多模态大模型在视觉与语言任务中表现卓越,但其主流的Decoder-only架构在处理海量视觉Token时,计算冗余问题十分突出。近期一篇由合合信息团队参与完成的论文,提出了一套无需额外训练的动态计算削减方法,通过在模型结构层面引入可选择、可跳过的计算机制,能在基本不影响性能的前提下显著降低推理成本。
论文名称:RedundancyLens: Revealing and Exploiting Visual Token Processing Redundancy for Efficient Decoder-Only MLLMs
中文名称:破解视觉Token冗余,“动态计算削减技术”助力多模态大模型推理“减负”
论文链接:https://arxiv.org/abs/2501.19036v3
所属单位:华南理工大学,合合信息等
多模态大模型两大主流架构
当前多模态大模型的发展已形成两大核心架构,其核心差异集中在视觉Token的处理方式上:
1. Decoder-only(解码器式)架构
结构简洁,无需额外设置跨模态交互层,在复杂多模态理解任务中性能更优,是高性能MLLMs的主流选择。但其存在显著的计算效率瓶颈——对视觉和文本的每个Token均执行全量自注意力和前馈网络(FFN)操作,尤其是在处理高分辨率图像带来的大量视觉Token时,计算资源消耗极大。
2. Cross-attention(跨注意力式)架构
引入专门的跨模态交互层,能够更高效地处理长序列Token,计算成本相对较低。但受限于架构设计,其在复杂多模态任务中的性能通常略逊于Decoder-only架构。
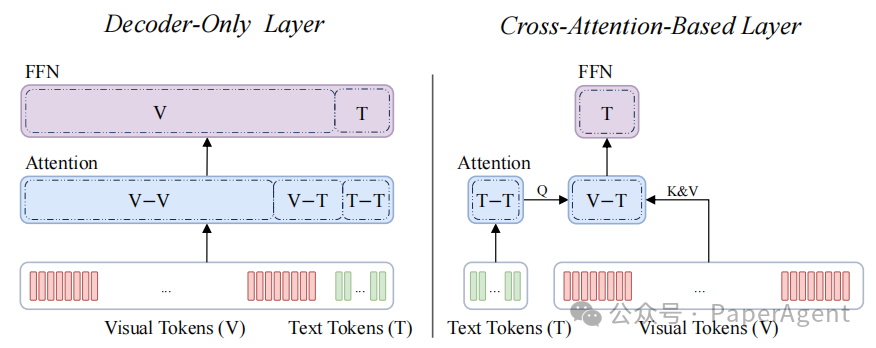
图1. 比较纯解码器架构(Decoder-Only)与基于交叉注意力机制的架构(Cross-Attention-Based);视觉标记的自注意力与 FFN 操作主导了纯解码器层的计算过程
痛点剖析:视觉Token的“冗余”从何而来?
Decoder-only架构虽性能优异,但视觉Token处理存在大量冗余,这些冗余的形成具体可归纳为五点核心原因:
- 模态本质差异:视觉Token来源于图像编码器,包含大量细粒度视觉细节,部分信息在早期层即可完成有效表达;而文本Token是文字的线性映射,需全层深度处理。二者被无差别全量计算,造成了天然的计算浪费。
- 多层重复处理:实验发现,视觉Token在多层堆叠中,会被重复执行相似的自注意力和FFN变换,未产生新的有效信息。
- 长序列处理负担:为捕捉更细粒度视觉细节,模型需不断提升输入图像分辨率和视觉Token数量,导致视觉Token数量远超文本Token。
- 结构化与集群性冗余:Decoder-only模型的视觉Token处理存在结构化、集群式冗余,即部分层的视觉计算可直接省略,且不会影响模型整体性能,说明这些层的计算本身就是冗余的。
- 注意力局部化冗余:自注意力的全局计算在视觉Token上存在大量无效操作,全局注意力计算未提供额外有用信息。
动态计算削减方案
针对上述痛点,研究团队提出一套面向视觉Token的动态计算削减方案,其核心思路是 “不压缩Token、不重新训练、仅在推理阶段动态调整计算” ,主要包括两项关键技术:
- Probe-Activated Dynamic FFN(探测激活动态前馈网络):对FFN中的参数进行动态激活。
- Hollow Attention(空洞注意力机制):对视觉Token的注意力计算进行结构性稀疏化。
- 此外,通过Layer Ranking Algorithm(层级排名算法),决定“在哪些层优先减计算”,以实现整体最优。
用动态模块替代原有 FFN 与 Attention
1. Probe-Activated Dynamic FFN
在标准FFN中,每一层都会对所有视觉Token执行完整的两次线性变换,无论这些Token是否对最终结果有贡献。这种“全量计算”在高分辨率输入下成本极高。
Probe-Activated Dynamic FFN的核心改进是:不再默认激活全部参数,而是根据当前输入动态选择“真正有用”的那一部分参数参与计算。
其机制可理解为“先探测、再计算”:首先,从全部视觉Token中随机采样一小部分作为“探针”,通过这部分Token的前向结果,估计FFN中各个隐藏维度的重要性。具体做法是,对采样Token的中间表示取绝对值均值,作为每个维度的贡献度指标,并据此选出Top-K的关键维度。
优势:无需额外训练,完全训练无关,在推理时动态选择参数,有效降低视觉Tokens的处理成本。
2. Hollow Attention
全局自注意力计算消耗巨大,视觉Tokens之间的全局交互存在明显冗余。通过设计“空洞”注意力,仅保留局部范围内的注意力计算,从而提高效率。
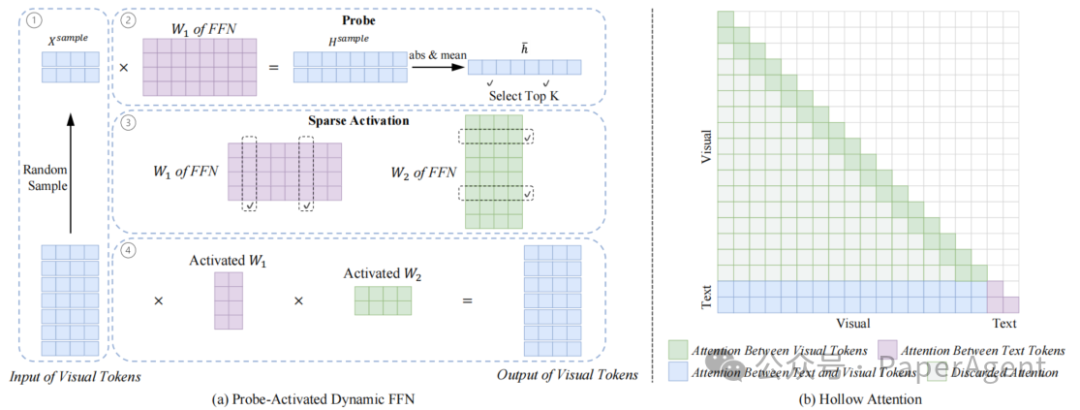
图2. 所提出的视觉标记计算简化方法示意图:(a)探测器激活动态FFN 与 (b)空洞注意力机制
Layer Ranking Algorithm(层级排名算法)
即使引入Dynamic FFN和Hollow Attention,不同层对模型性能的贡献仍有显著差异:部分层承担关键表征能力,部分层则存在明显冗余。
核心思路是:为每一层的视觉Token处理建立重要性排序,用数据来判断“哪些层可以动,哪些层不能动”。具体通过层级特征或指标作为评估标准,计算每一层的分数并完成排序,优先削减排名较低、冗余多且对性能影响小的层。
实验验证
实验结果与分析
1. 视觉token削弱一半仍能稳住性能
实验显示,当削减约50%层的视觉计算时,模型在各基准任务上的性能基本保持不变,甚至在部分任务中略有提升;当削减比例超过50%时,模型性能显著下降,其中FFN计算的削减对性能的影响更为明显。这验证了“削减约50%层为最优平衡点”的结论。
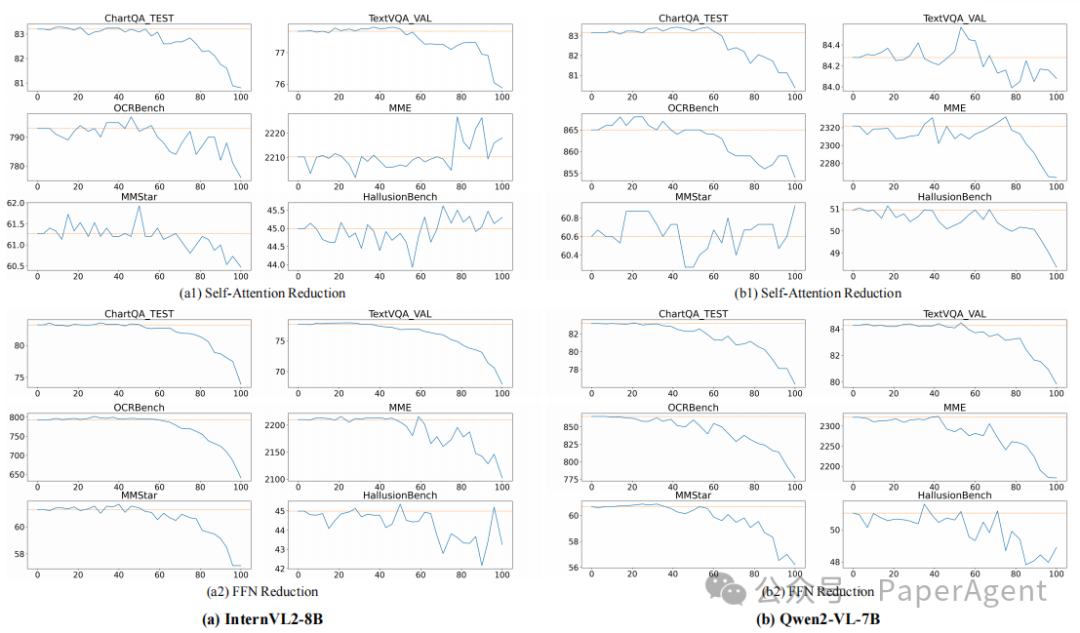
图3.在不同层比例下应用自注意力机制或 FFN 减少的影响
2. 冗余主要不在文本,而在视觉Token
对比“仅削减视觉Token计算”与“削减全量Token计算”的性能差异:仅削减视觉Token计算时,模型性能保持稳定;而削减全量Token计算时,性能急剧下降。这证实了冗余主要集中在视觉Token处理部分,精准削减视觉Token计算可实现效率提升与性能保持的平衡。
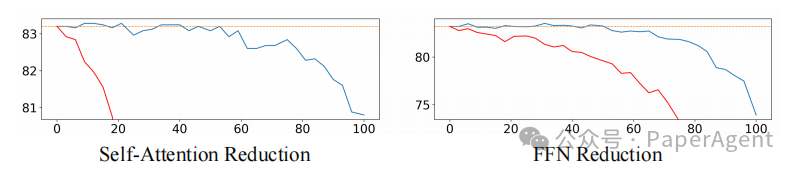
图4. 基于InternVL2-8B在ChartQA上的评估结果,对视觉标记与所有标记所应用的削减效果进行性能比较
3. 与现有视觉Token压缩技术具有兼容性
实验对比了不同三种加速方案的FLOPs与性能表现,结果如下表所示。可以看出:本文提出的方案可将模型FLOPs降至50%左右,计算量近乎减半,但是性能基本保持不变;同时,该方案可以与现有的Token压缩方法无缝结合。
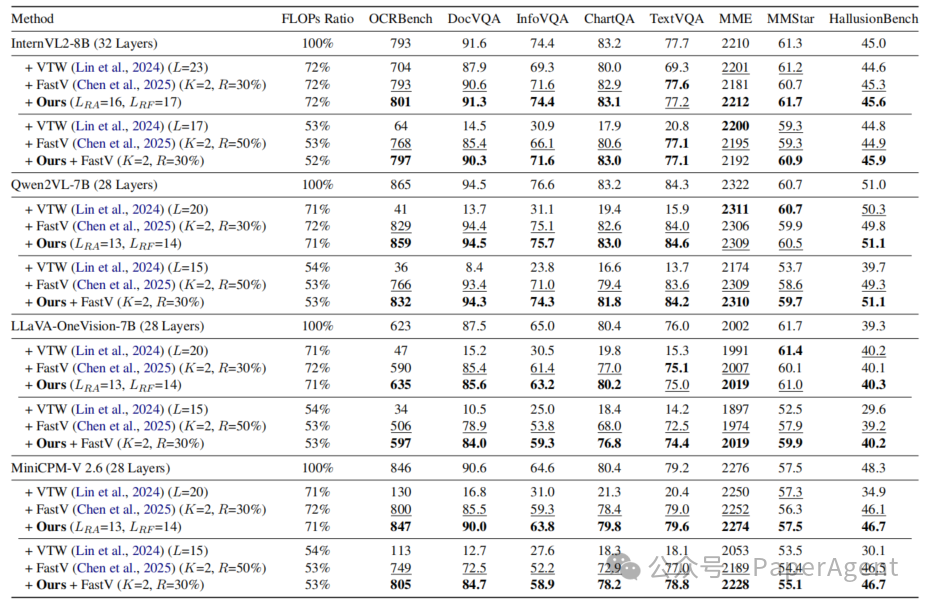
表1. 加速 MLLM 推理的无训练方法对比
结论与应用
核心结论
- Decoder-only架构的视觉Token冗余源于模态本质差异、多层重复处理等五点核心原因,且冗余呈现结构化、集群化特征,可被精准定位与利用。
- 本文提出的动态计算削减方案,以Probe-Activated Dynamic FFN与Hollow Attention为核心技术,结合层级排名算法,实现了在性能基本无损的前提下显著减少模型计算量,适用于对响应速度和算力资源敏感的真实应用场景。
落地应用
本文提出的动态计算削减技术,具备训练无关、低侵入、高兼容的特点,可广泛应用于多模态大模型的大规模落地,具体场景如下:
- ToB场景:适用于企业级文档扫描与识别、合同与票据OCR、表单信息抽取、智能审核与质检系统等。在高并发、有限算力或本地化部署场景中,可在保持高准确率的同时,显著降低算力与能耗成本。
- ToC场景:适用于手机端拍照识别、即时翻译、智能搜索、辅助阅读等应用。可使模型在移动设备或实时交互场景中,实现低延迟、低功耗运行,提升用户体验。
- 通用价值:打破了高性能Decoder-only多模态模型对高算力环境的依赖,使其可在端侧、边缘设备等算力有限的场景中轻量化部署,推动多模态大模型与人工智能技术在全行业的普及。对于希望深入了解此类前沿模型优化技术的开发者,欢迎到 云栈社区 交流探讨。
 发表于 2026-4-9 03:45:15
|
查看: 155|
回复: 0
发表于 2026-4-9 03:45:15
|
查看: 155|
回复: 0
