x41DD8", "segment": "__data",
"init_value": "0x5AE39E39", "description": "MBA seed key"},
{"name": "dword_4AF68", "addr": "0x4AF68", "segment": "__bss",
"init_value": "0xFFFFFFFF", "description": "BSS atomic flag (LDAR/STLR pair)"},
{"name": "dword_4AF80", "addr": "0x4AF80", "segment": "__bss",
"init_value": "0xFFFFFFFF", "description": "BSS atomic flag"},
{"name": "dword_4AF84", "addr": "0x4AF84", "segment": "__bss",
"init_value": "0xFFFFFFFF", "description": "BSS atomic flag"}
]
6 个 MBA seed key 都在 __data,初值是高熵 32 位常量;3 个 atomic flag 都在 __bss,初值统一是 0xFFFFFFFF。关键洞察:这些 dword_41DCx 不是状态字,是只读的 MBA 种子常量。每个 trampoline 在 MBA 计算里取不同的种子组合(像 sub_8794 取 41DCC + 41DD0)+ 一个魔数偏移(0xA96EA1AD)+ 一个上游传入的 W10 → 算出本节点的判断函数。整套 BDD 的“信息载体”实际上不在内存里,而在控制流的累积路径上——每条不同的执行路径选择不同的种子组合,产生不同的最终行为。这是 BDD 对“分支信息”做的反直觉编码:信息不存在节点里,信息存在路径里。
这一刻整个理解全翻了。
之前的模型:1492 个独立函数,每个函数都做 OLLVM CFF。
修正后的模型:整个 dylib 实质上是一个超级函数。sub_4000 是入口,负责建立栈帧、写入分发表、初始化 state。然后通过尾调用链(BR Xn)跳到一系列 trampoline,每个 trampoline 从 [X29-0xDC] 读 state,跟一个魔数比较,根据结果索引分发表跳到下一个 trampoline。1492 个“函数”实际是一个尾调用链上的 1492 个基本块,IDA 因为它们都是 BR Xn 跳进来的,误以为是函数。
你可以把这个东西理解成 OLLVM 把一个普通的 while-switch 状态机,整个翻译成了基于尾调用的递归形式,而且把状态字段从寄存器降级到栈槽。这样静态分析就废了——你看任何一个 trampoline,都不知道它的 W8 是从哪里来的、要去哪里,因为 W8 从栈读出来,而栈在调用方写入。再加上 CSET LT 永远只产 0 或 1 这一个事实,每个 trampoline 实际只编码 1 比特决策(< 取 1,≥ 取 0),根本不是经典 OLLVM CFF 的 N 路 switch。1492 个 trampoline 串起来不是一棵 N 叉决策树,而是一棵二叉决策图(BDD)。
这个观察直接改变了反混淆代价的量级。经典 CFF 反混淆需要对每个 case 做符号执行求 state 关系,O(N²) 复杂度,1492 个节点意味着数小时到数天的求解器跑;binary-fork 这种结构每个节点只藏 1 比特,直接读两个指针就能拿到分支去向,O(N) 就能推完。整个混淆体系的工作量从“两到五人周”降到“两到五人天”。混淆器作者很可能是想用函数数量把对手吓退(看到 1492 个 sub_XXXX 大多数人就放弃了),但忽略了单点信息量——一旦识破“每个 trampoline 只藏 1 比特”这件事,整体就崩了。
确认这个之后,反混淆策略整个推翻重写。我开始写一系列分析脚本,从 cff_step1_x20map.py 一直干到 cff_step19_parse_decomp_to_schedule.py,一步步把这棵尾调用链解构。脚本一共写了 19 个,加起来三千行左右。
3. 迷局二:xrefs_to(_MSHookMessageEx) 一个调用者都找不到
跟 CFF 的迷局并行的是 hook 注册表的迷局。
我习惯找 hook 注册函数的方式是:xrefs_to(_MSHookMessageEx) 看谁调它。逆向 iOS tweak 这是第一招,稳得不能再稳——MSHookMessageEx 是 MobileSubstrate 的入口 API,任何 tweak 想 hook ObjC 方法都得调它,谁调它谁就是 hook 注册函数,顺藤摸瓜整个 hook 列表都能挖出来。
这个 dylib 里这一招直接失败——xref 表显示只有几个 thunk 调它,真正的 hook 注册函数一个都看不见。
在 ida-pro-mcp 里跑:
xrefs = mcp__ida-pro-mcp__xrefs_to(MSHookMessageEx_addr)
# 返回 19 个 site,全是 4 指令 thunk 包装
19 个 thunk,每个 thunk 长这样:
ADRP X16, _MSHookMessageEx@GOTPAGE
LDR X16, [X16, _MSHookMessageEx@GOTPAGEOFF]
BR X16
继续追这 19 个 thunk 的 xref——还是找不到真正的调用方。因为调用方是通过函数指针表(BDD 节点出口)跳进来的,不是直接 BL,所以 IDA 的 xref 网络在这一层就断了。
这是混淆的另一层手段:间接化所有调用关系。原本 BL _MSHookMessageEx 一行能搞定,被改成 LDR X8, [X20, #off]; BR X8,IDA 只能告诉你 BR X8 跳了出去,跳到哪里它不知道。X8 在更早的某条 LDR X8, [X20, #imm] 设置,X20 是栈基址,栈基址上面装的是另一个表,这个表的内容由 sub_4000 prologue 在运行时填充——静态分析不跑 prologue 就拿不到这些数据,IDA 默认不模拟运行,所以一片漆黑。
更阴险的是,这个 dylib 还做了一层反静态:把 MSHookMessageEx 的调用包成 19 个不同地址的 4 指令 thunk(sub_3835C / sub_3839C / sub_383DC ……),每个 hook 注册函数随机用其中一个 thunk。这就让你哪怕用脚本扫“有谁直接 BL 到 _MSHookMessageEx”也只能找到 thunk 自己,而不是真正的注册函数。
我后来用了非常笨但有效的办法:直接在二进制里搜索 thunk 地址被 LDR 引用的地方。
# 找所有 19 个 _MSHookMessageEx thunk 的地址
thunk_addrs = [...] # 19 个
# 在 __const / __data 段全段扫描:
for offset in range(0x40000, 0x4B000, 8):
val = mcp__ida-pro-mcp__get_u64(offset)
if val in thunk_addrs:
# 这个 8 字节槽里存了 thunk 地址,某个 BR Xn 会跳过来
print(hex(offset), hex(val))
这种“在数据段里 grep 函数指针”的做法听起来粗暴,但它绕开了所有混淆层——你不需要懂 BDD,不需要解 OLLVM CFF,只要相信“thunk 地址必须出现在某个 8 字节槽里才能被间接调用”这个简单事实。所有间接调用最终都要把目标地址装进某个内存槽,而 8 字节对齐的内存槽是有限的,扫一遍就完了。
跑出来 167 个引用点,而不是 19 个。换句话说,真正的 hook 数量是 167,不是 19。19 是 thunk 数,167 是 thunk 被装入函数指针表的次数——每次装入对应一个 hook 注册。
到这里基本看清楚了,这个 dylib 的“反逆向价值”,也即作者的核心防护投入,不在于隐藏代码,而在于隐藏 hook 列表。隐藏 hook 列表的目的就一个:让别人不能直接照抄。这是商业反封号工具的核心商业秘密——算法可以重写,核心代码可以重新组织,但“作者花了多长时间发现微信哪些方法值得 hook、哪些方法 hook 后会引发副作用、哪些方法是关键卡口”这种领域知识,是用时间和试错堆出来的,这才是真值钱的部分。
4. 写反混淆器:223 个 trampoline 全部解码,0 错误
没办法了,只能写反混淆器一个个来。整体思路按 OBDD(Reduced Ordered BDD)展开——因为这棵尾调用链本质就是一棵决策树,每个 trampoline 是一个决策节点,根据 W8 的值二选一往下走。BDD 这个数据结构在 SAT/SMT 求解、模型检查、电路 EDA 里用得很多,核心思想就是把布尔函数表示成一棵分叉树,每层节点对一个输入比特做判断,共享相同的子树以减少节点数。OLLVM 在这里把一个常规 if-else 嵌套结构编译成 BDD,本质上是把逻辑结构延展到运行时。
step1 先重建 X20 偏移映射。sub_4000 的 prologue 里把一个巨型指针表的基址 hoist 到栈帧上的某个槽,后续所有 trampoline 用 LDR X10, [X20, #imm] 读这张表。要解 BDD 必须先把这张表完整还原出来。
ARM64 的 ADRL Xn, off_xxxx + STR Xn, [X20, #imm] 是两步指令,光看单条 STR 拿不到目标地址,必须维护一个 shadow state 跟踪“哪个寄存器最近被装载了什么地址”,看到 STR 时再回查 source 寄存器:
# cff_step1_x20map.py: 重建 X20 偏移 → mini-table 地址映射
import ida_funcs, ida_ua, idc
ENTRY = 0x4000
fn = ida_funcs.get_func(ENTRY)
last_adr_for_reg = {} # 寄存器号 → 最近一次 ADRL 装入的地址
x20_map = {} # x20_offset → mini-table 地址
ea = fn.start_ea
while ea < fn.end_ea:
insn = ida_ua.insn_t()
sz = ida_ua.decode_insn(insn, ea)
if sz == 0:
ea += 4; continue
mnem = idc.print_insn_mnem(ea)
# 1) ADRL/ADRP/ADR: 记录"哪个寄存器刚装了什么地址"
if mnem in ("ADRL", "ADR", "ADRP"):
reg = insn.Op1.reg
target = idc.get_operand_value(ea, 1)
last_adr_for_reg[reg] = target
# 2) STR Xreg, [X20, #imm]: 把刚才装入 reg 的地址,存到 X20+imm
elif mnem == "STR" and insn.Op2.type == ida_ua.o_displ:
op2_str = idc.print_operand(ea, 1)
src_reg = insn.Op1.reg
if "X20" in op2_str and src_reg in last_adr_for_reg:
disp = insn.Op2.addr
x20_map[disp] = last_adr_for_reg[src_reg]
ea += sz
import builtins; builtins._x20_map = x20_map
跑完得到 202 条映射,呈现明显的两段结构:X20[0x0..0x3D0] 全部指向 0x42DA0(共享大表的 122 个状态槽),X20[0x3E0..0xC50+] 指向从 0x47348 起递减的滑动窗口段。后来把这个映射 dump 成 JSON 重看才发现实际是 5 段结构外加 3 个特殊槽,其中 X20[0xC78] 指向 0x4AF68——LDAR 用的 atomic flag。这个 LDAR flag 后来被证明是首次/再次入口判定的关键。
step2 扫每个 trampoline,提取 (cmp_const, true_target, false_target) 三元组。模式匹配的锚点是末尾 3 条定式指令——LDR Xn, [X20, #imm](取 mini-table 基址)+ LDR Xn, [Xm, Wk, UXTW#3](以 0/1 索引)+ BR Xn,这三条几乎从来不变,把它们卡住其它的就好办了:
# cff_step2_scan_trampolines.py: 扫 1492 个函数,识别 trampoline 模板
import ida_funcs, ida_ua, ida_bytes, idc, idautils, ida_segment, builtins
x20_map = builtins._x20_map
text_seg = ida_segment.get_segm_by_name("__text")
# sub_4000 prologue 装的魔数寄存器(一开始只知道 3 个)
W_REG_CONSTANTS = {
22: 0xFD6886DF, 25: 0x3664924A, 28: 0xD8128E13,
}
trampolines, errors = [], []
for fn_ea in idautils.Functions(text_seg.start_ea, text_seg.end_ea):
if fn_ea == 0x4000:
continue # sub_4000 自己不是 trampoline,跳过
insns = list(decode_function(fn_ea)) # [(ea, mnem, ops, insn_t), ...]
if not (4 <= len(insns) <= 12):
continue
# 末尾必须是 BR Xn
if insns[-1][1] != "BR":
continue
# 倒数第 2 条: LDR Xn, [Xm, Wk, UXTW#3] ← mini-table 索引
if insns[-2][1] != "LDR" or "UXTW#3" not in insns[-2][2][1]:
continue
# 倒数第 3 条: LDR Xn, [X20, #imm] ← mini-table 基址
pp = insns[-3]
if pp[1] != "LDR" or "X20" not in pp[2][1]:
continue
x20_offset = pp[3].Op2.addr & 0xFFFFFFFF
# 往前找 CMP / CSET 解 cmp_const(8 种模式后面会讲)
cmp_const = resolve_cmp_const(insns, W_REG_CONSTANTS)
# 用 X20 偏移查 step1 的映射拿到 mini-table 地址,读两个槽
table_addr = x20_map.get(x20_offset)
if table_addr is None:
errors.append({"fn": fn_ea, "x20_offset": x20_offset})
continue
trampolines.append({
"ea": fn_ea,
"x20_offset": x20_offset,
"table_addr": table_addr,
"cmp_const": cmp_const,
"false_target": ida_bytes.get_qword(table_addr),
"true_target": ida_bytes.get_qword(table_addr + 8),
})
builtins._trampolines = trampolines
# 跑完: 223 个 trampoline,errors = 0
resolve_cmp_const 是个递归往前扫的小函数,处理几种比较模式。第一版我只覆盖了三种:
CMP W8, #imm ✓
CMP W8, W22/W25/W28 ✓ (上面那三个魔数寄存器)
CMP W8, W? + 前面 MOV W?, #imm ✓
漏掉的:
CMP W8, [SP, #imm] ✗ 栈变量
CMP W8, W7/W9/W10/W11 ✗ 其他寄存器
CMN W8, #imm ✗ 负数比较
TST W8, #imm ✗ 位测试
LDR W?, [X20, #imm] + CMP W8, W? ✗ X20 数组取常量(最常见!)
第二版补全所有这些模式,解析率到 83%。剩下 17% 卡在 sub_4000 末尾隐藏的 13 个魔数寄存器——我之前只看到 W22/W25/W28,实际 prologue 末尾紧跟着另外 13 个 MOV Wn, #imm,把其他寄存器初始化成更多魔数:
W12 = 0x40D58939 W17 = 0x52BD65EA
W13 = 0x3F4EFB5E W0 = 0x7C2AD684
W14 = 0x3BEEF50F W1 = 0x68470F1E
W15 = 0x50856051 W2 = 0x84FF6501
W16 = 0x5B167B19 W3 = 0x822E0282
W4 = 0x97F5C604
W27 = 0xCA599231
W23 = 0xFF9AE195
这 13 个 MOV 装在 0x493C-0x49A4,夹在 prologue 主体跟函数末尾的 BR 之间,我第一遍读 sub_4000 是从入口顺序读的,看到 X20 数组初始化和那一大堆 ADRL+STR 之后觉得已经摸清模式就跳过去了,完全错过了末尾这 13 行。这是典型的“以为读完了其实没读”。手工补完之后解析率到 100%(16 个魔数寄存器,从只看见 3 个变成 16 个),回头看 step2 跑出的 cmp_const 列表,所有“未知”标签都消失了。
这些 cmp_const 的值看起来都是高熵随机数(0x3664924A、0x5245100A、0x673C4425、0x72E2FCCE、0x78AE4B81……),平均 popcount 接近 16(理论期望也是 16),没有明显模式——这几乎可以肯定是 PRNG 的连续输出。这种模式有个有趣的副产品:如果能猜出 PRNG 的种子和算法,就可以预测整条 trampoline 链的 cmp_const 序列,这反过来可以做“哪些函数被切割成了 trampoline”的预测器。
step4 是真正的反混淆器,把 223 个描述符渲染成 if-else 树:
# cff_step4_unflatten.py: BDD 反扁平化,输出 if-else 树
from collections import Counter
import builtins
descriptors = builtins._tramp_descriptors
desc_by_ea = {d["ea"]: d for d in descriptors}
tramp_set = set(desc_by_ea)
# 1) 入口 / 出口 / 入度
referenced, all_targets = set(), set()
in_degree = Counter()
for d in descriptors:
for k in ("false_target", "true_target"):
t = d.get(k)
all_targets.add(t)
if t in tramp_set:
referenced.add(t)
in_degree[t] += 1
entries = tramp_set - referenced # 没被任何 trampoline 跳来的
exits = all_targets - tramp_set # 跳出 BDD 的真实函数
# 2) 递归渲染(visited 防环,max_depth 防爆栈)
def render(ea, indent, visited, max_depth=15):
pad = " " * indent
if ea not in tramp_set:
return f"{pad}-> sub_{ea:X}() [exit]\n"
if ea in visited:
return f"{pad}-> sub_{ea:X} [LOOP]\n"
if max_depth <= 0:
return f"{pad}-> sub_{ea:X} [DEPTH LIMIT]\n"
d = desc_by_ea[ea]
cond = d["cset_cond_pretty"] # < / == / ...
cst = f"0x{d['cmp_const']:X}" if d.get("cmp_const") else "?"
out = f"{pad}if W8 {cond} {cst}: // sub_{ea:X}\n"
out += render(d["true_target"], indent+1, visited|{ea}, max_depth-1)
out += f"{pad}else:\n"
out += render(d["false_target"], indent+1, visited|{ea}, max_depth-1)
return out
# 3) 输出全部入口
output = []
for entry in sorted(entries):
output.append(f"### ENTRY: sub_{entry:X} (in-degree={in_degree.get(entry, 0)})")
output.append(render(entry, 0, set()))
open("data/unflattened_bdd.txt", "w").write("\n".join(output))
跑完产物 4.7 MB / 84557 行 if-else,平均每个入口几百到几千层嵌套。文件大但不离谱,grep 找特定 hook 的 dispatch 路径很方便——比如要看 sub_8794 在哪些上游被引用,直接 grep -n "sub_8794" unflattened_bdd.txt | head -50 就能列出来。
unflatten_summary.json 里的关键数字:74 个入口 / 53 个出口 / 149 个内部节点。出口是真正跳出 BDD 的“业务函数”,其中 38 个是 hook 的 newImp(后面会讲它们里面 36 个还是 BDD,只 2 个是真函数)。74 入口意味着这棵尾调用链不是一棵“大树”,是 74 棵相对独立的子树并存,每棵子树对应一个 hook dispatch 路径。
入度统计揭露了 BDD 的拓扑形状极不均匀:
sub_8794 in-degree=130 ← 58% 的 trampoline 都跳来这里
sub_49C4 in-degree= 20 ← 主干链 #1 根节点
sub_87B0 in-degree= 20 ← 主干链 #2 根节点
sub_8F08 in-degree= 13
其余 ... in-degree ≤ 2
130 + 20 + 20 + 13 = 183 条边收敛到 4 个节点(占 446 条边的 41%),其余 263 条边平均分配到 217 个节点。这种“少数节点高度收敛 + 多数节点零散”的拓扑反映 OLLVM 用了 ROBDD(Reduced Ordered BDD) 优化——把多个判定路径里相同的尾段合并成共用节点,这是 BDD 数据结构的标准压缩。
223 个 trampoline 全部成功还原,errors = 0。这件事本身就是最强的信号——它证明我的模型 100% 准确,没有漏掉任何一种 trampoline 形态。0 错误的真正含义是模板假设零反例——任何 trampoline 一旦满足“6-7 条定式指令 + CSET LT + LDR [X20+off] + LDR [X10, Wx UXTW#3] + BR X9”模板,X20 偏移在映射表里一定能查到,F/T target 一定指向合法的 trampoline 地址。剩余 85% 没匹配上的不是反例,是模板变种。模型对了,剩下的就是工程量;模型错了,跑 100% 命中率也是徒劳。
5. 找解密器:xref 全军覆没,dref 一击命中
反混淆完成之后,主战场转移到字符串解密。__data 段里有 0x40328 字节高熵密文,得搞清楚解密算法和 key。
我的第一反应是找解密器函数——解密器肯定要“写”密文区(把解密结果写到某个 buffer),那么 xrefs_to(0x40000) 应该能找到所有写入点。这是逆向加密字符串最直接的入口。
# 第一轮(失败)
for cipher_byte in range(0x40000, 0x42500):
refs = mcp__ida-pro-mcp__xrefs_to(cipher_byte)
# 几乎全是 0 个引用!
整整一天我卡在这里。0 个 xref 意味着 IDA 没有任何指令“显式引用”这个地址。但密文确实存在,确实有人解密它,这是个矛盾。
我换了个角度想:IDA 的 xref 是已经确认的链接,但 IDA 还有一种更宽松的引用——dref(data reference),是数据流分析推断出来的“指令可能访问的数据地址”。OLLVM 阻断了 xref(因为 xref 检查指令是否“明确引用某地址”),但阻断不了 dref(IDA 的 ADRP+ADD 重组分析)。
具体的差别在于,xref 是 IDA 看到形如 MOV X0, addr / LDR X0, [addr] 这种“指令的立即数操作数本身就是地址”才会建立的;但 ARM64 没法在单条指令里塞一个完整 64 位地址,通常用 ADRP X8, page; ADD X8, X8, #pageoff 两条指令拼出来。OLLVM 把这两条指令拆开,中间塞一堆无关 MOV/STR/CMP,IDA 的 xref 引擎匹配不到这种“两步寻址”模式,就不建立 xref。但 IDA 的 dref 引擎专门做 ADRP+ADD 的指令对配对,这种数据流分析在两步寻址下仍然有效。OLLVM 阻断了 xref,但阻断不了 dref,这是它自己挡不住自己的数据流分析。
第二轮——不再扫“谁引用了密文地址”,换成扫“哪些函数对密文区写入次数最多”,而且区分 STR(写)和 LDR(读),顺手统计 EOR 指令数(疑似 XOR 解密的强指标):
# cff_step16_find_dec_v3.py: dref 扫全函数,找 master decryptor
import idc, idautils, ida_funcs, ida_ua
CIPHER_MIN, CIPHER_MAX = 0x40000, 0x42500
candidates = []
for fn_ea in idautils.Functions():
fn = ida_funcs.get_func(fn_ea)
if not fn: continue
sz = fn.end_ea - fn.start_ea
if sz < 30 or sz > 5000:
continue # 排除 thunk + sub_4000 这种巨型初始化函数
W_addrs, R_addrs = set(), set()
n_eor = 0
ea = fn.start_ea
while ea < fn.end_ea:
mn = idc.print_insn_mnem(ea)
# 关键: dref 而不是 xref
for dref in idautils.DataRefsFrom(ea):
if CIPHER_MIN <= dref < CIPHER_MAX:
if mn in ("STR", "STRB", "STUR", "STURB"):
W_addrs.add(dref)
elif mn in ("LDR", "LDRB", "LDUR", "LDURB"):
R_addrs.add(dref)
if mn == "EOR":
n_eor += 1
ea = idc.next_head(ea)
if len(W_addrs) > 10:
candidates.append({
"ea": fn_ea, "size": sz,
"n_W": len(W_addrs), "n_R": len(R_addrs), "n_eor": n_eor,
"W_range": (min(W_addrs), max(W_addrs)),
})
candidates.sort(key=lambda x: -x["n_W"])
# 跑完: 15 个候选,头部 3 个写入量最大
几个阈值都是经验值:size < 30 排除 thunk,size > 5000 排除 sub_4000 这种巨型初始化函数,n_W > 10 卡掉只是顺便引用一两个常量的普通函数。最后剩下来的几乎全是 master decryptor。
跑完落盘 data/decryptor_candidates.csv,15 行,头部几行(按 n_W 排序)长这样:
addr name size n_R n_W n_eor W_range
0x4f34 sub_4F34 2260 107 108 18 0x40005-0x4026B
0x6df4 sub_6DF4 2532 109 108 22 0x40005-0x4026B ← W_range 跟上一行完全一样!
0x1e418 sub_1E418 2556 119 116 23 0x41130-0x4127C
0x22ab8 sub_22AB8 1724 76 73 12 0x4152F-0x415DF
0x26b3c sub_26B3C 1160 49 47 6 0x416E9-0x4176E
0x1d0b8 sub_1D0B8 420 13 12 5 0x41032-0x4103D
0x1d3e0 sub_1D3E0 292 11 12 5 0x41032-0x4103D ← 跟上一行同 W_range
... 其余小节点
光看这个表就能看出细节:第二三行(sub_6DF4 / sub_1D3E0)的 W_range 跟它们前一行完全相同,这就是孪生——写入同样的 108 / 12 个字节地址,只是 MBA 模板不同。n_eor 越高的越像 OLLVM 字符串解密的“显式 EOR”版本(不那么努力 MBA 的);n_eor 低的可能 MBA 强度更高,EOR 全被位掩码替代了。
跑出来的 15 个候选里,头部 3 个写入量最大:
sub_168C4 写 161 个独立字节,W_range = 0x40590-0x41001 ★ master
sub_FB2C 写 160 个独立字节,W_range = 0x40642-0x40FC4
sub_10A30 写 160 个独立字节,W_range = 0x40642-0x40FC4 ← 跟 sub_FB2C 范围完全相同
注意第三行那个奇怪的事实:sub_FB2C 和 sub_10A30 写的范围完全一样。第一眼看到的时候我以为是哪里统计错了,跑了一遍验证,确实是两个不同的函数(地址相差 0xF04),但 W_addrs 集合完全相同。这是 OLLVM 的“复制粘贴 MBA 重写”模式——每个真 master 在地址相邻 0x1000-0x4000 的位置有一个 MBA 重写孪生。代数等价,但 MBA 模板不同。
具体例子,反编译出来同一行的两个版本:
// sub_FB2C
byte_40F60 = (~byte_40F30 & 0x89 | byte_40F30 & 0x76) ^ 0x13;
// sub_10A30
byte_40F60 = byte_40F30 ^ 0x9A;
代数化简两者等价,因为 0x89 | 0x76 = 0xFF 且 0x89 & 0x76 = 0,所以 ~b & 0x89 | b & 0x76 = b ^ 0x89,再 XOR 0x13 得到 b ^ (0x89 ^ 0x13) = b ^ 0x9A,跟 sub_10A30 完全一样。
这种孪生不是冗余备份,是双 MBA 写法测试——同一组 K 值用两套不同的 MBA 模板生成两份代码,把分析者引入“哪个是真的”的死胡同。检测方法很简单:找写地址集合 100% 相等的两个函数,跳过其中之一。这能直接砍掉一半的工作量。
6. 数学化简:OLLVM 的 8 种 MBA 模板,代数化简后全是 b ^ K
确定 sub_168C4 是主解密器,我开始反编译它的解密公式。
它写得很恶心,121 个字节解密公式,每一个都用不同的 MBA 表达式包装。我看到的前几个:
plain[0] = b ^ 0xE0; // 直接 XOR
plain[1] = ~b & 0x83 | b & 0x7C; // 位掩码 1
plain[2] = ~((b | 0x33) & (~b | 0xCC)); // 位掩码 2
plain[3] = b - 2 * (b & 0xF3) - 13; // 算术 1
plain[4] = (~b & 0xE9 | b & 0x16) ^ 0xF6; // 嵌套 XOR
plain[5] = b - 2 * (b & 0x50) + 80; // 算术 2
plain[6] = ~(b & 0xA4 | ~b & 0x5B); // 位掩码 3
刚开始看到这些我有点头疼,以为得逐条手工化简或者上 SMT solver。但后来我盯着这些公式看了一会儿,发现一个规律:所有这些公式,实质上只做一件事——XOR。
| 公式形态 |
代数化简 |
真实操作 |
b ^ K |
b ^ K |
XOR K |
~b & A \| b & B (A+B=0xFF, A&B=0) |
b ^ A |
XOR A |
~((b\|A) & (~b\|B)) (同上约束) |
b ^ B |
XOR B |
~(b & A \| ~b & B) |
b ^ ~A |
XOR ~A |
b - 2*(b & A) ± C (A 是单 bit 掩码或全位) |
(b ^ A) ± C |
XOR + 加减 |
(... bitmask ...) ^ K |
双重 XOR 链 |
XOR (M ^ K) |
证明的话用真值表展开就行,比如 ~b & A | b & B,当 A | B == 0xFF 且 A & B == 0 时,A 和 B 互补:
b 的某一位 = 0 时:~b 该位 = 1,~b & A = A 的对应位,b & B = 0
→ 输出 = A 的对应位
b 的某一位 = 1 时:~b 该位 = 0,~b & A = 0,b & B = B 的对应位
→ 输出 = B 的对应位
把 A 和 B 拼起来等于 0xFF,而 b XOR A 在 b=0 时输出 A,b=1 时输出 ~A = B(当 A+B=0xFF 时)。完全等价。OLLVM 用 8 种写法绕死分析者,代数学一拳打回原形。
第一版 step17 是最笨的办法:把 IDA 反编译出来的 121 行 C 表达式逐行抄成 Python lambda,放进列表,直接跑:
# cff_step17_apply_dec_168C4.py: 第一版手工照搬反编译输出
import ida_bytes
def b(addr):
return ida_bytes.get_byte(addr)
# 把 sub_168C4 反编译里每一行 byte_DST = expr; 抄成 (DST, lambda) 元组
RULES = [
# 第一段 0x40D5D-0x40D67 → 0x40D7D-0x40D87 (+0x20, 11 字节)
(0x40D7D, lambda: b(0x40D5D) ^ 0xE0),
(0x40D7E, lambda: b(0x40D5E) ^ 0xBA),
(0x40D7F, lambda: ((~b(0x40D5F) & 0x83 | b(0x40D5F) & 0x7C) ^ 0xE4) & 0xFF),
(0x40D80, lambda: (b(0x40D60) - 2 * (b(0x40D60) & 0xF3) - 13) & 0xFF),
(0x40D81, lambda: b(0x40D61) ^ 0x23),
(0x40D82, lambda: ~(b(0x40D62) & 0xA4 | ~b(0x40D62) & 0x5B) & 0xFF),
(0x40D83, lambda: ~((b(0x40D63) | 0x33) & (~b(0x40D63) | 0xCC)) & 0xFF),
# ... 共 121 条
]
decrypted = {dst: fn() & 0xFF for dst, fn in RULES}
plaintext = bytes(decrypted[a] for a in sorted(decrypted))
print(plaintext.split(b"\x00")) # 9 段明文字符串
跑出 9 段明文之后,我意识到下一个 master(sub_FB2C)还有 160 行公式要抄,后面还有 14 个 master 等着——总共一千多行公式手抄,只要错一处就得回头 debug。这时候才动手把这一步抽象成通用解析器:
# cff_step19_parse_decomp_to_schedule.py: 通用 schedule 解析器
import re
ASSIGN_RE = re.compile(r"byte_([0-9A-Fa-f]+)\s*=\s*(.+?);", re.S)
BYTE_REF_RE = re.compile(r"byte_([0-9A-Fa-f]+)")
def parse_pseudo_to_schedule(pseudo_text):
"""把 IDA 反编译输出的 C 赋值行,转成可 eval 的 Python 表达式列表"""
schedule = []
for m in ASSIGN_RE.finditer(pseudo_text):
dst_addr = int(m.group(1), 16)
c_expr = m.group(2).strip()
# 跳过"右侧无 byte_ 引用"的行(栈引用 / 形参 / 临时变量)
if not BYTE_REF_RE.search(c_expr):
continue
# byte_XXXX → b(0xXXXX),整体 & 0xFF 防止 ~ 在 Python 里的有符号扩展
py_expr = BYTE_REF_RE.sub(lambda mm: f"b(0x{mm.group(1)})", c_expr)
py_expr = f"({py_expr}) & 0xFF"
schedule.append((dst_addr, py_expr))
return schedule
def apply_schedule(schedule, byte_func):
"""跑 schedule,输出 dst → plaintext byte 字典"""
return {dst: eval(expr, {"b": byte_func}) for dst, expr in schedule}
# 用法:
# pseudo = open("sub_168C4_decompile.c").read()
# sched = parse_pseudo_to_schedule(pseudo)
# result = apply_schedule(sched, byte_func=ida_bytes.get_byte)
整套流程不需要 SMT solver、不需要 IR 转换、不需要代数化简,Python 标准库就够。这是写工具时的一种思路:当对手已经把信息明文表达在 C 代码里,你就别费劲去做“理解”那一步,直接把代码当函数用。
7. 第一次明文曝光:9 段字符串炸开整个反封号机制
跑出来的 9 段明文是这样的:
0x40D87: rRequest: # 加好友请求 SEL 后缀
0x40DDF: MMTokenService # ★ ObjC 类名
0x40E60: MMClientCacheManager # ★ ObjC 类名
0x40BFE: checkConfig # ★ SEL
0x40590: reportCrashLog:type: # ★★★ 被 nullify 的 hook!
0x40B20: reportDeviceToken: # ★★ 设备 Token 上报
0x40CB0: refreshTokenWithPolicy: # ★★ Token 刷新
0x40AE2: getAppSignType # 应用签名类型
0x40FF0: isJailbrokenDevice # ★★★★ 越狱检测!
isJailbrokenDevice 配合后面发现的 9 个 nullsub_1 newImp,机制完全清楚了:dylib 把微信内部用于检测越狱、上报安全事件的方法,全部 hook 成空操作或返回伪值。
reportCrashLog:type: 直接被替换成 nullsub_1(汇编层面就是 MOV X0, #0; RET 两条指令)。任何代码调它都直接返回。崩溃信息永远不会到达微信服务器。崩溃日志在风控里有非常高的价值——黑产的 hook 工具崩溃模式跟正常用户完全不同(频繁在 ObjC runtime 内部崩溃、栈帧带有 MobileSubstrate 痕迹、崩溃地址固定在某些 hook trampoline),把这条上报通路砍掉,等于砍掉一个核心信号源。
isJailbrokenDevice 被 hook 让它永远返回 NO。微信代码里所有 if ([self isJailbrokenDevice]) { ban_user(); } 这种判断,直接走“非越狱”分支。
MMTokenService 是微信 Token 系统的核心类。dylib 拦截这个类的 refreshTokenWithPolicy: 等方法,控制 Token 刷新行为,维持账号“看起来合法”的状态。
那一刻我意识到一件事:这个 dylib 不是在破解微信的风控算法,是在切断风控的信息源。这是攻防中典型的高维降维打击——算法再强,数据进不来等于零。微信服务端可能跑着最先进的图神经网络做账号关系建模、用 LSTM 做行为时序异常检测,但如果客户端连“isJailbrokenDevice = YES”这条信号都不上报、连崩溃日志都不发,模型再强也是在猜。
8. 扩搜索面:孪生 + 双份镜像
这里我犯了另一个错误:以为找全了。
之前我扫的 cipher 区是 0x40500-0x41100,因为这是 sub_168C4 写入的范围。我以为 cipher 总量就这么大。直到我去看 sub_FB2C(被识别为孪生)和它的孪生 sub_10A30 的 W_range——0x40642-0x40FC4,跟 sub_168C4 部分重叠但不完全相同。两个 master 不是覆盖同一片区域的“主备”关系,而是分别管不同的字符串区。
我把搜索面扩大到整个 __data 段(0x40000 - 0x42500),用同样的 dref 扫描,这次找到了 17 个 master decryptor(包括 5 对孪生)。
跑完每一个,累计解出 66 个独立明文字符串、981 字节。一下子从 4% 覆盖跳到接近全覆盖。
| Master |
明文范围 |
字节数 |
主要内容 |
| sub_168C4 |
0x40590-0x41001 |
161 |
hook 主区(MMTokenService 系列) |
| sub_FB2C |
0x40642-0x40FC4 |
160 |
hook 主区(MMContext / ExptService) |
| sub_5A4C |
0x400D5-0x4031F |
215 |
反作弊核心类(MMRuntimeIntegrity 等) |
| sub_4F34 |
0x40005-0x4026B |
108 |
dylib 头部(isEnvironmentTrusted 等) |
| sub_1E418 |
0x41130-0x4127C |
116 |
A/B 配置 key |
| sub_22AB8 |
0x4152F-0x415DF |
73 |
状态字典 key |
| sub_26B3C |
0x416E9-0x4176E |
47 |
越狱痕迹擦除 |
| sub_33CE8+sub_33A24 |
0x41BA0-0x41BBC |
29 |
★ SHA-256("") 伪值前 29 字节 |
| sub_2E5E8 |
0x4196A-0x41A64 |
12 静态可见 / 96 不可见 |
栈指针变种 |
| ... 其余 8 个小节点 |
|
|
辅助类名 |
最后那个 sub_2E5E8 是这个项目的死角,放到第 11 节讲。
里面 B@:@、v@:、@@: 这种 4-5 字节短串是 ObjC method type encoding(B= BOOL,@= id,:= SEL,v= void,i= int),是 ObjC runtime 在 class_addMethod 等 API 里用的方法签名格式。它们出现在解密结果里说明 dylib 不光 swizzle 已存在的方法,还会用 class_addMethod 给目标类新增方法——这跟 hook 注册函数中出现的 _class_addMethod import 完全对得上。
中间还有个意外发现——hook 注册表是双份镜像的。我把 167 个 hook site 按地址段分布画出来:
0x118dc - 0x11dc0 ~64 个 hook
0x1bb98 - 0x1c2b4 ~64 个 hook ← 跟上面完全相同的 SEL/Class 序列!
0x12128 - 0x121b8 ~6 个,签名相关
0x16598 - 0x16624 ~6 个,签名相关
0x1c134 - 0x1c2b4 ~20 个,Token/Crash 相关
两段 64 个 hook 是同一份。我先是怀疑自己脚本统计错了,把每个 hook 的 SEL 地址 + Class 地址对都列出来比对,确实是同样的序列出现两次,只是注册函数名不同,代码体也几乎一样。原因猜测有几个:
ObjC swizzling 在 `+load` 早晚两个时机各执行一次
反卸载机制——即使别人写脚本 unhook 一份,另一份依然在
不同微信版本兼容——一份对 8.0.30,另一份对 8.0.40,运行时根据版本选
我觉得可能是第 3 个。
9. 167 hook 完整关联:从二进制反扫到作战图
到这一步素材都齐了:66 个明文字符串、167 个 hook 注册 site。剩下要做的是把每个 hook 的 SEL/Class 跟明文对应起来。
每个 hook 注册 site 长这样:
; 大约在每个 hook 注册前 40 条指令内,会有这两条 ADRP+ADD 拼字符串地址
ADRP X0, #class_name_addr@PAGE
ADD X0, X0, #class_name_addr@PAGEOFF ; X0 = ObjC class name 地址
...
ADRP X1, #sel_name_addr@PAGE
ADD X1, X1, #sel_name_addr@PAGEOFF ; X1 = SEL 字符串地址
...
BL _MSHookMessageEx ; (实际是 LDR + BR 间接调用)
_MSHookMessageEx 的标准签名是 void MSHookMessageEx(Class cls, SEL sel, IMP newImp, IMP *origImp)——第一个参数是目标类,第二个是 selector,第三个是替换实现,第四个是用来回填原 IMP 指针的输出参数。所以 hook site 之前的 ADRP+ADD 序列里,前两组拼字符串地址(class name 和 sel name)被传给 _objc_getClass 和 _sel_registerName,把字符串转成运行时对象再喂给 MSHookMessageEx。这是 Substrate tweak 的标准动态注册流程,结构稳定。
分两步走:step6 先把 167 个 hook 注册 site 的原始信息抽出来(每个 site 是哪个 ObjC class、SEL、newImp、origImp 槽地址),step25 再把这些地址跟 step17/19 解出的明文表对应起来。
step6 的核心思路是:对每个 hook 注册函数(sub_1BB50 / sub_118D4 / sub_1C12C / sub_12114 / sub_16504),线性扫一遍找所有 BL _MSHookMessageEx 调用,然后对每个调用反扫前 25 条指令找 ADRL 的目标。SEL 的识别不是直接看 BL _MSHookMessageEx 之前的 ADRL,而是先找 BL _sel_registerName,再看它前面紧跟的 ADRL X0——这是稳定的 ObjC 动态注册模式:
# cff_step6_extract_hooks.py: 从 5 个注册函数提取 167 hook 三元组
def extract_hooks_from_func(fn_ea):
insns = list(decode_function(fn_ea)) # [(ea, mnem, ops, op_vals), ...]
hooks = []
# 1) 找所有 BL _MSHookMessageEx 或它的 thunk(0x38xxx 范围)
hook_calls = []
for i, (ea, mn, ops, ovs) in enumerate(insns):
if mn != "BL":
continue
target = ovs[0]
target_name = idc.get_name(target) or ""
if "_MSHookMessageEx" in target_name or 0x38000 <= target < 0x39000:
hook_calls.append((i, ea))
# 2) 对每个 hook call 反扫前 25 条
for call_idx, call_ea in hook_calls:
sel_str = class_str = newImp = origImp = None
for j in range(call_idx - 1, max(call_idx - 25, -1), -1):
ea_j, mn_j, ops_j, ovs_j = insns[j]
if mn_j == "ADRL":
dst = ops_j[0].strip()
tgt = ovs_j[1]
# ADRL X2/X3 一般是 newImp / origImp 槽
if dst == "X2" and newImp is None:
newImp = tgt
elif dst == "X3" and origImp is None:
origImp = tgt
elif mn_j == "BL":
tname = idc.get_name(ovs_j[0]) or ""
# _sel_registerName 之前的 ADRL X0 是 SEL 字符串地址
if "_sel_registerName" in tname and sel_str is None:
if j > 0 and insns[j-1][1] == "ADRL":
sel_str = read_cstring(insns[j-1][3].Op2.value)
# _objc_getClass 之前的 ADRL X0 是 Class 字符串地址
elif "_objc_getClass" in tname and class_str is None:
if j > 0 and insns[j-1][1] == "ADRL":
class_str = read_cstring(insns[j-1][3].Op2.value)
hooks.append({
"site": call_ea, "class": class_str, "sel": sel_str,
"newImp": newImp, "origImp_slot": origImp,
})
return hooks
all_hooks = []
for fn_ea in [0x1BB50, 0x118D4, 0x1C12C, 0x12114, 0x16504]:
all_hooks.extend(extract_hooks_from_func(fn_ea))
# 跑完: 167 个 hook 三元组
25 条指令的回扫窗口是经验值。一开始我用 15,漏掉了被 OLLVM 拉远的 ADRL 对;后来用 50,又把上一个 hook 的字符串引用也扫进来了。25 是覆盖整个 hook 注册块、不污染前一个 hook 的折衷值。
step6 跑完拿到的 class_str / sel_str 此时还可能是密文——如果字符串区当时还没解密,read_cstring 读出来的就是高熵 binary。所以真正能拿到明文 hook 列表必须等到 step17/19 把字符串解密完之后,再跑 step25 做关联:
# cff_step25_join_hooks_strings.py: hook site 跟明文字符串表对应
import json, idc, idautils
# 已解密的字符串表: [{"addr": 0x40DDF, "plaintext": "MMTokenService", "length": 14}, ...]
plaintext_table = json.load(open("data/all_decrypted_strings.json"))
def lookup_str(addr):
"""addr 落在某个明文字符串内则返回该串,支持中段命中(指针落在串中间)"""
for s in plaintext_table:
if s["addr"] <= addr < s["addr"] + s["length"] + 1:
return s, addr - s["addr"]
return None, 0
def find_str_refs(site_ea, lookback=40):
"""从 hook site 反扫前 40 条指令,收集所有落在密文区的 ADRP+ADD 拼出地址"""
refs = []
ea = site_ea
for _ in range(lookback):
ea = idc.prev_head(ea)
# 1) IDA dref(ADRP+ADD 数据流分析能拼出的地址)
for dref in idautils.DataRefsFrom(ea):
if 0x40000 <= dref < 0x42500:
refs.append(dref)
# 2) 手动 ADRP+ADD 配对(IDA 偶尔识别不全,兜底)
if idc.print_insn_mnem(ea) == "ADRP":
base = idc.get_operand_value(ea, 1)
nx = idc.next_head(ea)
if idc.print_insn_mnem(nx) == "ADD":
offs = idc.get_operand_value(nx, 2)
target = base + offs
if 0x40000 <= target < 0x42500:
refs.append(target)
return refs
# 主流程
results = []
for h in all_hooks:
refs = find_str_refs(int(h["site"], 16))
str_refs = []
for addr in set(refs):
s, off = lookup_str(addr)
if s:
str_refs.append({"plaintext": s["plaintext"], "offset": off})
else:
# 未解密的,直接读密文 hex 留作后续审计
cipher = bytes(idc.get_wide_byte(addr+k) for k in range(64))
cipher = cipher[:cipher.index(0)] if 0 in cipher else cipher
str_refs.append({"cipher_hex": cipher.hex()})
results.append({"site": h["site"], "refs": str_refs})
# 跑完: 164/167 拿到 ≥ 2 个 string ref(SEL+Class 完整对)
这一步有两个细节。第一个是 find_str_refs 同时用 idautils.DataRefsFrom(IDA dref)和手动 ADRP+ADD 配对兜底——单靠 dref 在某些 OLLVM 拉远的指令对上识别不全,加手动配对能覆盖剩下的 5%。第二个是 lookup_str 支持“中段命中”——ADRP+ADD 拼出来的不一定是字符串起点,可能是字符串中段某个字符的位置,这种情况要根据 offset 推回完整字符串。如果不支持中段命中,这一步会少匹配 20% 左右的 hook。
跑完结果:164 / 167 拿到了 SEL+Class 完整对,3 个只拿到一个引用——这 3 个特殊的可能是 class_addMethod 而不是 MSHookMessageEx,后者只需要 Class 不需要现成 SEL。
最终关联结果按业务分类整理:
反作弊核心类(微信侧)
MMRuntimeIntegrity — 运行时完整性
MMSecurityPolicyValidator — 安全策略验证器
MMAntiTamperGuard — 反篡改保护
MMTokenService — Token 服务(风控核心)
MMClientCacheManager — 客户端缓存管理
MMContext — 微信全局 Context
ExptService — A/B 实验服务
CUtility — 工具类
被 hook 的关键 SEL
isJailbrokenDevice → NO
isEnvironmentTrusted → YES
auditLoadedImages → 跳过(过滤掉 MobileSubstrate 路径)
verifyCodeSignature: → YES
validateCertChain:depth: → trusted
getAppBundleSignatureHash → 原版预期值
getAppSignType → 原版类型
flushSecurityEvents → return (nullify)
reportCrashLog:type: → return 0 (nullsub_1)
reportDeviceToken: → return (nullify)
refreshTokenWithPolicy: → return (nullify)
getStringExpt: → 劫持
getBoolExpt: → 劫持
startVerifyContact:opcode:verifyMsg: → 加好友核心动作(改参数)
sendVerifyUserRequest: → 加好友请求
checkConfig → 配置劫持
startMonitoring → no-op
refreshPolicyStore → no-op
auditLoadedImages 这个名字一看就知道是“扫一遍 dyld 已加载的所有 image,看有没有 MobileSubstrate / Cydia / Theos 这种越狱痕迹”。dylib 把它 hook 成“过滤掉自己”——调用时返回 image 列表,但去掉了 dylib 自己和 Substrate 的相关条目。这是一个有意思的细节:作者没有简单粗暴地让 auditLoadedImages 返回空,而是返回一个“过滤后的真实列表”,因为返回空会立即触发风控(“没有任何 dylib 加载?这设备不正常”),而返回过滤后的真实列表,在统计模式上跟正常用户完全吻合。
A/B 配置 key(劫持目标)
clicfg_gogwcs_ios_runtime_sdk_dc_dc_report_enable → NO
clicfg_gogwcs_ios_runtime_sdk_main_cert_chain_report → NO
cert_valid → 写入 YES
env_abnormal → 写入 NO
jb_indicator → removeObjectForKey:
clicfg_gogwcs_ios_runtime_sdk_* 这套 key 是微信 ConfigManager 的命名规范,clicfg 是“client config”,“gogwcs” 看起来是某个内部团队代号,“ios_runtime_sdk” 表明这是 iOS 客户端的运行时安全 SDK。这两个 key 一旦被 hook 返回 NO,整套上报链路从源头就被关闭——比 nullify 拦截更优雅。
10. SHA-256("")
sub_33CE8 解出来 7 字节明文:e3b0c44,在地址 0x41BA0。
sub_33A24 解出来 22 字节明文:298fc1c149afbf4c8996fb,在地址 0x41BA7。
两段相邻地址。拼起来:
0x41BA0: e3b0c44298fc1c149afbf4c8996fb (29 字节)
这 29 字节是什么?第一眼看到的时候我没认出来,以为是某种 token 或者 nonce。我把它拷到 grep 里跟所有解出来的字符串比对,没匹配上;放到 Google 搜了一下,瞬间明白了——这是 SHA-256("") 的前 29 字符。完整 SHA-256 空字符串值是:
e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
这个字符串在 dylib 里被解密出来,只有一个用途——当微信调用 integrityHash getter 时,dylib hook 这个 getter,直接返回这个 SHA-256("") 伪值。不计算真 hash,不读取真数据,直接糊弄过去。
微信可能只检查“返回值是 64 字符的 hex 串”(格式校验),没有做 hash(actual_data) == reported_hash 的双向绑定。一句话总结:任何 hash 校验如果不绑定数据,等于摆设。客户端自己算自己上报,服务端只看格式不看内容,逻辑上等于零防护。
为什么作者偏偏选 SHA-256("") 而不是别的伪值?有几个理由:
- 它是常量,可以硬编码进 dylib,不需要每次运行时计算
- 它是个真实存在的合法 SHA-256 输出,如果服务端有“是否落在合法 hash 值域”的弱校验,这个值能过
- 它“看起来很正常”——一串纯 hex,任何启发式检测都看不出异常
11. 死角:sub_2E5E8 栈指针变种
sub_2E5E8 是个解密器,但它的写入方式跟其他 master 完全不同。看签名:
__int64 __fastcall sub_2E5E8(int a1, _BYTE *a2, _BYTE *a3, _BYTE *a4, _BYTE *a5);
5 个参数,后 4 个是 BYTE 指针。函数体内还额外用了 6 个未在签名里的指针寄存器(X11/X12/X13/X14/X15/X16),通过寄存器从外面传进来。
这 10 个指针总共构成 5 对 source→dest 段:
X11 → X12 (v5/v6) 18 字节
X13 → X14 (v7/v8) 19 字节
X15 → X16 (v9/v10) 16 字节
X1 → X2 (a2/a3) 26 字节 ← 函数签名传入
X3 → X4 (a4/a5) 17 字节 ← 函数签名传入
小计指针段 96 字节 ★ IDA dref 看不到!
外加两段直接 ADRL 加载的可见段:
ADRL byte_41961 → byte_4196A 3 字节 ★ 静态可解
ADRL byte_41A53 → byte_41A5C 9 字节 ★ 静态可解
可见的 12 字节解出来是 NSN+umber\0 拼出 NSNumber\0。
剩下 96 字节卡死了。原因是 caller 通过 BR 间接跳进 sub_2E5E8,IDA 的 xref 看不到调用者。caller 在 BR 之前怎么设置 X11/X13/X15 的值,涉及 ADRP+ADD+ADD 链或者从 struct 字段加载,需要逐 caller 推断——但 caller 是谁,我们根本不知道(因为 BR 间接跳)。
这是 OLLVM CFF + MBA 之外的另一种反静态手段:寄存器混淆。让关键常量不出现在指令立即数里,而是从某个寄存器传进来,这个寄存器在更早的某个调用方设置,IDA 的数据流分析需要“地址常量作为指令立即数”才能起作用,寄存器传递的常量它推不动。
这种混淆比 OLLVM CFF + MBA 都更狠。代码混淆(CFF + MBA)对付的是“理解”,但代数学一拳打回原形;寄存器混淆对付的是“信息可达性”——你看到 LDR Xn, [X11],你知道是从某个地址 load,但你根本不知道 X11 是什么——它从外部寄存器传进来,而外部又来自更外部。要破得跑模拟,跑模拟需要完整 CFG,完整 CFG 已经被前面的 CFF 砍碎。层层嵌套之后,静态分析就是不行。
如果有越狱设备 + frida,破这个 30 秒搞定:hook sub_2E5E8 入口,dump 5 个源指针的值,96 字节 cipher 全部跑出来。Frida 脚本大概 10 行就够:
Interceptor.attach(Module.findBaseAddress("JiDe.dylib").add(0x2E5E8), {
onEnter(args) {
// ARM64 standard: a2=X1, a3=X2, a4=X3, a5=X4
// 加上自定义 X11/X13/X15
const x11 = this.context.x11;
const x13 = this.context.x13;
const x15 = this.context.x15;
console.log("X11:", hexdump(x11, {length: 32}));
console.log("X13:", hexdump(x13, {length: 32}));
console.log("X15:", hexdump(x15, {length: 32}));
// ... a2-a5 同理
}
});
但本样本无越狱设备无 frida,这 96 字节是静态分析的硬边界。dylib 的整体反封号机制理解已经 95%+ 完整。
12. 最终的反封号机制全图
所有材料拼起来,这个 dylib 的反封号攻击对应微信的 6 层防御,每一层都布了对口攻击点:
微信反作弊的 6 层防御 dylib 的 6 层攻击
───────────────────────────────────────────────────────────
① 环境信任检测 让所有“是否越狱/被注入”返回 NO
MMRuntimeIntegrity isJailbrokenDevice → NO
isEnvironmentTrusted → YES
auditLoadedImages → 跳过
② 签名 / 完整性校验 让所有“签名/Hash 校验”返回通过
MMSecurityPolicyValidator verifyCodeSignature: → YES
CUtility validateCertChain: → trusted
getAppBundleSignatureHash → 原版值
integrityHash → SHA-256("") 伪值
③ 反篡改监控 让监控功能空转
MMAntiTamperGuard startMonitoring → no-op
refreshPolicyStore → no-op
④ 事件上报通道 让所有“风险事件上报”无声失败
MMTokenService flushSecurityEvents → return
reportCrashLog:type: → nullsub_1
reportDeviceToken: → return
refreshTokenWithPolicy: → return
⑤ A/B 配置开关(★ 最优雅) 从源头让微信“自己决定”不上报
ExptService getBoolExpt:(@"clicfg_*_dc_dc_report")
→ NO,根本不调用 ④
⑥ 状态字典 + 核心动作 擦除已检出痕迹 + 改加好友参数
NSDictionary 状态 removeObjectForKey:(@"jb_indicator")
MMContext startVerifyContact:opcode: → 改参数
里面第 ⑤ 层的设计最值得一说。直觉的做法是 ④:hook 上报函数本身,让它静默。但作者额外做了 ⑤:hook A/B 配置,让上层 if 直接走 false 分支。为什么要冗余两层?
只 nullify ④ 的代价:微信代码里 if ([MMRuntimeIntegrity isEnvironmentTrusted] == NO) { [self flushSecurityEvents]; } 这种调用链,nullify 拦不住 if 之前的检测,服务端可以从其他接口反查“环境检测是否触发”。hook ⑤ 的优势:让微信自己决定不调用上报。客户端代码路径 100% 走“不需要上报”分支,调用栈干净,寄存器状态、函数耗时都“看起来”是合规客户端,服务端没有任何“客户端被 hook”的反向指纹。
更微妙的是 ④ 跟 ⑤ 的冗余配合。如果只 hook ⑤ 不 hook ④,极端情况下 A/B 配置可能被服务端覆盖(微信下发新配置强制开启 clicfg_*_dc_dc_report_enable = YES),这时候上层 if 又会调进 ④,如果 ④ 没 hook 就漏掉一次上报。两层都 hook,无论 A/B 配置怎么变,上报永远到不了服务器。这是工程上的纵深防御思维,作者不是单点打洞,而是布多层防线。
13. 没做完的事
36 个 BDD 包装的 newImp 内部参数改写细节。我只确认了 SEL/Class 对应关系,具体 hook 替换函数里怎么改 startVerifyContact:opcode:verifyMsg: 的参数还没深入。这部分静态分析能给出的信息有限,主要是因为 newImp 本身也是 BDD 节点(36/38 个 newImp 末尾是 BR Xn 不是 RET),里面的逻辑分散在 BDD 链路上,不在单个函数里。
sub_2E5E8 的 96 字节静态死角。无越狱设备无 frida 的硬边界。
sub_F584 这第二个 dyld init 函数没深挖。__init_offsets 段里有两个入口,sub_4000 是主入口(0xE00 大栈帧那个),sub_F584 是第二个,大约 1296 字节,结构跟 sub_4000 类似(也在栈上构建 mini-table)。它的 BDD 入口不同,可能挂载的是另一组 hook,也可能是某种 fallback。
sub_B50C 这个 dyld_register_func_for_add_image 回调的语义。1740 字节,在栈上构建巨型表,既是 dyld 回调又是 BDD 节点。它的真正用途是“等微信主二进制加载完之后再触发某些 hook”,这是 Substrate tweak 的标准延迟 hook 模式。我确认了它的入口结构,把它构建的指针表 off_47358 落盘到 data/off_47358_table.csv,其中 is_shared_subexpr=True 的条目就是 ROBDD 的共享子表达式——同一个判断节点被多个上游路径复用。这跟主 BDD(sub_4000 的尾调用链)是两套独立机制,但风格一致,都是 OBDD 优化。
14. 数据交付
完整数据落在附件,样本估计搞不出来了。这里汇总一下完整目录结构:
lib/ 总 19 个脚本,~3000 行
├── cff_step1_x20map.py 2.3 KB X20 偏移映射重建
├── cff_step2_scan_trampolines.py 6.0 KB trampoline 三元组提取
├── cff_step3_v3_full_descriptor.py 7.2 KB 完整描述符(CSET 谓词 + 栈槽)
├── cff_step4_unflatten.py 6.2 KB BDD 反扁平化
├── cff_step5_subF584_probe.py 4.1 KB 第二个 dyld init 探测
├── cff_step6_extract_hooks.py 5.9 KB hook 注册函数提取
├── cff_step7_substrate_analyze.py 4.5 KB Substrate 框架识别
├── cff_step8_substrate_callers.py 3.0 KB thunk 反向 caller 追踪
├── cff_step9_globals_probe.py 2.5 KB 全局变量探测
├── cff_step10_classify_newimps.py 2.0 KB newImp BDD/真函数分类
├── cff_step11_nullify_callers.py 2.0 KB nullify hook 识别
├── cff_step12-16_find_dec*.py dref 扫描找 master(5 版迭代)
├── cff_step17_apply_dec_168C4.py 11.6 KB 第一版手工 lambda 列表
├── cff_step18_export_all.py 27 KB 批量导出聚合
├── cff_step19_parse_decomp_to_schedule.py 3.5 KB 通用 8-MBA parser
├── cff_step20-23_run_*.py 批量跑 16 个 master
├── cff_step24_merge_all_strings.py 5.1 KB 字符串合并去重
├── cff_step25_join_hooks_strings.py 5.7 KB hook 跟字符串关联
└── cff_step26_run_2E5E8_adrl.py sub_2E5E8 静态可见部分
data/
├── x20_map.json 5.2 KB 202 条 X20 偏移 → mini-table
├── trampolines.json 67 KB 223 个完整描述符
├── trampolines_compact.json 31 KB 紧凑版(int 而非 hex 字符串)
├── errors.json 335 B 0 错误占位(审计用)
├── edges.csv 17 KB 446 条 BDD 边
├── cff_bdd.dot 33 KB GraphViz dot 文件
├── unflatten_summary.json 2.4 KB 74 入口 / 53 出口 / 149 内部
├── unflattened_bdd.txt 4.7 MB 反扁平化 if-else 树
├── decryptor_candidates.csv 1.2 KB 15 个解密器候选
├── master_decryptors.csv 348 B 17 个 master(含 5 对孪生)
├── dec_168C4_schedule.csv 12 KB sub_168C4 121 行解密 schedule
├── dec_168C4_schedule.json 33 KB 同上 JSON
├── dec_summary.json 2.2 KB 解密总体摘要
├── decrypted_strings.csv 1.4 KB 第一批 9 段明文(sub_168C4)
├── all_decrypted_strings.csv 4.4 KB ★ 66 个独立明文 / 981 字节
├── all_decrypted_strings.json 10 KB 同上 JSON
├── off_47358_table.csv 1.1 KB sub_B50C OBDD 共享子表达式表
├── off_47358_table.json 4.7 KB 同上 JSON
├── globals_probe.json 1.9 KB MBA seed keys + atomic flags
├── hooks_extracted.json 39 KB 167 hook 注册 site 原始信息
├── all_hooks_decrypted.csv 63 KB ★ 167 hook 完整关联表
├── all_hooks_decrypted.json 283 KB 同上 JSON,带详细 refs 链
├── nullify_hooks.csv 1.1 KB ★ 9 个 nullify hook
├── nullify_hooks.json 2.3 KB 同上 JSON
└── newimp_classification.csv 1.8 KB ★ 38 newImp 分类(36 BDD + 2 真函数)
本文为看雪论坛精华文章,由 qqqiu 原创。
如果你想深入了解更多关于逆向工程或底层安全分析的原理与案例,可以访问 云栈社区的安全/渗透/逆向版块。
 发表于 2026-5-26 02:10:55
|
查看: 113|
回复: 0
发表于 2026-5-26 02:10:55
|
查看: 113|
回复: 0
