在大模型的发展进程中,强化学习已从一项辅助技术,跃升为驱动模型能力跃迁的核心动力。当前,RL发展正经历一场关键范式转移:从单轮、静态任务(如独立的数学题求解等),全面转向多轮、交互式智能体训练。这一新范式的目标,是让大模型真正成为能在复杂、动态环境中,通过多步观察、思考、行动与反馈来完成任务的Agent。这不仅是技术上的巨大挑战,更是通往AGI的关键一步。总而言之,强化学习正在重塑大模型的能力边界。它不仅是弥补数据瓶颈的利器,更是构建下一代通用智能体的核心方法论。而支撑这一切的,正是背后日益成熟和强大的RL基础设施生态。本文结合相关文献,对现有主流RL库进行简单整理。
现代RL基础设施的架构范式
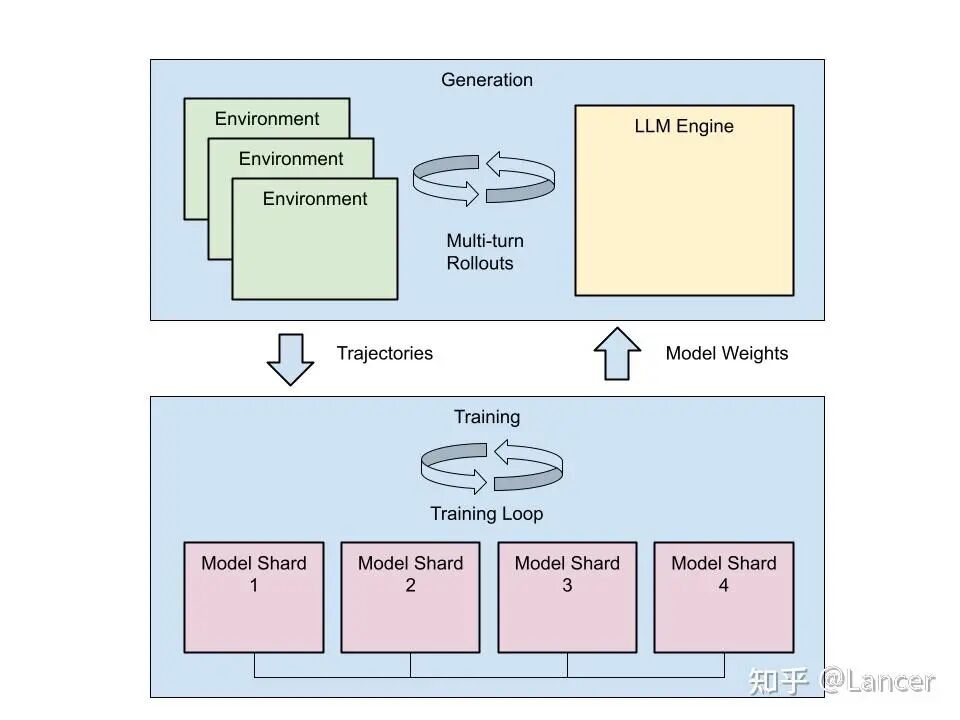
现代RL基础设施的核心通常围绕以下两个基本组件展开。
-
Generator:负责让LLM与环境交互,生成Trajectory并计算奖励。这是计算开销特别大的部分,其设计灵活性(如是否支持自定义采样、分支搜索)和环境抽象能力至关重要。
-
Trainer:负责根据生成阶段收集的轨迹数据,使用优化算法(主要是PPO和GRPO等)更新模型参数。其性能取决于所采用的分布式训练后端(如FSDP, DeepSpeed, Megatron)。
上述的生成器-训练器架构,配合以Ray为代表的分布式协调层,构成了大模型强化学习系统的“黄金标准”。RL 训练计算成本极高,涉及上述大规模并行推理和参数更新。一个优秀的 RL 库必须能高效、稳定、可扩展地协调这两个阶段。
本文梳理了支撑大规模RL for LRM(Large Reasoning Models)训练的软件栈和工程框架,并将RL基础设施分为两大类:Primary Development和 Secondary Development。
Primary Development
这些是构建RL训练管线的“基石”框架。它们通常不直接提供完整的端到端解决方案,而是提供核心的算法实现和与底层训练/推理引擎的集成,供研究者和工程师在此基础上进行定制化开发。
定位:Hugging Face官方推出的、最“开箱即用”的RL框架。它更像是一个“训练器集合”,而非一个复杂的分布式系统。
https://github.com/huggingface/trl
核心能力:
- 算法支持:SFT, PPO, DPO, GRPO, IPO, KTO, Online DPO, REINFORCE++ 等。
- 集成:紧密集成 transformers 库,支持与 vLLM 的集成以加速Rollout。
- 训练后端:依赖accelerate 库,支持 DDP, DeepSpeed ZeRO, FSDP。
- 特点:API设计简洁,文档丰富,非常适合快速原型验证和中小规模实验。但对于超大规模、异步、多智能体等复杂场景支持有限。但是不支持环境交互,并且生成与训练耦合紧。
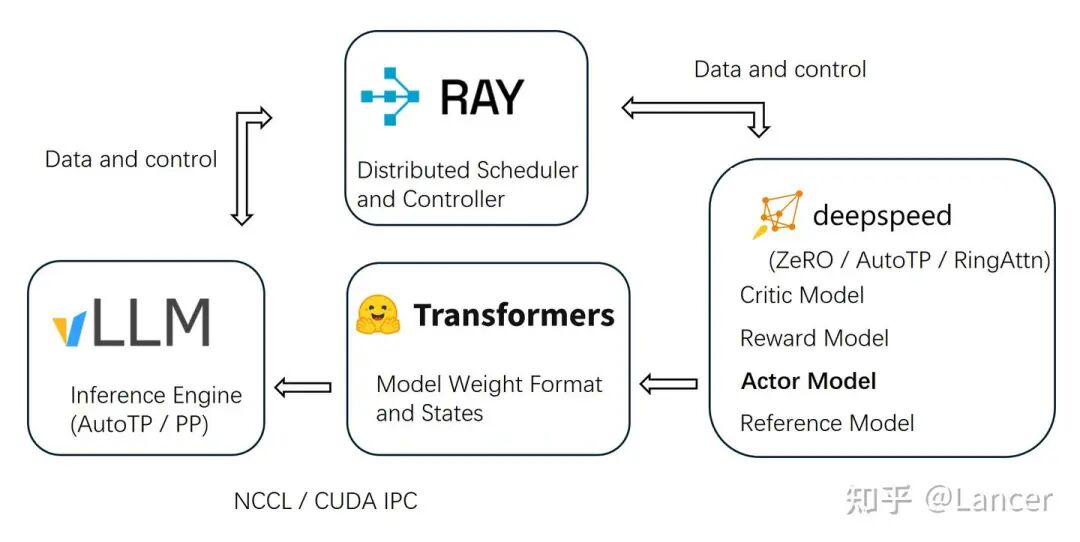
2. OpenRLHF
定位:由OpenLLMAI,字节,网易等的一个联合团队开发,旨在提供一个高效、可扩展的RLHF和Agentic RL框架。
https://github.com/OpenRLHF/OpenRLHF
核心能力:
- 算法支持:PPO, GRPO, REINFORCE++, RLOO, DPO, IPO, KTO 等。
- 架构:支持异步Pipeline RLHF和异步Agentic RL模式。后者通过Agent 类API支持多轮对话。
- 集成:深度集成 vLLM 用于高吞吐Rollout。
- 训练后端:基于 DeepSpeed ZeRO-3 + Auto Tensor Parallelism (AutoTP)。
- 特点:代码结构清晰,是许多二次开发框架的基础。
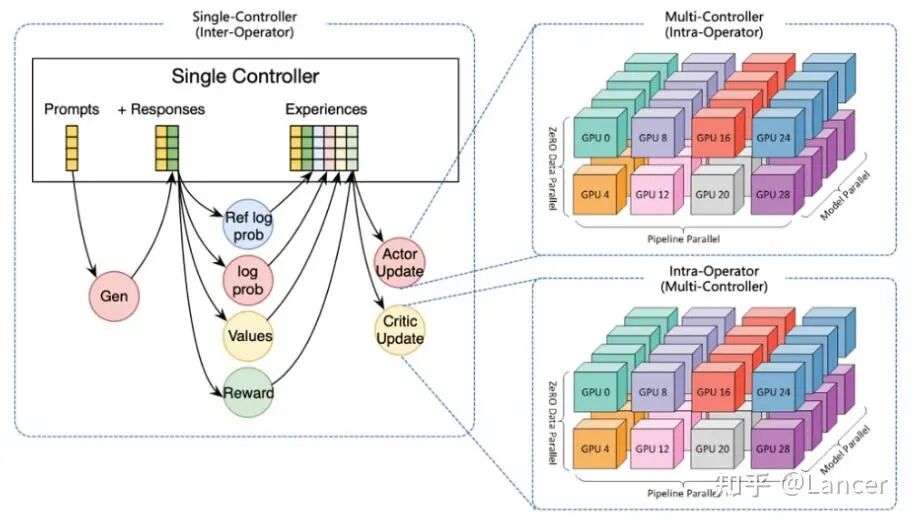
3. veRL
定位:功能最全面、算法支持最广泛的框架之一,由字节Seed团队开发。
https://github.com/volcengine/verl
核心能力:
- 算法支持:极其丰富,包括 PPO, GRPO, GSPO, ReMax, REINFORCE++, RLOO, PRIME, DAPO, DrGRPO 等。
- 架构:采用 HybridFlow 控制器,支持多轮训练和工具调用,目前生成与训练耦合,后续规划会支持异步解耦。
- 集成:支持 vLLM 和 SGLang 等作为推理后端。
- 训练后端:同时支持 FSDP/FSDP2和 Megatron-LM。
- 奖励:支持模型奖励和函数/规则奖励(如数学/代码)。
- 特点:追求“全能”,几乎涵盖了当前所有主流RL算法和应用场景。是进行前沿算法研究和复杂任务(如多模态、多智能体)实验的理想选择。相比 TRL/OpenRLHF等,配置更复杂。
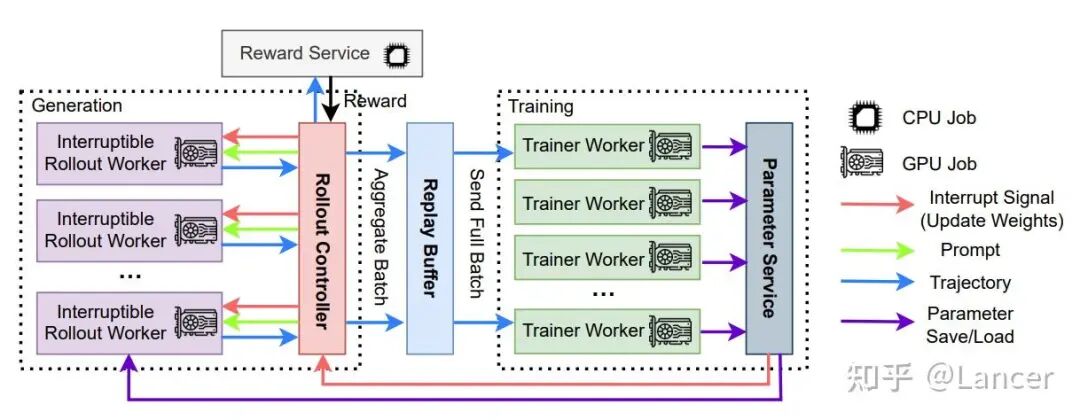
4. AReaL (Asynchronous Reinforcement Learning)
定位:蚂蚁开源,专为大规模、高吞吐的推理模型RL训练而设计,核心是完全异步架构。
https://github.com/inclusionAI/AReaL
核心能力:
- 架构:核心创新是完全异步设计。通过可中断的Rollout Worker、经验回放缓冲区和并行奖励服务,将生成与训练彻底解耦。
- 集成:使用 SGLang等 进行Rollout,并使用Ray进行集群管理。
- 训练后端:主要使用 PyTorch FSDP,也支持 Megatron。
- 特点:为追求极致训练效率和可扩展性而生。其“轻量版” AReaL-lite 提供了更易用的API。
5. NeMo-RL (NVIDIA NeMo)
定位:NVIDIA官方推出的、面向生产的RL框架,集成在其庞大的NeMo生态系统中。
https://github.com/NVIDIA-NeMo/RL
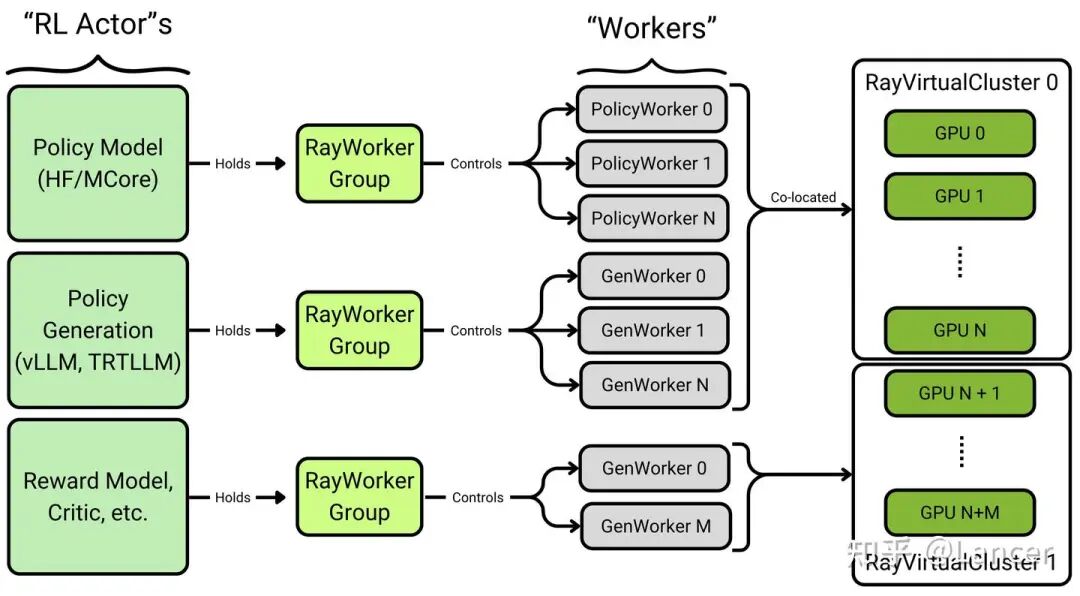
核心能力:
- 算法支持:SFT, DPO/RPO/IPO/REINFORCE, PPO, GRPO 等。
- 架构:强调可扩展性和生产级编排,支持异步 Rollout,非Colocate放置等。
- 训练后端:支持 Megatron-Core和DTensor (FSDP2)。
- 集成:支持使用 TensorRT-LLM 和 vLLM 进行rollout。
- 特点:与NVIDIA硬件(GPU)和软件栈(CUDA, TensorRT)深度集成,提供了从RM训练到PPO的端到端Pipeline。设计优雅,接口定义清晰,性能和扩展性兼顾。
6. ROLL (Reinforcement Learning Optimization for Large-Scale Learning)
定位:阿里开源的,一个专注于大规模LLM RL的框架,同样强调异步和Agentic能力。
https://github.com/alibaba/ROLL
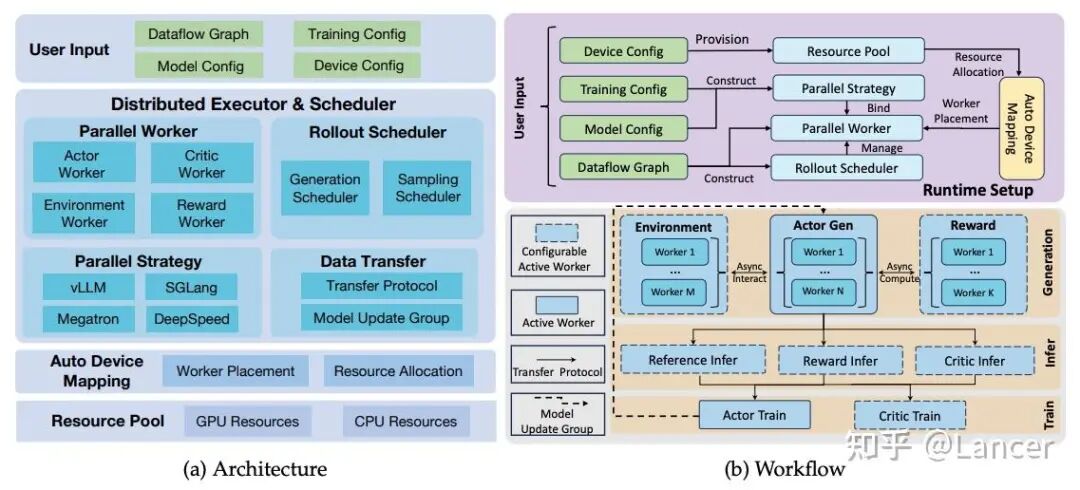
核心能力:
- 算法支持: 集成了 GRPO, PPO, REINFORCE++, TOPR, RAFT++, GSPO 等多种先进 RL 算法。
- 架构: 采用基于 Ray 的多角色分布式设计,将策略生成、价值评估、奖励计算等任务解耦到独立的 Worker 角色中,实现灵活的资源调度、异步训练和复杂任务编排。
- 集成: 深度集成 SGLang 和 vLLM 作为高性能推理后端,加速策略生成(Rollout)。
- 训练后端: 主要基于 DeepSpeed (ZeRO) 和 Megatron-LM (5D 并行),未来将支持 FSDP2。
- 奖励: 通过模块化的“奖励工作者”(RewardWorker)处理奖励计算,支持验证器、沙盒、LLM-as-judge 等多种奖励源,构建灵活的奖励路由机制。
- 特点:面向多样化用户,高度可配置,接口丰富。
7. slime (SGLang-native post-training framework for RL scaling)
定位:清华,智谱开源的一个轻量级、专注于将 SGLang 与 Megatron 无缝连接的框架。
https://github.com/THUDM/slime
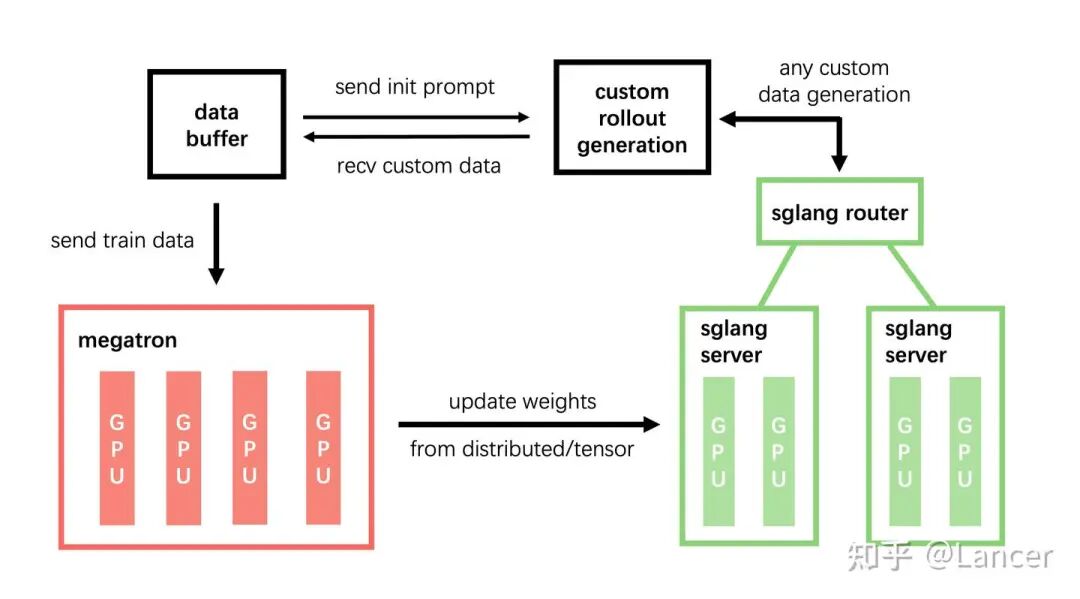
核心能力:
- 架构:Ray 进行资源管理和分布式任务调度,Rollout和训练解耦。
- 训练后端:默认使用 Megatron-LM,也支持FSDP和xtuner。
- 特点:通过自定义数据生成接口和服务端引擎(server-based engine),slime 可以实现任意的训练数据生成流程。支持异步训练和Agentic工作流。追求极简主义与高性能。
除论文中总结的,还有其他的强化学习库:
SkyRL (UC Berkeley)
https://github.com/NovaSky-AI/SkyRL
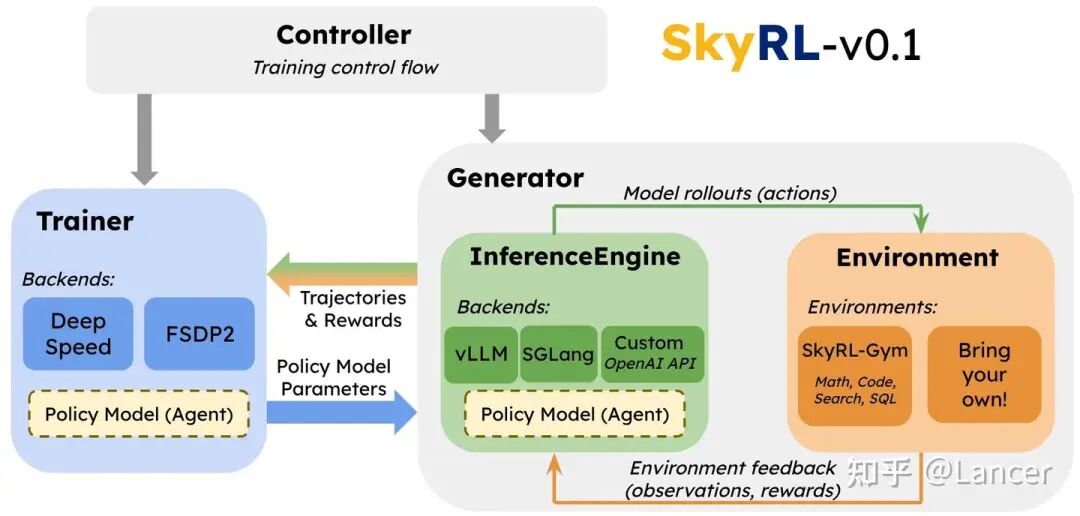
定位:追求设计灵活性和未来兼容性的新锐选择。支持同步/异步、Colocate/解耦、外部/内置推理,接口灵活,但生态未成熟,社区支持弱于 Verl/OpenRLH等。
RAGEN(Northwestern University )。
https://github.com/RAGEN-AI/RAGEN
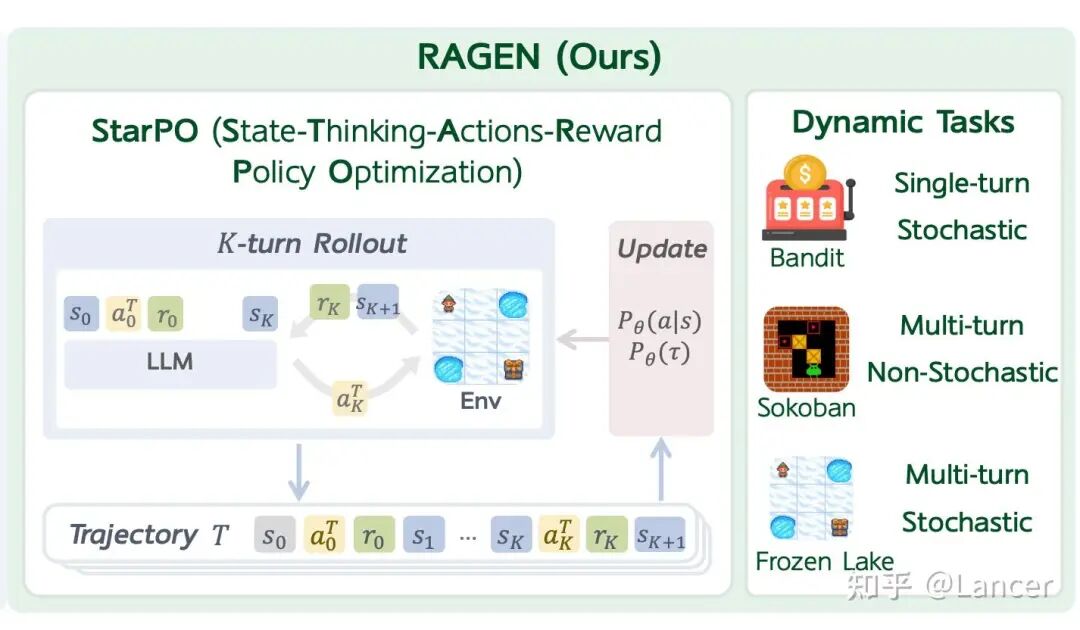
定位:基于Verl构建,旨在为其添加更明确的环境接口和更好的智能体/多轮RL支持,生态尚在成长中。
Verifiers(William Brown等人):用于构建自定义多轮交互协议的强化学习环境框架,专为 LLM 的评估、训练和数据生成而设计。
定位:TRL 的升级版,基于 HF Trainer + 增加多轮环境交互,支持vLLM等。轻量灵活,适合快速原型 Agentic 实验。代码结构清晰,易修改。
https://github.com/willccbb/verifiers
Miles(RadixArk team): 专为大规模 MoE 模型设计的企业级RL训练框架,基于轻量级 RL 框架 slime 升级而来,聚焦于生产环境下的稳定性、可扩展性和训练-推理一致性。
定位:提供高可靠性、可扩展性和生产级稳定性的大型MoE模型RL,支持最新硬件(如 GB300)。主要特性包括: True on-policy 、内存优化(OOM 防护、FSDP 改进、offloading 支持)、Speculative Training等。后端支持Megatron-LM,FSDP等。
https://github.com/radixark/miles
Secondary Development
这些框架通常是基于上述主干框架(尤其是 veRL)构建的,针对特定的下游应用场景(如多模态、多智能体、GUI自动化)进行了深度定制和功能扩展。
1. Agentic RL (智能体强化学习)
背景:Agentic RL的核心挑战是模型需要与外部环境(如搜索引擎、Python解释器等)进行多轮、异步的交互。这要求框架支持动态工作流和状态管理。
框架:
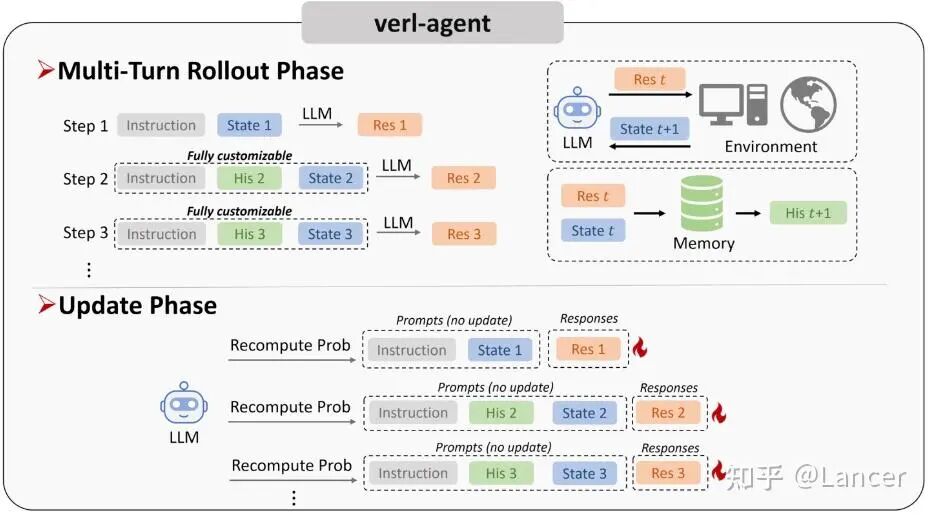
- verl-agent:基于 veRL构建,专门为Agentic RL优化,支持异步Rollout和训练。
https://github.com/langfengQ/verl-agent
- agent-lightning:实现了训练与推理的解耦,更容易支持多智能体训练。
https://github.com/microsoft/agent-lightning
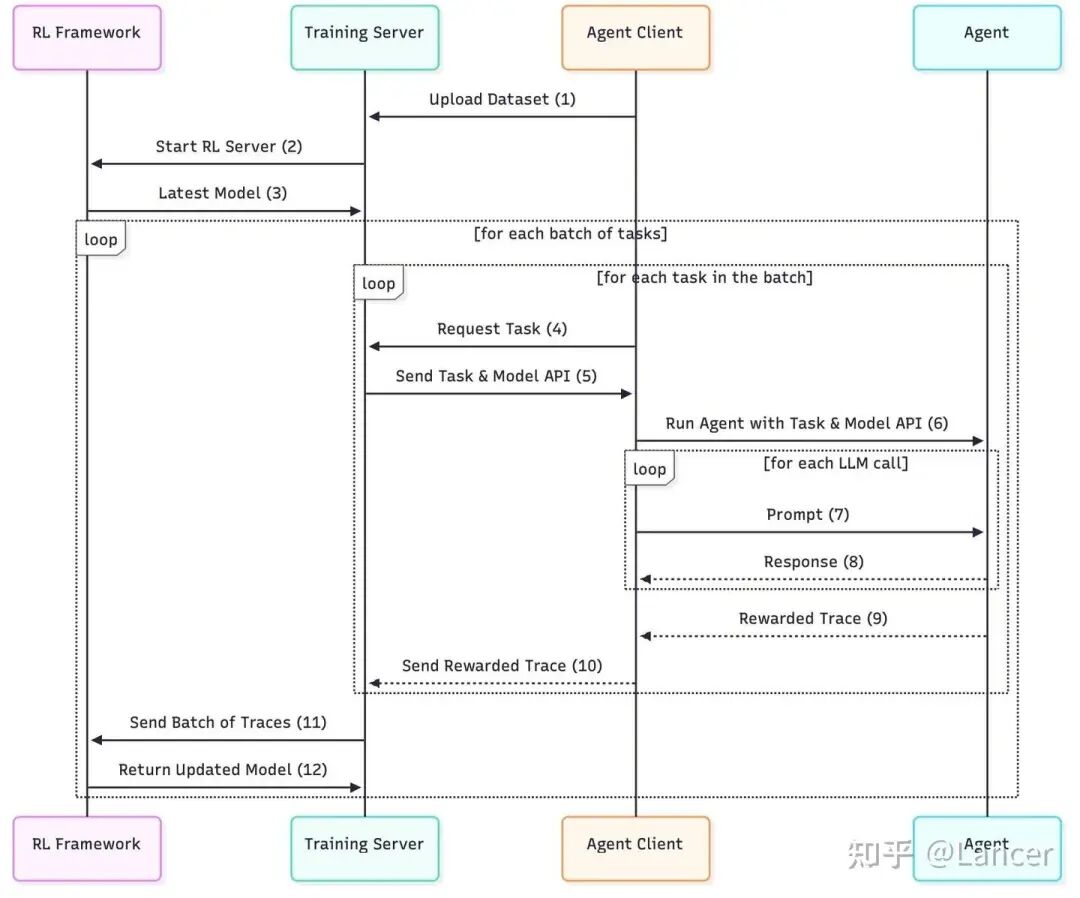
关键技术:异步生成、经验回放、环境接口标准化。
2. Multimodal RL (多模态强化学习)
背景:将RL应用于视觉-语言模型(VLM)。主要挑战在于数据处理(图像/视频编码)和损失函数设计(如何对齐文本和视觉信号)。
框架:
- VLM-R1和 EasyR1:基于 veRL开发,用于训练视觉-语言推理模型。
https://github.com/om-ai-lab/VLM-R1
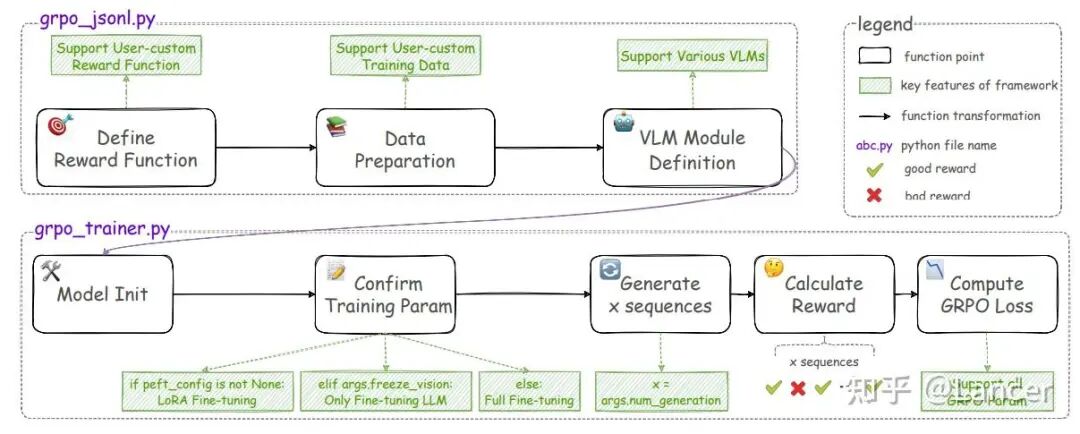
- DanceGRPO:专门用于扩散模型(如文生图)的RL训练。
https://github.com/XueZeyue/DanceGRPO
关键技术:多模态数据加载器、跨模态奖励设计(如CLIP分数)、针对扩散模型的特殊采样策略(ODE/SDE转换)。
3. Multi-Agent RL (多智能体强化学习)
背景:训练多个LLM智能体进行协作或竞争。挑战在于Credit Assignment和通信协调。
框架:
- MARTI:论文作者团队(清华C3I)提出的首个高性能、开源的LLM多智能体强化训练与推理框架。通过统一框架整合多智能体推理与强化学习,结合高性能引擎与灵活架构,为复杂协作任务提供高效、可扩展的解决方案。兼容单智能体RL框架(如 OpenRLHF、veRL),支持vLLM。
https://github.com/TsinghuaC3I/MARTI
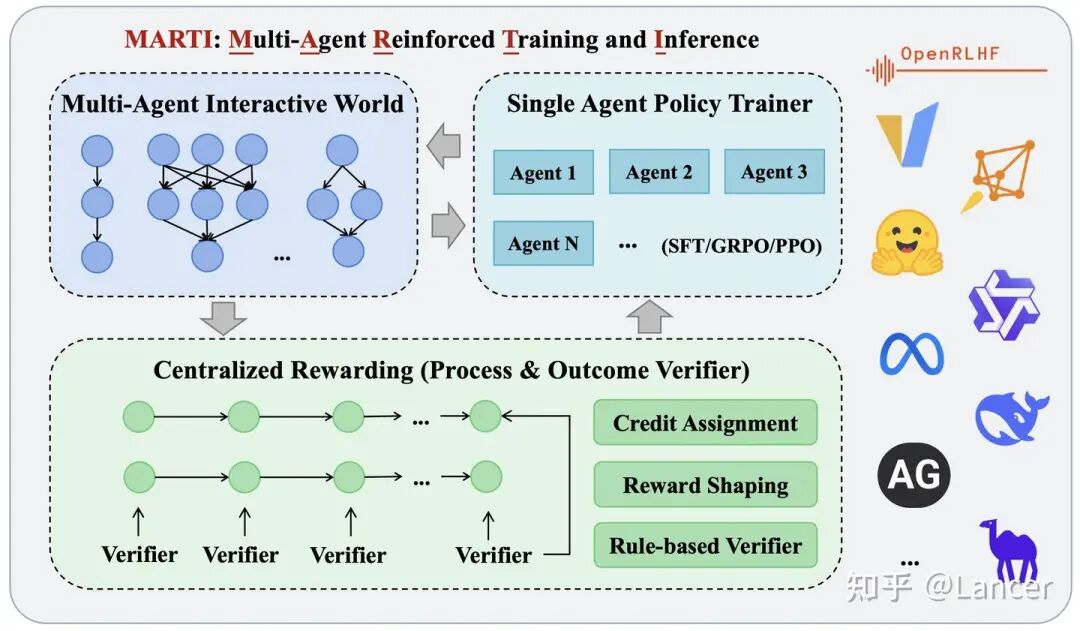
- Agent-Lightning:其解耦设计也便于扩展到多智能体场景。
关键技术:集中训练分散执行(CTDE)、基于自然语言的信用分配(如LLaMAC)、多智能体策略优化(如MAGRPO)。
总结与趋势
- 标准化与模块化:RL基础设施正从“手工作坊”走向“标准化流水线”。框架设计越来越模块化,将Rollout、Reward、Train等环节解耦,便于复用和扩展。比如,库不再绑定单一推理后端,而是支持 vLLM、SGLang等。
- 异步化是王道:为了应对Rollout和Train之间巨大的计算不对称性,异步架构(AReaL, OpenRLHF, slime等)已成为大规模RL的必备特性。
- 推理引擎至关重要:vLLM和 SGLang等高性能推理引擎的出现,极大地加速了Rollout过程,成为现代RL框架的标配。
- 从 RLHF 向 Agentic RL 演进:早期的库(如 TRL等)主要为单步任务设计。新一代库都内置了强大的环境抽象,以支持复杂的多步交互。
- 分布式训练框架选择:Megatron-LM 在超大规模模型训练中性能最佳,FSDP/FSDP2 因与 PyTorch 集成好而广受欢迎,DeepSpeed 则在内存优化上表现出色。成熟的库通常会支持多种方案。
- 场景驱动的二次开发:通用框架(如 veRL, OpenRLHF)为生态奠定了基础,而针对特定场景(多模态、多智能体、GUI)的二次开发框架则在解决垂直领域的独特挑战。
- Orchestrator重要性:由于 RL 涉及多个分布式组件(训练框架、推理框架、环境),使用 Ray等进行任务编排、资源管理和容错已成为行业共识。
总而言之,RL Infra是推动大型推理模型发展的“幕后英雄”。选择合适的框架,可以事半功倍,让研究者和工程师能够更专注于算法和数据本身,而非底层的工程细节。随着RL for LRM领域的持续火热,我们可以预见,这些基础设施将变得更加成熟、高效和易用。想要深入探讨这些前沿技术,欢迎访问云栈社区与更多开发者交流。
参考文献
Kaiyan Zhang et al. A Survey of Reinforcement Learning for Large Reasoning Models .2025
 发表于 2026-1-22 23:34:32
|
查看: 193|
回复: 0
发表于 2026-1-22 23:34:32
|
查看: 193|
回复: 0
