上下文窗口是大语言模型、Transformer、自然语言处理、文本生成和 AI 应用开发中非常重要的一个术语。它用来描述:模型一次能够接收、保留并参与计算的最大文本范围。换句话说,上下文窗口回答的是:模型在一次对话或一次推理中,最多能“看见”多少内容。
如果说 token 是模型处理语言的基本单位,那么上下文窗口就是模型一次能容纳的 token 数量上限。用户输入、系统提示、历史对话、检索资料、工具返回结果和模型生成内容,通常都会占用上下文窗口。
因此,上下文窗口常用于长文本处理、多轮对话、RAG 检索增强生成、文档问答、代码分析、摘要生成和大语言模型应用设计中,是理解语言模型能力边界的重要基础概念。
一、基本概念:什么是上下文窗口
上下文窗口(Context Window)指模型在一次推理过程中能够处理的最大 token 范围。
例如,一个模型的上下文窗口为:8192 tokens,这并不表示它一定能处理 8192 个汉字,也不表示能处理 8192 个英文单词,而是表示它最多能处理大约 8192 个 token。
在大语言模型中,一次请求通常包含:
• 系统提示
• 用户输入
• 历史对话
• 检索到的文档片段
• 工具返回的信息
• 模型需要生成的输出
这些内容加起来,都要放进上下文窗口中。可以简单表示为:
$$T_{input} + T_{output} \le T_{window}$$
其中:
• $T_{input}$ 表示输入部分占用的 token 数
• $T_{output}$ 表示输出部分需要生成的 token 数
• $T_{window}$ 表示模型上下文窗口大小
从通俗角度看:上下文窗口就像模型当前工作台的大小。工作台越大,一次能摊开的资料越多;工作台越小,就必须选择最重要的内容放上去。
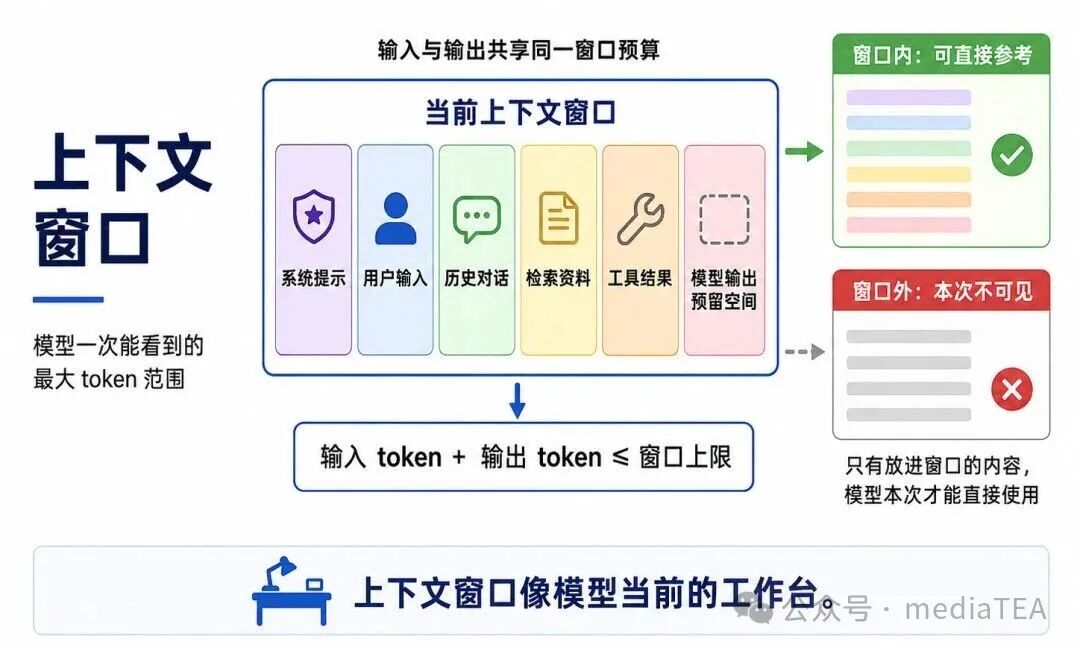
图 1:上下文窗口的基本思想
需要注意:上下文窗口不是模型的永久记忆。它只表示模型在当前一次计算中能看到的内容范围。超出窗口的内容,如果没有被重新提供、压缩或检索回来,模型通常无法直接使用。
二、为什么需要上下文窗口
上下文窗口之所以重要,是因为语言模型生成答案时,需要基于当前可见信息进行判断。
模型不是凭空在无限长的历史中查找所有内容,而是在当前上下文窗口内进行计算。
例如,用户让模型总结一篇文章,模型需要看到文章内容;用户让模型继续多轮对话,模型需要看到相关对话历史;用户让模型根据资料回答问题,资料也必须进入上下文窗口或被外部工具检索后提供。
上下文窗口的作用主要包括:
• 决定模型一次能处理多长文本
• 决定多轮对话中能保留多少历史
• 决定 RAG 中能放入多少检索片段
• 决定代码分析中能看到多少文件内容
• 决定模型生成时能参考多少前文
从通俗角度看:上下文窗口决定模型“当前能读到多少材料”。
如果关键信息在窗口内,模型就可以利用它。
如果关键信息不在窗口内,模型就可能不知道、遗忘或只能根据已有信息猜测。
因此,在长文档问答、论文分析、项目代码理解等任务中,上下文窗口大小会直接影响模型表现。
三、上下文窗口与 token 的关系
上下文窗口通常按 token 计算,而不是按字数、词数或页数计算。这点非常重要。
例如,一段中文、英文、代码、公式、表格,在人类看来长度可能相近,但被 tokenizer 切分后的 token 数可能不同。
一段文本经过 tokenizer 后,可以表示为:
$$t_1, t_2, \dots, t_L$$
其中:
• $t_1, t_2, \dots, t_L$ 表示 token 序列
• $L$ 表示 token 数量
如果模型最大上下文窗口为 $M$,则输入 token 数必须满足:
$$L \le M$$
其中:
• $L$ 表示当前输入 token 数
• $M$ 表示模型最大上下文 token 数
如果 $L$ 超过 $M$,就不能一次完整放入模型。
从通俗角度看:上下文窗口的单位不是“字”,而是“模型切分后的文本块”。
例如:
• 中文文本可能接近按字、词或子词切分
• 英文单词可能是一个或多个 token
• 代码中的符号、缩进、变量名可能占用较多 token
• 表格、JSON、公式也可能快速消耗 token
因此,不能简单用页数或字符数估算上下文窗口。真正影响模型的是 token 数。
四、上下文窗口在对话中的作用
在多轮对话中,上下文窗口决定模型能参考多少历史内容。
一段对话可以理解为不断增长的上下文:
第 1 轮用户问题
第 1 轮模型回答
第 2 轮用户问题
第 2 轮模型回答
……
当前用户问题
这些内容都会占用上下文窗口。
随着对话变长,早期内容可能会被压缩、裁剪,或者不再完整出现在当前上下文中。
从通俗角度看:模型在当前回答时,主要依赖它此刻能看到的对话内容,而不是自动拥有无限长的聊天历史。
这就是为什么在很长的对话中,模型有时会:
• 忘记很早之前的细节
• 混淆旧任务和新任务
• 需要用户重新提供背景
• 更适合把关键信息整理成摘要
为了让长对话更稳定,可以采用:
• 明确重述当前任务
• 保留关键约束
• 定期总结上下文
• 把重要资料单独整理
• 避免把无关内容长期混在同一对话中
例如,在写作任务中,如果文章格式、公式规范、术语风格很重要,最好在当前请求中再次说明关键要求。
五、上下文窗口与注意力机制
在 Transformer 中,模型通常通过注意力机制让每个 token 参考上下文中的其他 token。
如果输入序列为:
$$t_1, t_2, \dots, t_L$$
那么模型在处理某个 token 时,可以根据注意力机制从其他 token 中获取信息。
简化地说,注意力机制会计算 token 之间的相关性:
$$Attention(Q, K, V) = softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
其中:
• $Q$ 表示查询向量
• $K$ 表示键向量
• $V$ 表示值向量
• $d_k$ 表示键向量维度
• $softmax$ 用于把相关性转换成权重
上下文窗口越大,模型理论上能看到的 token 越多。但是,更长的上下文也意味着计算成本更高。
在标准注意力中,注意力计算量通常会随序列长度增加而快速增长。直观上,$L$ 个 token 之间需要两两比较,复杂度常近似理解为:
$$O(L^2)$$
其中:
• $L$ 表示序列长度
• $O(L^2)$ 表示计算量随 $L$ 的平方级增长
从通俗角度看:上下文越长,模型能参考的信息越多,但也需要处理更多 token 之间的关系,计算压力会增加。
因此,长上下文模型不仅需要更大的窗口,也需要更高效的注意力机制、缓存机制或工程优化。
六、上下文窗口与长文本处理
当文本长度超过上下文窗口时,模型不能一次完整读取全部内容。这在论文、书籍、长报告、代码仓库、法律文档和企业知识库中很常见。
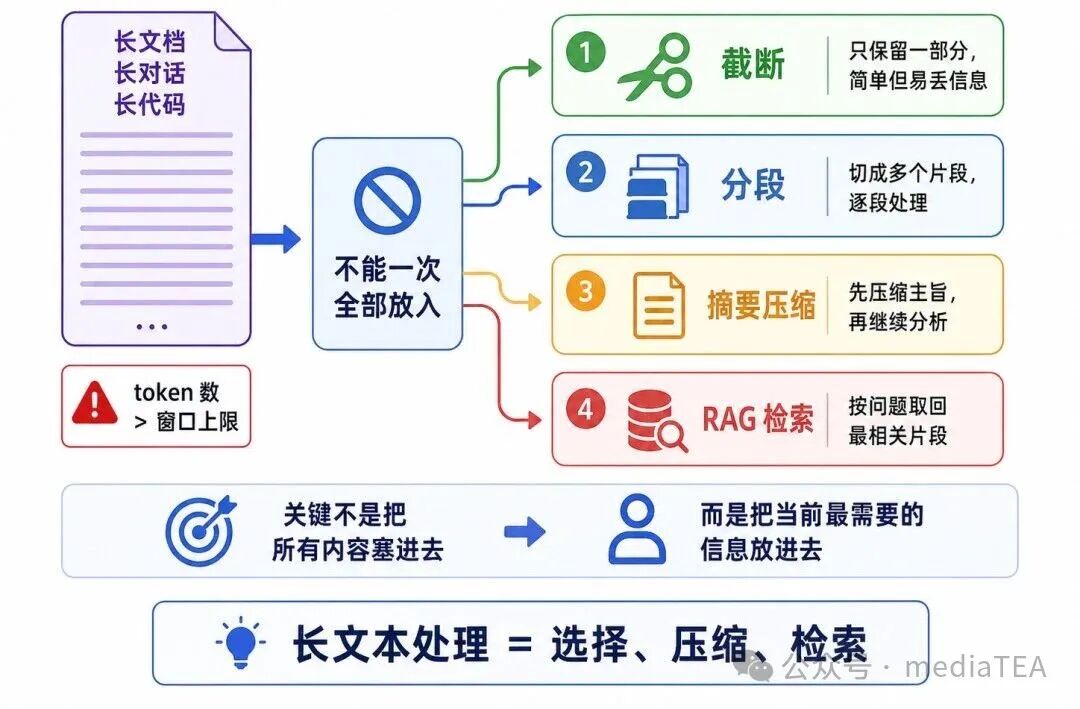
图 2:长文本超出窗口的常见处理方式
常见处理方式包括以下几种。
1、截断
截断是最简单的方法。只保留前面或后面一部分文本,丢弃其他内容。
优点是简单。缺点是可能丢掉关键信息。
例如,如果答案依据在被截断的部分,模型就无法正确回答。
2、分段处理
把长文档切分成多个片段,分别处理。
例如:
第 1 段 → 总结
第 2 段 → 总结
第 3 段 → 总结
……
汇总所有摘要
这种方式适合长文总结、章节分析和分步处理。
3、摘要压缩
先把长文本压缩成较短摘要,再把摘要放入上下文窗口。
这种方法适合保留主旨信息,但可能损失细节。
4、检索增强生成
RAG 会先根据问题检索相关片段,再把最相关的片段放入上下文窗口。它不要求模型一次读完整个知识库,而是按问题动态取回需要的内容。
从通俗角度看:长文本处理的关键不是“把所有东西塞进去”,而是“把当前任务最需要的信息放进去”。
七、上下文窗口与 RAG
RAG 是 Retrieval-Augmented Generation,通常译为“检索增强生成”。这个技术正是为了突破上下文窗口的物理限制而设计的,通过先检索再回答的方式,让模型不必一次性吞下整个知识库。
在 RAG 中,外部知识库不会全部放进模型,而是先进行检索。
基本流程是:
用户问题 → 检索相关片段 → 放入上下文窗口 → 模型生成答案
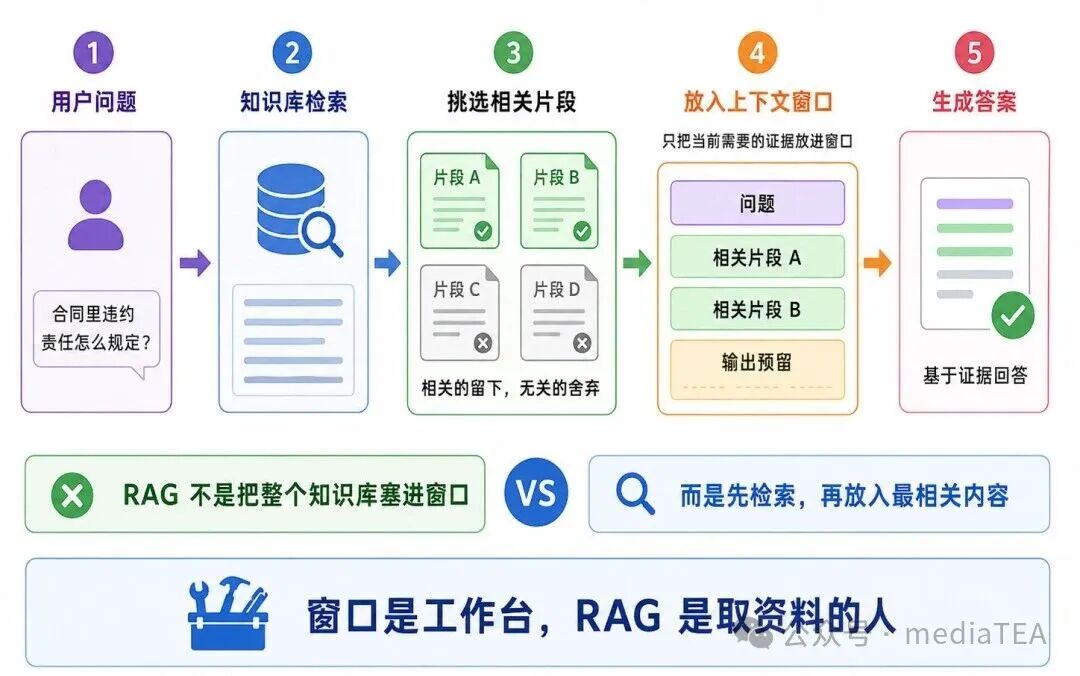
图 3:RAG 如何配合上下文窗口
例如,用户问:这份合同中关于违约责任是怎么规定的?
系统会先从合同文档中检索“违约责任”相关段落,再把这些段落放入模型上下文窗口中,让模型基于它们回答。
从通俗角度看:上下文窗口是模型当前工作台,RAG 是帮助模型从资料柜中取出最相关材料放到工作台上。
RAG 的关键不在于窗口无限大,而在于:
• 检索片段是否相关
• 片段是否足够完整
• 片段数量是否合适
• 上下文是否包含回答所需证据
• 模型是否忠实基于检索内容回答
如果检索结果不相关,即使上下文窗口很大,答案也可能不准确。
如果检索片段太多,窗口被无关内容占满,也会降低回答质量。
因此,RAG 的核心是“选对内容”,而不是简单“塞更多内容”。如果你想动手实践 RAG 与上下文窗口的配合,可以查阅相关的技术文档,那里有避坑指南和完整示例。
八、上下文窗口的优势、局限与使用注意事项
1、上下文窗口较大的优势
较大的上下文窗口可以让模型一次处理更多内容。它适合:
• 长文档分析
• 多轮对话
• 代码文件理解
• 长报告摘要
• 多资料综合比较
• 复杂任务规划
从通俗角度看:窗口越大,模型当前能摊开的材料越多。这可以减少频繁分段、反复检索或手动摘要的需求。
2、上下文窗口的局限
上下文窗口大,并不等于模型一定理解得更好。
主要原因包括:
• 长上下文中可能包含大量无关信息
• 模型可能忽略中间位置的重要细节
• 有效检索和信息组织仍然重要
• 长上下文计算成本更高
• 输出长度也会占用窗口预算
• 超出窗口的信息仍然不可见
从通俗角度看:工作台大,不代表资料摆得乱也能高效工作。如果把很多无关内容都放进去,模型仍然可能抓不住重点。
3、使用上下文窗口时需要注意的问题
使用上下文窗口时,需要注意:
• 上下文窗口按 token 计算
• 输入和输出通常共同占用窗口预算
• 长文本要尽量保留与任务相关的部分
• 多轮对话中早期内容可能逐渐不可见
• RAG 要优先检索相关片段,而不是塞满窗口
• 关键信息最好靠近当前问题或明确标注
• 表格、代码、JSON、公式可能消耗较多 token
• 需要长输出时,应为输出预留 token 空间
尤其要注意:如果输入已经占满上下文窗口,模型就没有足够空间生成长答案。
例如:
$$T_{input} + T_{output} \le T_{window}$$
如果 $T_{input}$ 太大,$T_{output}$ 就会受到限制。
九、Python 示例
下面给出几个简单示例,用来帮助理解上下文窗口与 token 数的关系。
示例 1:用字符数粗略观察文本长度
text = "人工智能正在改变软件开发、教育、医疗和科学研究。"
print("字符数:", len(text))
这个例子只能统计字符数。
需要注意:字符数不等于 token 数。真实模型使用 tokenizer 把文本切成 token,token 数取决于具体 tokenizer。
示例 2:模拟上下文窗口限制
def check_context_length(token_ids, max_context_tokens):
length = len(token_ids)
if length <= max_context_tokens:
print(f"当前 token 数:{length},未超过窗口限制")
else:
print(f"当前 token 数:{length},超过窗口限制")
print(f"需要截断或分段处理:超出 {length - max_context_tokens} 个 token")
# 假设这是一段文本被 tokenizer 转换后的 token id
token_ids = list(range(1200))
check_context_length(
token_ids,
max_context_tokens=1000
)
这个例子中:
• token_ids 表示 token id 序列
• max_context_tokens 表示上下文窗口限制
• 超过窗口时,需要截断、分段或压缩
示例 3:为输出预留空间
max_context_tokens = 8192
input_tokens = 7000
reserved_output_tokens = 800
total = input_tokens + reserved_output_tokens
if total <= max_context_tokens:
print("输入和输出空间足够")
else:
overflow = total - max_context_tokens
print(f"空间不足,需要减少输入或输出预算:超出 {overflow} tokens")
这个例子说明:上下文窗口不只考虑输入,也要为模型输出预留空间。如果输入太长,模型可能无法生成足够长的回答。
示例 4:简单分段处理长文本
def split_into_chunks(token_ids, chunk_size):
chunks = []
for start in range(0, len(token_ids), chunk_size):
chunk = token_ids[start:start + chunk_size]
chunks.append(chunk)
return chunks
token_ids = list(range(2500))
chunks = split_into_chunks(
token_ids,
chunk_size=800
)
print("分段数量:", len(chunks))
for i, chunk in enumerate(chunks, start=1):
print(f"第 {i} 段 token 数:{len(chunk)}")
这个例子展示了长文本分段的基本思想。在真实任务中,分段时还要尽量避免切断自然段、标题、代码块或表格结构。
示例 5:模拟 RAG 中选择相关片段
# 假设检索系统返回若干片段,每个片段有 token 数和相关性分数
passages = [
{"text": "片段 A", "tokens": 300, "score": 0.92},
{"text": "片段 B", "tokens": 500, "score": 0.88},
{"text": "片段 C", "tokens": 900, "score": 0.61},
{"text": "片段 D", "tokens": 400, "score": 0.79},
]
budget = 1000
selected = []
used = 0
# 按相关性从高到低选择
for passage in sorted(passages, key=lambda x: x["score"], reverse=True):
if used + passage["tokens"] <= budget:
selected.append(passage)
used += passage["tokens"]
print("已选择片段:", [p["text"] for p in selected])
print("占用 token 数:", used)
这个例子说明:RAG 不是把所有片段都放进上下文窗口,而是在 token 预算内优先选择更相关的内容。
📘 小结
上下文窗口是模型一次推理中能够处理的最大 token 范围。它决定模型当前能看到多少输入、历史对话和外部资料。上下文窗口越大,模型一次能参考的信息越多,但也需要更好的信息组织和更高计算成本。对初学者而言,可以把上下文窗口理解为:模型当前工作台的大小,只有放在工作台上的内容,模型才能在本次回答中直接使用。
如果你想更深入地探索上下文窗口如何影响实际应用,或者自己动手写一个简单的 RAG 管道,不妨来云栈社区看看。这里聚集了许多开发者和技术爱好者,大家会分享从避坑经验到源码解析的各种干货,或许能给你带来新的思路。
 发表于 2026-6-15 23:28:59
|
查看: 188|
回复: 0
发表于 2026-6-15 23:28:59
|
查看: 188|
回复: 0
