
在量化投资领域,动量策略(Momentum Investing) 无疑是经过时间检验最久的因子之一。自Jegadeesh和Titman于1993年发表那篇经典研究以来,动量效应被反复验证,并成为众多系统化投资组合的核心基石。然而,一个始终困扰研究者与机构投资者的问题是:在信息高度透明、市场反应速度日益加快的今天,传统动量策略还能持续创造超额收益吗?
来自Finreon AG、圣加仑大学以及瑞士金融研究所的研究者Nikolas Anic等人在其最新论文 “ChatGPT in Systematic Investing, Enhancing Risk-Adjusted Returns with LLMs” 中,给出了属于新时代的答案:大型语言模型(LLMs)正在为传统动量策略注入新的信息优势。

研究问题
这项研究旨在探究一个核心问题:像ChatGPT这样的大型语言模型,能否在一个真实、可执行的投资框架内,切实提升动量策略的风险调整后收益?
其研究逻辑其实很清晰。大量金融学文献表明,动量效应与市场对信息的“渐进式吸收”过程紧密相关。无论是财报公布后的价格漂移,还是公司层面的重大公告,价格往往不会在信息出现的第一时间就完全反映所有内容。真正的挑战在于,如何有效地区分“那些真正会推动趋势延续的新闻”与大量噪音化、短暂的市场信息。
传统的文本分析方法多依赖于情绪词典、关键词计数或监督学习模型,对复杂语境的理解能力有限。而大型语言模型的优势恰恰在此:它能够结合上下文,对新闻内容进行整体的语义判断,并在给定的决策框架下输出概率性的评估结果。
实验验证
数据与研究设计
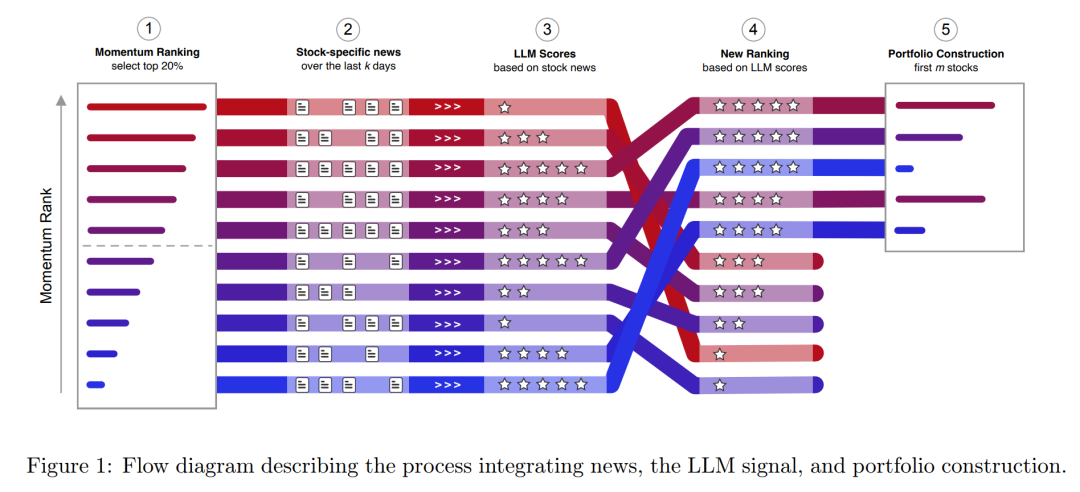
为了验证这一构想,研究团队构建了一个高度贴近真实投资环境的测试框架,整合了三类关键数据源。
首先是股票收益数据。样本覆盖 2019年10月至2025年3月 期间的 S&P 500成分股日度收益率,用于构建标准的横截面动量信号。
其次是高频新闻数据。研究使用了Stock News API,获取来自 CNBC、Bloomberg、Zacks、The Motley Fool、Fox Business、The Street 等主流媒体的公司层面新闻,时间戳精确到秒级。仅在2024年,年度新闻条数就超过了 200,000条,这本身就凸显了人工处理海量信息的极高难度。
第三个关键组件是 ChatGPT 4.0 mini。研究者并未对模型进行任何微调,而是通过精心设计的提示词(prompt),让模型在“某只股票即将进入动量组合”的明确决策语境下,对相关新闻进行解读,并输出一个 0到1之间的分数,用以表示该模型对“动量延续”可能性的支持程度。
AI在这里到底做了什么?
与许多人想象的简单“情绪分析”不同,此处的LLM扮演的是 新闻解释器(news interpreter) 的角色。
在每次投资组合调整之前,研究者会将某只候选股票最近 1个交易日(或其他测试时间窗口)内的全部相关新闻输入模型,并明确告知模型:
- 该股票已因其过去12个月(剔除最近1个月)的表现而进入动量候选池。
- 当前任务是判断这些新闻是否支持其在未来 21个交易日 内的趋势延续。
模型输出的分数不仅用于 对股票进行重新排序,还会进一步用于 倾斜投资组合的权重。在最优参数配置下,权重倾斜系数高达 η = 5,这意味着模型的判断在资金配置决策中具有实质性的影响力。
测试框架与样本切分
为避免过拟合,研究将样本划分为两个阶段:
- 验证期(Validation Set):2019年10月至2023年12月,用于在 512种参数组合 中寻找最优策略配置。
- 测试期(Test Set):2024年1月至2025年3月,进行完全样本外的策略评估。
一个至关重要的细节是:ChatGPT 4.0 mini的训练数据截至2023年10月。这意味着测试期内的所有表现结果,并非源于模型“记住了”历史事件,而是完全依赖其语言理解与逻辑推理能力在新信息上的应用。
实验结果
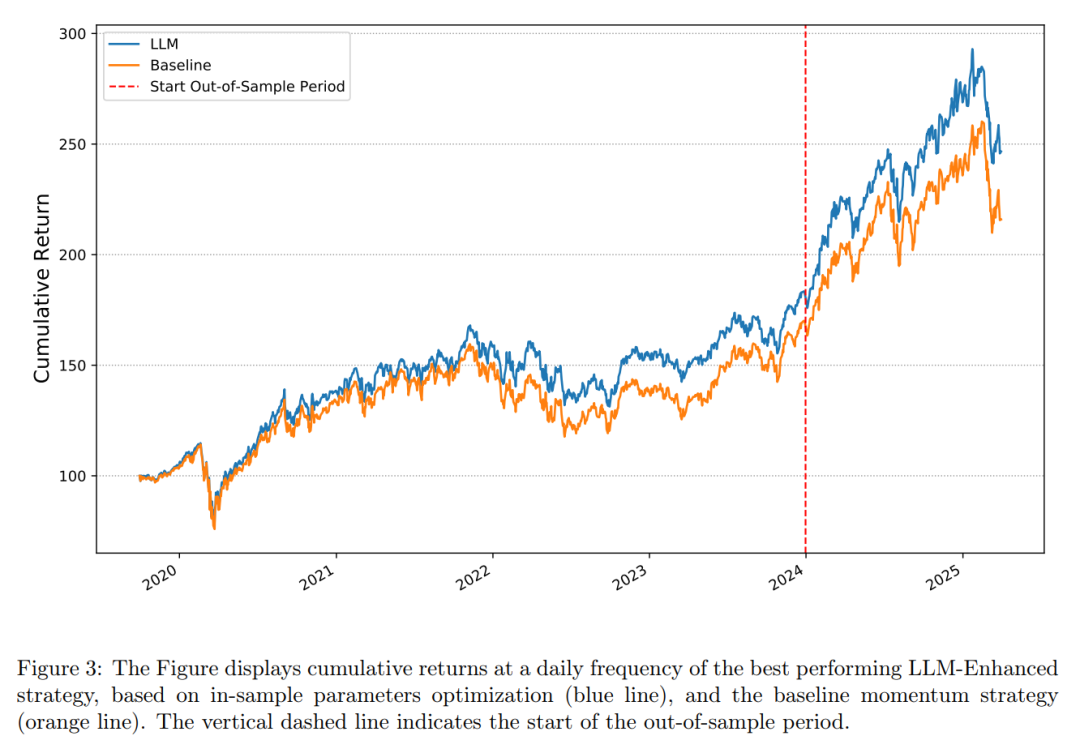
在 全样本 中,经LLM增强后的纯多头动量策略表现如下:
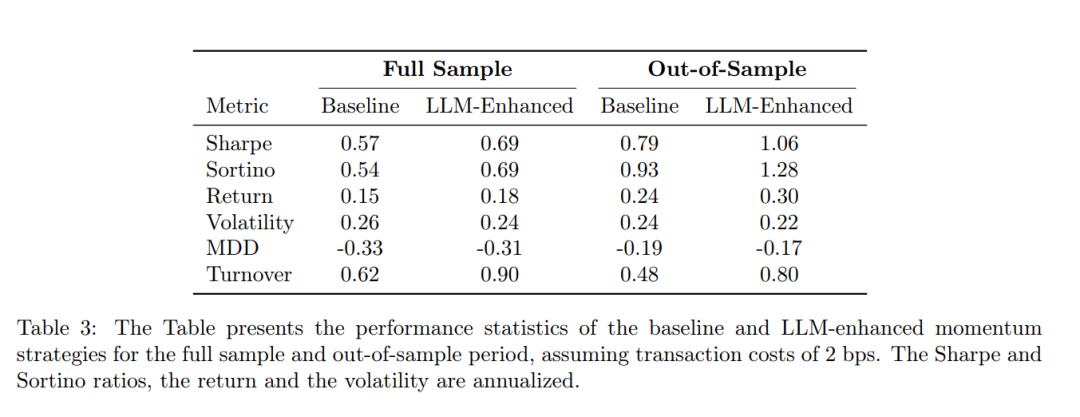
需要重点强调的是,所有展示的结果均已计入 每笔交易2个基点(bps)的交易成本,并且属于历史回测的假设性结果,并不代表任何实际投资者的真实收益。
研究分析
样本外表现
论文中一个值得关注的现象是:策略在样本外阶段的表现并未弱化,反而有所增强。
如果LLM的有效性主要来源于其训练数据中所包含的历史信息模式,那么在2024年之后(即模型训练数据截止日期之后),其带来的边际贡献理论上应该下降。然而,实证结果并未支持这一假设。研究者据此认为,模型带来的增量价值更可能源于其对新闻语义与股价趋势之间关系的 实时解释与推理能力。
从这一视角看,LLM所提供的并非简单的历史模式复现,而是一种基于动态语境的语义筛选与评估机制。
稳健性检验与现实约束
研究进一步在多个维度上检验了策略的稳健性,包括:
- 不同复杂度的提示词设计
- 不同的投资组合规模(25、50、75、100只股票)
- 不同的组合调仓频率
- 是否设置单只股票持仓上限
- 等权重与市值加权的初始配置方式
在上述各种设定下,策略整体上仍然保持了正向的风险调整后表现,这表明研究结论并非依赖于某一种特定的参数配置。
其他发现
首先,简化的提示词在表现上并不逊色于复杂的提示词,这表明模型在此项特定任务中,并不依赖高度精细和复杂的指令结构。
其次,月度调仓的表现显著优于周度调仓,这再次强调了交易成本在系统化策略中的关键影响。
第三,投资组合的集中度越高,LLM信号带来的边际贡献就越明显。在仅包含25只股票的高度集中组合中,夏普比率(Sharpe Ratio)接近 1.3,而在包含100只股票的组合中约为 0.95。这显示出模型更适合用于筛选高确信度的投资机会。
最后,采用市值加权配置的表现优于等权重配置,这与大型上市公司通常拥有更丰富、更持续的新闻覆盖特征相符,但也可能部分反映了样本期内超大型股票(mega-cap)的结构性强势表现。
结语
总体而言,这项研究表明,大型语言模型可以在现有的系统化投资框架内,作为一种可扩展的信息解释工具,为传统的动量策略提供可量化的增量价值。这一结论并未颠覆动量策略的基本逻辑,而是清晰地展示了在信息处理层面引入先进AI技术所蕴含的潜在收益空间。
对于关注量化投资前沿动态的开发者与研究者而言,这项研究提供了一个将人工智能与经典金融理论相结合的生动范例。欢迎访问云栈社区获取更多深度技术解析与行业洞见。
 发表于 2026-1-25 03:21:51
|
查看: 216|
回复: 0
发表于 2026-1-25 03:21:51
|
查看: 216|
回复: 0
