如何看待当前大火的 Agent Skill(智能体技能)?与其在碎片信息里打转,不如系统性地“啃”下两篇高质量综述。一篇回答关于技能生命周期的四个基本问题,另一篇则深入讲解技能的四种自动演化范式和六类核心评测基准。两者互相补充,是深入该领域不错的索引。
一、Agent Skill的4个基本问题:表示、获取、检索及演化策略
我们之前曾讨论过一个围绕技能生命周期(表示、获取、检索、演化)展开的研究总结。它将智能体技能定义为可复用的过程性工件,用以弥补工具调用与可靠执行间的过程鸿沟。该工作系统梳理了四类技能获取方式、多维度检索与选择策略,以及全链路演化机制。
相关成果来自论文:A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications ( https://arxiv.org/pdf/2605.07358 )。研究论文、开源数据与项目均已整理并汇总于 https://github.com/JayLZhou/Awesome-Agent-Skills 。这里做个简单的回顾:
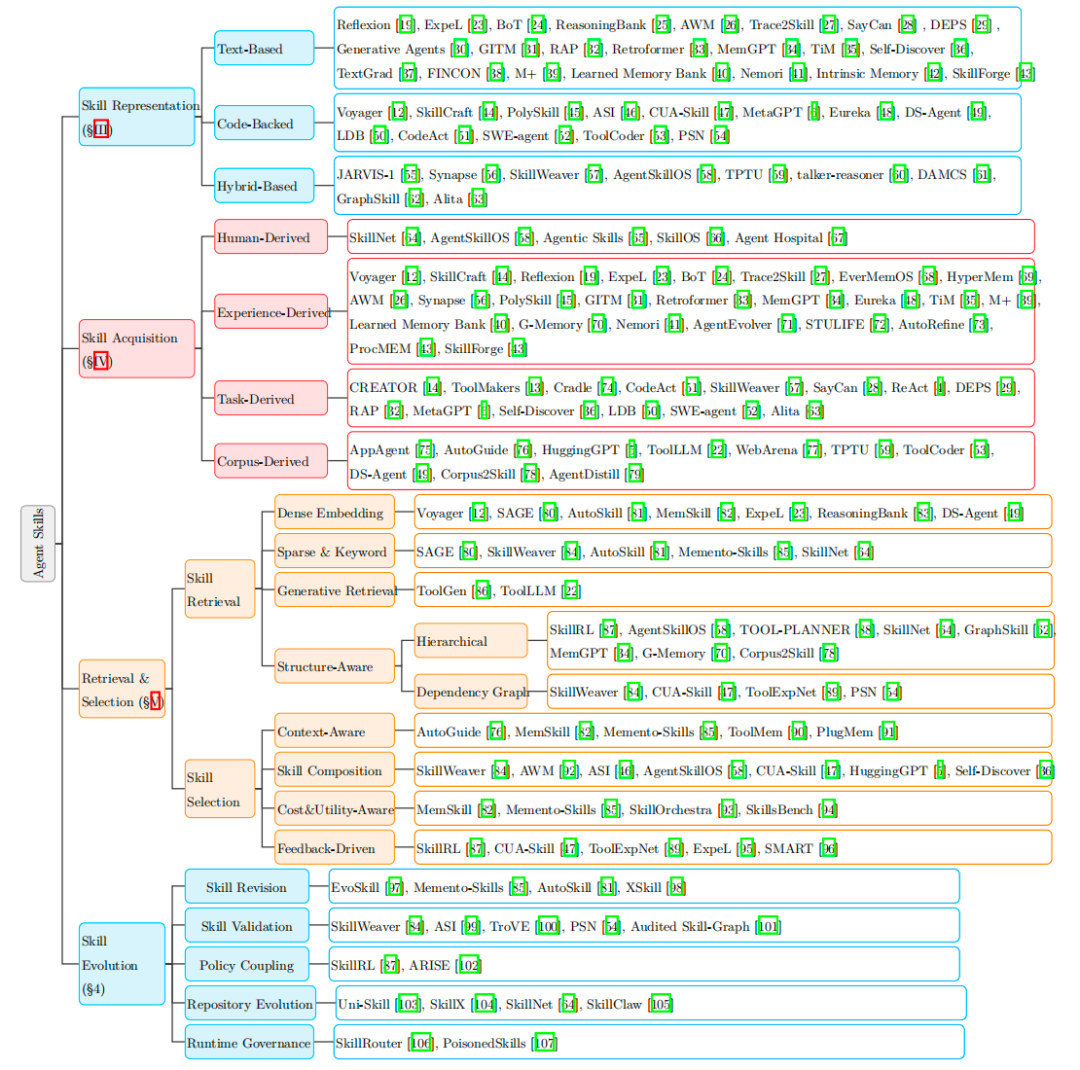
具体解读可参考这里: https://mp.weixin.qq.com/s/49qzXvT5HdWdEyZGXNnVIg ,此处不再赘述。
二、Agent Skill的4种自优化方式和6类评测基准
另一篇值得精读的综述:Agent Skill Evaluation and Evolution: Frameworks and Benchmarks ( https://arxiv.org/pdf/2606.11435 ),其核心就讲两件事:技能怎么自动优化迭代,又该怎么科学评测好坏。 对应的开源项目地址是: https://github.com/Cassie07/AgentSkill_Survey
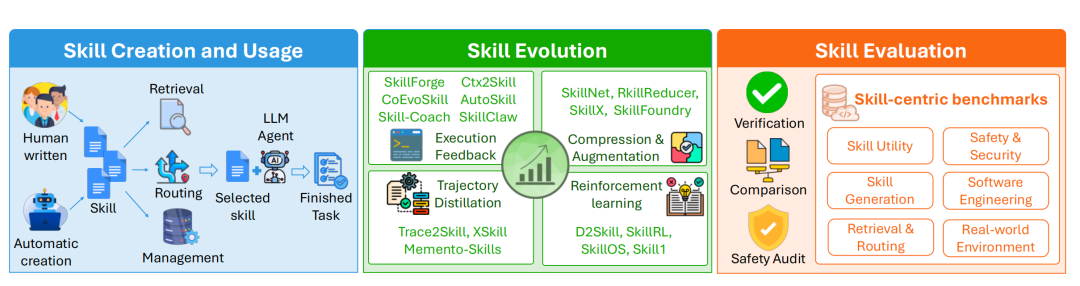
首先,它对"技能"做了一个形式化界定:技能被定义为结构化包 S=(C,π,T,R)。其中,C(Condition,条件) 根据智能体观测与任务目标准确判断技能是否适用;π(Policy,执行策略) 编码了具体操作流程;T(Termination,终止准则) 判定技能何时执行结束;R(Reusable Interface,可重用接口) 则支持技能间的组合调用。技能本身分为人工编写与自动化创建两类。
基于此,我们来重点拆解技能的四种自动演化方式和六类评测基准。
1. 技能自动优化的4种方式
这四种范式分别作用于不同层级:执行反馈面向单次运行的细粒度步骤级信号;轨迹蒸馏面向多次运行的序列级模式;压缩与增强作用于整个技能库的结构;强化学习则从任务级奖励出发进行优化。
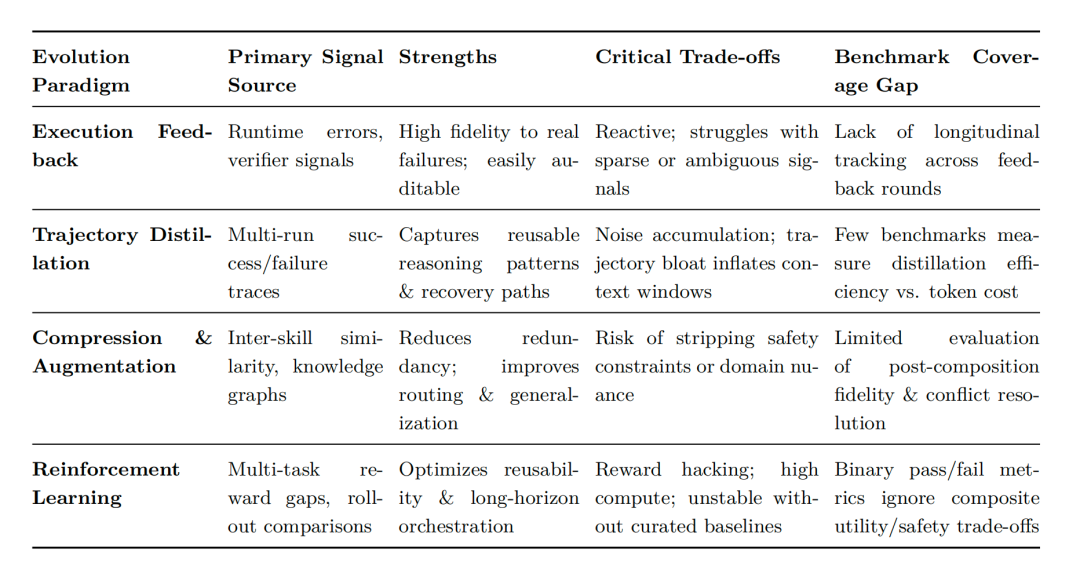
1) 执行反馈 (Execution Feedback)
原理是基于单次执行中的细粒度信号(如运行报错、错误输出、用户偏好等)来修正技能,这很像人工查找并修正 bug 的过程。代表方法有 SkillForge、CoEvoSkills、Skills-Coach、AutoSkill、SkillClaw 等。
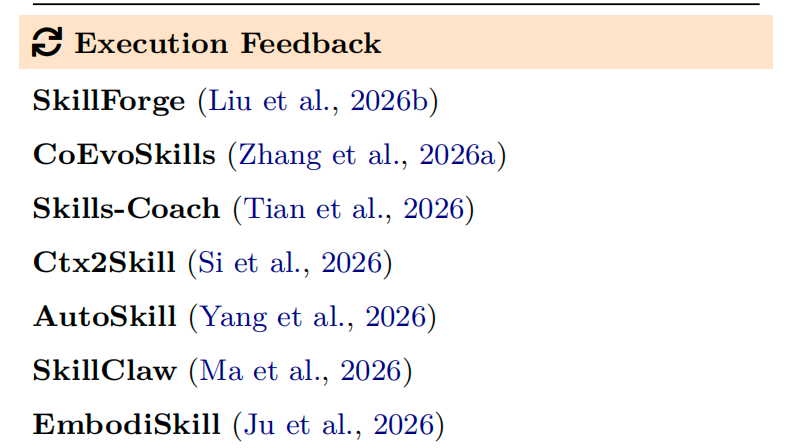
其本质是:技能执行时报错或结果不对,系统就自动去查问题、改 bug。优点是修问题准、高保真到真实失败案例;缺点在于是一种被动补漏模式,没有报错信号就无法启动优化。因此,识别失败与生成重写这两个环节的有效区分,是完善反馈环的关键。
2) 轨迹蒸馏 (Trajectory Distillation)
它挖掘多次任务运行的完整轨迹序列,从成功和失败案例中提炼出通用的、可复用的执行模式,进而形成新技能或优化旧技能。代表方法有 SPARK、Trace2Skill、Memento-Skills,以及拓展至多模态视觉轨迹的 XSkill。
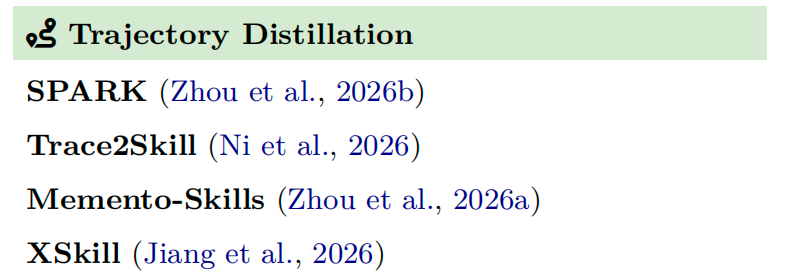
简而言之,这就是把多次执行的完整流程“扒”出来,总结归纳出通用靠谱的步骤,沉淀成一个新技能。好处是总结经验和复用模式的能力强;但原始轨迹本身带有噪声和冗余,容易导致上下文过度膨胀。在现实操作中,可以通过比较多次运行间的模式来进行蒸馏以发现可复用知识。更重要的是,需预先准备高质量轨迹,并显式地以质量和多样性为标准进行筛选,而非随意使用所有可用数据。
3) 压缩与增强 (Compression & Augmentation)
这种方式面向整个技能库进行全局优化,旨在解决技能冗余、内容冲突、覆盖不足以及 Token 消耗过高等问题。"压缩"负责精简冗余、降低成本;"增强"负责补全覆盖、合并同类项或拆解复杂技能。代表方法有 SkillNet、SkillX、SkillReducer、SkillFoundry。

当技能库变得臃肿混乱时,这种方法通过合并重复、精简描述来"瘦身提效",同时查漏补缺。最大的风险在于,不当的压缩可能误删核心执行逻辑、安全约束或领域细节。因此,一个稳妥的流程是:压缩前,将核心可执行步骤标注为受保护的参考;压缩后,使用保留的测试用例集对演化后的技能进行回归测试,以确认性能无损。
4) 强化学习 (Reinforcement Learning)
依托任务级的全局奖励(如技能复用率、任务成功率),以迭代方式更新技能策略,着重解决技能跨任务复用的问题。多数方法基于 GRPO 框架进行改进,代表有 D2Skill、SkillRL、SkillOS,以及旨在解决组件碎片化问题的统一演化框架 Skill1。
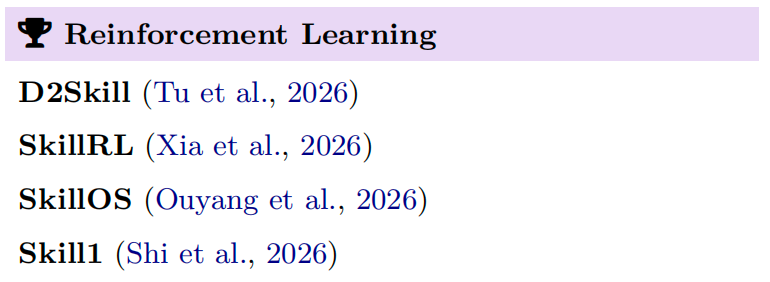
此方法将任务成败作为奖励信号,反复训练使技能更好用、适配更多场景。优点是跨任务复用性很强;缺点是计算开销高昂,且易出现"奖励投机"问题。主流的二元(成功/失败)指标,根本无法区分性能的提升究竟是源于技能本身的改进,还是模型基础能力的增强。为了更准确地评估,可以在定期训练间隔中,分别测试"使用技能"与"不使用技能"下的任务表现,并将这二者的性能差距作为真实的技能贡献信号。
2. 技能评测的6类方式及代表
如何科学地判定一个技能的好坏?这需要构建多维度的评测体系,大致可归为以下六类:
1) 技能效用基准 (Skill Utility)
评估技能对任务完成率的实际提升效果,侧重量化其业务价值。代表评测有:覆盖 11 大专业领域的 SkillsBench,以及专注于长时序工具调用和技能复用的 SkillCraft。

2) 技能生成基准 (Skill Generation)
用于量化自动化生成技能的质量与复用能力,核心在于区分高质量与低质量技能,防止错误累积。代表评测为 SkillLearnBench。

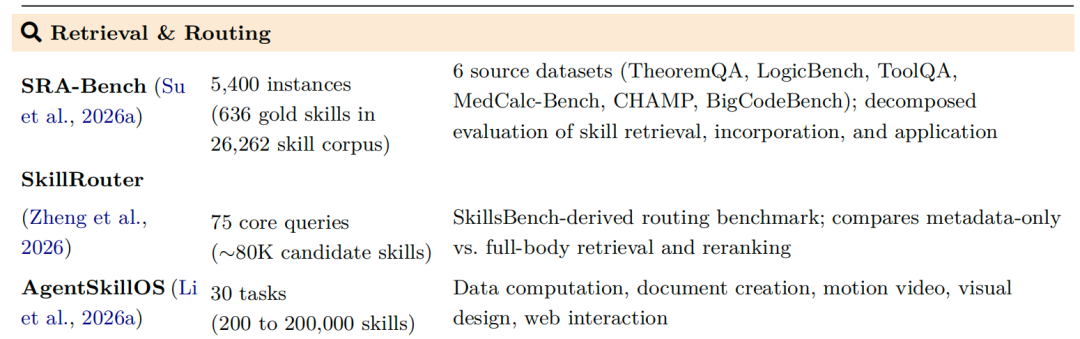
3) 技能检索与路由基准 (Retrieval & Routing)
评估在拥有大规模技能库的场景下,系统筛选、调度和协同编排多个技能的能力。代表评测有 SkillRouter、SRA-Bench、AgentSkillOS。这些评测普遍揭示了一个结论:仅靠技能的名称或简短描述进行检索,准确率会大幅下降。
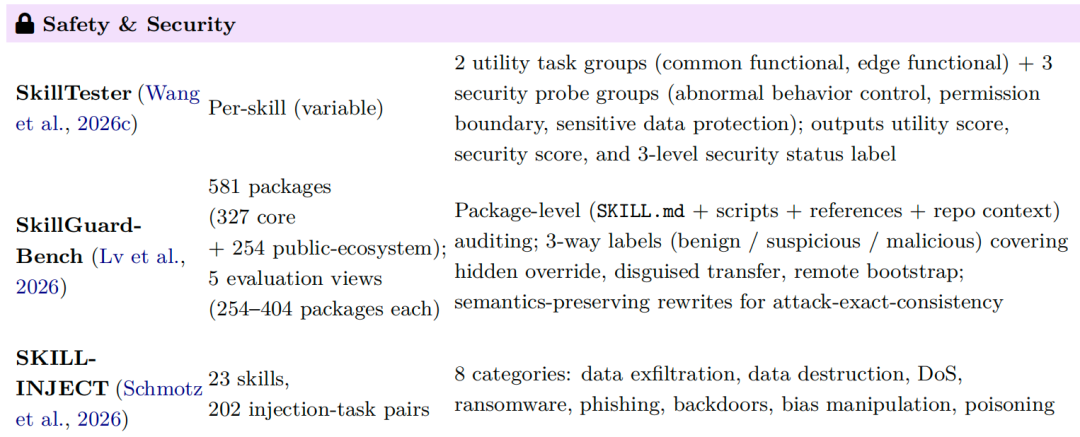
4) 技能安全审计基准 (Safety Auditing)
用于检测恶意技能、运行时漏洞,防范数据泄露、指令劫持等风险。它覆盖隐藏覆盖、伪装转移、远程引导等多种攻击模式。代表评测有 SkillTester、SkillGuardBench、SKILL-INJECT。
5) 软件工程基准 (Software Engineering)
面向代码开发、运维等场景评估技能效果。代表评测为 SWE-SkillsBench,它依托公开代码仓库构建,可复现性较强,但目前在私有工程、遗留代码等复杂场景上仍有欠缺。

6) 真实环境基准 (Real-world Environment)
将技能部署到开放、动态的真实世界场景中进行测试,更贴近实际应用。代表评测有 WildClawBench 和 SkillForge 基准。不过,封闭式的测试环境也给跨方法对比和结果复现带来了一定挑战。

参考文献
- https://mp.weixin.qq.com/s/49qzXvT5HdWdEyZGXNnVIg
- https://arxiv.org/pdf/2606.11435
 发表于 2026-6-15 23:22:27
|
查看: 248|
回复: 0
发表于 2026-6-15 23:22:27
|
查看: 248|
回复: 0
