从2025年春晚的《秧BOT》,到2026年春晚里走进武术、小品等不同节目,机器人已经不只是舞台上的技术点缀,它们的动作越来越复杂,角色也越来越丰富。
但对于具身智能领域而言,真正的问题并不在于机器人能不能完成一场预先设定的表演,而在于这些能力能否离开特定的编排和场景,泛化到更广泛的真实任务中。
互联网上的海量视频,构成了物理世界最庞大的交互数据库。人类看段短视频就能学会的物理技能,具身模型却迟迟无法从中有效挖掘。画面里只有像素的流动,天然缺少机器能读懂的控制指令。视觉信号与动作标签之间,隔着一道难以跨越的模态鸿沟。
为打破这一僵局,美团LongCat团队推出了 LARYBench。
作为业内首个专门评估此类泛化表征的系统性基准,它提供了一把量化标尺,旨在帮助具身模型真正从海量视觉数据中学会通用的动作语言。为推动这一路径的探索与验证,LARYBench及其数据集、代码现已全面开源。

论文地址:
https://huggingface.co/papers/2604.11689
GitHub地址:
https://github.com/meituan-longcat/LARYBench
项目主页:
https://meituan-longcat.github.io/LARYBench/
HuggingFace地址:
https://huggingface.co/datasets/meituan-longcat/LARYBench
ModelScope地址:
https://modelscope.cn/datasets/meituan-longcat/LARYBench
具身泛化的三大现实瓶颈
长期以来,具身智能模型之所以难以直接向人类视频学习,主要受制于三个现实瓶颈。
一方面是数据获取难。带有精确动作标注的机器人数据极度依赖高成本的遥操作采集,规模极为有限,而庞大的人类视频库又缺乏机器人可用的底层指令。
另一方面是表征难迁移。传统的动作数据往往与特定硬件本体高度绑定,导致在一个平台上习得的特征很难跨形态复用。
更致命的是缺乏统一度量。由于没有独立的标尺来衡量中间表征质量,目前的模型大多局限于特定任务微调,难以走向大规模无监督预训练。
隐式动作表征通过学习视频帧间的时空演变来抽象动作语义,被视为打破上述瓶颈的关键。LARYBench的出现,正是为了将这种中间表征的质量与下游控制策略彻底解耦,为行业提供科学的评价体系。
构建动作表征的度量标准
针对前述的评估空白,LARYBench建立了一套能够量化隐式动作质量的标准化框架。它并非单纯的单一数据集,而是一个从物理执行(本体动作)与高层理解(语义动作)两个核心维度切入的综合评价体系。

LARYBench概览:数据规模、动作分类体系及多形态机器人平台覆盖
这一体系建立在庞大的数据底座之上。LARYBench整合了超过120万个标注视频片段(总时长超1000小时),以及62万对图像和59.5万条运动轨迹。
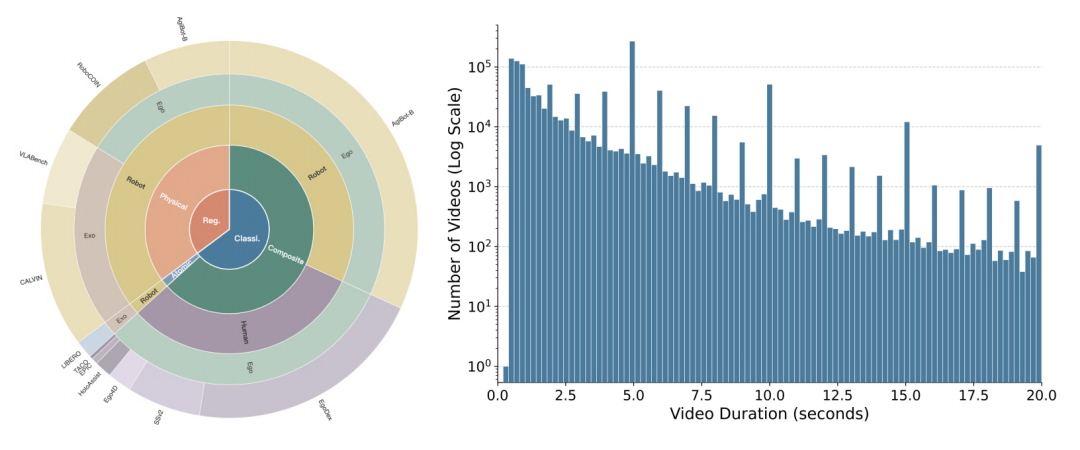
数据构成:组成比例及视频时长分布
其样本空间展现了极高的多样性。动作类别精细划分为本体动作、原子语义动作和复合语义动作三个层级,共计151种,既包含pick、place等基础交互,也覆盖了shovel(积雪)、float(气球)等长尾场景。

语义分布:动作动词与操作对象的词云分析
硬件形态则横跨了从Franka单臂到Agilex Cobot、Realman以及半人形G1在内的11种机器人平台,并深度融合了人类视角的交互数据。
为了实现精准度量,LARYBench构建了一套全链路自动化的多粒度数据引擎。它将视频切片、描述匹配到特征归一化等复杂流程交由算法闭环,极大地提升了海量异构数据的处理效率。
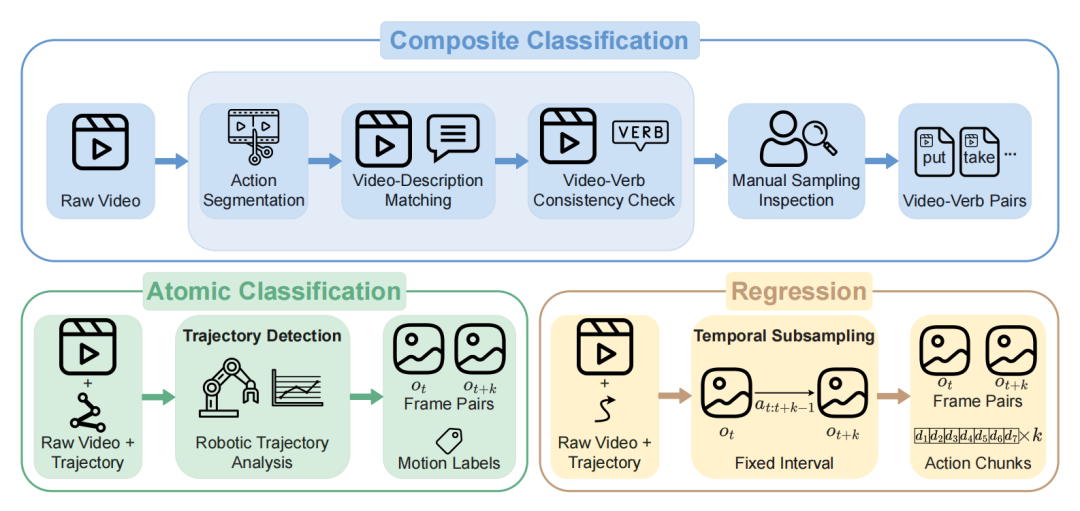
LARYBench数据构建流程:视频切片、描述匹配与一致性检验
系统引入了运动引导采样器(MGSampler),通过计算帧间运动强度确保提取的时序序列包含足够的物理动态变化,并覆盖了从真实住宅厨房到工业场景等多样化环境。



典型动作样例
该基准对数据质量把控严苛,在全链路自动化处理的基础之上,辅助以严格的人工抽检做质检校验。
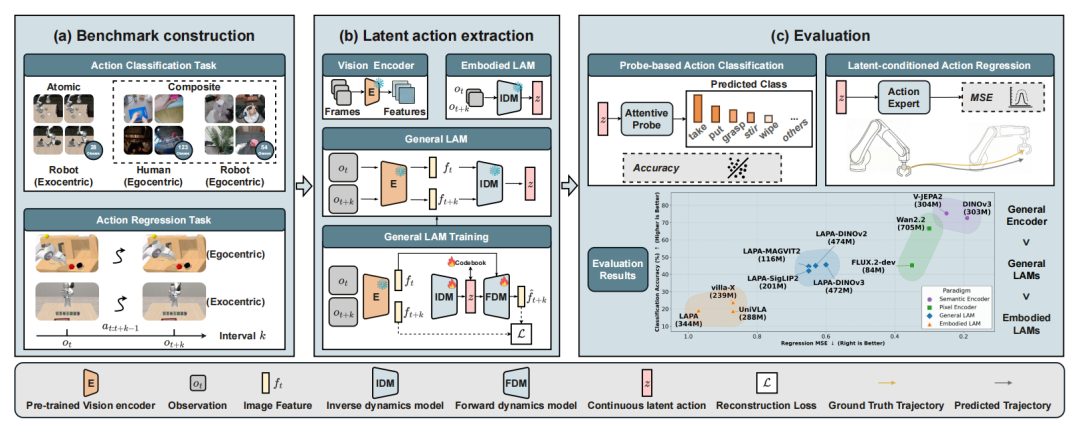
LARYBench整体流程:涵盖数据采样、隐式表征提取及解耦评测任务
如上图所示,在核心评测流程上,系统会首先通过待测模型提取出隐式动作表征z,随后利用浅层探测头进行解耦验证,其评估逻辑最终收敛为两个独立维度:
- 语义动作分类:衡量特征z对动作意图的识别精度,涵盖原子动作与复合行为。
- 本体动作回归:衡量特征z对末端执行器绝对位姿参数(7/12/16-DoF)物理细节的还原能力。
实验解析:从宏观性能到底层机制
为了全方位验证隐式动作表征的有效性,论文系统评估了具身智能领域现有的四类代表性范式:专为具身设计的隐式动作模型(Embodied LAMs)、语义级通用视觉编码器、像素级通用视觉编码器,以及在通用主干上构建的General LAMs。
实验围绕宏观性能、底层物理机制以及超参数规律展开了深入剖析。
通用视觉模型在控制任务中占优
实验数据给出了明确答案,在未接受任何显式动作监督的情况下,通用视觉编码器(如V-JEPA 2、DINOv3)在语义捕捉和底层控制还原上的表现,均明显优于专为机器人研发的Embodied LAMs。
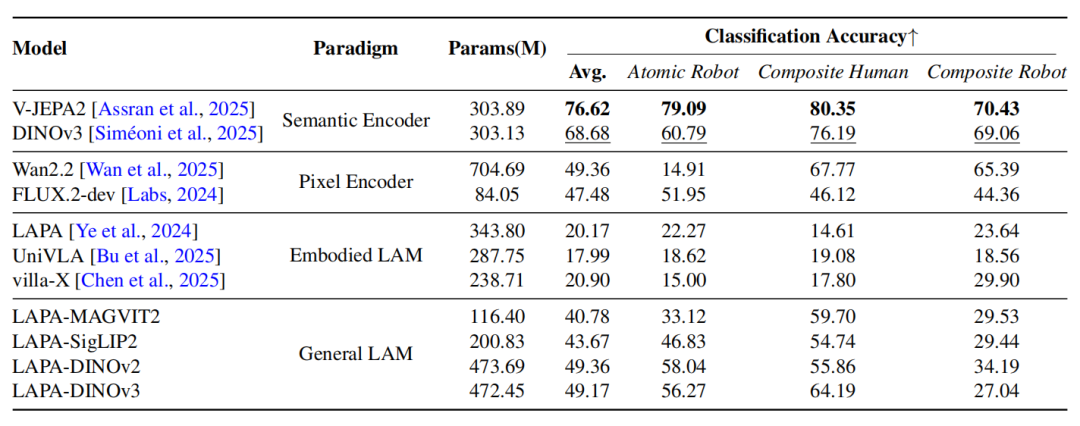
性能对比:模型在原子与复合语义分类任务上的准确率
对比DINOv3与Wan2.2 VAE的表现,DINOv3的平均MSE低至0.19,优于后者的0.30。数据表明,基于隐式特征空间的视觉编码在物理控制对齐上,比像素级生成模型更具精度。
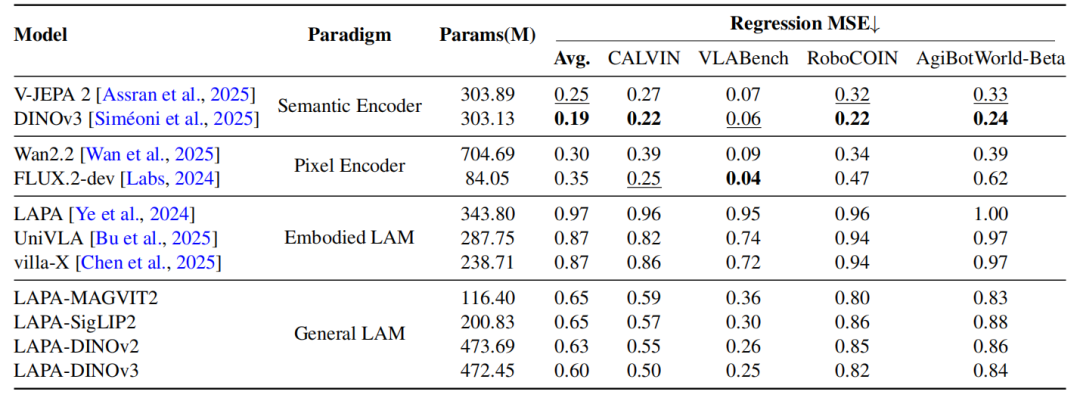
回归误差对比:各模型在单臂及双臂数据集上的表现
研究团队认为,这主要是因为专用的具身模型训练数据较少,或者是过早受到领域特定约束,限制了表征的普适性。
长尾分布的泛化能力进一步印证了这一结论。随着动作频率降低,强模型与弱模型之间的性能差距进一步拉大,证明了高质量计算机视觉预训练能够助力模型在样本稀缺场景中保持精准捕捉。
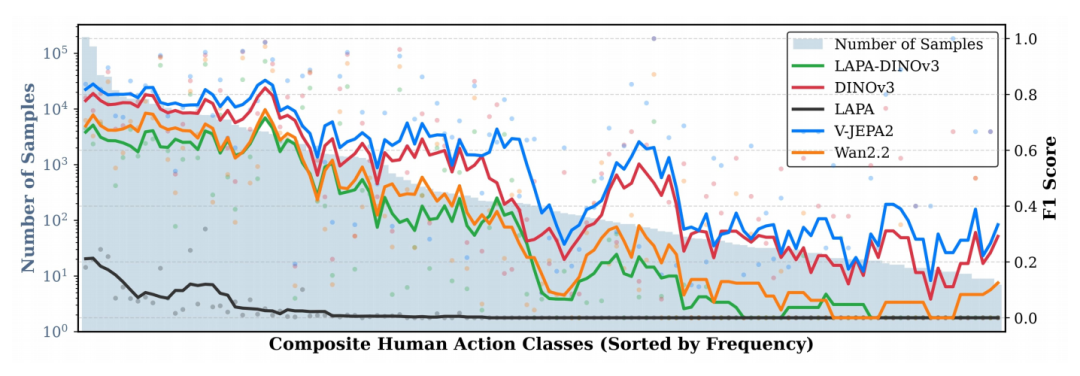
模型在长尾分布动作上的性能表现
动态轨迹编码与注意力聚焦
隐式表征是否真正编码了动作规律,还是仅仅在做静态图像匹配?研究团队通过采样步长(Stride)消融实验给出了证据。
当预测步长从5增加到30时,纯像素级生成模型(FLUX.2-dev)误差严重恶化,MSE飙升至0.62;而隐式动作范式(LAMs)表现出极高的稳定性。这证明了隐空间确实编码并保留了连续的物理运动轨迹。
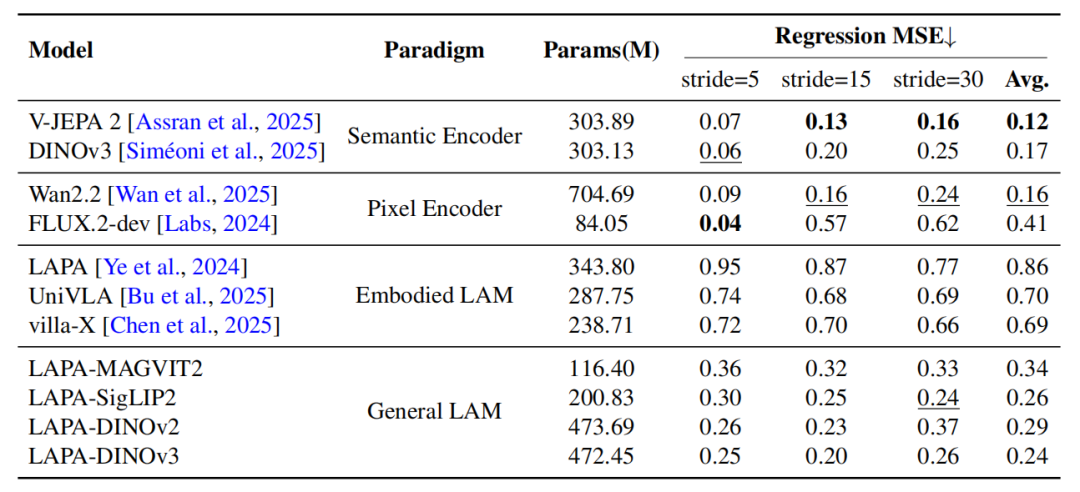
时间稳定性验证:采样步长消融实验结果
交叉注意力热力图直观展示了模型底层的聚焦差异。在倾倒动作序列中,V-JEPA 2和DINOv3能精准聚焦于手部与物体的物理交互区域。相比之下,具身专项模型的注意力呈现弥散状态,像素级模型则易受光影等无关变化的干扰。
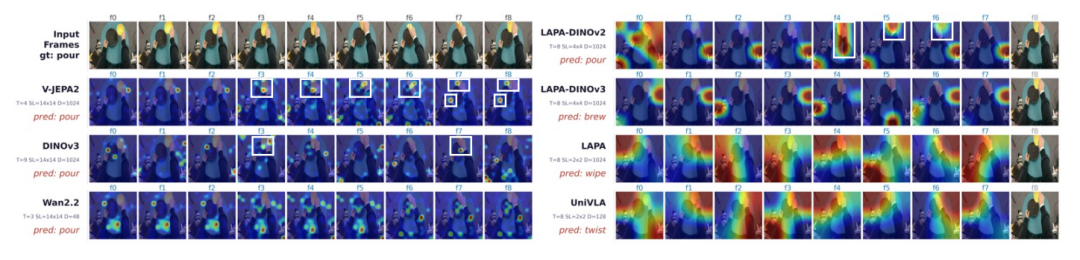
不同模型在倾倒动作序列上的注意力热力图对比
动作表征的超参数规律
为指引General LAMs的构建,实验进一步对关键参数进行了消融分析。结果表明,调整码本大小、序列长度、隐空间维度和学习率等超参可以有效提升动作表征效果:
- 视觉主干是基石:将冻结的通用编码器特征作为输入,训练出的LAM性能显著优于基于像素重建的方案。
- 参数配置的平衡:在合理范围内,增大序列长度和隐空间维度有利于提升特征表达能力。
- 码本的容量界限:实验显示,在当前数据分布下,码本并非越大越好。当容量从64增加到256时,码本利用率降至89.5%,导致性能出现小幅回落。
值得注意的是,超参数的配置与训练数据规模高度相关。目前观测到的性能波动仅基于现有数据量。随着数据规模的进一步扩展,隐式表征的性能边界仍有巨大的提升空间。
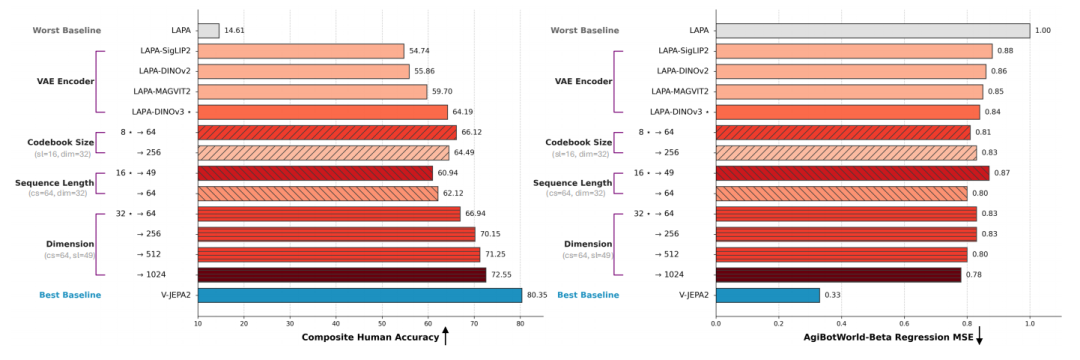
超参消融:不同配置下的性能演进路径
从“看懂”到“行动”的范式转移
LARYBench的实验数据证明,有效的动作先验,完全可以从海量互联网无标注视频中自然涌现。
在未来的VLA模型设计中,与其在极其稀缺的机器人标注数据上从头构建动作空间,不如采用一种更具扩展性的策略。先依托互联网视频庞大的数据规模,学习稳健的动作先验,再将其对齐到底层控制策略中,实现从通用视觉特征空间到物理执行能力的跨越。
这种路径有望帮助具身智能彻底突破现有的数据获取瓶颈,真正将数据的规模优势转化为模型的行动力——通过打通从认知物理世界到执行复杂任务的闭环,指引具身智能走向属于它的GPT时刻。这项研究及相关资源都已开源,为社区提供了宝贵的基础设施,感兴趣的开发者可以前往其 GitHub 仓库获取更多信息。
 发表于 2026-4-19 02:44:28
|
查看: 254|
回复: 0
发表于 2026-4-19 02:44:28
|
查看: 254|
回复: 0
