过去两年里,大模型的能力可谓突飞猛进。从文本生成到多模态理解,它们已经逐渐成为很多人日常使用的工具。
但随着使用深入,一个问题也变得越来越明显:这些模型虽然强大,却并不真正“懂你”。
在与模型的互动中,我们不断提供个人信息。你可能在某次对话中提到自己的偏好,在另一段交流中表达情绪状态,又在不经意间展现出性格特征。
但现有的大多数模型,很难将这些信息整合起来,更难以在长期交互中持续更新对你的理解。它们要么记不住,要么记错了,用的是过时的记忆。
那什么是个性化多模态大模型呢?
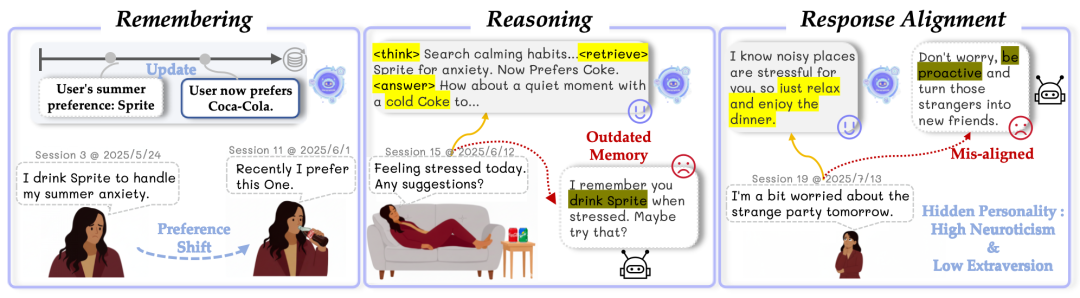
如图 1 所示,用户缓解焦虑的饮品偏好从“雪碧”转变为“可乐”,而仅依赖静态数据库的系统受限于“过时记忆”给出了错误的推荐。
另外,用户的真实性格往往隐匿于琐碎的对话片段中,例如对于因聚会而感到忧虑的“内向、敏感”型用户,通用模型给出了“积极主动表现”这种充满社交的建议,与用户性格完全不符。

论文地址:
http://arxiv.org/abs/2604.13074 (CVPR 2026 Highlight)
项目主页:
https://personavlm.github.io/
代码地址:
https://github.com/MiG-NJU/PersonaVLM
训练数据:
https://huggingface.co/datasets/ClareNie/PersonaVLM-Dataset
评测数据:
https://huggingface.co/datasets/ClareNie/Persona-MME
核心问题:AI仍然是“静态的”,而人是“动态的”
这一问题的本质在于,当前的大模型仍然是“静态系统”,而真实的人却是不断变化的。
人的偏好会改变,情绪会波动,性格也会在长期互动中逐渐显现。
但现有方法通常只依赖当前上下文,或简单拼接历史信息,甚至使用固定的用户画像。这使得模型很难跟踪用户的动态变化,导致所谓的“个性化”停留在表面。
换句话说,当前的大模型更像是在“回答问题”,而不是在“理解一个人”。
核心思路:让模型具备“长期个性化能力”
围绕这一问题,来自南京大学和字节跳动的研究团队提出了一种新的解决方法 PersonaVLM:将多模态大模型从“通用能力工具”,转变为“长期个性化助手”。
这一框架的关键在于三个能力的协同:记忆、推理与对齐。
首先是“记忆”。与传统方法不同,这里的记忆并不是简单存储对话,而是被结构化为多种类型,包括用户基础信息、抽象知识、具体事件以及行为习惯等。模型不再只是“记住说过的话”,而是逐步构建对用户的整体理解。
其次是“推理”。当用户提出问题时,模型不会直接生成答案,而是通过多步推理判断是否需要检索记忆、检索哪些信息,并在过程中不断整合上下文。这种“边检索边推理”的方式,使回答更加贴合用户背景。
最后是“对齐”。模型会持续跟踪用户性格,并通过动态机制不断更新其人格表示(采用心理学大五人格,将性格量化为 5 维向量)。输出不仅在内容上正确,也在风格上更符合用户特征。
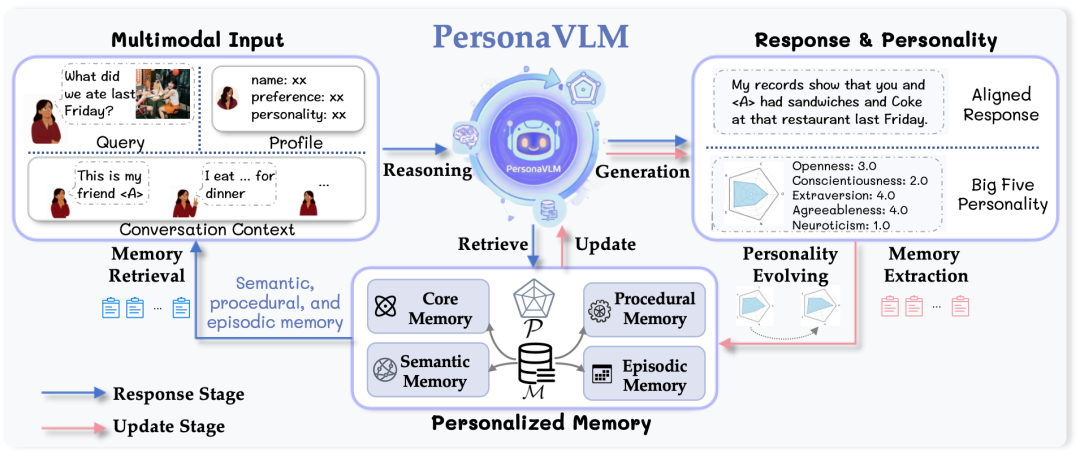
在现实世界中,用户并不是固定的标签,而是随着时间不断变化的个体。
PersonaVLM 中引入五大人格模型对用户性格进行建模,并设计了动态更新机制,使模型既能快速适应初期信息,又能在长期交互中保持稳定认知。
这使得模型的行为,从“统一风格”,转向“面向具体个体”。 这一点非常关键,因为真正的个性化,并不是静态标签,而是持续演化的理解过程。
具体地,区别于传统的单一文本记忆,PersonaVLM 像人类一样对记忆进行了精细化分层:
- 性格画像 (User Personality Profile): 基于心理学“大五人格”,量化并追踪用户的动态性格;
- 核心记忆 (Core Memory): 存储用户的基础属性(如姓名、职业、核心身份);
- 语义记忆 (Semantic Memory): 提取并存储跨模态的抽象知识(如用户喜欢的物品长什么样、偏好习惯等);
- 情景记忆 (Episodic Memory): 将长篇对话切分为带有时间戳的原子事件,方便按主题检索;
- 程序性记忆 (Procedural Memory): 记录用户的长期目标和重复性行为模式。
同时,PersonaVLM 采用了双阶段协作流:
- 响应阶段 (Response Stage): 当接收到用户的图文输入时,PersonaVLM 不会急于回答。它会自主进行多步推理,决定是否需要检索记忆、检索什么时间段的哪类记忆。在提取出相关记忆后,模型会结合用户的当前性格,生成“投其所好”且“语气契合”的专属回答;
- 更新阶段 (Update Stage): 在交互结束后(系统空闲时),模型会自动触发性格演变机制,根据刚刚的对话微调用户的性格评分,并主动提取对话中有价值的信息,对四类记忆库进行增删改查,为下一次交互做好准备。
研究团队还为该框架量身定制了 SFT 和 RL 两阶段训练流程,构建数据集生成管线合成 80K+ 数据,极大增强了模型的多轮推理和格式遵循能力。
不只是方法:还重新定义了评测方式
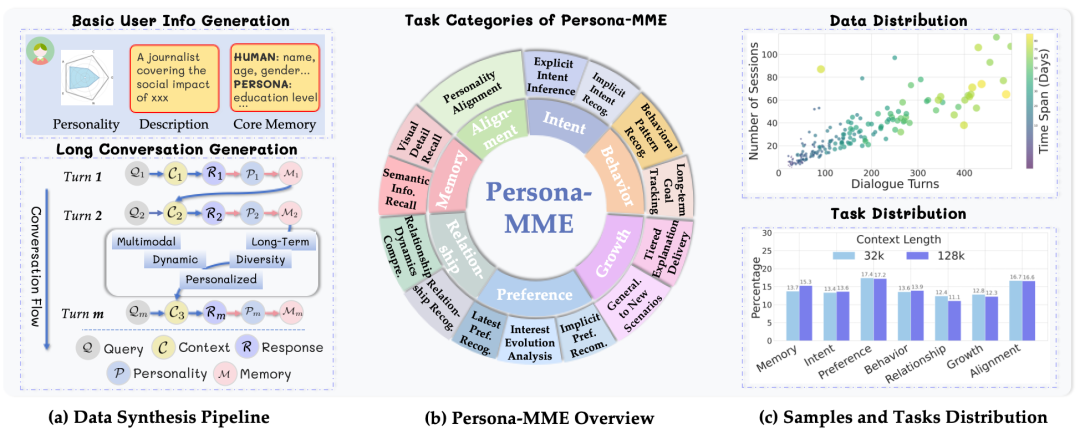
除了方法本身,这项工作还提出了新的评测基准—Persona-MME,通过设计的数据合成管线,生成了包含 200 个多样化虚拟角色的交互数据,用于系统评估模型的长期个性化能力。
与传统评测不同,这一基准基于多轮交互构建,覆盖记忆、意图、偏好、行为、关系、成长、和对齐 7 个核心维度(14 个细粒度任务),更贴近真实使用场景。它不再只关注“答对一道题”,而是关注“是否持续理解一个人”。
实验结果:当问题变真实,差距被重新拉开
在新的评测体系下,模型之间的差距变得更加明显。
PersonaVLM 在多个维度上显著优于现有方法,在 Persona-MME 上相较基线提升超过 20%。
在开放生成任务中,其表现甚至在部分场景下高于 GPT-4o,尤其是在需要结合长期记忆与个性化表达的任务中,优势更加突出。
这说明,当评测从“单题准确率”转向“长期一致性与个性化能力”时,我们对模型能力的认知也需要被重新审视。
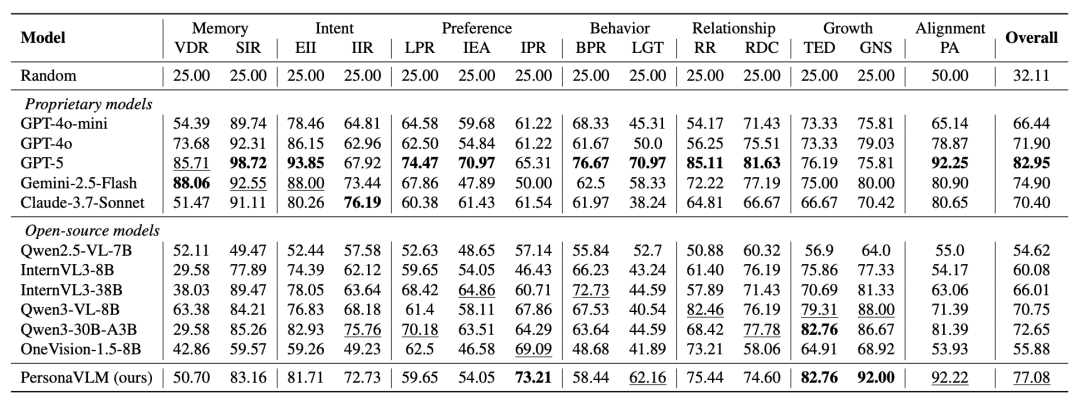
论文在 Persona-MME 上对一系列私有和开源多模态模型进行全面评估,主要观察如下:
(1)闭源模型长期个性化能力超越开源模型,但目前暂无全能型选手在所有细分任务中领先;
(2)开源多模态小尺寸模型在个性对齐任务上表现不佳(略优于随机选择),而 Qwen3 系列纯语言模型在该任务表现相对优异;
(3)标准 RAG 在短上下文场景中反而会导致性能下降,比如在偏好理解任务上的性能下降高达 9.3%,这说明未经加工的外部记忆反而会导致检索不准确和引入干扰噪声,而 PersonaVLM 通过结构化记忆和多轮检索有效解决该问题;
(4)情景记忆对于 PersonaVLM 整体性能影响最大,而程序记忆对“行为”和“关系”两类任务影响显著。

图 5 进一步提供定性案例。在视觉细节召回提问中,PersonaVLM 能准确检索到历史图像对话并规避基线出现的记忆幻觉;在长程上下文对话中,它能自发关联历史碎片信息进行自然互动;在常规交互问答中,它能敏锐捕捉用户“高严谨性”等深层人格特征,提供契合用户认知的定制化建议。
结语
这项工作的意义,不只是提出了一种方法,更在于揭示了一个重要趋势:大模型正在从“回答问题”,走向“理解用户”。
未来的 AI,不只是知道答案,而是能够记住你的偏好、理解你的习惯、适应你的变化,并在长期互动中逐渐形成对你的认知。
从短期对话到长期关系,从统一能力到个体差异,大模型正在从工具,逐渐演化为真正的智能体。对于这类前沿技术的深入探讨和实践分享,欢迎访问云栈社区与更多开发者交流。
 发表于 2026-4-22 19:23:46
|
查看: 224|
回复: 0
发表于 2026-4-22 19:23:46
|
查看: 224|
回复: 0
