推荐理由:多模态大模型的“幻觉”是个老大难问题。以往的方法要么修改图像,要么调整内部参数,效果总不尽如人意。这篇来自香港科技大学的论文提出了一个新颖视角:幻觉源于模型对文本表述“过敏”!基于此,研究者提出了一个无需训练、即插即用的“脱敏”框架DeP,通过巧妙的“以文治文”策略,显著降低了模型的幻觉率。思路新颖,实现巧妙,对于理解和解决幻觉问题很有启发。
论文信息:
- 标题:Decoding by Perturbation: Mitigating MLLM Hallucinations via Dynamic Textual Perturbation
- 发表日期:2026年04月
- 发表单位:The Hong Kong University of Science and Technology (Guangzhou)
- 原文链接:https://arxiv.org/pdf/2604.12424v1.pdf
你有没有遇到过这种情况:给AI看一张戴着墨镜、穿着红色帽衫的人物图,然后问它“这个人戴眼镜吗?”。AI可能会回答:“是的,他戴着一副红色眼镜。”
墨镜和红色帽衫是真的,但“红色眼镜”从何而来?这就是多模态大模型 (Multimodal Large Language Model, MLLM) 著名的“幻觉”问题——生成与输入图像事实不符的描述。
传统观点认为,幻觉源于模型“看”不清或“看”与“说”没对齐。但香港科技大学的研究者提出了一个全新视角,并由此开发出一个完全无需重新训练就能为模型“脱敏”的方法:DeP框架。

幻觉根源新解:对文本“过敏”
论文的核心洞察非常精妙:幻觉的本质,是模型对文本表述“过敏”。
如何理解?假设模型真正“理解”了图像,那么无论你如何变换提问方式(只要核心语义不变),它的注意力焦点应该是稳定的。
但如果模型过度依赖从海量文本中学到的“语言先验”,它就会对提问文本的字面表述异常敏感。例如,当问题中提到“红色”,即使图像中只有一个红色物体(如帽衫),模型的注意力也可能被错误地吸引过去,从而将帽衫的“红”与眼镜错误关联,凭空造出“红色眼镜”。
下图清晰地展示了这种“文本过敏”现象:
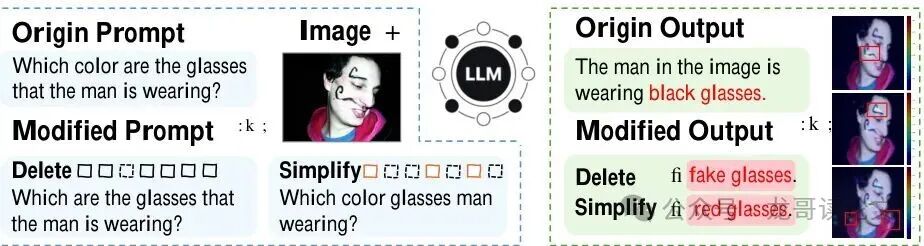
如图所示,尽管修改后的提示(如“他戴的是红色的吗?”)保留了原问题“这个人戴眼镜吗?”的核心语义,但其表面结构的微小变化却导致了截然不同的错误输出(“红色的”)。右侧的注意力热图显示,这种文本扰动造成了视觉定位的严重漂移,将注意力从眼镜错误地转移到了红色帽衫上。这种注意力的不稳定性,正是幻觉发生的核心信号。

无需训练!DeP框架的“以文治文”之道
既然找到了“过敏源”——文本,治疗思路就很清晰了:进行“脱敏”治疗。DeP (Decoding by Perturbation) 框架的核心思想是:主动给输入文本制造一些“无害”的扰动,通过观察模型反应的剧烈程度,来诊断并抑制其“过敏”倾向。
整个流程在推理时进行,无需修改模型的任何训练权重,是真正的“即插即用”。框架主要执行三个步骤:
- 刺激(扰动):生成几个语义不变但表述不同的“问题变体”,刺激模型以观察其反应。
- 诊断(解耦):分析模型对不同变体的注意力反应,分离出“稳定的视觉证据区”和“可疑的过敏区”。
- 治疗(校正):增强“证据区”的信息,抑制“过敏区”的噪声,并修正输出层面的概率偏差。
下图展示了DeP框架的整体流程:
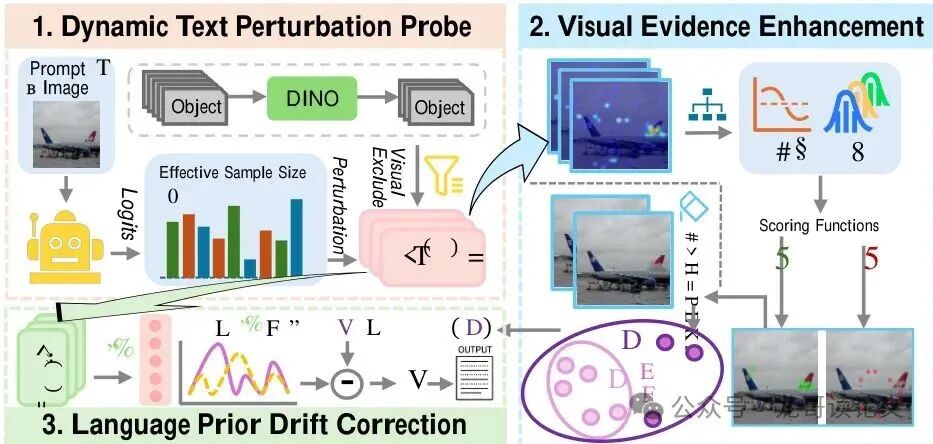
三步拆解:扰动、解耦、校正
第一步:动态文本扰动探测
在模型生成每个词时,DeP不仅使用原始问题 $x$,还会动态生成 $M$ 个语义保留的扰动版本 $x^{(m)}$。
$$x^{(m)} \sim q(\tilde{x} | x), \quad m = 1,...,M$$
这相当于在问“戴眼镜吗?”的同时,也偷偷问了几个语义相近但措辞不同的版本,例如“戴墨镜吗?”。然后,观察模型对每个扰动版本产生的注意力 $A_t^{(m)}$ 和输出逻辑值 $l_t^{(m)}$。
$$l_t^{(m)} = \log P_{\theta}(\cdot | I, x^{(m)}, y_{<t})$$
$$A_t^{(m)} = \text{Attention}(\cdot | I, x^{(m)}, y_{<t})$$
扰动的生成具有策略性:
- 多级语义扰动策略:设计了从温和(如替换近义词)到强力(如对抗高频共现词)的扰动方式。
- 自适应选择:根据模型当前输出的“犹豫程度”——用有效样本大小 $N_{\text{eff}}$ 衡量——来决定扰动强度。模型越自信($N_{\text{eff}}$ 小),使用温和扰动;模型越犹豫($N_{\text{eff}}$ 大),则用更强扰动激发其潜在偏见。
$$N_{\text{eff}}(p_t) = ||p_t||_2^{-2} = (\sum_{v \in V} p_{t,v}^2)^{-1}$$
第二步:视觉证据解耦与增强
获得 $M$ 个扰动下的注意力图后,进行统计分析。计算注意力图的平均值 $\tilde{A}_t$ 和方差 $\tilde{V}_t$。
$$\tilde{A}_t = \mathcal{N}(A_t), \quad \tilde{V}_t = \mathcal{N}(V_t), \quad \tilde{\sigma}_t = \sqrt{\tilde{V}_t}$$
- 平均值 $\tilde{A}_t$:代表模型稳定关注的区域,可能是真正的视觉证据。
- 方差 $\tilde{V}_t$:代表注意力波动的大小。方差大的区域,说明注意力“飘忽不定”,很可能是被语言先验误导的“可疑区域”。
基于此,构造两个评分:
- 证据分数 $S_e$:给予平均注意力高、方差小的区域高分。
$$S_e = \tilde{A}_t - \lambda_e(M, \delta_e) \cdot \tilde{\sigma}_t$$
- 可疑分数 $S_s$:给予平均注意力低、方差大的区域高分。
$$S_s = ((1 - \tilde{A}_t) - \lambda_a(M, \delta_a)) \odot (\tilde{\sigma}_t + \lambda_s(M, \delta_s))$$
接着进行“区域敏感性测试”:分别将识别出的证据区域 $R_e$ 和可疑区域 $R_s$ 在图像中进行模糊处理(高斯模糊),得到 $I_{\oplus R_e}$ 和 $I_{\oplus R_s}$,然后观察模型内部隐藏状态 $h_t$ 的变化量 $\delta_e$ 和 $\delta_s$。
$$I_{\oplus R} = (1 - M_R) \odot I + M_R \odot (G_{\sigma} * I)$$
$$\delta_e = h_t(I) - h_t(I_{\oplus R_e}), \quad \delta_s = h_t(I) - h_t(I_{\oplus R_s})$$
最后,在隐藏状态空间进行“对比融合”,增强证据信号,抑制可疑噪声,得到校准后的隐藏状态 $h_t^*$。
$$h_t^* = h_t(I) + \alpha \cdot \delta_e - \gamma \cdot \delta_s$$
第三步:语言先验漂移校正
有些语言先验偏见(例如总倾向于回答“是”)可能不体现在特定图像区域,而是直接扭曲了输出词的概率。DeP 利用扰动后的输出逻辑值来捕捉这种“漂移方向”。
计算所有扰动版本的平均逻辑值 $\bar{l}_t$ 与原始逻辑值 $l_t$ 的差值 $\Delta_t$。
$$l_t^{(m)} = \log p(\cdot | I, x^{(m)}, y_{<t})$$
$$\bar{l}_t = \frac{1}{M} \sum_{m=1}^{M} l_t^{(m)}, \quad \Delta_t = \bar{l}_t - l_t$$
$\Delta_t$ 向量代表了文本扰动导致模型输出概率的整体偏移方向,即语言先验的作用方向。在最终输出前,从这个方向“拉回”一部分影响,从而得到更忠于视觉事实的最终概率 $z_t$。
$$z_t = z_t^* - \beta \cdot \Delta_t$$
这三步共同构成了一次完整的“脱敏”流程。

实验验证:两大基准全面领先
论文在 LLaVA-1.5 和 InstructBLIP 两个主流 MLLM 上,使用 POPE 和 MMHal-Bench 两个基准进行了全面测试。
1. POPE基准(物体存在性判断)
POPE基准包含三个难度递增的设置:随机、流行(常见搭配)、对抗(故意触发语言先验)。
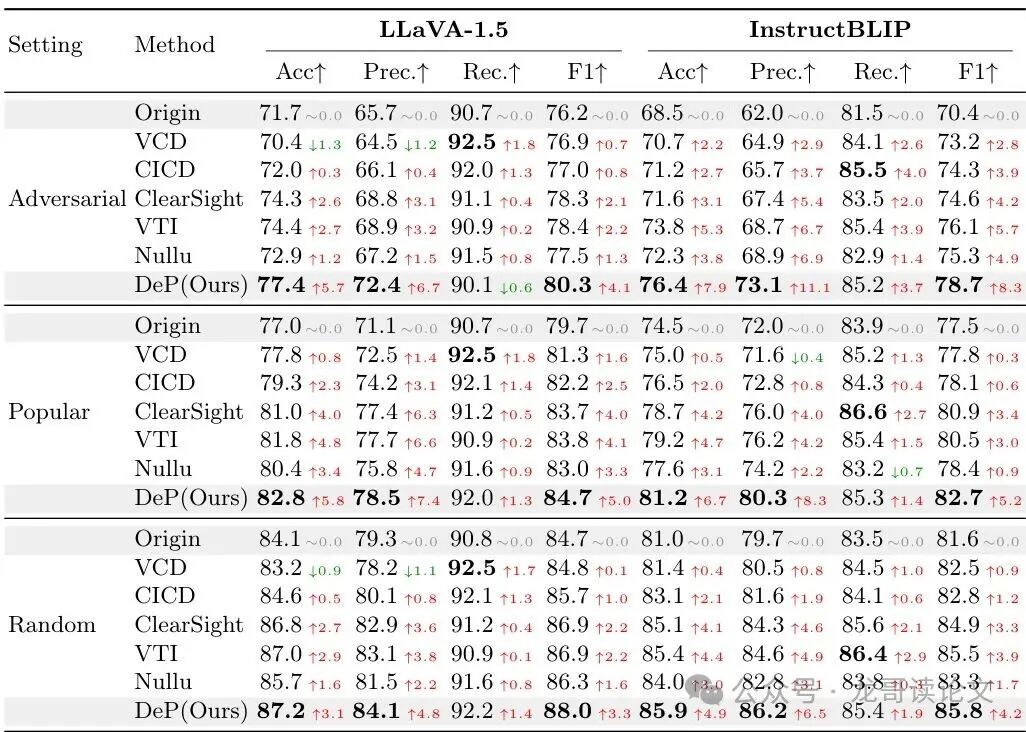
效果显著:在最具挑战的“对抗”和“流行”设置下,DeP的提升最为突出。例如,在对抗设置中,DeP将InstructBLIP的F1分数从70.4提升到了78.7,提升了8.3个百分点,说明其纠正语言先验偏见的能力很强。
2. MMHal-Bench基准(自由生成幻觉评估)
该基准评估模型自由描述的幻觉程度,涵盖属性、空间关系等8个细分类别,由GPT-4打分并计算幻觉率。
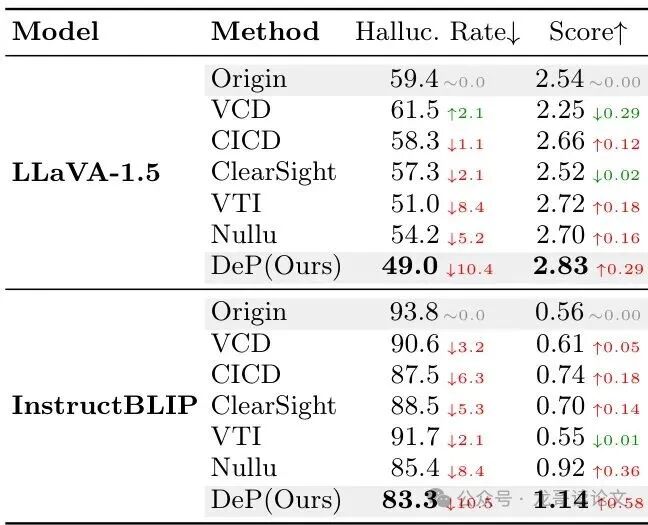
- 对于LLaVA-1.5,DeP将幻觉率从59.4%大幅降低到49.0%。
- 对于InstructBLIP,其原始幻觉率高达93.8%,DeP依然成功将其降低到83.3%,同时提高了生成质量分数。这显示了DeP在极端困难情况下的有效性。
下图雷达图更直观地显示,DeP在几乎所有细分类别上都取得了最佳或接近最佳的性能。
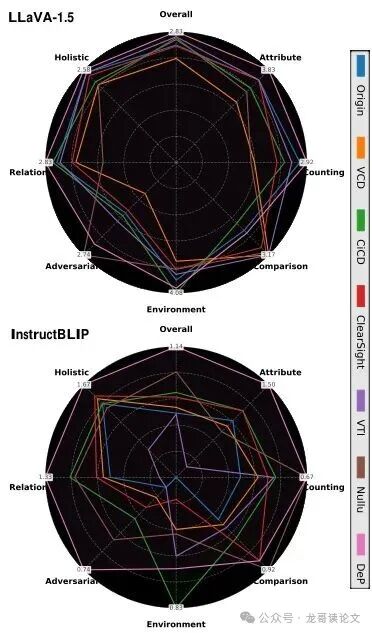
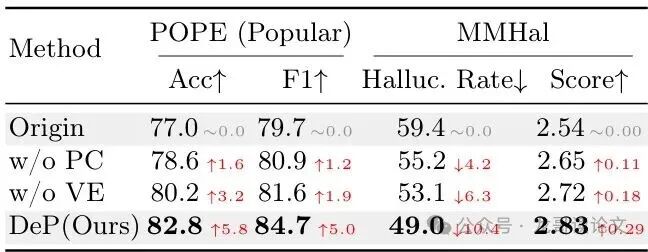
3. 消融实验与敏感性分析
消融实验证明了DeP三个核心模块(视觉证据增强VE、语言先验校正PC)均不可或缺。
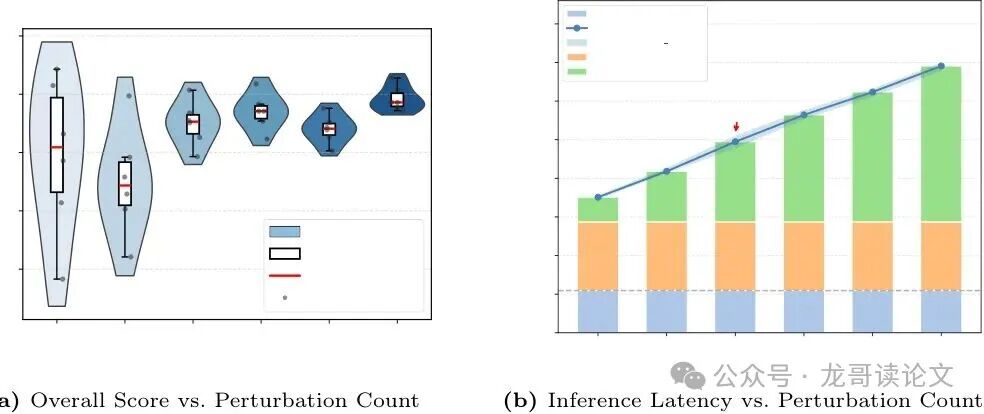
论文还分析了扰动数量 $M$ 的影响。$M$ 越大,估计越稳定(分数方差减小),但推理延迟线性增加。最终在效果和效率间权衡,默认选择 $M=3$。
方法局限与未来展望
DeP方法也存在一些局限:
- 推理开销增加:由于需要对每个解码步骤进行多次前向传播,推理延迟大约增加 $M$ 倍,对实时性要求高的场景有压力。
- 对扰动策略的依赖:扰动的设计和生成质量直接影响效果。
- 主要针对语言先验:对于纯粹由视觉编码器能力不足引起的幻觉,改善效果可能有限。
未来方向包括:将“扰动诊断”思想与高效微调结合;探索更轻量的实现以扩展到视频、音频等多模态场景。

核心要点问答
-
这篇论文解决的核心问题是什么?
解决多模态大模型在推理时产生的“幻觉”问题。论文提出了“文本过敏”这一新视角,并据此开发了无需训练的推理时校正框架DeP。
-
“语言先验”具体指什么?
指模型从预训练文本数据中学到的统计规律(如“红色”常与“苹果”共现)。在多模态任务中,过度依赖这些先验而忽略图像内容,就会导致幻觉。
-
DeP方法中的“logits”差值 $\Delta_t$ 有何作用?
$\Delta_t$ 捕捉了文本表述变化导致模型输出倾向的整体偏移方向,即语言先验的作用力。从最终输出中减去部分该方向的影响,能使输出更贴近视觉事实。
方法评价
- 创新性:★★★★☆。提出了新颖的“文本过敏”视角和“扰动诊断”框架,思路独特。
- 实验合理度:★★★★☆。在两个主流基准上进行了充分测试与对比,消融实验完整。
- 研究价值:★★★★★。为理解和诊断MLLM幻觉开辟了新路径,具有启发意义。
- 实用性:★★☆☆☆。推理延迟显著增加,目前更适合对准确性要求高、可容忍一定延迟的辅助场景。
主要参考文献:
Jia, Sihang, et al. "Decoding by Perturbation: Mitigating MLLM Hallucinations via Dynamic Textual Perturbation." arXiv preprint arXiv:2604.12424 (2026).

 发表于 2026-4-19 02:49:39
|
查看: 199|
回复: 0
发表于 2026-4-19 02:49:39
|
查看: 199|
回复: 0
