当我们最初接触强化学习时,往往会从 Bellman 方程、价值函数、动态规划这些经典概念学起,然后是时序差分、Q-learning 乃至 DQN。如今,随着强化学习走进大模型时代,它的核心角色与形态发生了微妙却深刻的转变。今天围绕大模型展开的强化学习(如 RLHF、RLAIF),其理论基石已经悄然发生了变化。
下面,我们就来梳理一下这场从数学基础到工程实践的演变历程。
一、Bellman:强化学习的数学原点
一切都要从 Bellman 方程这个“第一性原理”开始:
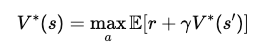
它揭示了一个核心的递归结构:
最优价值函数是 Bellman 算子的不动点。
这构成了强化学习最坚实的数学骨架。其内涵包括:
- 价值递归:当前状态的价值依赖于后续状态的价值。
- 期望结构:需要对环境转移和奖励取期望。
- 不动点性质:最优解满足自我一致性条件。
- 收缩映射:保证了迭代求解的收敛性。
可以说,如果说强化学习有一条“物理定律”,那就是 Bellman 方程。
二、动态规划:模型已知的精确求解
当环境模型(转移概率、奖励函数)完全已知时,问题简化了。我们可以通过迭代来逼近这个不动点:
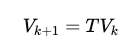
这就是动态规划(DP)的思想:不断应用 Bellman 算子,直至收敛到最优值函数。然而,现实世界给我们出了一个难题:我们通常无法获知精确的环境模型。于是,强化学习必须回答一个根本问题:
在不知道模型的情况下,如何逼近 Bellman 不动点?
三、TD 与 Q-learning:用采样替代期望
时序差分(Temporal Difference, TD)学习带来了关键突破:用一次采样(样本)来替代 Bellman 方程中的期望计算。
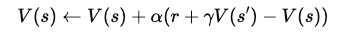
Q-learning 在此基础上更进一步,直接学习状态-动作对的价值,其更新规则为:
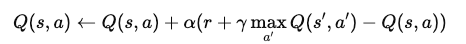
这意味着:
- 无需模型:通过与环境的交互采样来学习。
- 在线更新:可以实时、增量式地改进策略。
- 收敛保证:在理想条件下仍能逼近 Bellman 最优不动点。
至此,强化学习正式迈入了主流的“无模型”时代。
四、DQN:函数逼近进入深度学习时代
当状态空间变得巨大甚至连续时,传统的表格(Tabular)方法彻底失效。Deep Q-Network(DQN)的诞生解决了这个问题,它主要做了三件事:
- 函数逼近:用深度神经网络来拟合 Q 函数。
- 经验回放:存储并随机抽样过往经验,打破数据间的相关性。
- 目标网络:引入一个更新较慢的目标 Q 网络,稳定训练目标。
这一步的意义在于:
它将“求解 Bellman 不动点”这个数学问题,转变成了“用神经网络进行函数拟合”的工程问题。
强化学习与深度学习实现了深度融合。
五、另一条路线:策略梯度
几乎在价值函数方法发展的同时,另一条技术路线——策略梯度方法也在演进。其核心思想不是间接地学习价值函数再导出策略,而是直接对策略函数进行优化。
REINFORCE 算法给出了策略梯度的核心公式:
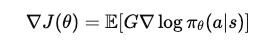
这一思想转变至关重要:
它将强化学习问题,重新定义为对策略参数空间的概率分布进行梯度优化的问题。
至此,一条新的主线出现了,它不再围绕 Bellman 不动点展开,而是围绕目标函数的梯度展开。
六、Actor-Critic:两条路线的融合
Actor-Critic 架构巧妙地将价值函数和策略梯度两条路线结合起来:
- Critic(评论家):学习价值函数(通常使用 TD 方法),评估状态或动作的好坏。
- Actor(演员):根据 Critic 的评价,使用策略梯度更新策略,做出更好的决策。
Critic 提供了更低的方差估计,Actor 则负责直接优化策略。这成为了现代强化学习中最主流的算法框架之一。
七、TRPO 与 PPO:稳定性革命
随着策略网络变得更深更复杂,一个新问题凸显出来:策略更新步长如果过大,可能导致性能剧烈下降甚至训练崩溃。为了解决这个稳定性问题,TRPO(Trust Region Policy Optimization)引入了信赖域约束,严格限制新旧策略之间的 KL 散度。
而 PPO(Proximal Policy Optimization)在此基础上提出了一个更易于实现的工程化简化:
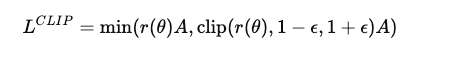
它通过裁剪概率比来隐式地约束策略更新,实现了:
- 稳定更新:避免破坏性的策略更新。
- 易于实现:相比 TRPO 省去了复杂的二阶优化。
- 可扩展性强:非常适合大规模分布式训练。
PPO 迅速成为深度强化学习领域事实上的默认算法。
八、关键转折:大模型时代的强化学习
当强化学习进入大语言模型时代,其应用场景发生了结构性变化。LLM 的训练环境具有以下特点:
- 没有明确的状态转移模型:对话的“状态”是生成的文本序列,转移难以定义。
- 没有长时间序列奖励:通常每个回复得到一个即时的人类偏好反馈。
- 更接近上下文赌博机:每个提示(prompt)下选择一个完整的回复序列作为“动作”。
因此,强化学习在大模型对齐(如 RLHF)中的角色转变为:
在预训练模型生成的语言分布上,进行基于人类反馈的策略优化。
一个典型的目标函数是最大化奖励的同时,约束新策略不要偏离原始参考模型太远:
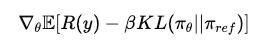
这本质上就是:
- 策略梯度:使用人类反馈作为奖励信号。
- 加上 KL 约束:防止过度优化导致模型退化。
- 使用 PPO 实现:利用其稳定性和效率来完成优化。
九、Bellman 在 LLM 时代的地位
这里有一个非常关键的区别:在现代大模型的强化学习训练中,几乎不再显式地使用 Bellman 递归或求解价值函数。
它不再求解 $V = T V$ 这样的不动点方程,而是在求解:
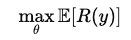
这是一个带约束的策略分布优化问题。换句话说:
以 RLHF 为代表的大模型强化学习,其技术血脉主要继承自策略梯度和约束优化理论,而非经典的 Bellman 不动点迭代体系。
十、整条演化脉络
我们可以将强化学习数十年的发展压缩成一条清晰的主线:
Bellman 方程(奠定递归结构与不动点理论基础)
↓
动态规划(模型已知下的精确求解)
↓
时序差分 / Q-learning(用无模型采样替代期望)
↓
DQN(用深度神经网络进行大规模函数逼近)
↓
策略梯度(绕过价值函数,直接优化策略分布)
↓
Actor-Critic(融合价值评估与策略优化)
↓
TRPO / PPO(引入约束,实现大规模稳定训练)
↓
RLHF / RLAIF(应用于大模型对齐,完成最终形态转变)
十一、最核心的总结
如果说 Bellman 方程奠定了强化学习的数学结构,那么:
- TD 学习让它能够在未知环境中进行学习。
- DQN让它能够处理高维、复杂的状态空间,实现规模化。
- 策略梯度让它能够直接优化复杂的行动分布。
- PPO让它能够稳定、高效地训练参数量巨大的模型。
正是这一系列关键的范式演进与技术突破,共同推动着强化学习走进了今天波澜壮阔的大模型时代。想了解更多前沿技术讨论与实践分享,欢迎访问云栈社区,与广大开发者共同交流成长。
 发表于 2026-3-5 14:56:39
|
查看: 253|
回复: 0
发表于 2026-3-5 14:56:39
|
查看: 253|
回复: 0
