「2018 到 2023 年间在 EMNLP 会议上发表的那篇论文中,第一作者本科就读于达特茅斯学院、第四作者本科就读于宾夕法尼亚大学的那篇科学论文,题目是什么?」
这绝不是一个可以依靠简单记忆或单一检索就能解决的问题。一个合格的智能体(Agent)必须在多轮环境交互中,不断地进行假设、验证并修正推理路径,始终维持前后逻辑的一致性,才能将互联网上零散分布的“证据碎片”整合成一条自洽的答案链条。
2025 年常被视为 AI Agent 的元年,但真正具备自主能力的智能体,其核心挑战在于 「深度搜索」——在长程、复杂的任务中,像人类专家一样持续保持目标、验证信息并动态调整策略。然而,训练这样的智能体一直面临三大瓶颈:
- 数据稀缺:高难度的长程问答任务极度依赖人工标注,成本高昂。因此,业界迫切需要一条能够自动化合成高质量、高难度问题的数据生成链路。
- 能力鸿沟:预训练大模型虽然知识储备丰富,但普遍缺乏与真实环境进行长程、多轮交互的规划与执行能力。这需要通过一个低成本、高效率的中期训练(Mid-Training)阶段来弥补鸿沟。
- 环境缺失:在真实的互联网环境中进行训练,不仅成本高,而且过程不可控、难以复现。一个功能等价的模拟训练环境,对于快速迭代算法至关重要。
为了系统性地突破这些瓶颈,REDSearcher 团队提出了一套低成本、可扩展的完整训练框架。令人瞩目的是,基于该框架训练的 30B 参数规模模型,在多项深度搜索任务上取得了开源模型的领先性能(SoTA),甚至在部分基准上超越了一系列闭源大模型,如 GPT-5。

一、什么是「足够难」的深度搜索题目?
一个搜索问题是否困难,仅仅看它需要多少步推理(跳数)往往是片面的。真正的难点在于问题的 「结构性困难」。
1. 拓扑复杂度:用树宽衡量「结构性困难」
在复杂的搜索任务中,信息线索会分叉、交织,甚至形成回环。智能体需要同时记住多条推论的中间状态,时刻验证它们之间的一致性,并随时准备进行整体的策略回溯——这正是深度搜索的核心挑战。为此,团队引入了图论中的 TreeWidth(树宽) 概念来精确量化这种结构性复杂度。下面通过三种不同结构的对比来理解:
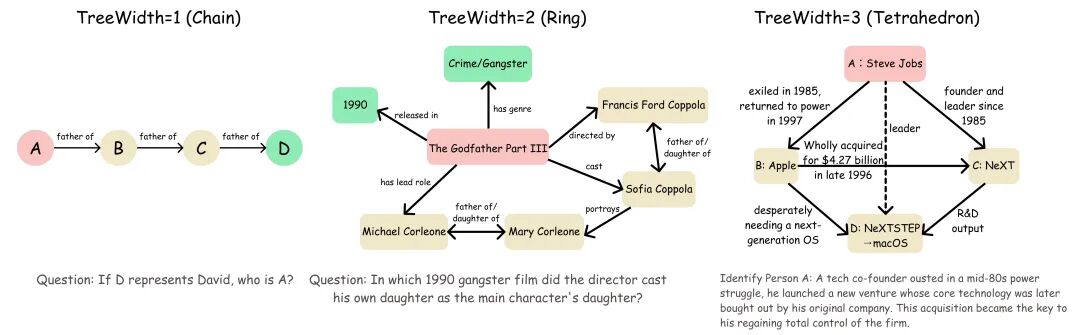
- 线性/树状(树宽=1):典型的链式推理。例如“A是B的父亲,B是C的父亲,问A和C的关系?”智能体只需按顺序检索即可解答,无需维持复杂的状态。
- 菱形/回环(树宽=2):结构中出现分叉与重新汇合。例如一部电影,其导演的女儿饰演了片中主角的女儿。智能体必须同时处理“导演-女儿”和“角色-父亲”等多条关系假设,并确保它们在“女儿”这个节点上保持一致,出现矛盾时需要回溯。
- 强耦合子图(树宽≥3):形成高度互连的网状约束。例如涉及多个实体(人物、公司、产品、时间)相互交织的商业案例推理。这迫使模型必须进行全局性的验证和策略规划,将零散证据拼合成一个逻辑一致的整体。
2. 信息分散度:杜绝搜索「捷径」
即使一个问题的拓扑结构很复杂,但如果互联网上恰好存在一个网页,完整地总结了所有关键事实,那么模型一次检索就可能“抄到答案”。为了杜绝这种“捷径”,REDSearcher 引入了 「信息分散度」 指标,即覆盖全部关键证据所需的最小独立信息源数量。
信息分散度越大,意味着与问题答案相关的证据片段在互联网上的分布就越零散。这直接迫使智能体必须与外部环境(搜索引擎、数据库、工具)进行更多轮次、更有策略的交互,从而无法通过单次“偷看”来解决问题,这正体现了 Agent 的核心价值。
二、大规模「自动化」合成「高难度」的深度搜索问题
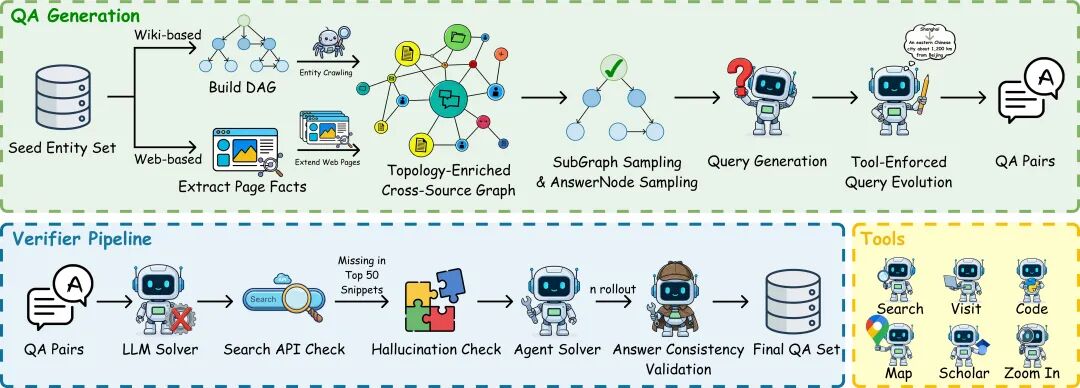
基于上述“树宽”和“分散度”的双重约束标准,REDSearcher 采用 graph-to-text(从图生成文本)的流程来自动化合成数据:首先生成符合目标树宽与分散度要求的推理逻辑图,再将其“翻译”为自然语言问题,并经过多层校验以确保问题“高难度、可解且答案唯一”。
同时,团队设计了基于 「维基百科结构化信息」 与 「通用网页爬取」 的两套图构造流程,以覆盖不同颗粒度和来源的搜索环境。在合成策略上,有两个关键设计:
- 拓扑结构增强:直接生成高树宽的复杂图成功率较低。为此,团队引入大模型智能体对初始的实体依赖图进行 「拓扑加密」 ,通过智能地添加环状约束与交错关系,显著提升图的结构复杂度,从而迭代地生成更困难的问题。
- 工具增强的问题合成:在问题构造阶段,就主动植入工具调用需求。例如,将关键地名替换为需要地图服务查询的描述,或将学术概念替换为需要调用谷歌学术工具才能查清的表述。这使得工具使用成为解题的必要前置条件,而非可选项。
三、多模态扩展:从「文本图」到「多模态图」
在强大的文本问题合成能力基础上,REDSearcher 通过 「模态注入」 ,轻松地将纯文本推理图转化为 「跨模态推理图」 ,使问题中的部分关键约束“锚定”在图像信息中。
- 视觉属性锚定:用具体的图像描述(或实际匹配一张图片)替换掉节点的文本属性。例如,不直接说“埃菲尔铁塔”,而是描述“一座位于巴黎、具有镂空钢铁结构的棕色高塔”的图片,迫使模型必须先理解图像内容,再关联知识进行搜索。
- 跨模态依赖:设置“视觉信息不可替代”的约束,使得图像搜索成为推理链上的必经之路,而非冗余信息。
- 视觉语义抽象:使用“左侧建筑物”、“图中所示的设备”等抽象指代,替代直接的对象命名,进一步迫使模型进行跨模态理解。
- 模态灵活插入:视觉证据可以被插入到推理链的任意位置——既可以在早期设置瓶颈增加难度,也可以在后期引入作为验证,实现了对问题难度的精细化控制。
通过这套轻量级但高效的扩展,REDSearcher 可以无缝迁移至 多模态搜索 领域,合成高质量的图文交织的深度搜索问题。
四、「成本可控」Mid-Training 强化智能体能力
预训练大模型本质上是优秀的“语言建模者”,但缺乏进行多轮交互式任务训练。在长程搜索中,它们容易表现出目标漂移、重复搜索、无法从失败中学习等问题。为此,REDSearcher 采用了一个可扩展的两阶段 Mid-Training 框架,依次强化模型的 「原子能力」 与 「组合能力」,实现从语言模型到智能体的平稳过渡。
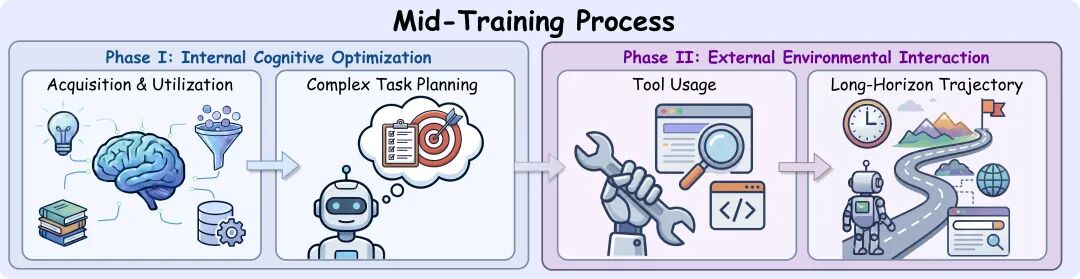
原子能力建设
针对深度搜索所需的基础能力进行针对性优化:
- 意图锚定:训练模型从含噪的网页观测文本中,精准抓取与当前目标相关的关键证据片段,有效过滤无关噪声,从而减少后续推理中的“幻觉”和目标漂移。
- 层次化规划:教会模型将复杂的初始查询,智能地拆解为可立即执行的具体子目标,以及需要进一步信息才能消解的不确定性子目标,确保每一步规划都是可落地的。
组合能力建设
通过模拟环境交互,强化模型在长程任务中的状态维持与目标一致性。整个过程严格以低成本为约束:
- 工具调用能力:通过合成标准的工具调用协议,并在本地构建的功能一致性模拟环境中进行交互训练,使模型熟练掌握在 ReACT(Reasoning + Acting)范式下与外界环境交互的基础能力。
- 长程交互能力:在功能与真实搜索环境等价的模拟器中,让智能体进行完整的长轨迹交互训练,重点强化其复杂规划能力与在长程任务中保持目标一致性的能力。
五、后训练持续进化:不只是「搜得多」,更要「搜得准」
后训练阶段采用 SFT(监督微调) + Agentic RL(智能体强化学习) 的双阶段策略进行能力增强:
- SFT 阶段:让初步具备能力的模型在真实搜索环境中与合成的高难度问题进行交互,通过多重过滤机制(如答案一致性验证、幻觉检查)采集高质量的解决轨迹,直接教会模型正确的深度搜索行为模式。
- RL 阶段:在真实环境中进一步优化搜索策略。此阶段有两个关键设计:
- 低成本验证与迭代:构建一个 「功能等价」的本地高性能模拟环境。它与真实搜索引擎 API 保持一致,但内置了完备且含噪声的“证据库”,使得训练和策略评估的成本急剧下降,加速实验迭代。
- 数据质量保障:针对合成数据集中可能存在的答案错误或“一题多解”现象,采用 Agent-as-Verifier(智能体即验证器) 对用于强化学习的问题集进行严格校验,避免脏数据污染模型,保证训练稳定性。
一个有趣的发现是,训练过程中出现了 效率与性能同步提升 的现象:随着训练的进行,模型解决同一问题的平均交互轮次(即搜索次数)在不断下降,但任务准确率却在持续上升。这表明 REDSearcher 模型并非学会了“暴力搜索”,而是掌握了更精准、更高效的信息获取策略,学会了主动减少无效或冗余的调用,形成了“越训练越聪明”的良性循环。这套方法论对于希望在 开源实战 中复现或改进智能体的开发者而言,具有很高的参考价值。
六、实验结果
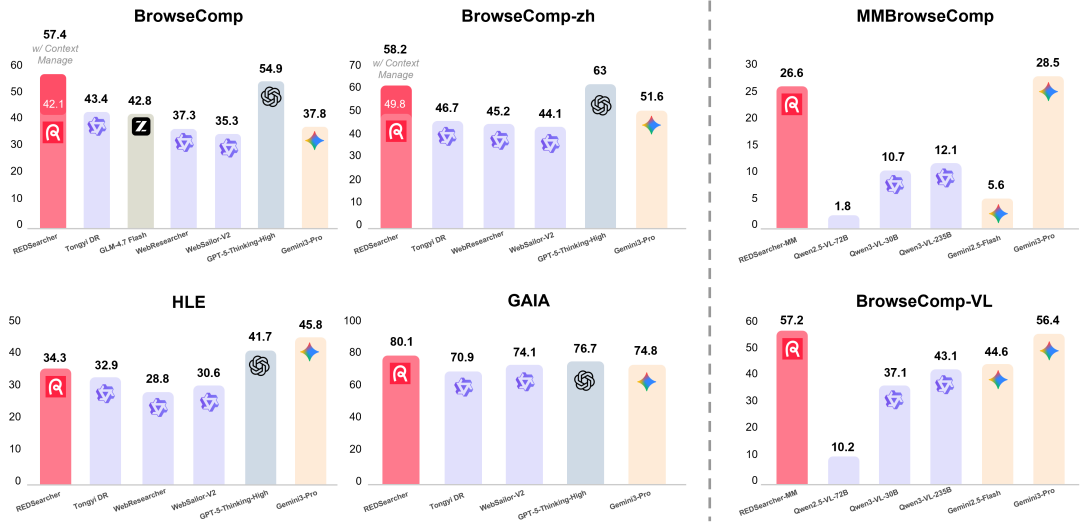
在 BrowseComp、GAIA、HLE 等多个深度搜索权威基准测试上,REDSearcher 均取得了优异的表现。
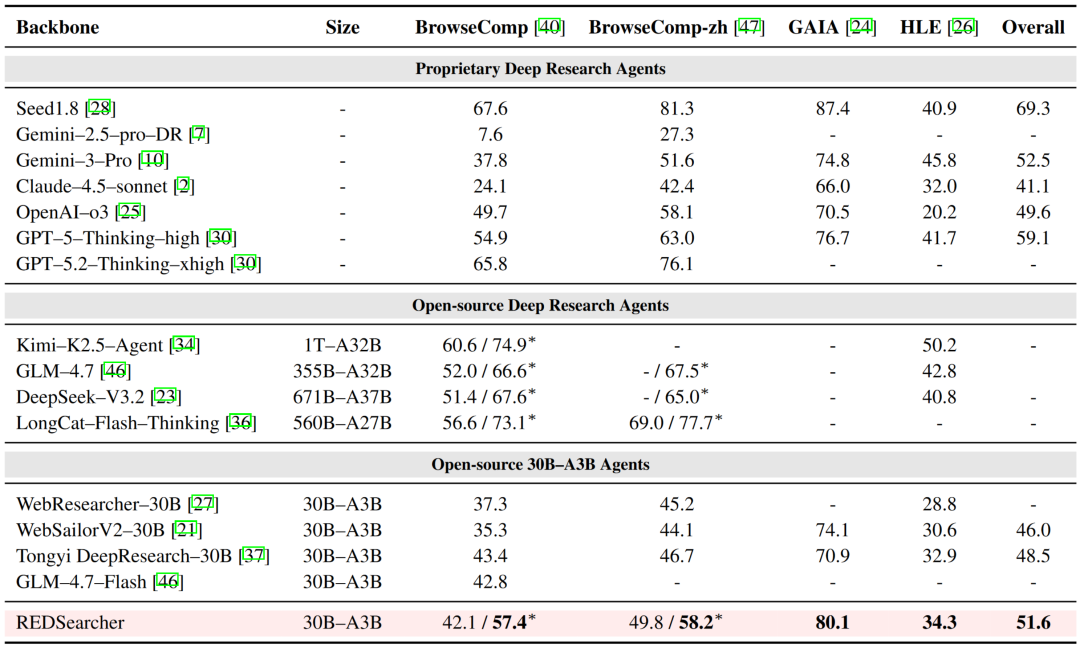
- 在 文本深度搜索 任务上,30B 参数的 REDSearcher 在同规模开源模型中达到了 SoTA 水平。其性能不仅大幅领先其他同规格模型,甚至超过了 GPT-5-Thinking-high、Gemini-2.5-pro、Claude-4.5-sonnet 等一众主流闭源大模型(表格中带 * 号为启用上下文管理功能的性能)。
- 在 多模态深度搜索 任务上,REDSearcher-MM 同样表现突出。
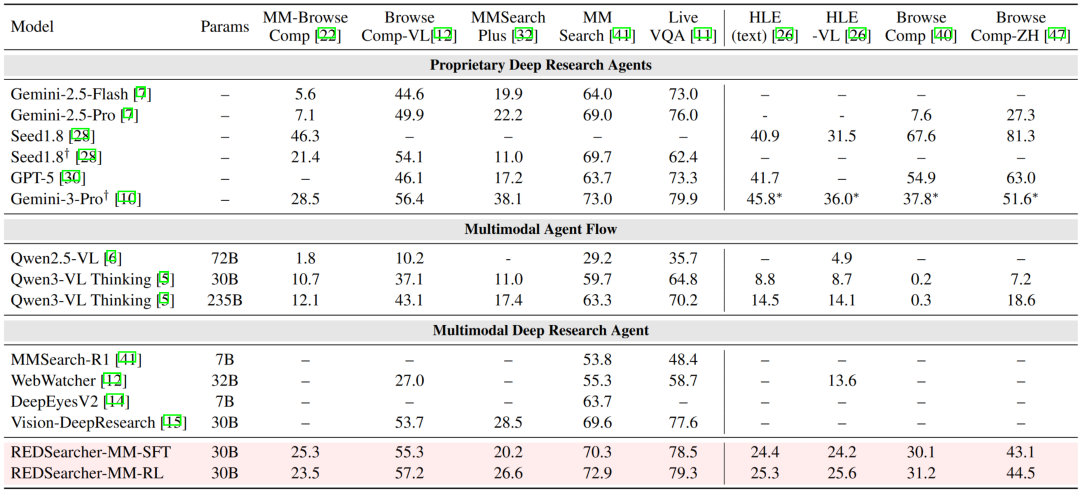
相比其他同规格多模态模型,REDSearcher-MM 取得了全面领先的 SoTA 性能。其表现超过了 Gemini-2.5-pro,并在部分基准(如 MM-Browse Comp)上取得了接近更大规模、更强能力的 Gemini-3-pro 的水平。详细的 技术文档 和基准测试方法可以在其论文和项目页面找到。
结语
REDSearcher 框架的成功,核心在于其系统性的顶层设计:从图论角度严谨定义深度搜索任务的复杂度;以“树宽”和“分散度”为双约束,设计出可扩展的自动化数据合成方案;通过两阶段的中期训练低成本地弥合能力鸿沟;最后以高质量轨迹结合强化学习实现智能体的持续进化。
它为广大研究者和开发者提供了一条清晰、可复现、低成本的深度搜索智能体训练路径。这不仅是一个性能强大的模型,更是一套完整的方法论,推动 AI 系统从静态的知识问答,迈向在开放、复杂环境中进行自主探索、实时验证与深度信息整合的新阶段。
 发表于 2026-3-9 08:20:08
|
查看: 102|
回复: 0
发表于 2026-3-9 08:20:08
|
查看: 102|
回复: 0
