Hexo Labs 在 GitHub 上开源的 SIA(Self-Improving AI)框架,为我们展示了“AI 自我进化”的真正可行性。它并非简单的单次执行,而是通过结构化反馈循环,让 AI 系统能自己评估表现、适应策略并迭代改进——理论上可以无限循环下去。
有别于现有 Agent 那种“执行一次就结束,还得等人来优化”的静态模式,SIA 的核心在于让 Target Agent 的 Harness(代理脚手架/代码)和底层能力实现自主进化。这个项目的实际效果相当亮眼:在 LawBench 上,Top-1 准确率从 45% 提升到了 70.1%;GPU 内核优化实现了 14 倍加速;单细胞 RNA 去噪的 MSE 更是提升了 502%。官方论文还提到,它在 OpenAI MLE-Bench Hard 榜单上排到了第一。
如果你对前沿 [人工智能](https://yunpan.plus/f/29-1)框架感兴趣,或者常在 开源实战 中寻找灵感,那么这个基于 Python 实现的项目绝对值得你深入了解。
一、SIA 核心功能拆解
SIA 是一个基于 Python 的开源自改进 AI 框架(MIT 协议),它的目标很明确:在任意基准任务上,自主提升任意 AI 系统(Model/Agent)的性能。
1. 自改进循环(Self-Improvement Loop)
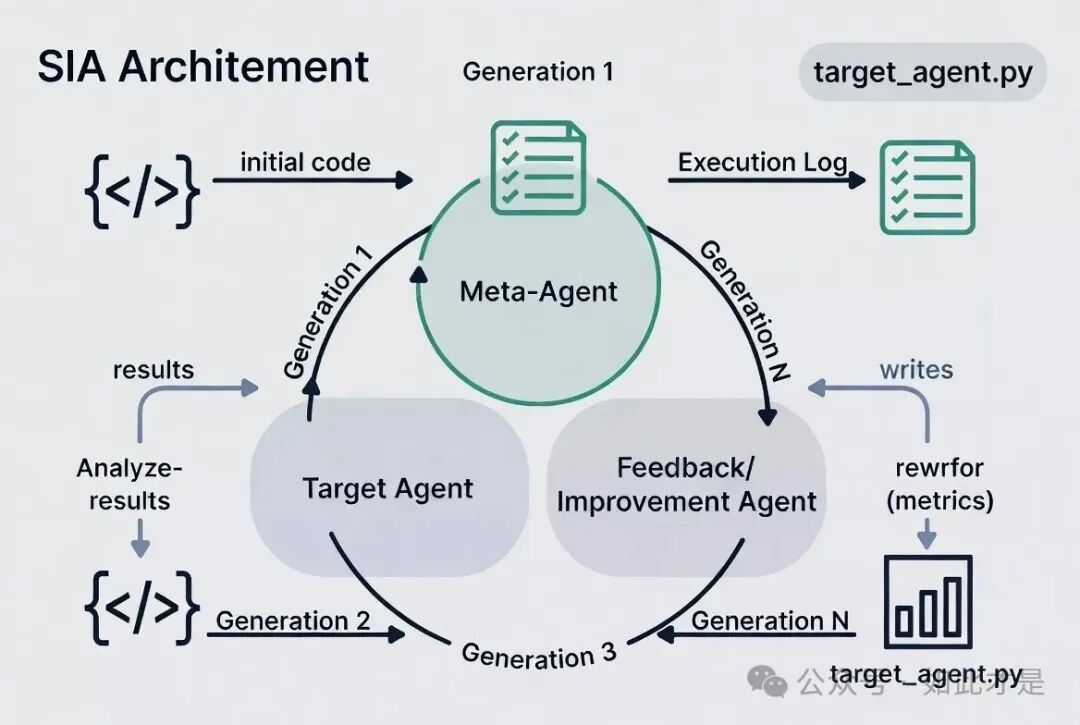
这是 SIA 最根本的能力。系统通过多代(Generations)迭代来实现自我驱动:
- Gen 1:Meta-Agent 根据任务描述生成初始的
target_agent.py。
- 后续 Gen:Target Agent 执行任务并记录完整的执行轨迹 → Feedback/Improvement Agent 分析日志、历史表现和前代改进记录 → 重写出更优的
target_agent.py。
- 循环会一直持续,直到达到
--max_gen 设定的代数。
每一代都会产生独立的 Artifacts,从理念上支持无限迭代。值得留意的是,SIA 不仅改进 Harness,还支持 Weights Improvement,从而实现递归自进化。
2. 三类 AI Agent 如何协同工作?
- Meta-Agent:它会读取
task.md,结合参考模板,生成初始的、专用于当前任务的 Target Agent 代码。
- Target Agent(任务特定代理):负责具体执行任务,支持单轨迹或多轨迹日志记录,使用通过 CLI 参数指定的 LLM,并严格遵守
dataset_dir(只读)和 working_dir(读写)的路径限制。
- Feedback/Improvement Agent:分析
execution logs、evaluation metrics 和历史 context.md,最后输出 improvement.md(分析报告+改进计划)和新的 target_agent.py。它的改进重点在于提升代码结构的鲁棒性和通用性,而非针对特定任务耍小聪明,同时会避免重复之前的失败路径。
3. 内置任务与自定义任务支持
- 内置了 4 个任务:
gpqa、lawbench、longcot-chess、spaceship-titanic。
- 自定义任务:通过
--task_dir 指定目录,该目录需要严格遵循以下结构:
my-task/
├── data/
│ ├── public/
│ │ ├── task.md # 任务描述(Meta-Agent的核心输入)
│ │ └── ... # 公开输入数据(如csv)
│ └── private/ # 隐藏评估数据(Agent不可见)
└── reference/
├── reference_target_agent.py # 模板(从_shared/复制)
└── SAMPLE_TASK_DESCRIPTIONS.md # 可选:类似任务示例,对Meta-Agent泛化很有帮助
- MLE-Bench 集成:通过
python -m sia.prepare_mlebench_dataset -c "spaceship-titanic" 命令,可以一键准备 Kaggle 竞赛数据集(需要 Kaggle API),并自动生成 task 目录。
4. 评估系统(Evaluation)
任务目录下的 data/public/evaluate.py 必须实现 evaluate(submission_path: Path) -> dict 函数。Orchestrator 会自动调用它来生成 results.json,评估指标会自动注入到 Feedback Prompt 中,形成闭环。它支持任意自定义指标,比如 accuracy、MSE 等。
5. 多 Backend 与模型支持
- Claude Backend(默认):专用于 Claude 模型,可选快捷代号
haiku/sonnet/opus。
- OpenHands Backend:支持 Gemini、OpenAI、Anthropic 等多提供商,需要使用完整的
provider/model 名称。
- CLI 参数可以分别指定
--meta_model(Meta/Feedback 用)和 --task_model(Target Agent 用),灵活性很高。
6. 完整的 Artifacts 与日志系统
每一次 Run 都会在 runs/run_{run_id}/gen_{n}/ 目录下生成详细的产物:
target_agent.py(每代代码)agent_execution.json(或 agent_execution/ 文件夹,包含多样本轨迹)improvement.md(Gen≥2 时出现,内含详细分析)results.json 以及 evaluation logs- 隔离的 venv 环境、stdout/stderr 日志
7. CLI 命令行与配置
核心命令很简单:sia --task gpqa --max_gen 5 --run_id 1
一些关键的 Flags(详见 configuration.md):
--task / --task_dir--max_gen(默认为 3)--backend(claude/openhands)--meta_model / --task_model- API Key 通过环境变量设置(
ANTHROPIC_API_KEY、GEMINI_API_KEY、OPENAI_API_KEY 等)
8. 其他实用功能
- 每个 Run 都有独立的 venv,有效避免了环境污染。
- Prompt 高度可定制(在
orchestrator.py 中修改 META_AGENT_PROMPT 和 FEEDBACK_AGENT_PROMPT)。
- Troubleshooting 指南覆盖了目录已存在、ImportError、Kaggle 认证等常见问题。
这些功能组合起来,让 SIA 不只是个简单的 Demo 工具,而是能真正用于科研、Kaggle 竞赛和复杂工程任务自动化迭代的强大平台。
二、安装方法(Pip + 从源码安装)
推荐使用 Pip 安装(最快):
python3 -m venv .venv && source .venv/bin/activate
# Claude专用
pip install 'sia-agent[claude]'
export ANTHROPIC_API_KEY="sk-..."
# 或多模型OpenHands
pip install 'sia-agent[openhands]'
# 设置对应API Key
从源码安装(推荐在进行深度研究或修改时使用):
git clone https://github.com/hexo-ai/sia.git && cd sia- 创建 venv 并激活。
pip install -e '.[claude]' (或 [openhands],根据 pyproject.toml 中的 extras 选择)。- 或使用
environment.yml(如果存在):conda env create -f environment.yml。
- 验证:
sia --help 或直接运行一个内置任务。
源码安装后,你就能直接修改 sia/orchestrator.py 中的 Prompts,或扩展 tasks/ 目录,可玩性更高。
三、高效使用指南
步骤1:运行内置任务
sia --task lawbench --max_gen 5 --run_id 1 --backend claude --meta_model sonnet
Artifacts 自动保存在 runs/run_1/ 下。
步骤2:自定义任务实战
- 按目录结构准备好
my-task/。
- (可选)
cp sia/tasks/_shared/reference_target_agent.py my-task/reference/
- 运行:
sia --task_dir ./my-task --max_gen 5 --run_id 2
- MLE-Bench 示例:先执行
pip install 'sia-agent[mlebench]' && pip install git+https://github.com/openai/mle-bench,设置好 Kaggle Key,然后运行 python -m sia.prepare_mlebench_dataset -c "spaceship-titanic"
步骤3:分析结果
cat runs/run_1/gen_2/improvement.md # 查看改进计划
diff runs/run_1/gen_1/target_agent.py runs/run_1/gen_2/target_agent.py # 对比代码变化
cat runs/run_1/gen_1/agent_execution.json # 查看执行轨迹
高效 Tips:
- 先用小一点的
--max_gen=3 来快速验证任务目录是否正常。
- 使用不同的
--run_id 可以并行对比不同模型或 Backend 的效果。
- 仔细阅读
evaluate.py 示例,确保 results.json 能被正确生成并被 Feedback Agent 有效利用。
- 遇到问题可以参考
docs/troubleshooting.md(比如 venv 包缺失时,可以手动 pip install)。
四、技术原理、架构与实现方式
原理:SIA 专注于“结构化反馈循环”——让系统自我评估、适应策略、持续变优。流程是:Meta-Agent 进行初始化,Target 负责执行并写日志,Feedback 则基于历史 context.md(包含前代改进信息)和当前的执行日志及指标,来重写代码,实现 Harness 乃至 Weights 的进化。
架构实现(核心文件在 sia/ 目录):
orchestrator.py:这是主控逻辑所在。它定义了 META_AGENT_PROMPT(详细规范 target_agent.py 的 CLI 参数、路径处理、日志格式:单 JSON 或多 execution_qN.json)和 FEEDBACK_AGENT_PROMPT(要求阅读 context.md、避免重复失败、输出 improvement.md + 新代码)。context_manager.py:负责跟踪 Run 的历史并生成 context.md。util.py:Agent 运行工具、日志加载(支持单/多轨迹)。prepare_mlebench_dataset.py:MLE-Bench 数据集准备脚本。- 每一代 Target Agent 都在隔离的 venv 中运行,确保了安全性和可重复性。
目录结构:
sia/tasks/{task-id}/:内置任务数据 + reference 模板。runs/run_{id}/gen_{n}/:动态生成的 Artifacts。docs/:包含 architecture.md(流程)、walkthrough.md(自定义)、configuration.md、troubleshooting.md、EVALUATION_GUIDE.md(evaluate.py规范)。
实现亮点:
- Target Agent 有严格的路径控制,防止越权访问
private 数据。
- Feedback Agent 强调“结构改进”与“跨任务泛化”(参考
SAMPLE_TASK_DESCRIPTIONS.md)。
- 自动 Evaluation 闭环:metrics 直接进入 Prompt,形成性能驱动的进化。
- 高度模块化:Prompt 可改、Backend 可换、任务可自定义,非常适合进行研究扩展。
更多架构细节,可以直接阅读仓库 docs/ 和 orchestrator.py 源码。SIA 作为 Hexo Labs 加速 Superintelligence 的首个开源项目,真正把“AI 改进 AI”从概念落地为可运行的框架。它解决了 Agent 的静态瓶颈,让研究者和开发者能将精力聚焦于高价值问题,而把迭代底层能力的苦力活交给 AI 自己。想要获取更深入的 技术文档 参考,它本身就是一个绝佳范例。
 发表于 2026-5-31 21:11:05
|
查看: 162|
回复: 0
发表于 2026-5-31 21:11:05
|
查看: 162|
回复: 0
