想象一下,你派遣一个AI智能体去厨房完成番茄炒蛋。它可能需要先“查阅食谱”,接着“找到菜刀”,然后“拿起番茄”并“切成块”。在这个过程中,或许只有“成功切好番茄”这个动作,环境(厨房模拟器)会给出一点奖励分,告诉它“干得不错”。而前面那些“找菜刀”、“看食谱”等体现策略的关键动作,环境给予的奖励很可能是零。
这好比老板只在你交付整个项目后才发放奖金,中间的熬夜协调、方案撰写统统没有回报。这种稀疏奖励(Sparse Reward)问题是强化学习(RL)领域的经典难题,如今也成为训练大语言模型(LLM智能体)的主要障碍。缺乏密集的反馈,模型的学习效率会大打折扣,犹如蒙眼走迷宫。
那么,能否让智能体自己给自己发放“过程工资”呢?例如,在完成一步操作后,它回顾整个任务流程,自行评估“找菜刀”这一步对未来成功完成炒蛋有多大贡献,然后给自己打个分?
想法虽好,却存在一个致命缺陷:自我评估(Self-Evaluation)可能不可靠,甚至带有严重偏见。模型可能过度偏爱“查看当前持有物品”这类动作,认为这是“谨慎”的表现,导致智能体光顾着检查背包,却不去执行关键任务。
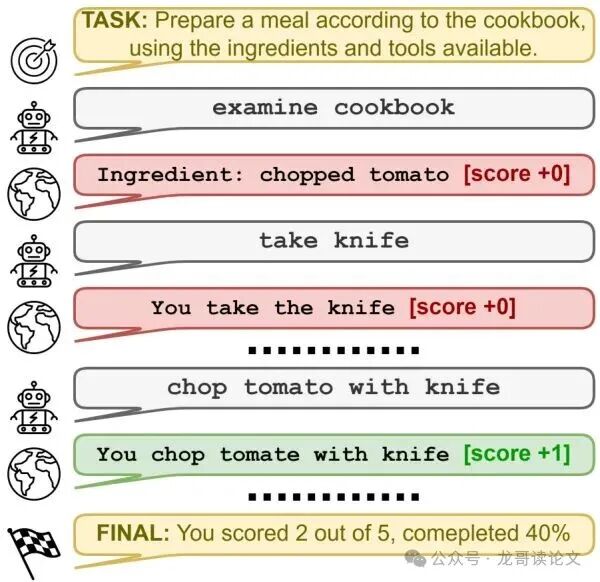
图1:LLM智能体与环境的交互示意图。环境奖励(彩色箭头)是稀疏的,许多有策略价值的动作(灰色箭头)未获得奖励。
来自北京理工大学与北京航空航天大学的研究团队,在其最新论文《Utilizing and Calibrating Hindsight Process Rewards via Reinforcement with Mutual Information Self-Evaluation》中,直面了这一挑战。他们提出了一种名为 MISE 的新范式,即互信息自评估(Mutual Information Self-Evaluation)。
MISE的核心思想可概括为两点:
- 利用自我评估:让LLM智能体在任务完成后,以“后见之明”(Hindsight)回顾每一步动作的战略价值,生成密集的内部奖励信号,从而解决稀疏奖励问题。
- 校准自我评估:同时引入一个校准机制,防止智能体过度“自恋”或产生系统性偏见,确保自我评估与环境的真实反馈保持一致。
实验结果令人振奋:仅使用约70亿参数的开源模型(如LLaMA3-8B),在经过MISE训练后,其在多个文本交互任务上的表现能够逼近甚至在某些情况下超越GPT-4o,且全程无需人类专家的步骤级监督。
下面,我们来深入解析这套让AI学会“自省”与“校准”的方法是如何运作的。
告别稀疏奖励:LLM智能体如何自己给自己“发工资”?
在深入MISE之前,必须先理解其要解决的核心问题。传统强化学习中,智能体依赖环境反馈的奖励信号进行学习。但在复杂的序列决策任务(如文本游戏、网页导航)中,环境奖励往往是稀疏的——只有导致子目标完成的关键动作才能获得非零奖励。
这就好比只告诉登山者“恭喜登顶”,却不指出哪一步踩得稳、哪条路线选得好。没有密集、即时的反馈,学习过程如同在黑暗中摸索,效率极低。
一个自然的想法是:利用LLM强大的语言理解能力,让它自行评估动作的好坏。这类方法被称为过程奖励模型(Process Reward Model, PRM)。具体而言,在一个任务轨迹(一系列观察与动作)完成后,让LLM回顾整个过程,根据每个动作对任务完成的战略价值进行打分(例如+1或-1)。
这相当于赋予智能体“事后诸葛亮”的视角,使其能识别出那些虽无直接环境奖励、但对最终成功至关重要的“幕后功臣”动作。
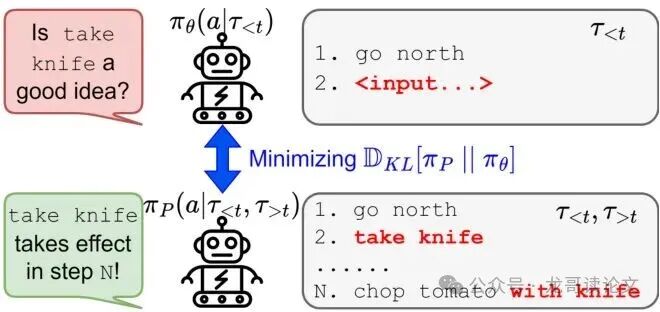
图2:优化朝向事后自评估的理想效果。上方的智能体π_θ原本可能不会选择“拿刀”这个动作,但通过向能看到完整未来的“代理策略”π_P学习,它学会了这个动作的价值。
但问题接踵而至:LLM的自我评估可靠吗? 论文指出,未经针对性训练的LLM,其评估存在显著偏见。例如,在烹饪任务中,未经校准的模型会严重高估“查看库存”动作的价值(81%的情况评为正面),导致训练出的智能体有24%的时间都在反复检查背包,而非真正执行烹饪步骤。
因此,既要利用自我评估来提供密集奖励,又要防止被其偏见带偏,这便是MISE需要解决的“既要又要”难题。而解开难题的钥匙,藏在信息论之中。
理论基石:后见之明与互信息的奇妙关联
这篇论文的一大亮点,是为“利用后见之明进行自我评估”这件事奠定了坚实的理论基础。这不仅仅是启发式的“感觉有用”,而是可以从数学上严格推导出其优化目标。
简而言之,研究者证明,最大化这种后见之明过程奖励,等价于最小化一个包含两项的损失函数:
- 互信息项:即动作 $a$ 与未来轨迹 $\tau_{>t}$ 之间的条件互信息 $I(a; \tau_{>t} | \tau_{<t})$。最小化此项意味着,智能体要学会在仅知晓当前和历史信息($\tau_{<t}$)的情况下,做出与知晓完整未来信息时一样好的决策。这本质上是在鼓励智能体学习高瞻远瞩的策略,减少对未来不确定性的依赖。
- KL散度项:即当前策略 $\pi$ 与一个基于自我评估定义的“代理策略” $\pi_P$ 之间的KL散度。这项则比较微妙。因为 $\pi_P$ 的定义可能包含了偏见,如果直接让策略 $\pi$ 去模仿它,就可能将这些偏见也学过来。
理论的价值在此显现:它清晰地表明,纯粹依赖自我评估(Vanilla PRM)会同时优化这两项。第一项是我们期望的,它能解决稀疏奖励,让智能体更有远见。但第二项是“有害”的,它会导致智能体习得评估偏见。
因此,一个完整的解决方案必须主动校准(Calibrate)这个自我评估过程,以对抗第二项带来的负面影响。理论不仅解释了为何需要校准,更为如何设计校准机制提供了指导。
MISE框架揭秘:三份“工资单”的协同作战
基于上述理论洞见,MISE框架应运而生。其整体流程可形象地理解为智能体同时领取三份“工资单”:
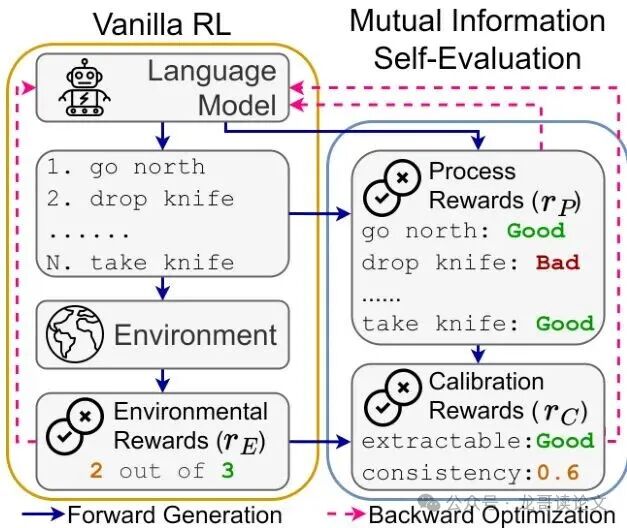
图3:MISE框架概览。除了稀疏的环境奖励(r_E),它还生成密集的自我评估过程奖励(r_P),并通过校准奖励(r_C)确保自我评估与实际表现一致。
第一份工资:环境基本工资 ($r_E$)
这就是传统RL中的稀疏环境奖励。它客观、真实,但发放频率极低。MISE仍然将其作为基础奖励来源。
第二份工资:自我评估绩效奖金 ($r_P$)
这是MISE解决稀疏奖励问题的核心。在完成一个任务轨迹后,LLM智能体被要求回顾整个过程,并根据提示(例如“评估每个动作对完成任务的战略价值”),对轨迹中的每一个历史动作进行二元评估(+1有用 / -1无用)。由此,为每一步都生成了一个密集的内部奖励信号。
这对应了理论中的“互信息”项,旨在提升智能体的前瞻性与策略性。
第三份工资:校准监督补贴 ($r_C$)
这是MISE的创新关键,用于对抗自我评估的偏见(对应理论中那项“有害”的KL散度)。它的设计颇为巧妙:
对于一个完整的任务轨迹,我们计算两个百分比:
- $p_{real}$:真实任务完成度。用获得的总环境奖励除以任务最大可能得分。
- $p_{self-eval}$:自我评估积极度。用获得的正向自我评估奖励数除以总步数。
然后,校准奖励 $r_C$ 的设计鼓励 $p_{real}$ 和 $p_{self-eval}$ 保持一致。如果智能体给自己打的分数很高($p_{self-eval}$ 很大),但实际任务完成得很差($p_{real}$ 很小),它就会受到惩罚。反之亦然。
这如同一位外部监督者,不断提醒智能体:“别只顾着给自己打高分,看看实际干得怎么样!”从而迫使智能体的自我评估能力(打分)与行动能力(执行)协同进化、相互对齐。
最终,MISE的总体优化目标 $J(\theta)$ 便是将这三份奖励结合,同时加上一个标准的策略KL正则项(防止策略变得过于极端):
$$
J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=1}^{T} \frac{(r_E + r_P)}{2} + r_C \right] - \beta D_{KL}.
$$
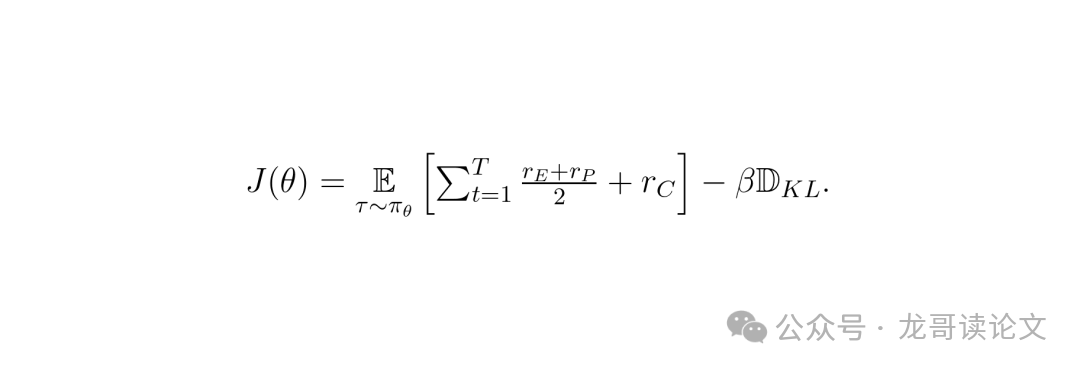
至此,一个完整、自洽且具备理论支撑的强化学习范式构建完成。
实验验证:小模型逆袭GPT-4o,全靠“自省”与“校准”
理论优美,框架精妙,最终仍需实践检验。研究团队在三个经典的文本交互任务上进行了全面评估:
- FTWP:在文本模拟的现代房屋中导航并完成烹饪任务。
- ScienceWorld:完成一系列科学实验任务。
- WebShop:在线购物网站导航任务。
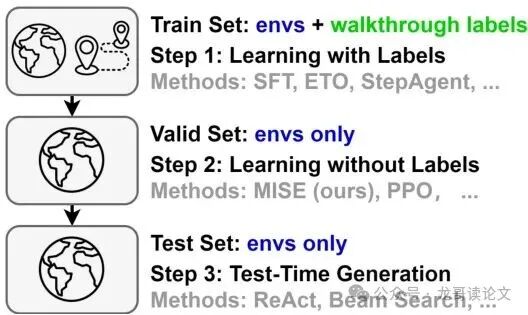
图4:整体实验流程。MISE在无需任何步骤标签的第二阶段(纯环境交互学习)中发挥作用。
他们对比了包括提示工程方法ReAct、基于成功轨迹模仿的RFT、在线偏好优化DPO、标准PPO以及不加校准的Vanilla PRM在内的多个强基线方法。基座模型选用了LLaMA3-8B、Qwen2-7B、Gemma2-9B等主流开源模型,并与闭源的GPT-4o和GPT-4o-mini进行比较。
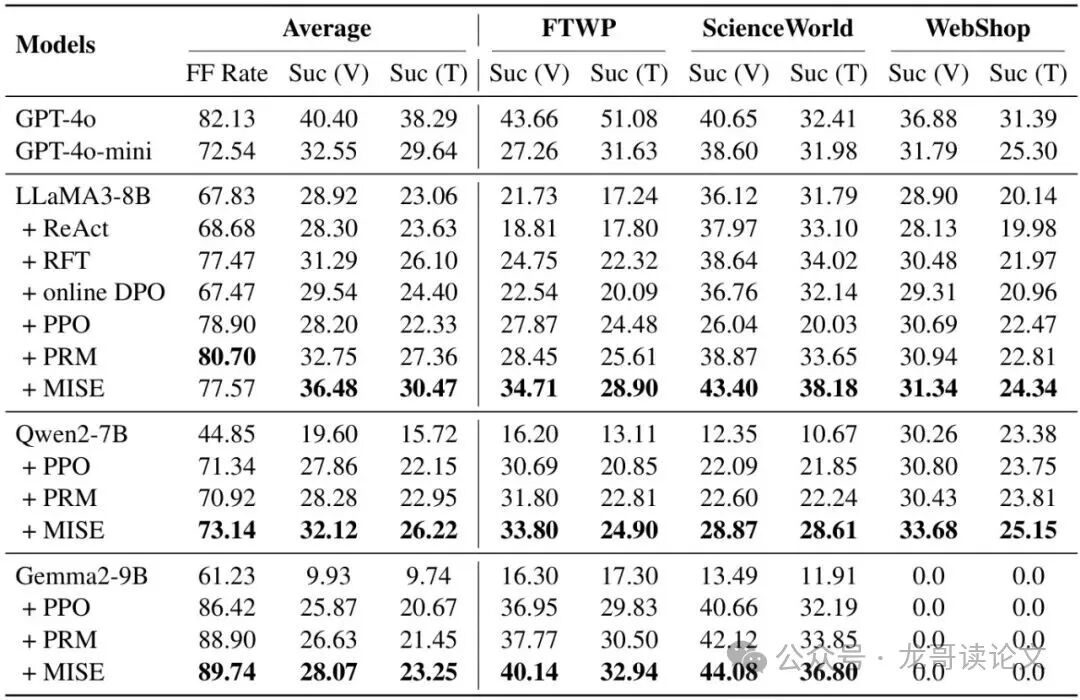
表2:在三个任务上的主要实验结果。加粗数字代表每个基座模型下的最佳结果。
实验结果非常出色:
- 全面超越基线:在完全无标签(无需人类专家进行步骤标注)的场景下,MISE在所有基座模型和所有任务上,均显著超越了RFT、DPO、PPO等基线方法。特别是,MISE相比不加校准的Vanilla PRM也有显著提升,直接证明了校准机制的有效性。
- 小模型逆袭大模型:以LLaMA3-8B为例,经过MISE训练后,其在FTWP验证集上的任务成功率(Suc Rate (Val))达到34.71%,超越了GPT-4o-mini的27.26%,并与GPT-4o的43.66%处于可比量级。考虑到模型参数量(~8B vs 巨大未知)和训练成本(无监督 vs 海量监督)的悬殊差异,这一结果堪称惊人。
更有趣的是,即使在一些已使用监督微调(SFT)数据预训练的模型上,采用MISE进行“后训练”也能进一步提升性能,甚至超过那些需要步骤级标签的专门RL方法(如ETO、StepAgent)。
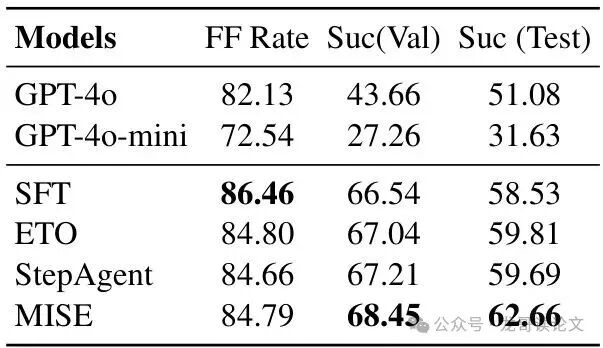
表3:在有训练标签的场景下(基于SFT模型)在FTWP任务上的实验结果。
这说明MISE具有很好的通用性:它不仅能在“白手起家”的完全自主学习中表现优异,还能作为现有模型的“能力增强器”。
深入分析:自评估与行动能力的“互助共赢”
MISE的精髓在于“自我评估”与“行动策略”的协同进化。论文通过一系列细致的分析实验,揭示了这种“互助共赢”的内部机制。
分析一:自我评估的质量真的提高了吗?
研究者手动标注了一个包含764个动作的小型测试集,然后让不同模型对其进行评估。结果如下表所示:
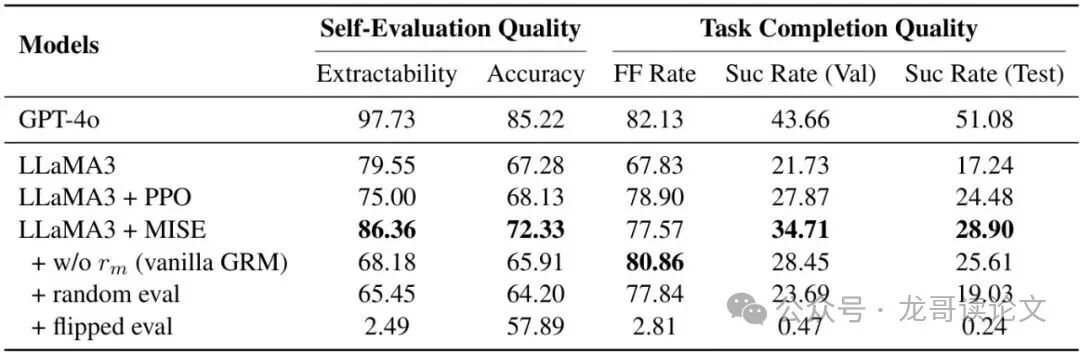
表4:自我评估质量和任务完成质量的消融分析。
可以看到,经过MISE训练的LLaMA3模型,其自我评估的准确率(72.33%)显著高于原始模型(67.28%)和仅用PPO训练的模型(68.13%)。更关键的是,如果去掉校准奖励 $r_C$(即Vanilla PRM),模型的评估准确率会下降至65.91%,甚至低于原始模型。这清晰地证明了校准机制对于维持和提高LLM自我评估能力至关重要,否则模型可能在强化学习过程中“遗忘”如何正确评估。
分析二:校准奖励 $r_C$ 如何起作用?
下图展示了训练过程中,有/无校准奖励时,模型的实际任务成功率和自我评估积极率的变化。
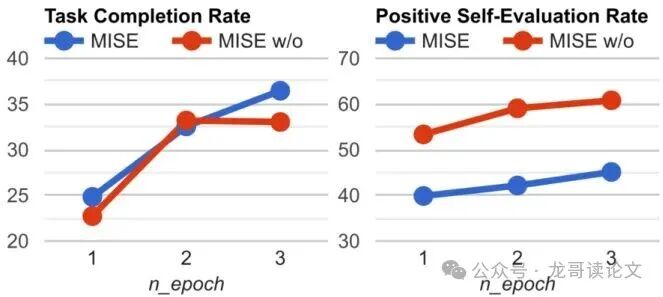
图5:验证集上三个训练周期内的任务完成率和正向自评估率。MISE w/o 指没有校准奖励的MISE(即Vanilla PRM)。
一个非常有趣的现象出现了:没有校准的模型(橙色虚线)虽然实际任务成功率较低,但它给自己打的“积极评价”却非常高(接近60%)。这正是理论中提到的“偏见”在作祟——模型陷入了“自恋”陷阱,觉得自己每一步都做得很好,但实际任务完成度却不高。
而带有校准的MISE(蓝色实线)则表现得更加“诚实”和“务实”:它的自我评估积极率随着任务成功率的真实提升而稳步、合理地增长。校准奖励 $r_C$ 犹如一位严厉的导师,不断敲打智能体:“用结果说话!”,从而确保了学习过程的健康进行。
这些分析共同印证了MISE框架设计的精巧:它通过一个简洁的校准机制,成功实现了行动策略与自我评估能力的双向促进和良性循环。更好的行动带来更真实的结果,校准迫使评估更准确;更准确的评估提供更优质的训练信号,进而导向更好的行动策略。
未来展望与总结
MISE的工作为构建更自主(Autonomous)的AI智能体迈出了坚实一步。它展示了如何让智能体在仅有稀疏环境反馈的情况下,通过“自省”和“自我校准”实现高效学习,减少对人类标注数据的依赖。
未来的探索方向可能包括:
- 更强大的基础模型:本文实验基于7B-9B参数量的模型。若使用更强大、推理能力更强的基座LLM(其自我评估的初始准确率可能更高,如表4中GPT-4o达85%),有望进一步提升MISE的性能上限。
- 更复杂的任务与环境:将MISE应用于更开放、动态的虚拟世界或具身智能场景,测试其在长期规划、多任务学习中的潜力。
- 与其他学习范式结合:探索MISE与模仿学习、课程学习、世界模型等技术的结合,形成更鲁棒、更通用的自主智能体训练体系。
这项研究在云栈社区等技术论坛中也引发了关于AI智能体自主性训练的深入讨论。它不仅为学术研究提供了新思路,其“自我评估+校准”的核心思想,对于实践中设计更高效、更可靠的AI系统也具有重要的借鉴意义。
 发表于 2026-4-18 23:17:47
|
查看: 150|
回复: 0
发表于 2026-4-18 23:17:47
|
查看: 150|
回复: 0
