小红书 AI 平台团队正式开源了 Relax —— 一款专为全模态与 Agentic 场景设计的大模型强化学习训练引擎。Relax 基于 Megatron-LM 和 SGLang 高性能后端构建,以协同设计为核心,致力于系统性地解决全模态数据支持、服务化容错架构和异步训练流水线这三个维度的挑战。在 Qwen3-Omni-30B 模型上,Relax 验证了对图像、文本、音频和视频四种模态进行 RL 训练时的稳定收敛能力;在 16 台 H800 GPU 的多机环境下,其全异步训练模式相比传统的 Colocate 方案端到端提速 76%,相较于 veRL 的全异步方案,端到端速度也提升了 20%。
资源链接

在将 RL 训练从纯文本扩展到全模态、Agentic 场景的过程中,开发者们普遍面临三大困境:
困境一:数据异构。高质量的图片和音视频原始数据体积庞大,CPU 预处理开销高,编码后 token 数量激增,现有的多模态编码器难以与并行策略高效协同。面对小红书内部丰富的多模态应用场景,亟需一个深度定制优化的框架。
困境二:系统脆弱。多模态训练本身就伴随着更高的显存溢出(OOM)风险,叠加千卡规模的长时间训练任务,硬件故障或 NCCL 通信超时等问题随时可能出现。传统方案缺乏分钟级别的故障恢复能力,以及针对单一角色的弹性伸缩支持。
困境三:角色耦合。在 Colocate(同址部署)方案中,RL 训练的不同角色(如 Rollout、Trainer)共享同一组 GPU,只能串行执行。Trainer 必须空闲等待最慢的 Rollout 完成才能开始工作。现有的全异步方案虽然将 Rollout 和 Train 拆分到不同 GPU 组,但仍然缺少细粒度的流水线调度能力,资源利用率仍有提升空间。

上述三个挑战紧密耦合,一个局部的优化可能会引入新的瓶颈。因此,协同设计往往比逐个击破更为有效。多模态数据的低效与不稳定,倒逼系统走向服务化隔离与全异步架构,而这又催生了统一的数据总线设计,该总线的结构恰好能天然地适配多模态数据流,从而形成一个自洽的技术闭环。
服务化容错架构:所有角色皆服务
Relax 将每个 RL 角色(如 Actor、Critic、Rollout)都封装为独立的 Ray Serve 部署。每个服务拥有独立的故障域、资源配额和健康监控,由此获得了三个核心能力:
- 故障隔离:某个 Serve 服务故障(例如 OOM)不会波及其他角色。系统采用两级恢复策略,区分无状态角色(原地重启)和有状态角色(全局恢复),避免因单一角色问题导致整个训练任务重启。
- 独立伸缩:可以根据需求单独增加某个角色(如 Rollout)的副本数量,而不会影响其他角色集群(如 Critic)的稳定性。
- 生命周期管理:每个角色从初始化、保存检查点到重启,都在服务级别进行统一管理,不再与全局训练循环的逻辑纠缠不清。
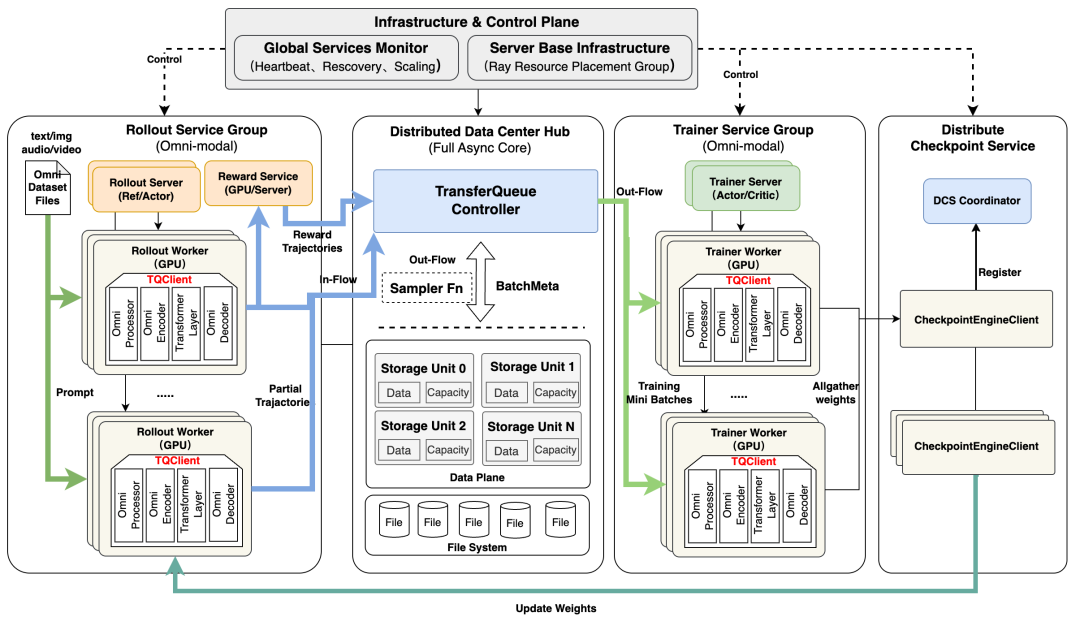
此外,Relax 提供了 分布式 Checkpoint 服务(DCS) —— 一个独立部署的权重同步服务。DCS 能够以极低的延迟将更新后的模型权重分发给所有推理引擎,使得故障恢复无需回退到磁盘中读取检查点文件。它支持 NCCL(集群内 GPU 到 GPU 直连传输)和 TCP(跨集群传输)双通道,以适应不同的硬件部署拓扑。
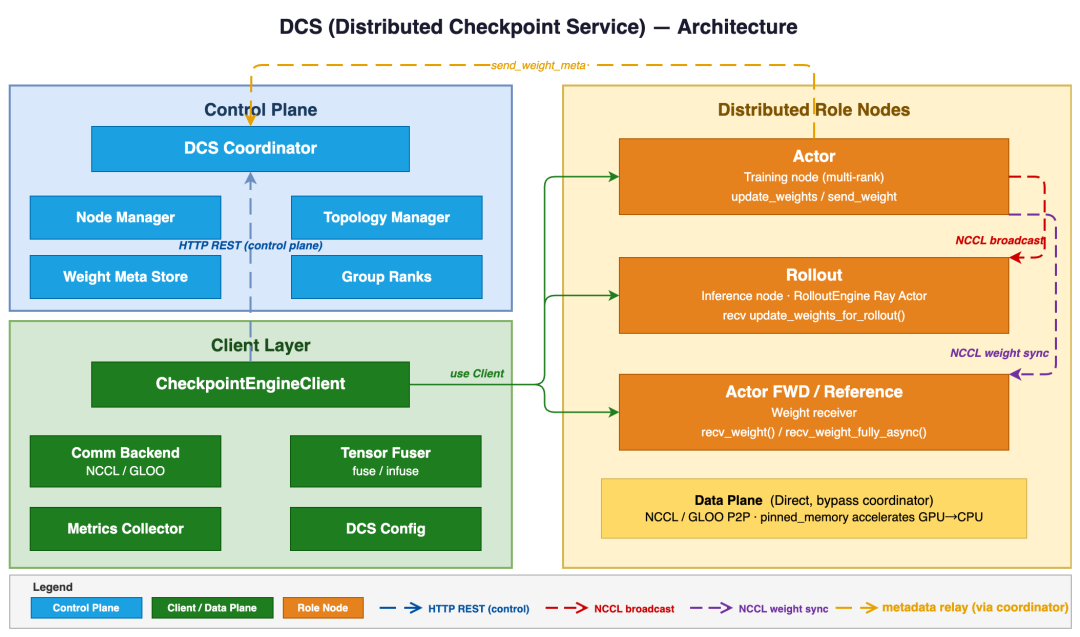
异步训练流水线
Relax 集成了 TransferQueue(TQ) 作为所有服务之间的异步数据总线。TQ 的字段级存储特性,使得同一个样本的不同字段(如生成结果、log-probs、奖励值)可以在不同时间点独立地写入和读取。这完美匹配了 RL 训练中,不同阶段在不同时间产生不同字段的多阶段计算模式。
基于 TQ,Relax 仅需通过一个 max_staleness 参数即可在 On-Policy 和 Off-Policy 训练模式间自由切换。在全异步模式下,On-Policy 训练相比 Colocate 性能提升 12%,而 Off-Policy 训练则实现了高达 76% 的性能提升。
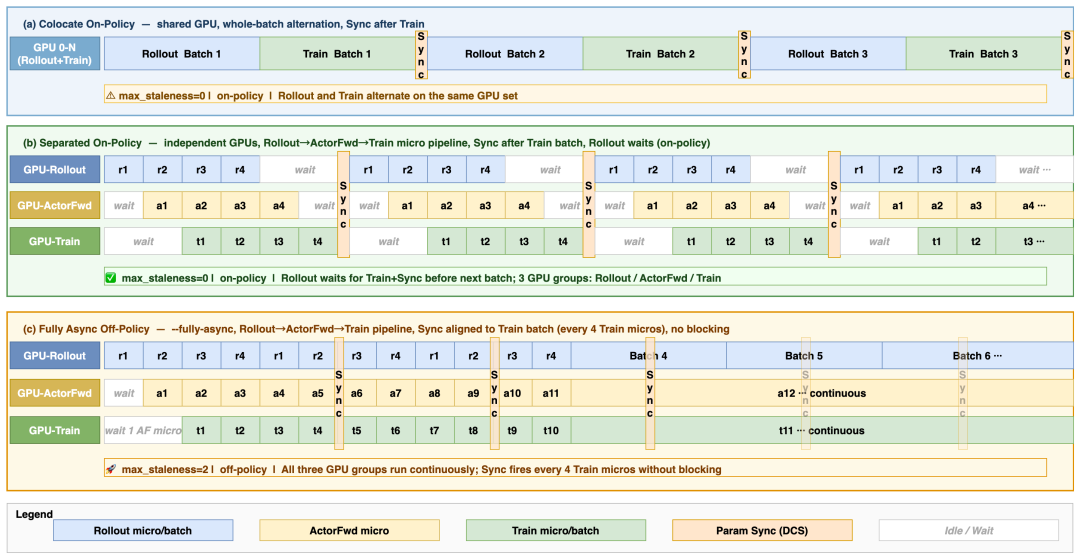
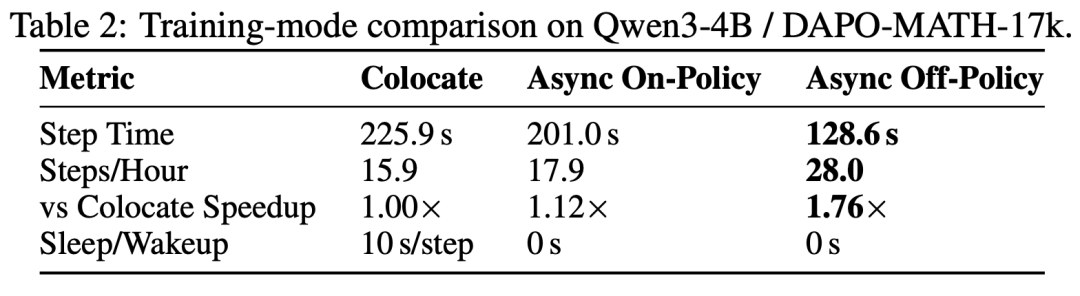
这一显著的性能优势主要由两项关键机制驱动:
- 流式微批调度(Streaming Micro-Batch Scheduling):传统框架采用全局批次同步,即 Rollout 必须生成完整个批次的所有数据后,才能交付给下游的 Trainer。这就意味着,一个包含 20k token 的长尾样本可能会阻塞整个训练步骤。Relax 将全局批次拆分为多个微批次,每个微批次一旦完成就立即写入 TQ,供下游角色消费,有效消除了瓶颈。
- Actor Train 资源分离:将 log-probability (
logp) 和 reference log-probability (ref_logp) 的计算部署在独立的 GPU 资源上并行执行。通过异步数据传输,将这部分计算时间完全“掩盖”在主要的训练时间内,实现了零额外等待开销。
全模态与 Agentic 场景原生支持
Relax 原生支持图像、音频、视频等多种模态输入的统一处理与灵活接入。它结合了模态感知的并行策略与端到端的异步流水线,显著提升了多模态训练的效率与可扩展性。在 Qwen3-Omni-30B 模型上的实验表明,无论是基于图文音频混合数据(AVQA-R1-6K)还是纯视频数据(NextQA)进行 RL 训练,奖励都能稳定收敛,其中视频数据持续训练超过 2000 步依然保持稳定。
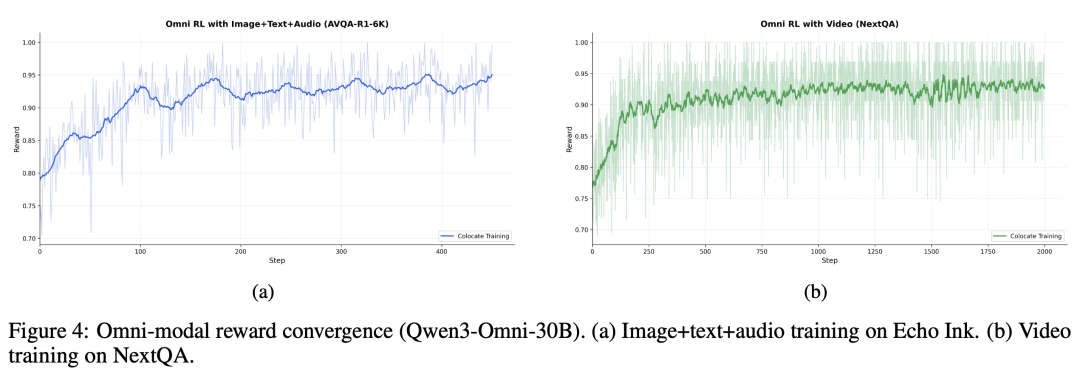
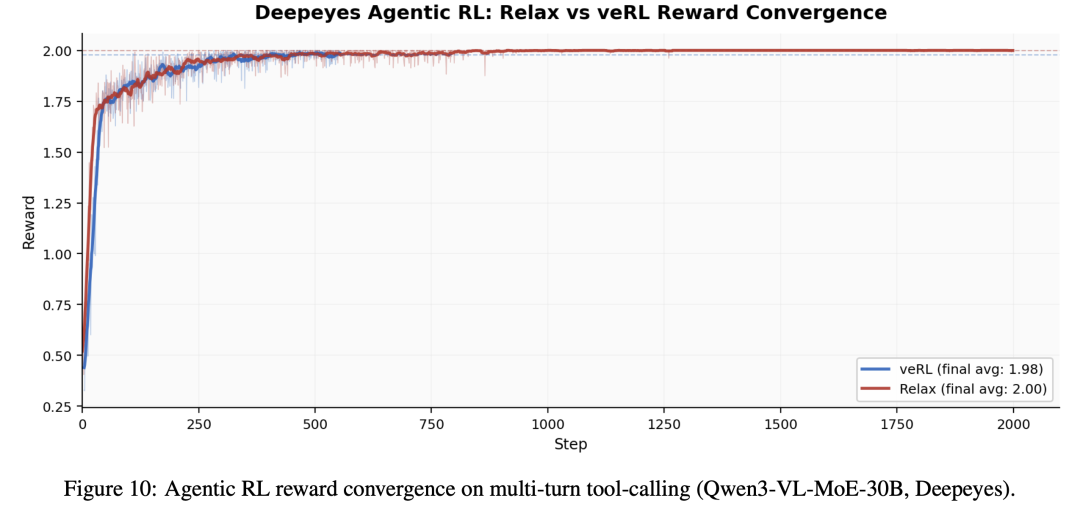
针对 Agentic RL 中的多轮推理、工具调用和搜索增强等复杂场景,Relax 将底层基础设施与上层算法逻辑解耦,支持业务侧灵活敏捷地接入:
- 自定义 Rollout 与 Reward:支持多轮 Agentic 工作流(例如,每一轮推理都可能接收新的视觉输入)。Rollout 服务会维护会话状态,而 TQ 则独立追踪每一轮产生的字段的就绪状态。奖励计算支持规则奖励、生成式奖励模型(GenRM)和自定义 Reward 接口三种模式。
- 工具调用(Tool Use):将工具调用作为异步服务调用,无缝融入 Rollout 循环中。

端到端性能:对比 veRL
在 2 机 16 卡配置下的 DAPO-Math 任务上,Relax 相比 veRL 实现了 20% 的端到端提速。这一加速主要来源于:流式微批调度消除了全局批次同步的瓶颈,以及资源分离机制将前向推理计算完全掩盖,从而消除了进程休眠与唤醒的开销。
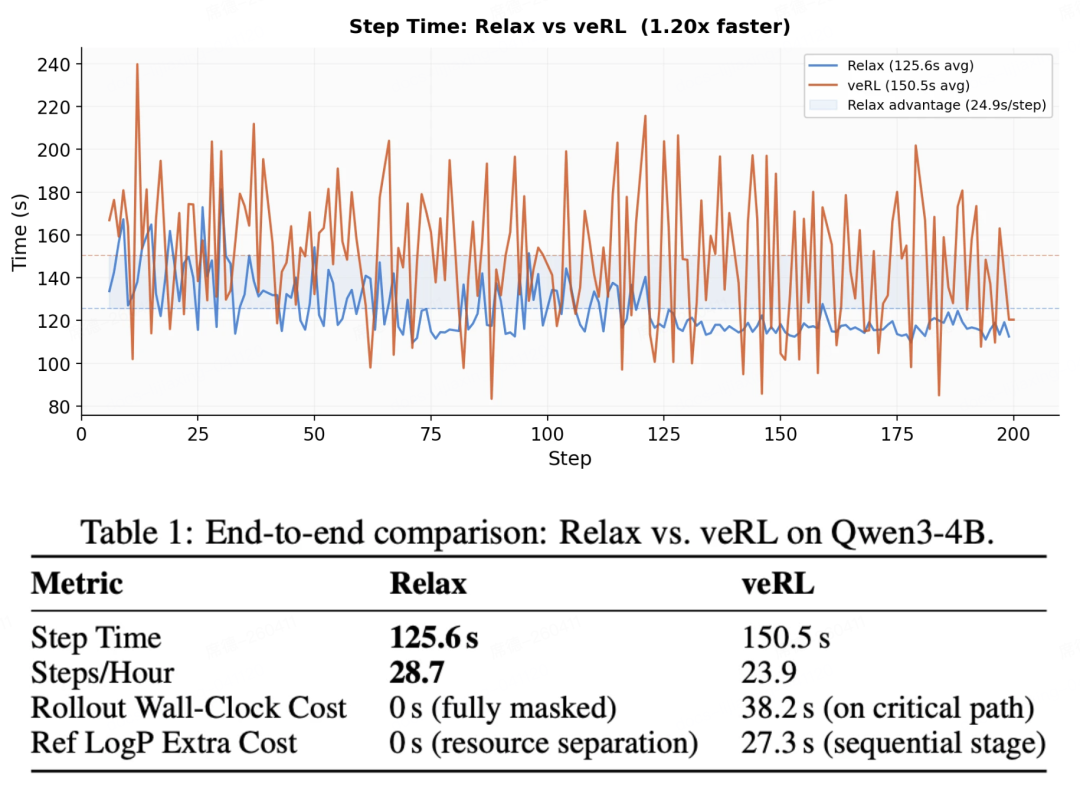
(实验配置:Qwen3-30B-A3B / 16×H800 / DAPO-MATH-17k / Megatron-LM + SGLang)
MoE 训练稳定性:Near-Zero-Overhead R3
Relax 实现了一种性能近无损退化版的 R3 机制。在 Qwen3-30B-A3B 混合专家模型上,R3 能够将路由不匹配(mismatch)降低 38%,而仅带来 +1.9% 的额外耗时。相比之下,veRL 开启 R3 后,端到端耗时增加了 34%。Relax 通过重写数据序列化路径(将路由数据从 pickle 序列化通道中剥离,改用 NCCL 原生广播)以及采用 GPU 驻留式的异步传输,使得 R3 的数据传输与重放开销变得极低。
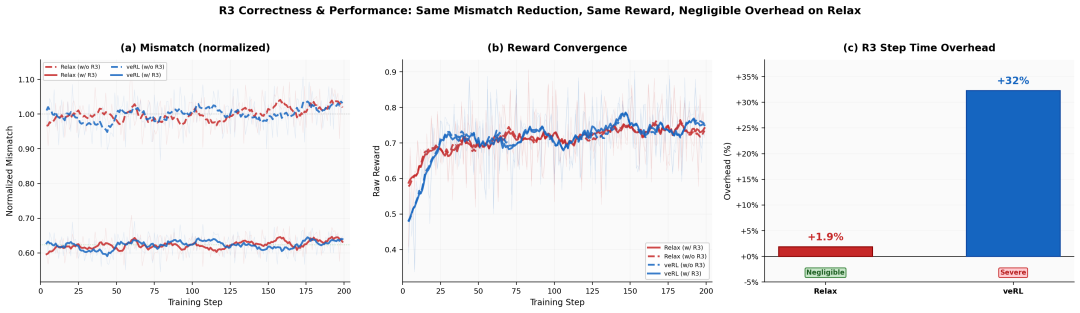
(实验配置:Qwen3-30B-A3B / 16×H800 / DAPO-MATH-17k 上的 2×2 对比实验)

当强化学习训练从纯文本、单轮交互走向全模态、多轮 Agentic 交互的新阶段时,数据异构、系统脆弱、角色耦合这三大挑战不再是能够被孤立解决的独立问题。Relax 给出的答案是一套协同设计的解决方案:全模态原生流水线解决数据异构,服务化隔离与 DCS 快速恢复解决系统脆弱,微批次级全异步流水线解决资源利用率问题——三者因果相连,形成一个完整的技术闭环,缺一不可。
未来,Relax 项目将继续紧密结合公司内部在多模态与 Agentic RL 等方面的实际业务需求,不断完善训练能力与系统优化,以期支撑更大规模、更高复杂度的模型训练任务落地。对于对如何构建高效、鲁棒的强化学习训练系统感兴趣的朋友,可以在 开源实战 板块找到更多相关的项目与深入讨论。
 发表于 2026-4-18 22:53:39
|
查看: 237|
回复: 0
发表于 2026-4-18 22:53:39
|
查看: 237|
回复: 0
