Chandra最值得关注的,并非它又在某个榜单上拿了第一,而是它背后那句分量很重的话:老一代的pipeline OCR,已经碰到天花板了。
读完Datalab的《Introducing Chandra》,我的第一反应不是“又一个OCR模型来了”,而是:这家公司终于把许多人心里清楚、却一直没点破的事给讲明白了。
过去几年里,OCR工具已经层出不穷。Surya、Marker,以及各种文档解析流水线,大家都能跑起来,也确实解决了不少问题。尤其是Datalab自家之前的作品Surya和Marker,累积了约5万个GitHub star,速度快、可定制、跨语言支持也不错,这绝非是“失败的产品”。
但问题在于,能跑通,不等于能攻克复杂文档。
一旦你开始处理下面这些“硬骨头”:
- 手写表单
- 跨页表格
- 混合布局文档
- 数学公式
- 图片和图表提取
- 老旧字体、低质量扫描件
传统OCR的弱点便会暴露无遗。这也是我认为Chandra最有价值的地方。它并非“在原有方案上微调参数”,而是Datalab亲口承认:我们之前那套方法,已经解决不了日益复杂的文档了。 这个承认本身,就很有分量。
真正的分水岭:从“切块识别”到“整页理解”
先说最核心的技术路线分歧。Datalab在博客中提到,过去的Marker/Surya走的是典型的 pipeline-based 路线:先将页面切割成一个个区块(block),再分别识别每个区块,最后将结果拼接回来。
这条路线为何流行?很简单:快。
你可以把它想象成流水线分拣。先把一页文档切成标题区、正文区、表格区、图片区,然后每块交给对应模块处理。这个思路在处理常规PDF、规则排版、多语言文本时非常有效,这也是Marker广受欢迎的原因。
但问题恰恰出在“先切块”这一步。因为复杂文档最难的地方,往往不是“块内识别”,而是区块与区块之间的关系。
例如:
- 手写表单中的一个勾选框,与旁边的文字到底是不是一组?
- 复杂表格里,跨列的说明文字究竟属于哪一列?
- 一张图是普通插图,还是数据图表,或是化学结构式?
- 一段公式下面的注释,是否应该和公式本身一同解析?
如果你先把页面切碎,再分别看每一块,就像把一封信剪成十几段再让人阅读。每个字都可能认识,但整体意思未必能拼对。
因此,Datalab决定转向 full-page decoding。通俗地说就是:不再先把页面切碎,而是把整页文档作为一个整体来理解和解读。
我认为这是Chandra真正的分水岭。它不仅仅是一个新模型,更标志着OCR的技术思路从“局部识别”转向了“全局理解”。对这类专注于人工智能和文档智能化的前沿项目保持关注,有助于我们把握技术演进的方向。
为什么Chandra值得关注
Datalab列举了几类他们的客户最关心、也是旧方案最容易“翻车”的场景:
- 手写文本识别
- 多语言支持
- 表单与表格抽取
- 图片标题生成与内容提取
- 数学公式精度
你会发现,这几乎涵盖了当今文档理解领域最难啃的骨头。
1. 布局感知能力
Chandra的核心设计之一是 layout-aware。

这四个字听起来平淡,意义却非常重大。因为很多OCR工具实质上只是在“认字”,而不是“理解页面”。Chandra的目标是:不仅知道页面上有什么内容,还知道什么内容在什么位置、它属于什么类型、以及该如何处理它。
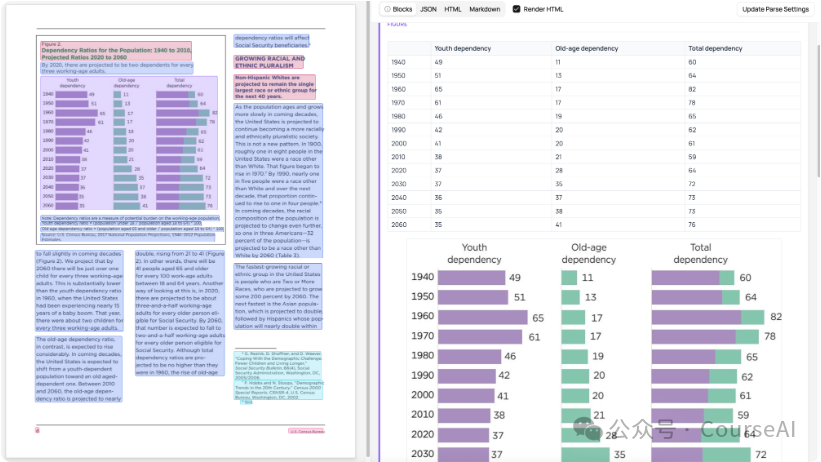
这样它才能做到两件过去难以兼顾的事:
- 将图片、图表、图示从页面中准确地切割出来
- 为这些非文本内容生成描述,甚至提取出结构化数据
说实话,这一步令人兴奋。一旦OCR真正将布局视为一等公民,它就不再只是“文本提取工具”,而开始接近一个文档理解引擎了。
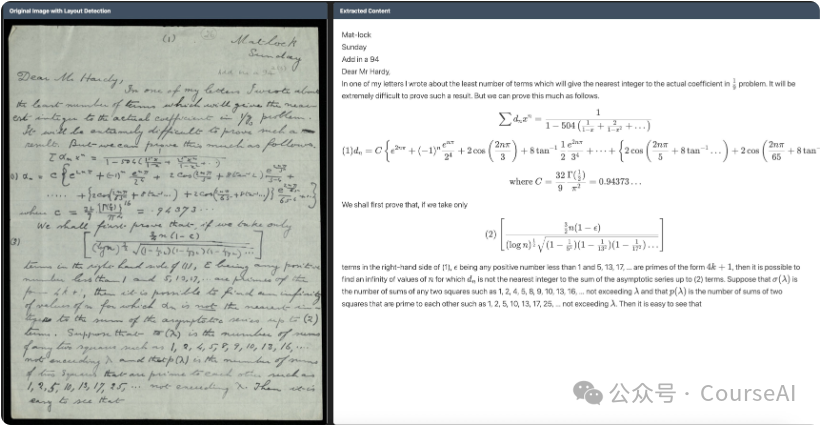
2. 数学公式支持
Chandra对数学公式的支持着墨颇多,这也表明他们很清楚这是一块高价值的技术战场。

公式识别一直是OCR领域最容易“看起来差不多,实则谬以千里”的部分。普通文字错一个词,读者或许能猜;公式错一个符号,结论可能就截然不同。Datalab为此进行了真实数据标注,也使用了合成样本。这个方向我非常认同,因为数学公式、科研论文、工程文档等场景,恰恰是OCR从“办公自动化工具”升级为“AI基础设施”的关键入口。
3. 表格与表单处理
有一句话我特别认同:表格是所有文档解析工具的噩梦。
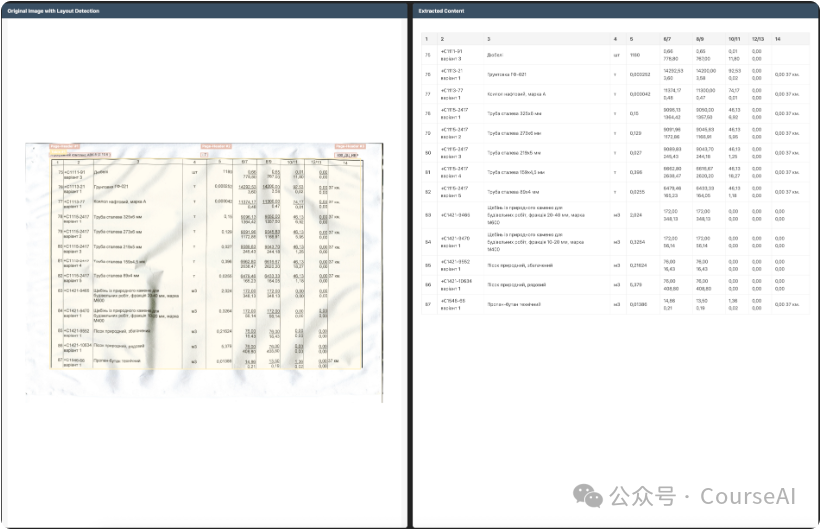
旧方案将表格拆分成单元格分别识别,速度是快,但遇到复杂表格、跨行内容、手写表单、勾选框等元素时,一拆就容易丢失结构关系。Chandra明显是希望通过整页解码来解决这个痛点。尤其是表单中的勾选框这类细节,听起来不起眼,实际上至关重要。合同里漏掉一个勾选框,其后果远非OCR评测中少0.5分那么简单。
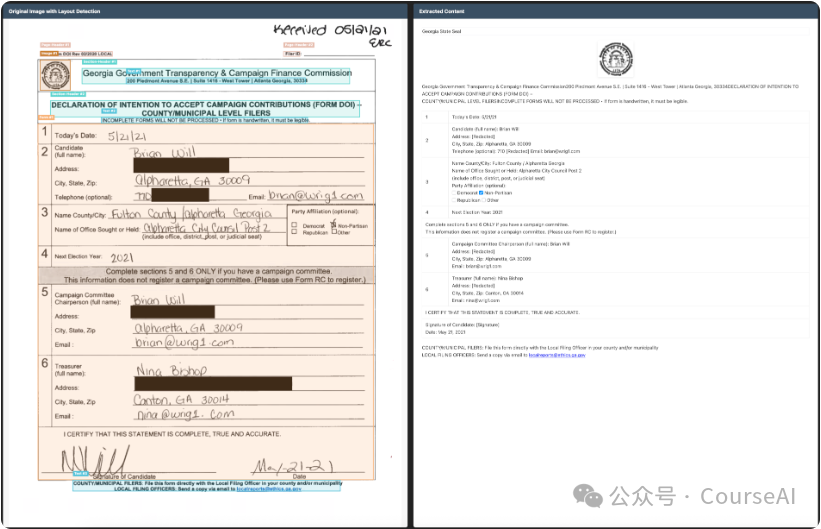
它的优势与挑战
Chandra在独立的olmocr benchmark上取得了领先成绩,并给出了吞吐量数据:量化后的8B/2B版本可在本地运行,在H100上最高可达4页/秒,一天能处理约34.5万页,且精度损失不大。
这个数据固然亮眼,但我认为更值得关注的不是“又赢了谁”,而是它传递出的两个信号。
第一,OCR正在被“大模型化”
Chandra这类模型越来越像一个通用的视觉语言模型,只不过被深度优化到了文档解析这一垂直场景。这意味着OCR未来将不再是一个孤立模块,而会成为:
- RAG系统的知识入口
- Agent的长期记忆入口
- 企业知识库的结构化入口
- 科研文档处理流程的起点
它输出的不再只是文字,而是能够直接进入下游工作流的结构化知识。这种将前沿模型应用于实际复杂任务的做法,正是开源实战精神在AI领域的重要体现。
第二,复杂文档解析的门槛正在抬高
但话说回来,我也不认为这条路只有好消息。Full-page decoding的方向无疑更强大,但这也意味着系统会更重、训练成本更高、工程复杂度更大。想要同时做好布局、公式、表单、图片、表格的解析,本质上是在构建一个文档领域的多模态大模型,而非一个轻巧的OCR小工具。
因此,Chandra的价值,很可能不在于让每个人都去训练一个自己的模型,而在于将行业的技术基线向上提升。它清晰地告诉大家:面对复杂文档,不能再依靠“分块+拼接”这套旧方法硬扛了。
对OCR未来的一个判断
如果看完这篇博客后,问我对于OCR未来最大的判断是什么?我会说:“OCR”这个词,很快就会不够用了。
未来真正重要的竞争,不是“谁识字更准”,而是以下三件事:
1. 谁更懂结构
标题、正文、脚注、图表、表格、公式、图片之间的逻辑关系,才是文档真正的信息密度所在。
2. 谁能更无缝地接入下游系统
输出结果不应以导出一个txt文件为终点,而是要能直接转换为Markdown、HTML、JSON等格式,直接进入RAG、Agent或数据分析系统。
3. 谁能在复杂场景中保持稳定
现实世界的文档从来都不“干净”。扫描件歪斜、手写潦草、表格跨页、语言混排、图片压缩过的情况比比皆是。未来的赢家,不会是在演示中最漂亮的工具,而是能够扛住这些“脏活累活”的稳健系统。
我认为Chandra这篇博客最值得记住的一句潜台词其实是:OCR的竞争,已经从“识别字符”阶段,进入了“理解文档”阶段。 这才是真正意义上的范式转变。理解和讨论此类技术演进,正是像云栈社区这样的开发者社区的核心价值所在。
最后
Datalab这样已经凭借Surya和Marker取得成功的团队,都在主动颠覆自己过去的成功路径,这说明这条技术赛道真的来到了拐点。一个团队最强大的时刻,并非证明自己过去做对了,而是敢于承认:那套方法在今天已经不够用了。
这也是为什么我认为Chandra值得被深入探讨。它不仅仅是一个新的OCR模型,更像是一枚信号弹:文档理解,已经正式进入了下一个发展阶段。
参考链接:
 发表于 2026-4-17 01:42:23
|
查看: 227|
回复: 0
发表于 2026-4-17 01:42:23
|
查看: 227|
回复: 0
