沉寂许久的Ian Goodfellow,终于再次现身于AI研究的前沿视野。
这位在2014年提出生成对抗网络(GAN)、一手开启AI生成技术早期浪潮的研究者,近年来在新一轮由大模型主导的竞赛中发声并不频繁。直到最近,他与两位重量级合作者共同发表了对下一代人工智能核心组件——世界模型(World Models)的深刻见解。
这篇文章题为《Towards Efficient World Models》,作者阵容堪称豪华:
- Ian Goodfellow:生成模型时代的开创者,GAN之父。
- Chris Manning:NLP先驱、斯坦福大学教授,自然语言处理与大语言模型领域的顶尖学者。
- Fan-Yun Sun:Moonlake AI联合创始人兼CEO,研究方向集中在多模态世界模型。
他们共同提出的核心观点是:利用符号化表示(symbolic representations)以及游戏虚拟世界的数据,可能是构建具备动作条件(action-conditioned)的多模态世界模型的最佳路径。这类模型旨在实现对长时序任务(long-horizon tasks)进行可靠的预测与规划。
文章地址:https://x.com/moonlake/status/2029983120087470545
以下是文章的核心内容梳理:
什么是世界模型?
当人类生活在世界中时,我们不仅能感知当下,还能预测未来并规划行动。这种能力的背后,需要一个高效的世界模型。
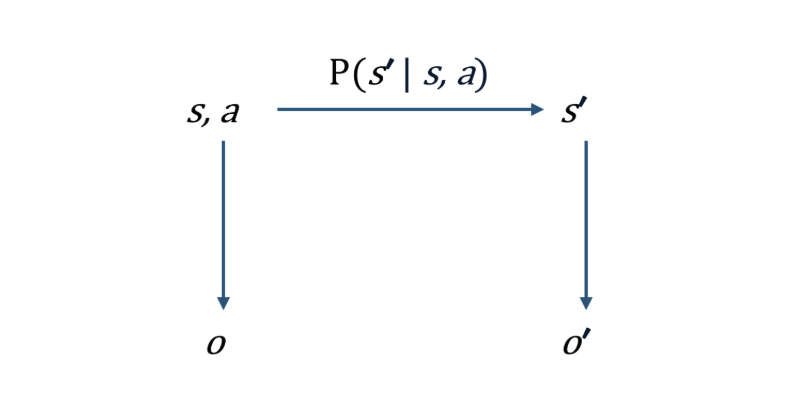
在技术层面,世界模型是指能够表示环境动态变化与因果结构的模型。在强化学习框架中,它通常被形式化为对部分可观测马尔可夫决策过程(POMDP)中状态转移函数 $P(s’|s, a)$ 的近似。简单说,就是给定当前状态 $s$ 和动作 $a$,预测下一个状态 $s’$ 的概率。
拥有世界模型,意味着我们可以基于内部的心理模拟进行预测和规划,而无需事事通过真实交互试错。但关键是,人类只能获得对真实状态的部分观测 $o$,这为我们理解与构建世界模型增加了挑战。
从文本到多模态
像ChatGPT这样的大语言模型,仅通过文本就能学习到某种潜在的“世界模型”,在其参数中隐含着对物理和社会世界的表示与因果理解。然而,现实世界远不止文本,还包括视觉、声音等多种模态。因此,文章将焦点放在了多模态世界模型上。
我们为何要构建世界模型?
目标是为了实现具有巨大经济价值的AI能力,让机器能理解行动在时间维度上的后果,而不仅仅是识别数据模式。关键在于掌握因果关系——例如,大喊可能导致他人不开心,但反之则不成立。作者认为,在多模态环境中进行因果推理的能力,是通向具身AGI的核心之一。
像素模型 vs. 符号抽象
提到多模态世界模型,许多人会想到Sora、Genie 3这类生成式视频模型。它们能产生逼真的像素级画面,但在捕捉世界的因果结构上可能存在局限。例如,它们可能无法清晰理解“打方向盘”是“汽车转弯”的原因。
更重要的是,对于许多需要规划和决策的任务而言,我们真的需要高分辨率的像素视图吗?人类在完成绝大多数现实任务时,并不依赖完整的像素解析,而是依赖于对象层级的抽象表示和语义理解。
人类的特殊之处在于我们发展出了强大的认知工具,如自然语言、数学和编程语言。这些符号化工具让我们能以高度抽象、高效的方式表达和推理因果关系。将这种抽象能力赋予AI模型,可以让它们将表示能力集中在真正影响决策的要素上,从而在数据和计算上更高效,就像代码生成模型通过操作符号(代码)而非底层机器状态一样。
数据从何而来?
数据是构建有效模型的关键。目前互联网充斥着海量视频数据,但能明确展示“行动-结果”对应关系的数据却非常稀缺。作者指出,一条更具数据效率和计算效率的路径,是利用软件抽象构建多样化的合成世界(如游戏虚拟环境)来增强训练。
符号表示(如代码、自然语言)本身就是一种高度可扩展的数据采集接口(键盘、鼠标),也更适合人类进行精细控制。它们形成了一个同时包含行动与观测的数据飞轮。一个由人类操作的模拟环境,其最自然的交互接口正是这类符号系统。
可行的商业化路径
文章最后强调,一条能够实现商业自我持续的路径至关重要。只有当商业化激励持续推动数据产生和模型改进时,能力才能螺旋上升。像游戏这样的交互式媒体,既能提供明确的参与激励(娱乐),又具备可扩展的数据采集接口,让数据自然积累,是构建世界模型的理想起点。
这条路径的最终目标,是形成一个能够生成环境、并用于训练和控制任何具身智能体(无论在虚拟还是现实世界)的成熟模型。
展望
作者并非否定像素表示的价值,也不认为未来只存在一种统一的世界表示形式。关键在于,世界模型的设计应围绕我们希望学习到的策略(policy)展开,并借助合适的抽象工具,让模型聚焦于影响决策的核心环境因素,从而在效率与能力间取得更优平衡。
如果目标是理解多模态环境中的因果关系,那么无论模型服务于虚拟还是物理世界,它都需要优先保证在长时序上空间与物理状态的一致性,并能真实反映行动带来的后果。这正是Moonlake团队目前致力探索的方向。这一技术动向也值得我们所有关注人工智能前沿的开发者在云栈社区进行深入的交流与探讨。面对海量虚拟世界数据的运用与抽象方法的选择,你的看法是什么?
 发表于 2026-3-8 05:51:10
|
查看: 109|
回复: 0
发表于 2026-3-8 05:51:10
|
查看: 109|
回复: 0
