Google Scholar作为学术搜索与影响力评估的利器,其背后潜藏的系统性漏洞正使其沦为数据造假的温床。近期曝光的两起事件,揭示了利用预印本平台和生成式AI即可轻松操纵学术指标的灰色路径。
预印本成刷分捷径:两天10篇论文引用暴涨十倍
事件的核心是国内某顶尖高校的一位外籍博士后。公开记录显示,其2022年总引用为47次,2023年在100次左右。然而到了2024年,其引用曲线呈现异常陡峭的增长,迅速飙升至629次。
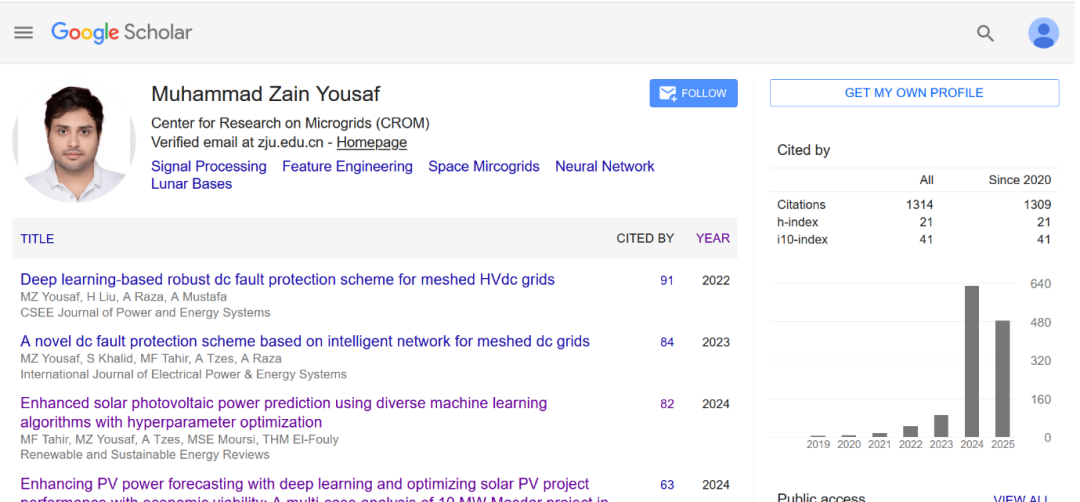 涉事博后2024年的引用量出现反常的垂直增长
涉事博后2024年的引用量出现反常的垂直增长
这一异常增长并非源于重磅研究成果,而是通过钻营IEEE旗下预印本平台TechRxiv的规则漏洞实现的。该研究者在两天内密集上传了10篇文档,内容经核查缺乏实质贡献。其操纵手法的关键在于参考文献列表:
- 其中5篇文档的参考文献列表中塞入了多达37条自引,几乎被其本人作品占满。
- 其余文档的自引率也高达三分之二。
这种赤裸裸的“刷单”行为,却成功骗过了Google Scholar的爬虫。尽管该账号最终被封禁,但漏洞已然暴露:预印本平台普遍缺乏严格的内容审核,为技术性刷分提供了近乎零成本的通道。
Google Scholar的机制缺陷:重收录而轻验证
为何如此明显的操作能轻易得逞?这与Google Scholar的设计理念有关。它优先追求文献的覆盖率,特别是对预印本几乎采取“来者不拒”的策略。爬虫会解析TechRxiv、ResearchGate等平台上的文档引用关系,但通常不会验证被引论文是否真实存在,也无法判断文档是否经过同行评审。
这一特性在作为检索工具时是优势,但在作为学术评价指标来源时则成了致命缺陷。一项针对全球前十高校教职员工的调查显示,超过60%的人在招聘或晋升评估中会参考引用数据,而Google Scholar是其首选数据源,使用率远超Scopus和Web of Science。
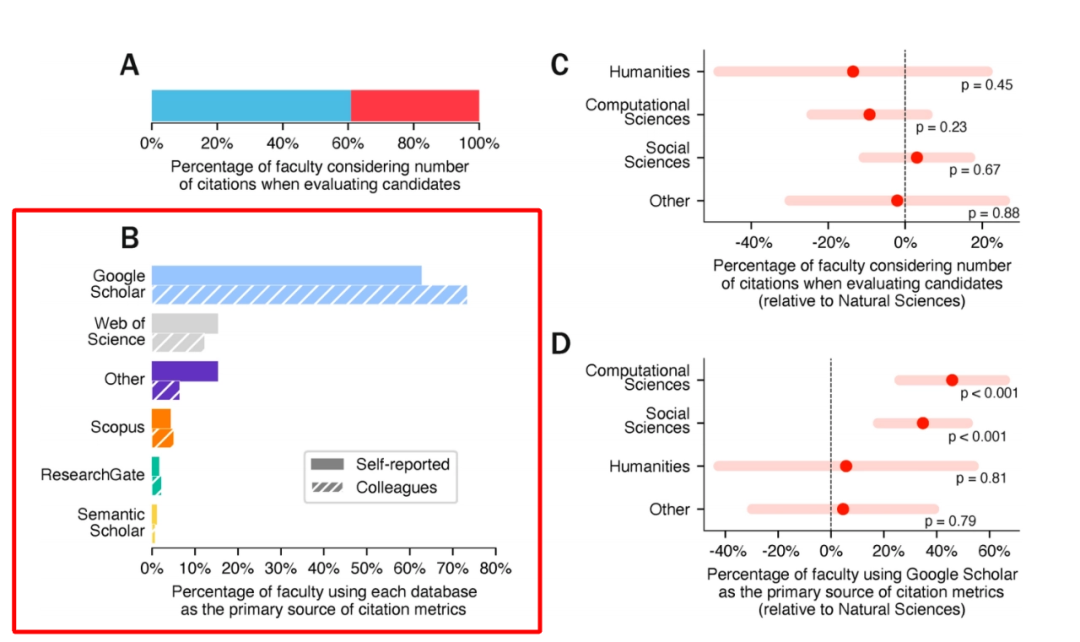 调查显示,在全球Top 10高校的招聘评估中,Google Scholar是使用率最高的工具
调查显示,在全球Top 10高校的招聘评估中,Google Scholar是使用率最高的工具
对比之下,审核机制更严格的Scopus数据库则像一面“照妖镜”。在上述事件中,异常账号在Scopus上的引用量相较于Google Scholar骤降96%,几近归零。而正常学者的数据在两个平台间则保持相对稳定。
进入AI时代:全自动脚本可批量伪造学术身份
手动上传效率低下,纽约大学的研究团队在《Scientific Reports》上发表论文,展示了利用生成式AI进行全自动化学术造假的完整流程:
- 虚构身份:创建一个不存在的作者及其所属机构。
- 批量生产:使用ChatGPT生成20篇主题为“假新闻”的论文,内容空洞,仅实现相互引用。
- 平台发布:将这些AI生成的论文上传至Authorea等预印本服务器。
结果令人震惊:Google Scholar毫无障碍地收录了所有这些论文,并据此为这个虚构人物计算出了380次引用和高达19的H-index,使其瞬间成为该细分领域的“权威学者”。更关键的是,即便原始预印本被删除,Google Scholar上的引用记录依然存在,形成了“查无对证”的局面。
渗透正规期刊:300美元购买50次引用
如果认为预印本不够“正式”,市场也提供了渗透正规期刊的渠道。研究团队通过暗访发现,存在所谓的“引用工厂”服务。仅需支付约300美元,即可购买50次引用。
与预印本刷分不同,这类购买服务的影响更为深远。团队购买的50次引用,最终出现在了5篇发表于正规期刊的论文中,其中4篇被Scopus收录。通过对引用网络的拓扑分析,可以发现明显的“引用卡特尔”特征:多篇论文相互密集引用,并非服务于单一客户,而是为多个“金主”进行批量化刷分,在图中形成显著的高密度聚类。
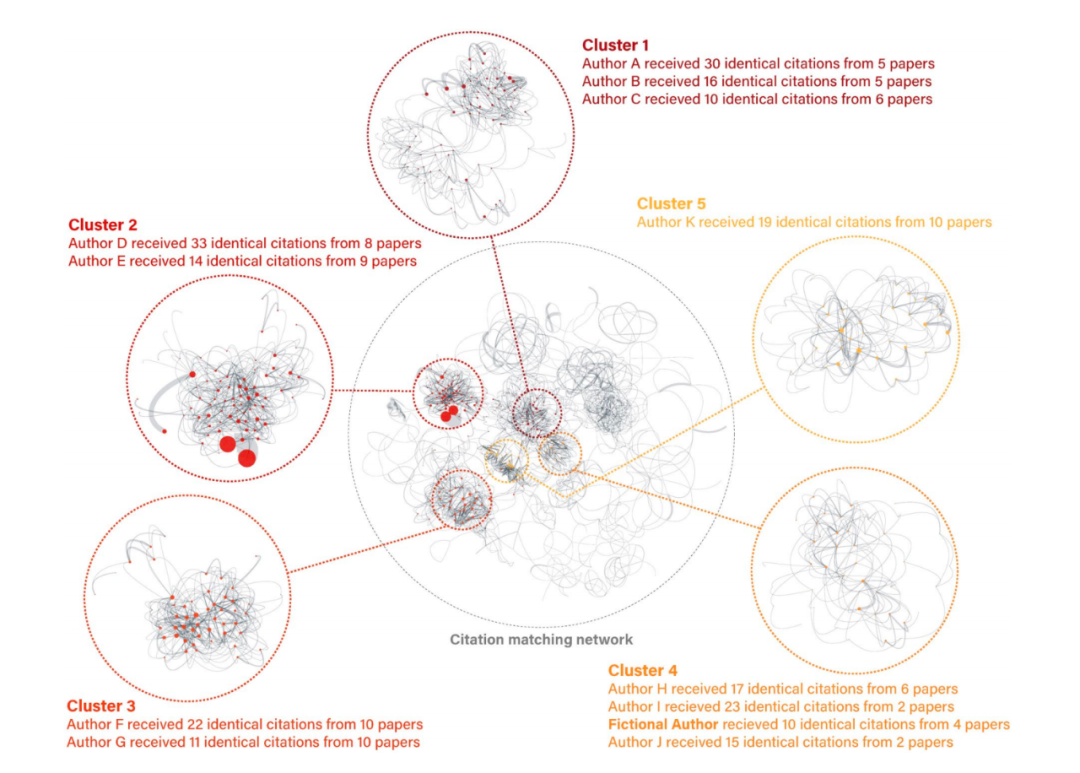 引用网络拓扑图揭示出潜藏在正规期刊背后的“引用卡特尔”
引用网络拓扑图揭示出潜藏在正规期刊背后的“引用卡特尔”
总结与反思:学术评价应回归质量本身
当虚构身份能借由AI轻松获得可观的H-index,当几百美元就能撬动正规期刊的引用数据时,我们不得不重新审视以Google Scholar数据为代表的量化指标的可靠性。
Google Scholar的便利性无可替代,但其对预印本和AI生成内容的无差别收录机制,无疑将学术不端的门槛降至历史低点。对于依赖此类数据进行人才筛选的招聘委员会和学术机构而言,是时候建立更审慎、多维的评估体系了。若继续单纯迷信冰冷的引用数字,未来脱颖而出的可能并非潜心研究的科学家,而是精通系统漏洞与操作规则的“策略家”。
|  发表于 2025-12-13 05:22:37
|
查看: 179|
回复: 0
发表于 2025-12-13 05:22:37
|
查看: 179|
回复: 0
