在大语言模型迅猛发展的当下,视频大语言模型(VideoLLMs)的生成能力日益精进。然而,其落地应用仍面临“慢”与“算力消耗大”的核心瓶颈。视频序列包含的视觉token数量庞大,导致模型计算复杂度呈二次方增长,处理长视频或高分辨率内容时等待时间尤为漫长。
为提升速度,一种常见的思路是采用Token压缩技术,旨在剔除冗余信息,保留核心内容。但将这一技术直接迁移到视频理解领域时,却往往效果不佳。现有方法多采用统一的压缩策略,忽视了视频帧间独特的视觉信号,导致关键信息丢失、模型性能显著下降。
图1的实验结果清晰揭示了这一问题:移除24个冗余帧对模型的理解准确性影响甚微,但丢弃仅8个独特帧便会引发性能“雪崩”。这凸显了视频信息分布的极度不均衡性,以及区分帧独特性在压缩过程中的至关重要性。
 ▲ 图1. 帧独特性的重要性
▲ 图1. 帧独特性的重要性
此外,许多现有压缩方法的实现依赖于过时的[CLS] token或显式的注意力权重计算,难以与现代化的SigLIP视觉编码器及高效的Flash Attention算子兼容,有时甚至会引入额外的内存开销,事与愿违。
 ▲ 图2. 现有token压缩方法的问题
▲ 图2. 现有token压缩方法的问题
针对以上挑战,上海交通大学EPIC实验室联合四川大学、复旦大学的研究团队提出了“视频压缩指挥官”(Video Compression Commander,简称VidCom²)。该框架能够在LLaVA-OV模型上,仅保留25%的视觉token即可实现99.6%的原始模型性能,同时将大语言模型的生成延迟降低70.8%。相关代码已全部开源。

核心方法:VidCom²框架
VidCom²是一种即插即用的推理加速框架,其核心思想是通过量化每一帧的“独特性”,自适应地调整不同帧的压缩强度,从而在大量削减冗余的同时,精准保留关键视觉信息。
该方法凝练了三大设计原则:模型适应性、帧独特性和高效算子兼容性。
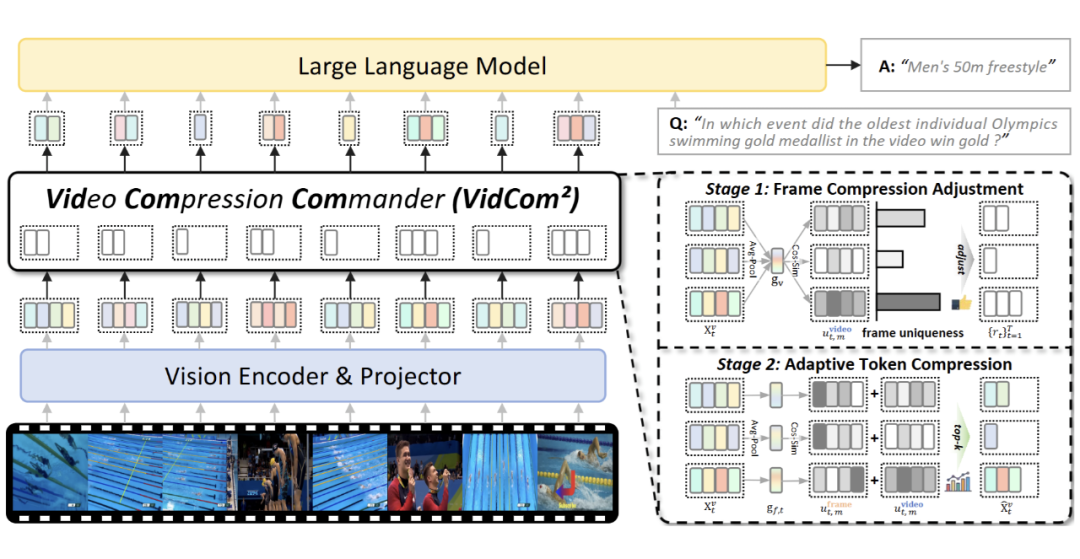 ▲ 图3. VidCom²整体框架
▲ 图3. VidCom²整体框架
VidCom²通过两个阶段完成视频Token的高效压缩:
- 帧级压缩调整:首先计算全局视频表示,然后通过余弦相似度度量每一帧与全局表示的差异,得出“帧独特性分数”。根据此分数,动态地为独特帧分配更高的Token保留预算,为冗余帧分配更低的预算。
- 自适应Token选择:在给定的帧级预算内,结合帧内特征分布,自适应地选择最具信息价值的视觉Token进行保留。
如图3所示,整个流程无需额外训练,可无缝集成到现有VideoLLM的推理流水线中,并天然兼容Flash Attention,确保计算高效。
 ▲ 图4. 帧独特性可视化(柱高与颜色深度代表独特性分数)
▲ 图4. 帧独特性可视化(柱高与颜色深度代表独特性分数)
图4的可视化结果表明,VidCom²能够有效识别并对独特帧(如包含动作变化、新物体出现的帧)赋予高分,其分配策略与人类对视频关键内容的理解高度一致。
实验结果
研究在多个主流视频理解基准(如MVBench、MLVU、VideoMME)和多种VideoLLM(LLaVA-OV、LLaVA-Video、Qwen2-VL)上进行了验证。结果表明,VidCom²的性能显著优于DyCoke、SparseVLM、PDrop等基线方法。
- 精度保持:在LLaVA-OV-7B模型上,仅保留25%的Token时,模型性能可达原始模型的99.6%(对比DyCoke的87.0%);在更极端的15%保留率下,仍领先SparseVLM方法3.9个百分点。
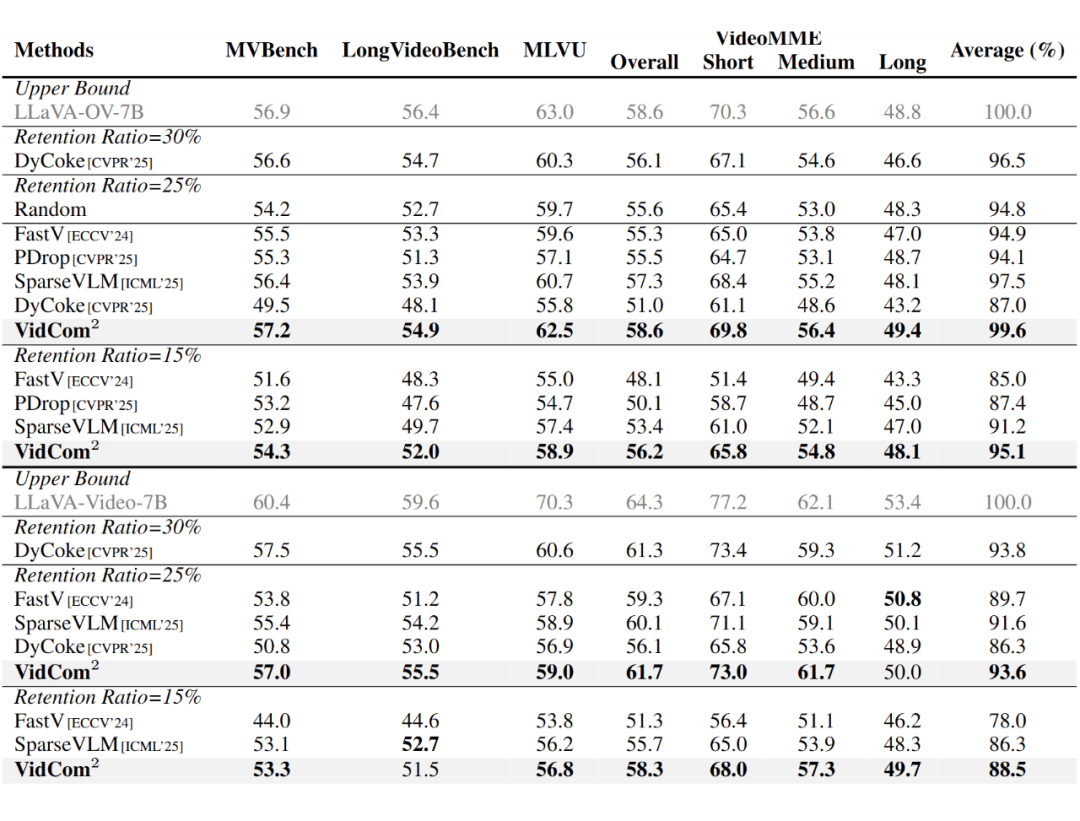 ▲ 图5. 在LLaVA系列模型上的性能对比
▲ 图5. 在LLaVA系列模型上的性能对比
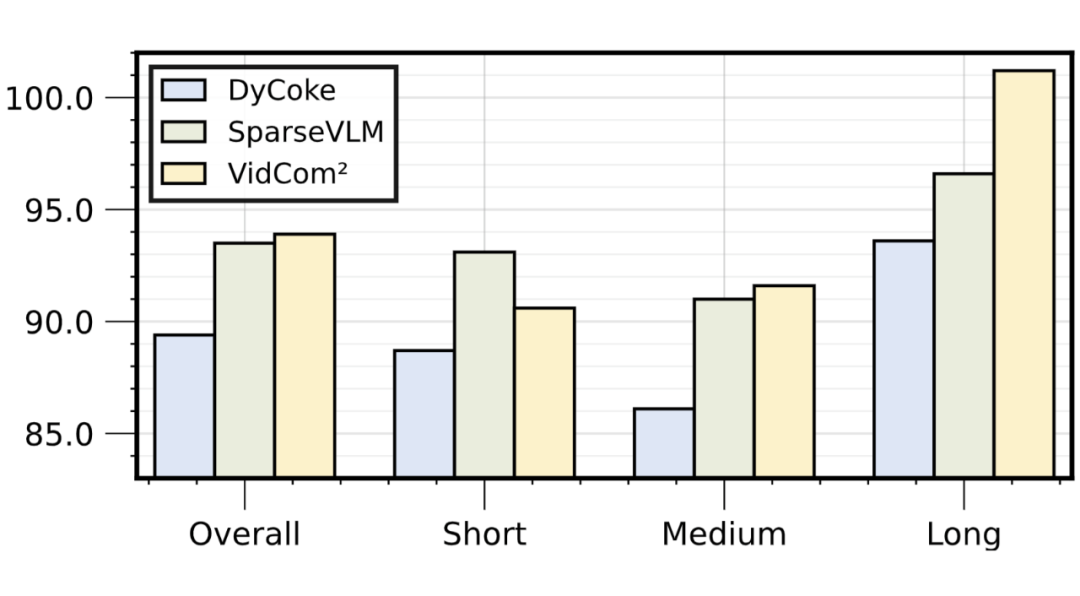 ▲ 图6. 在Qwen2-VL模型上的性能对比
▲ 图6. 在Qwen2-VL模型上的性能对比
-
效率提升:实际的延迟测试显示,VidCom²能将LLM生成阶段的延迟降低70.8%,吞吐量提升1.38倍。同时,得益于与Flash Attention的兼容性,峰值显存占用也得到优化。
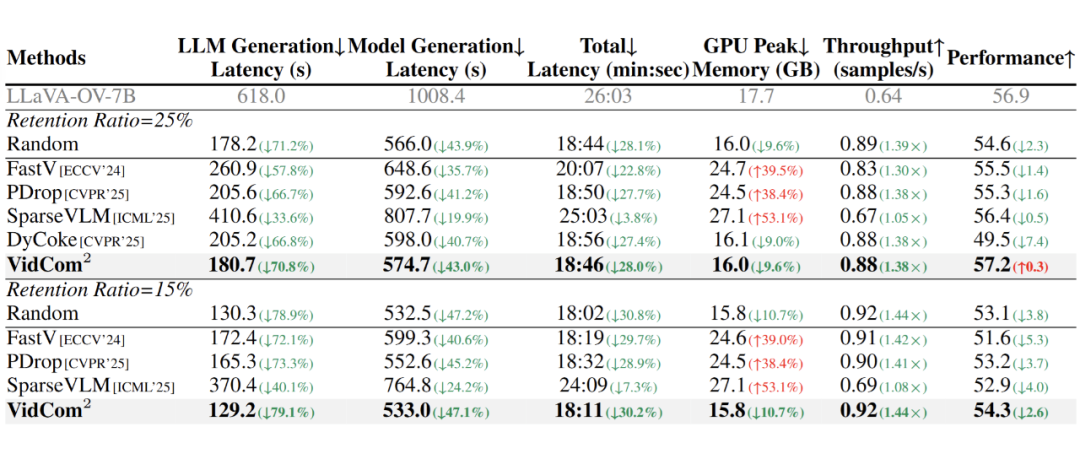 ▲ 图7. token压缩效率分析实验
▲ 图7. token压缩效率分析实验
-
泛化性与鲁棒性:VidCom²的帧级压缩调整机制可以作为一个通用模块,与其它Token压缩方法结合使用。如图8所示,将其应用于PDrop等方法后,在MVBench等多个基准上均能带来显著的性能提升。
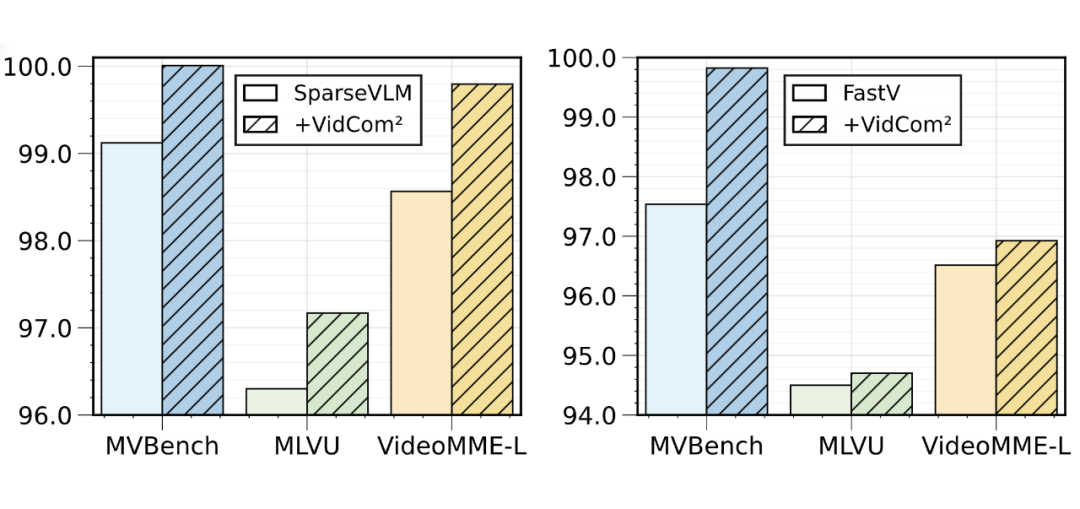 ▲ 图8. 与其它token压缩方法结合使用的效果
▲ 图8. 与其它token压缩方法结合使用的效果
总结
本文提出的VidCom²框架,为视频大语言模型的推理加速提供了一种新颖高效的即插即用解决方案。通过量化帧独特性并依此进行自适应的压缩强度调整,该框架在实现大幅度Token压缩(减少计算量)的同时,最大限度地保全了模型的理解能力。实验证明,其在精度、速度和泛化性上均优于现有方法,为实际部署高精度、低延迟的视频理解系统提供了新的技术范式。 |  发表于 2025-12-13 05:24:40
|
查看: 227|
回复: 0
发表于 2025-12-13 05:24:40
|
查看: 227|
回复: 0
