2026年以来,深度困扰软件行业的是风声鹤唳的SaaS末日论,A社每每发布一个新功能,股价就暴跌一波,全球软件之王微软也未能逃脱,创08年金融危机以来最差季度表现。
但最近一个月软件板块又华丽丽创下了2001年以来的最佳单月表现,5月以来我写了几篇文章来分析软件板块当前的问题与机会:
对于“AI吞噬软件,软件毫无价值”的论调,我一直认为需要分层看待。
然而,AI带来的同质化解读与二元倾向让市场越来越被叙事与注意力主导。一旦某个板块或公司背上负面叙事,就一定会被放大,股价波动的幅度会大幅偏离历史均值。一季度几乎所有美股软件公司都陷在这样的宏大叙事中——“Anthropic吞噬一切”几乎成为传播度最高的标签,也基本变成市场共识:软件行业的terminal value没了,杀估值、杀逻辑、杀事实。这一点在港股也很明显,被认为AI落后字节的腾讯与阿里,股价今年以来一直十分疲弱。但叙事与共识不一定是事情的原貌与真相,也不一定是真理:抱团、共识与真相。
最近的变化是:AI吞噬软件,将变成AI将软件分层。市场不再简单问“软件会不会被AI吞噬”,而是开始问:这个软件到底是AI agent的替代对象,还是AI agent必须依赖的系统、数据、流程、权限、治理和基础设施?近期软件抛售更多是投资者情绪的快速迁移,而不是所有公司基本面的同时恶化。
IGV这个月的超级反转,表面上是DDOG、FTNT、SNOW、OKTA、NOW、TEAM、CRM等财报与股价共振;本质上是市场从一个极端假设:
AI会吞噬SaaS seat / workflow / software margin
突然切换到另一个新假设:
AI会放大企业数据、身份、安全、治理、工作流控制层的需求,软件不一定被吞噬,部分软件反而是 AI adoption 的控制平面。
不是基本面一个月翻倍,而是叙事赔率 / 贝叶斯odds / 边际买家函数在一个月内翻倍。事实层看,IGV 5月上涨约21%,为2001年10月以来最佳单月表现;但即便如此,IGV年内仍约下跌3.8%,仍明显落后纳指,说明这是一次强烈的悲观修复 + 空头回补 + 再分类交易,还不能直接判定为软件新牛市全面确立。
用我的 Attention × Evidence × Pricing Phase-Space OS 来看,这轮IGV在5月前处于一个非常典型的高弹性相变区。
反弹前状态:

催化后状态:

这就是为什么一个月可以从极致悲观切到极致多:不是因为所有问题消失,而是市场原来的 H-set 太单边,证据一反向,就发生叙事空爆。
这次IGV反弹的归因拆解,我会粗略拆成五个因子:

真正主因不是财报数字本身,而是财报数字提供了足够证据,让市场有理由从bearish H-set切到bullish H-set。
也就是说,核心不是earnings beat,而是:
Evidence 给 Narrative 换了方向,Narrative 给 Marginal Buyer 换了身份。
有一说一,市场上关于AI使用是否带来足够ROI与费用管控的声音越来越多了。

Axios报道,有公司因为员工狂用Claude月烧33亿,全网都在寻找这家公司。
5亿美元/月这个案例是匿名AI顾问转述,不是公司官方披露,也没有发票细节;所以精确数字可信度应打折。但趋势本身已经被多条证据确认:微软撤回多数Claude Code许可证,Uber COO质疑token增长和产品产出之间的关系,Amazon关闭内部token排行榜,Salesforce的Benioff则明确说今年可能花3亿美元买Anthropic token,同时呼吁“中间路由层”来区分哪些任务需要最贵模型。
这条新闻真正重要的点,不是“某家公司到底是谁”,也不是“Claude是否太贵”,而是企业AI进入了一个新的阶段:
从AI FOMO / tokenmaxxing阶段,进入AI FinOps / ROI约束阶段。
过去企业看的是“有没有用AI、token用量是否增长、员工adoption是否足够高”;现在CFO/COO开始追问:这些token到底换来了多少收入、多少效率、多少可交付产品、多少真实成本下降?
这是“AI需求爆发”还是“AI成本失控”?
我认为,两个都对,但层级不同。
需求是真实的。 Anthropic官方称,2026年5月完成650亿美元Series H,投后估值9650亿美元,并称run-rate revenue本月已超过470亿美元;这说明企业级Claude / Claude Code / Claude Cowork的需求不是虚构的。
但需求质量开始被质疑。 Axios的后续报道也指出,企业CEO/CIO正在寻找更便宜的模型和router,因为AI使用量冲高后,ROI还没有完全固化;客户不想被单一OpenAI、Anthropic或Google锁死。
所以这不是“AI没用”,而是:
AI的边际token正在从“创新证明”变成“成本嫌疑人”。
最危险的不是前20%高价值token,而是后50%甚至后70%的低质量token:重复尝试、无效agent循环、长上下文反复读取、员工为了显示自己AI-native而刷usage、内部工具没有预算阀门。
按Anthropic当前公开API价格粗略估算,Claude Sonnet 4.6是$3/百万 input token、$15/百万 output token,Claude Opus 4.8是$5/百万 input token、$25/百万 output token;Fast mode甚至更贵。
如果用一个简单的80% input / 20% output混合成本估算:
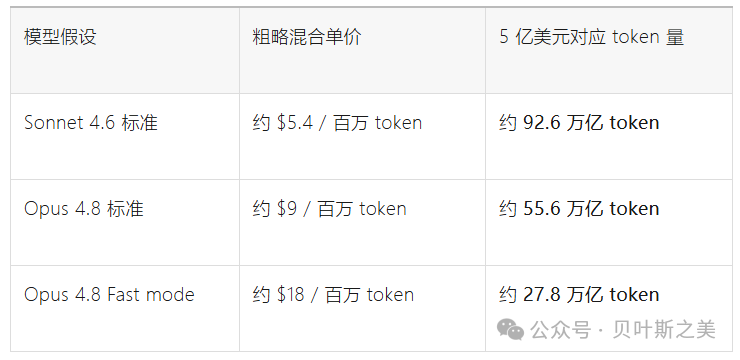
这说明一个关键点:
如果5亿美元/月是真的,它大概率不是普通员工“聊天提问”刷出来的,而是agentic coding / 长上下文 / 自动化循环 / 多agent并行 / 工具调用链条共同造成的。
agentic coding task的token消耗发现agentic任务可以比普通代码问答消耗1000倍token;同一个任务不同运行的token成本可相差最高30倍,而更高token消耗并不必然带来更高准确率。这就是为什么Claude Code这类产品非常强,但也非常危险:它不是“一个更聪明的聊天框”,而是一个会持续读取代码库、规划、调用工具、写文件、测试、回滚、再试一次的自动化成本机器。
本质矛盾:token是input,不是output。
企业最初追踪token,有合理性:它能衡量adoption、预算、使用密度、工具是否被员工接受。但一旦token usage被当成目标,就触发典型的Goodhart Law:
当指标变成目标,它就不再是好指标。
在AI语境下,这会变成:
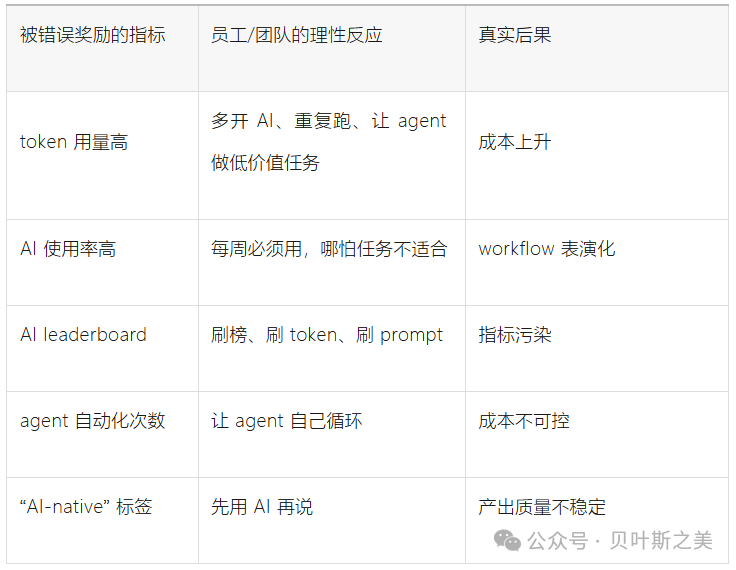
Amazon关闭KiroRank内部token排行榜,就是这个问题的典型信号:公司高管明确提醒员工不要“为了用AI而用AI”,而要解决客户和业务问题。
Uber的话为什么重要?
Uber COO Andrew Macdonald的核心不是“AI没用”,而是他问了一个企业经营层最关键的问题:
token增长,是否能对应到 更多有用的consumer features?
Business Insider引述他的意思是:现在还很难把token使用增长和“实际多产出25%有用消费者功能”之间画出清晰连线。这句话非常关键,因为它把AI ROI从“员工感觉效率提升”拉回到企业经营现实:
企业很快会发现:AI经常提升的是局部动作速度,但不必然提升系统吞吐量。因为真正的瓶颈可能在code review、产品决策、数据权限、合规、安全、测试、上线流程、用户需求判断,而不是写代码本身。这与AI “carbon bottleneck”很一致:硅基供给扩张,不等于碳基组织吸收能力、用户需求、信任、注意力、钱包同步扩张。
微软撤Claude Code:不是Claude不好,而是内部控制权问题
The Verge报道称,微软计划取消多数Claude Code许可证,把很多开发者转向GitHub Copilot CLI;公开口径是统一到Copilot CLI,但报道也指出这有财务动机,截止日期正好对应微软财年结束。更微妙的是,微软并不是完全不用Claude模型:Claude仍可通过Copilot CLI等方式被访问,Foundry与Anthropic的合作也未受影响。
这说明微软真实目标不是简单“省钱”,而是:把agentic coding的入口收回到自家控制平面;把模型能力商品化,工具链和workflow留在Microsoft/GitHub;避免Anthropic成为微软内部开发者事实标准;把token成本、权限、安全、数据、审计、代码库集成纳入统一治理。
这对投资的启示很重要:未来企业AI的价值,不只在“谁的模型最强”,而在“谁控制workflow、权限、数据、成本路由和审计层”。
Salesforce/Benioff是另一面:贵,但可能值
Benioff说Salesforce今年可能花3亿美元在Anthropic token上,主要用于coding;同时他也说并不是每个token都应该交给最贵的frontier model,而未来需要一个intermediary layer,把不同任务路由给不同模型。
这就是成熟用法和tokenmaxxing的分水岭:

Benioff的3亿美元并不一定是坏事。如果它替代的是数千工程师、客服、销售运营、测试、内部工具团队的部分边际工作量,而且能被清楚映射到成本下降或产品速度提升,那就是高ROI。问题是,大多数公司现在还没有能力证明这一点。
所以,市场原本把AI理解成软件的替代力量;SNOW、OKTA、NOW等公司把AI重新解释成软件控制层的需求放大器。
这就是整个反转的根因。
更精确地说:
- AI替代叙事过度单边,市场把所有SaaS都当成donor,忽略了data/security/identity/workflow控制层。
- 软件估值和仓位已经压缩,IGV年内大幅落后,形成高弹性反转条件。
- SNOW提供data-layer硬证据,AI workload需要统一数据云,且公司上修指引。
- OKTA提供identity-layer硬证据,agentic AI增加non-human identity治理需求。
- NOW/CRM/TEAM等提供workflow-layer联想,AI不是只替代UI,而是需要企业流程编排与治理。
- 边际买家函数切换,低配PM、空头、quant、ETF flow、sell-side narrative同时转向。
- AI trade从hardware-only扩散,资金从纯AI capex受益链,扩展到enterprise AI adoption/control-plane链。
- 但估值slack已压缩,现在不是4月那种左侧hidden receiver,而是进入右侧resonance chase。
这轮IGV反弹是一次真实的状态迁移,但不是终局确认。它确认的是:
软件没有被AI末日论一键归零;部分软件正在从AI donor迁移为AI receiver。
它尚未确认的是:
AI能否在整个SaaS板块产生可持续、可计价、可防守、可扩margin的新增增长。
所以现在最好的框架不是“买不买软件”,而是做软件内部的receiver purity ranking:
| 优先级 |
类型 |
| 第一优先 |
data / identity / security / workflow control plane |
| 第二优先 |
有系统记录权 + agent action权限的软件 |
| 第三优先 |
AI能提升NRR / ARPU / margin的SaaS |
| 谨慎 |
只有AI chatbot包装、无数据闭环、seat模型被压缩的软件 |
| 回避 |
AI成本上升但无法monetization的软件 |
IGV这一个月不是“软件全面复活”,而是市场发现:AI不是只会吞噬SaaS,它也会制造新的复杂性;而复杂性一旦进入企业生产系统,就必须被数据、身份、安全、流程和治理软件重新控制。真正的alpha不在“所有SaaS反弹”,而在找到那些从AI复杂性中获得控制权、预算权、定价权的receiver。
所以,对Anthropic / OpenAI / Google:收入增长真实,但“收入质量”要被重新定价:
AI labs的收入爆发是真实的,但市场下一步会看:
- 多少收入来自高价值工作流?
- 多少来自无节制token burn?
- 客户续约时是否降配、限额、转router?
- gross margin是否被compute cost吃掉?
- 企业是否从Opus/Sonnet迁移到Haiku、Gemini Flash、小模型、开源模型?
- token单价是否持续下行?
Axios已经观察到企业在寻找更便宜的模型和router,这会削弱单一frontier model的长期定价权。frontier lab当前不是需求证伪,而是进入 Revenue Quality Reclassification:从“AI使用越多越好”切换到“高价值token占比越高越好”。
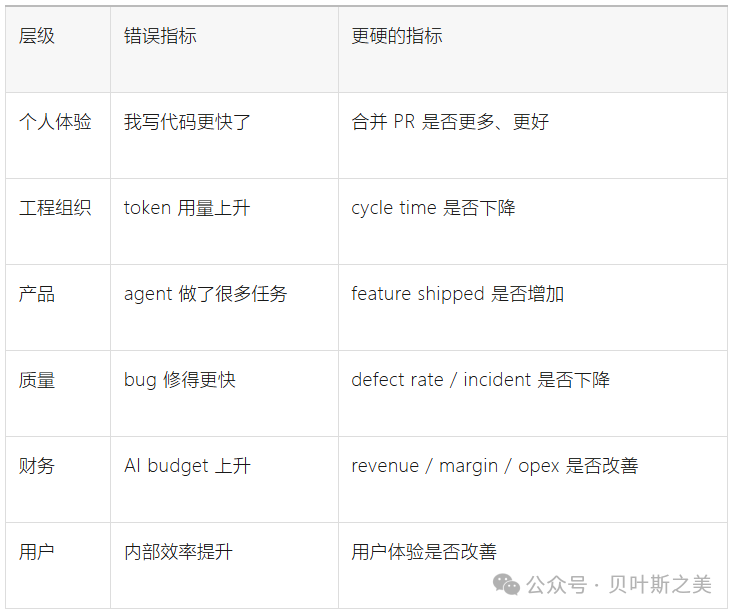
我会把当前企业AI adoption分成5个阶段:

所以,企业AI正在从P1进入P2。不是AI结束,而是粗放增长结束。因此,我认为AI需求要从“token demand”重写成“useful-work demand”。
未来不能再问:
这家公司token用量增长多少?
要问:
这些token转化成了多少可计量useful work?
更好的指标体系应该是:

Token是原材料,不是产成品。真正的AI alpha来自token → workflow → outcome → P&L的闭环,而不是token本身。
AI的下一阶段胜负,不是tokenmaxxing,而是value-routing。
谁能把每一个任务路由到正确模型、正确权限、正确预算、正确workflow,并把结果映射到P&L,谁才是真正的enterprise AI winner。
所以,真正戳破的窗户纸是:AI很有用,但AI使用量不是AI价值。烧token是需求,能把token变成利润才是商业模式。
全文完。
 发表于 2026-5-31 21:16:43
|
查看: 134|
回复: 0
发表于 2026-5-31 21:16:43
|
查看: 134|
回复: 0
