奥赛金牌不是一道选择题
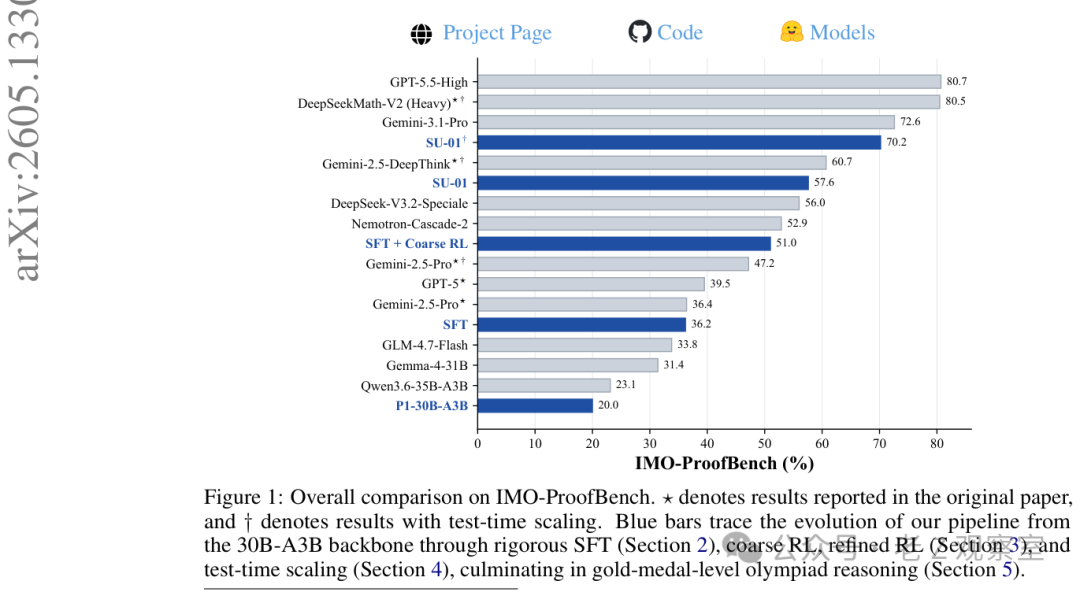
一篇新论文把一个名叫 SU-01 的模型推到了很醒目的位置:基于 30B-A3B 骨干,经过一套相对统一的训练和推理配方后,它在 IMO 2025 和 USAMO 2026 的竞赛式评测里都拿到三十五分,在 IPhO 2024 和 2025 上也越过金牌线。这个结果很容易被写成“AI 又会做奥赛了”,但我更在意的是另一件事:它不是靠一次性吐出答案取胜,而是把“写证明、查漏洞、再修证明”做成了核心流程。
奥赛题和普通数学题的差别,不在于答案更长,而在于中间每一步都要经得起阅卷。一个模型可以猜到结论,也可以写出看似漂亮的推导,但只要某个分类少了一种情况,或者某个几何关系没有真正说明,分数就会掉下去。看到 SU-01 的结果,我的第一反应不是“模型已经会数学了”,而是“模型终于被迫学会像参赛者一样对草稿负责”。
这篇工作的传播钩子有三个。其一,模型规模并没有夸张到只能当超级实验室展示品;其二,成绩来自一条清晰流水线,而不是神秘提示词;其三,它把“最终答案正确”降级成了必要条件,把“证明能过审”放到了台前。对研究者来说,这比单个榜单名次更有意思。
还有一个容易被忽略的点:它保留了对科学题的迁移。论文里的训练信号主要围绕数学和物理,但在更宽的科学评测里,SU-01 没有塌缩成只会竞赛套路的专用机器。这个现象让我觉得,它学到的可能不是某几类题的模板,而是更通用的“先建模、再检查、再修补”的工作习惯。当然,这个判断还不能下得太满,毕竟跨学科分数仍然不高,但方向值得盯住。
先把模型训练成会审稿的学生
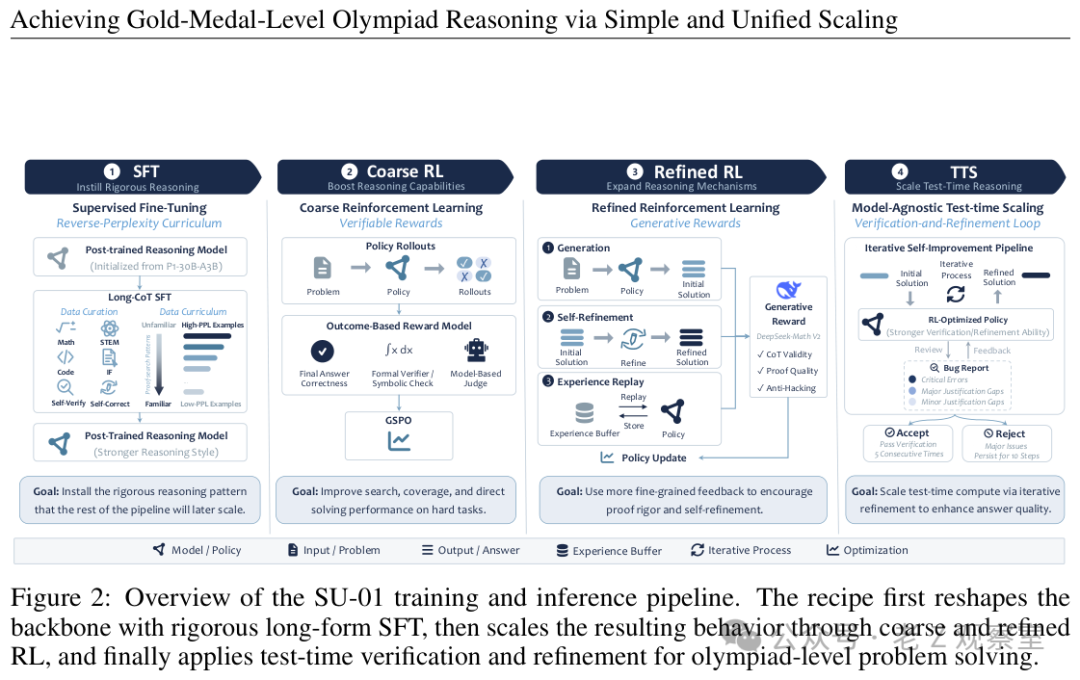
SU-01 的第一步不是直接强化学习,而是先做监督微调。训练材料里有数学、科学、代码和指令样本,也有专门的自验证、自修正轨迹。换句话说,它不只是看标准答案,还要看一份草稿如何被检查、哪里可能有缺口、怎么补成完整证明。我个人觉得,这一步像是在给模型补“竞赛作文课”:会算不够,还要学会把理由写到别人挑不出明显漏洞。
这里最值得讲的是训练顺序。团队没有把样本随机喂进去,而是按模型原本最不熟悉的程度倒着排:每一轮先碰最别扭、最不像自己会写的轨迹,再回到更熟悉的样本上稳定下来。这个设计看起来朴素,却很符合改造已有模型的现实。一个已经会不少题的模型,最怕被新风格冲坏;先让它适应陌生证明写法,再用熟悉样本收束,等于在拉开能力边界后再把状态稳住。

可以把这个过程想成训练车间里的排课:早上先做最不顺手的证明改写,中午练自查,下午再做熟悉题型恢复手感。我的判断是,反向课程不是论文里可有可无的小技巧,而是整条路线能否低成本生效的关键之一。因为它处理的不是从零教小孩,而是给一个已经有习惯的高手改动作。
这也解释了为什么监督微调后,部分答案型指标会短暂下降。模型开始写更长、更谨慎的解答,原来那种迅速命中答案的手感会被扰动。乍看像退步,实际更像换跑姿时的阵痛。只有后面的奖励训练接上来,新的证明习惯才会转化成更强的解题能力。
强化学习不只奖励答对
第二阶段进入强化学习,但它没有把奖励简单等同于“答案对了”。粗粒度阶段使用可验证题目,适合稳定提升搜索和求解能力:答案能被规则或评审器确认,就给模型明确反馈。这个阶段像刷题训练,能让模型更快找到可行路线,也能把监督微调里学到的长证明习惯放大。
真正改变气质的是精细阶段。奥赛证明经常出现一种尴尬情况:结论对,理由不够;方向对,中间断桥;局部计算对,整体分类漏了。SU-01 在这一阶段引入证明级评审,关注完整解答是否严谨、是否充分、是否存在投机格式。同时,它还把失败草稿改造成修正任务,让模型练习“指出问题并重写”;遇到少数难题上偶然成功的轨迹,还会放进经验池里反复利用。
这让我想到一个很具体的场景:老师批改奥赛作业时,不会只看最后一行,而会圈出“这里为什么成立”“这一类情况去哪了”“这个构造是否覆盖全部”。SU-01 的训练方向,正是把这种批改声音嵌进学习过程。我认为这是从答题器走向证明合作者的分水岭:模型不再只被奖励命中结果,而是被要求让整份解答站得住。
经验回放这一点也很有现实味道。难题训练里,模型可能十几次都失败,某一次突然找到一条能走通的路线。如果这条路线马上被丢掉,学习信号就浪费了;如果被保存下来,后续训练就能反复提醒模型:这类题原来有这样一条窄路。我的理解是,这不是让模型背答案,而是让它记住稀有成功背后的动作模式。
考试现场,它开始自己审自己
到了推理阶段,SU-01 还会继续花计算量。流程大致是:先写初稿,再让模型检查这份初稿,生成漏洞报告,然后依据报告修正,接着再次验收。只有候选解答连续通过检查,或者预算用完,流程才停下来。这个“考试现场自我审稿”的设定,是整篇论文最适合大众理解的部分。
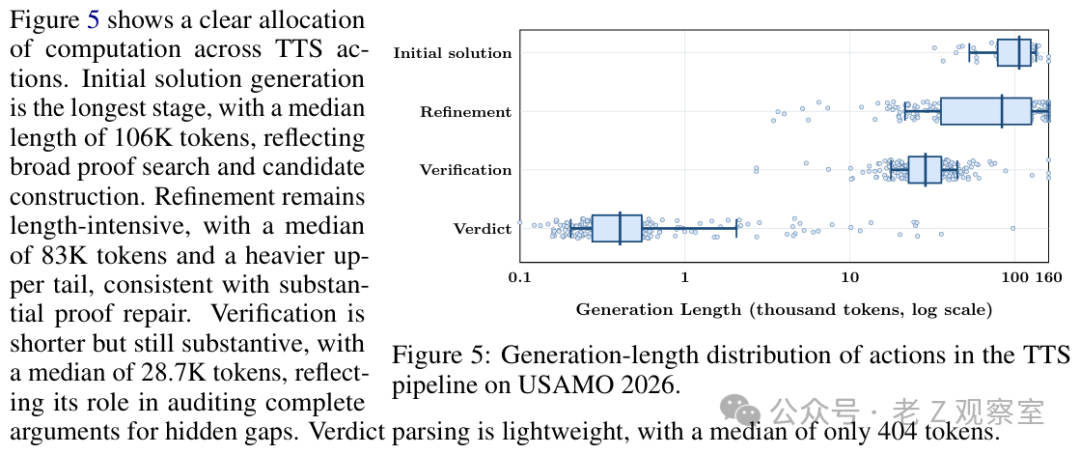
论文记录的测试时轨迹很长,初稿和修正阶段都可能达到十万 token 以上。这个数字本身是传播点,但我不想只把它理解成“想得更久”。更准确地说,它是在同一道题上持续保留草稿、评语和修改目标。长,不一定带来聪明;能在长上下文里不跑偏,才有意义。SU-01 的亮点恰恰是把长时间推理变成了可循环的审稿过程。
奥赛考场里的对应场景很直观:选手写完一道几何题,发现某个辅助点关系没有证明,于是退回去补;补完后又检查是否引入新问题。模型也在做类似动作。我的反应是,这比单次生成更接近真实解题,因为很多难题不是一次灵感就结束,而是在反复推翻和保留中成形。
这里还有一个反直觉之处:测试时扩展不是简单多抽几份答案再投票。投票适合答案短、验证清楚的题;证明题更像长文审稿,多个版本都可能有不同漏洞。SU-01 的流程把“发现漏洞”本身变成中间产物,这让下一轮修正有了明确靶子。对我来说,这也是它比普通采样更像解题的地方:它不是把错误版本藏起来,而是把错误版本拿出来加工。
高分很亮眼,但别急着神化
结果确实漂亮。SU-01 直接生成时已经在物理奥赛两年题目上越过金牌线;加上测试时扩展后,在 IMO 2025 和 USAMO 2026 都达到三十五分。论文还提到,USAMO 2026 的这个分数与公开统计里的最高人类总分相当。对一个三百亿级稀疏模型来说,这组数字足够制造冲击。
但我会保留一处存疑:这些竞赛式证明结果有专家评分参与,外部复现还需要时间;证明级奖励模型也可能有偏好和盲区。论文里的失败案例同样提醒我们,模型在组合结构、全局不变量这类问题上仍会犯错。它会写很长,也会修很多轮,但长草稿不自动等于可靠证明。
对产品化来说,另一个问题是成本。测试时扩展听起来优雅,实际意味着同一道题要跑多轮生成、审查和修正,时间与算力都会上去。它适合高价值题目、竞赛评测和科研难题,不一定适合每个日常问答。我的看法是,这条路线短期不会替代所有推理场景,却会成为高难任务上的重要开关。
还有一个工程细节不能忽略:这种自检链路很依赖评审环节的质量。如果评审器偏爱冗长、漂亮、格式完整的证明,模型可能学会把草稿写得更像正确答案,而不是真的堵住漏洞。实际接入科研助手时,我会更关心它能不能把关键不确定点标出来,而不是只给一篇气势很足的长解。这个风险不影响论文成绩的价值,但会影响它走向真实工具的速度。
所以我更愿意把 SU-01 看成一个方向信号:AI 数学能力的竞争,正在从“谁能更快给出答案”转向“谁能更可靠地打磨证明”。这对科研助手、竞赛训练和复杂问题求解都很重要。未来有价值的模型,可能不是永远一次说对的神谕,而是愿意反复检查、承认漏洞、把草稿改到可交付的合作者。它把“会做题”拆成了更细的能力:会探索、会质疑、会保留有用部分,也会在失败后重新组织论证。这个拆分,可能才是奥赛成绩背后最值得记住的东西,也让后续复现有了清楚参照,更便于判断成绩究竟来自哪里,以及是否真正稳健。
 发表于 2026-5-19 00:59:06
|
查看: 132|
回复: 0
发表于 2026-5-19 00:59:06
|
查看: 132|
回复: 0
