近年来,多模态大模型的发展正在不断推动视觉理解能力的提升。然而,在面对现实世界中具有天然层级结构的概念时,例如生物分类体系中的“界—门—纲—目—科—属—种”,现有模型仍然存在明显不足。这类任务不仅要求模型识别具体类别,更需要理解类别之间的层级关系和语义结构。
如何在开放世界中,利用已有知识帮助模型理解层级结构,并推断训练数据中未出现的未知类别,已成为当前视觉智能研究中的一个关键挑战。
针对这一难题,北京大学王选计算机研究所的彭宇新团队提出了一种名为 TARA(Taxonomy-Aware Representation Alignment) 的新方法。该方法的核心思想是,引入生物基础模型(BFM)中蕴含的分类学知识,并将其与多模态大模型的中间表征进行对齐,从而让模型学习到具有层级结构的视觉和语义表示。这项工作被CVPR 2026接收,论文标题为《Taxonomy-Aware Representation Alignment for Hierarchical Visual Recognition with Large Multimodal Models》。

一、TARA 如何提升模型的层级识别与泛化能力?
为了全面验证TARA方法的有效性,研究团队在多个数据集和多种评价指标下进行了系统性的实验。
1. 提升已知类别层级识别性能
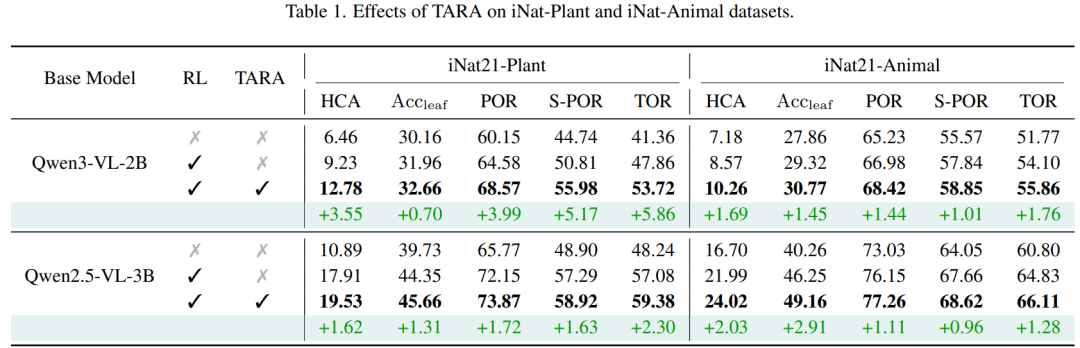
实验首先在具有完整生物分类层级的 iNaturalist-2021 (iNat21) 数据集上进行。结果显示,引入TARA方法后,模型在植物和动物子集上的各项指标均获得稳定提升。
以Qwen3-VL-2B基础模型为例,在iNat21-Plant数据集上,经过强化学习(RL)微调后,其层级一致性准确率(HCA)为9.23%。而结合TARA方法训练后,HCA进一步提升至12.78%,叶节点准确率(AccLeaf)也从31.96%提升到32.66%。对于更大的Qwen2.5-VL-3B模型,在动物数据集上的HCA更是从21.99%提升到了24.02%。
2. 增强对未知类别的泛化能力
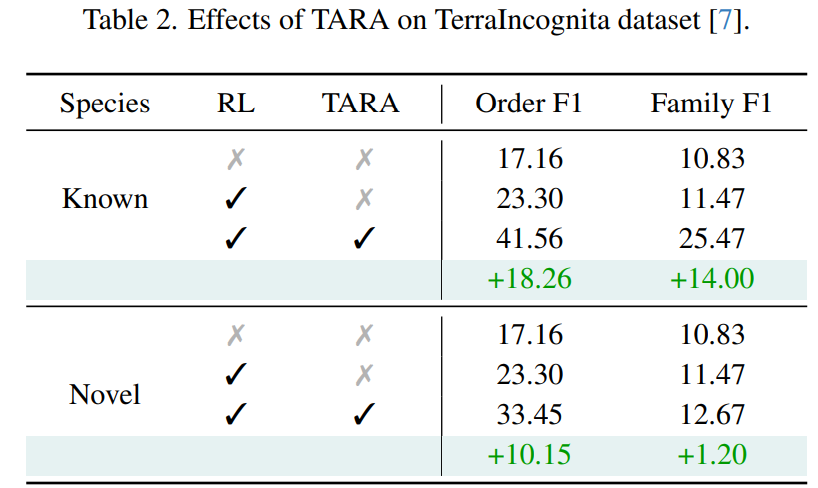
为了验证模型是否真正学会了分类学知识,而非简单记忆训练类别,研究在TerraIncognita数据集上进行了测试。该数据集包含许多稀有或未见过的物种。
实验结果表明,在已知类别上,TARA将Order F1分数从23.30大幅提升至41.56;更重要的是,在面对未知类别时,Order F1分数也从23.30提升到了33.45。这证明TARA赋予模型的层级知识,能够有效帮助其推断和识别训练中从未见过的物种。
3. 优化视觉特征表征能力
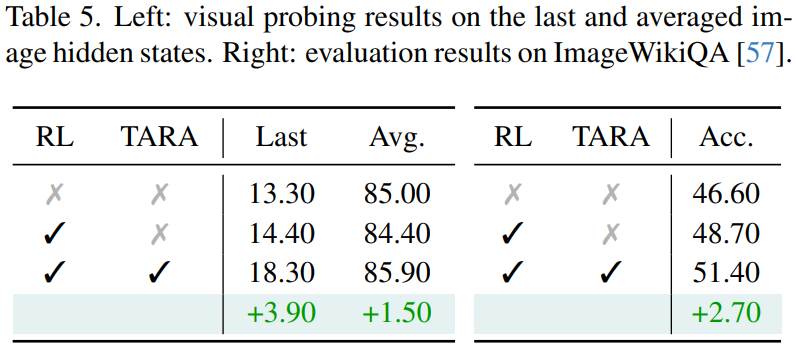
通过线性探针实验,研究人员分析了TARA对模型视觉特征的影响。他们从模型最后一层提取图像表征,并用线性分类器在iNat21-Plant数据集上测试。结果显示,仅使用RL微调时分类准确率为14.40%,而加入TARA后,准确率提升至18.30%。这说明TARA帮助模型学习到了更具判别力的视觉特征。
4. 提升复杂视觉问答任务表现
在需要综合视觉理解和知识推理的ImageWikiQA数据集上,TARA同样显示出优势。模型准确率从RL微调后的48.70%进一步提升到了51.40%。
5. 加速模型训练收敛
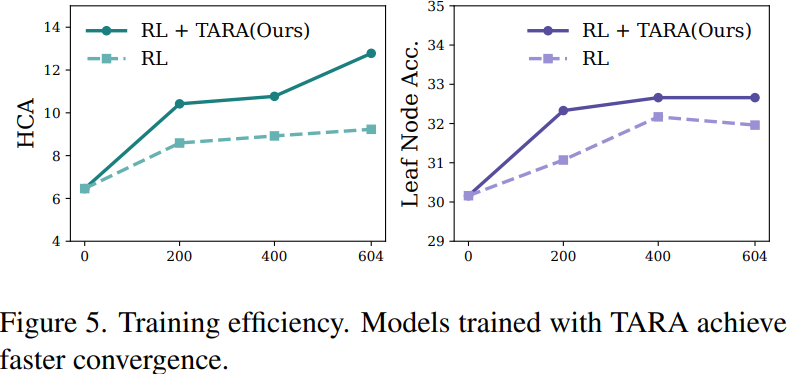
研究还发现,引入TARA方法能提升训练效率。在训练早期,使用TARA的模型性能就超过了基线模型,并且在相同训练步数下,其HCA和叶节点准确率均更高,表明TARA能促进模型更快地收敛。
二、TARA 方法的完整训练框架
这套有效的训练框架离不开精心设计的数据集、基础模型、训练策略和评价体系。
数据集与基础模型
- iNat21:大规模生物图像数据集,包含完整的六层分类体系(界、门、纲、目、科、种),用于核心的层级识别任务。
- TerraIncognita:包含中美洲和南美洲的昆虫图像,许多物种缺乏公开数据,用于测试模型对未知类别的泛化能力。
- ImageWikiQA:基于ImageNet的复杂视觉问答数据集,用于评估高层视觉理解和推理能力。
- 基础模型:研究选用Qwen系列多模态模型(Qwen3-VL-2B和Qwen2.5-VL-3B)作为起点。
训练框架:RL微调与表征对齐交替进行
整个训练框架如下图所示,核心是 “No-Thinking RFT”强化学习微调与 TARA表征对齐 的交替进行。
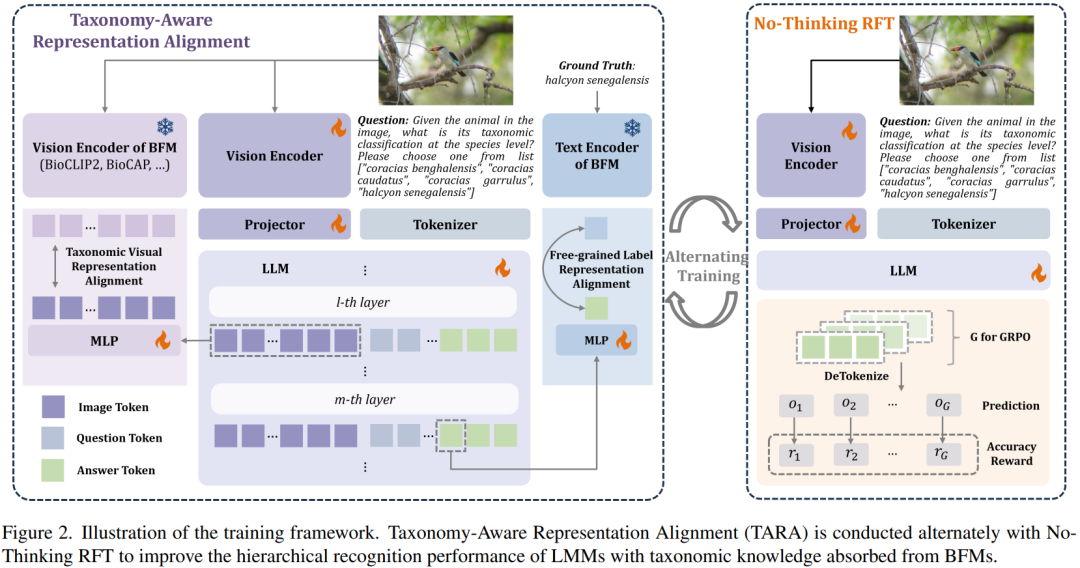
- No-Thinking RFT:与传统需要推理链的RL不同,研究发现在分类任务中,直接让模型输出答案(使用提示语“Please directly output the answer”)效果更好。奖励函数设计简单:预测正确得1分,错误得0分。
- TARA表征对齐:这是注入分类学知识的关键,包含两个对齐任务:
- 视觉表示对齐:使用生物基础模型(如BioCLIP2)提取图像特征,同时获取多模态模型中间层的视觉特征,将二者映射到同一空间,通过最大化余弦相似度进行对齐,使模型学习符合生物分类结构的视觉表示。
- 标签表示对齐:将分类标签(如“halcyon senegalensis”)输入BFM的文本编码器得到标签嵌入,同时将多模态模型生成答案的token表征映射到同一空间并进行对齐,使模型理解不同层级标签间的语义关系。
全面的层级评价指标体系
为了精准评估模型在层级识别中的表现,研究设计了多个互补的指标:
- 层级一致性准确率(HCA):要求从根节点到叶节点的整条预测路径完全正确,任一层次错误则整体判错。这是最严格的指标。
- 叶节点准确率(AccLeaf):仅衡量最细粒度(物种)级别的预测准确率。
- 点重叠率(POR):统计预测路径中正确节点的比例。
- 严格点重叠率(S-POR):要求预测正确的节点必须是连续的才计入得分。
- 顶层重叠率(TOR):衡量相邻层级间预测结果的一致性。
三、TARA 的核心价值与应用前景
这项研究的意义不仅在于解决了一个具体的视觉任务,更在于为多模态大模型与领域知识融合提供了一条可借鉴的路径。
- 解决层级识别不一致问题:传统多模态模型在扁平分类上表现良好,但进行层级预测时易出现路径矛盾。TARA通过引入结构化的分类学知识,显著提升了模型预测的层级一致性。
- 赋予模型“推断未知”的能力:在真实开放世界中,新类别层出不穷。TARA让模型能够利用已学的层级关系去推断未知类别的可能位置,极大增强了模型的实用性和泛化能力。
- 提供“知识注入”的通用范式:TARA通过中间表征对齐的方式将外部知识注入模型,这种方法具有普适性。可以推广到医学影像诊断(疾病层级)、商品分类、知识图谱推理等任何具有层级结构的领域。
- 迈向理解复杂关系的视觉智能:未来的视觉模型不应只是“识别器”,更应是“理解者”。TARA推动了多模态大模型向能够理解对象间复杂结构关系的通用视觉理解系统演进。
四、作者简介
- 何胡凌霄:论文第一作者,北京大学王选计算机研究所博士生,师从彭宇新教授。研究方向为细粒度多模态大模型,在CVPR、ICLR等顶级会议发表多篇论文。
- 彭宇新:论文通讯作者,北京大学王选计算机研究所教授、博雅特聘教授,IEEE/CCF Fellow,国家杰出青年科学基金获得者。长期致力于多媒体分析、计算机视觉和人工智能研究,发表大量高水平学术论文,并主持多项国家级科研项目。
这项来自北京大学的前沿研究,为我们展示了如何让大模型变得更“懂行”、更“善思”。对于从事人工智能,特别是计算机视觉和多模态研究的开发者而言,理解这类将领域知识深度嵌入模型的技术路径至关重要。我们也可以在云栈社区的相关板块深入探讨此类技术的实现细节与潜在应用。
 发表于 2026-3-8 08:52:08
|
查看: 139|
回复: 0
发表于 2026-3-8 08:52:08
|
查看: 139|
回复: 0
