在 Agent 开发框架层出不穷的当下,如果要手搓一个自己的 AI 助手,了解它们背后的设计思路就成了向最聪明的那批人“偷师”的捷径。我最近在研究 LangGraph 时这种感觉尤其强烈。虽然对很多生活中的小项目,用它有点像“杀鸡用牛刀”,但其中蕴含的架构思想,比如 State、Node、Edge 的解耦设计,很有启发性。
在 AI 能力爆炸的今天,“语法”反而不重要了。新框架、新语言迭代太快,个体根本追不上社区的进化速度。但技术的进化与生物进化相似,再复杂的变异,其起点都是几种基础模块。LangGraph 中的基础模块,正是理解复杂 Agent 逻辑的关键。
上一篇文章我们剖析了 State 的概念,本文接着拆解剩下的两大要素:Nodes 和 Edges,并会通过一个“邮件起草 Bot”实例,演示如何将人类反馈融入工作流。
本文核心内容:
- Nodes 的定义与设计原则
- Normal Edges 与 Conditional Edges
- 如何利用 Pydantic 实现 LLM 结构化输出
- 实战:构建带人类反馈的“邮件起草 Bot”
01. 什么是 Node?
如果把 Graph 看作一个智能工厂,State 就是贯穿全局的“共享记事本”,所有部门(Node)都可以读写它。而 Node,就是流水线上那些处理 State 的“机械臂”或“加工站点”——它接收 State,加工数据,再把结果更新回去。

那么,在实际开发中,什么时候应该新建一个 Node 呢?遵循以下原则可以帮你避免陷入纠结:
- 触发更新时:只要你想对 State 做出改动,就需要新建一个 Node。
- 坚持单一职责:就像写代码追求可复用、可维护一样,Node 的功能越纯粹,未来用基础模块搭建复杂逻辑就越轻松。如果一个 Node 看上去很“精分”,一会儿关注 A,一会儿关注 B,那就该拆分了。
- 调用 LLM 看人设:如果调用大模型,尽量给每个 Node 分配“单一人设”,清晰定义它在整个链条中的角色。
在代码层面,Node 的本质是一个函数(实际是 Runnable)。得益于 LangGraph 底层封装,我们只需在 Node 函数中输出 State 需要更新的“增量部分”,完全不用把整个 State 重新抄写一遍。
假设我们定义了这样的 State,其中 message 和 count 使用 operator.add 累加,memberTier 则直接覆盖:
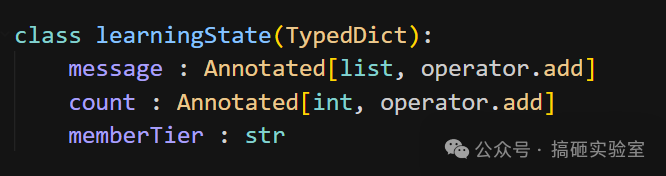
对应的 Node 函数可以写成这样,它只返回 message 和 count 两个 Key 的增量数据:

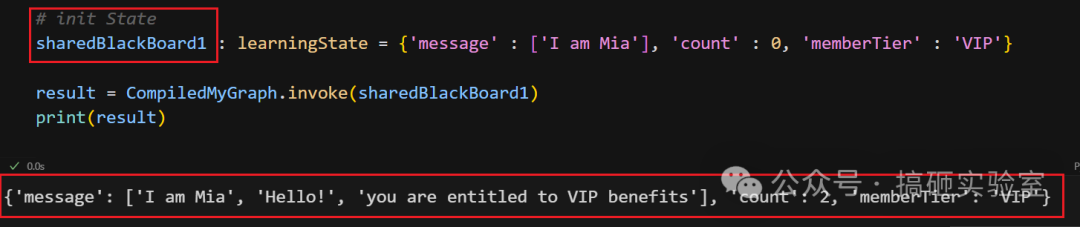
假如初始化 State 长这样:

经过 sayHello 处理后,message 会自动新增一条,count 也会加 1:

这里有个关键点:如果 Node 的输出 Key 与 State 不重叠,它就只是“路过”,不会改变 State。此外,Graph 中有两个默认的特殊节点——START 和 END,它们作为常量存在,用来标记工作流的“起点”与“终点”。为什么需要它们?因为执行图时数据是有序流动的,没有 START 就无法定义顺序,没有 END 底层搜索循环就停不下来。

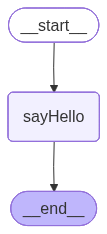
02. 什么是 Edge?
Edge 就好比连接各个“机械臂”的“传送带”,在底层,它可以被理解为一个调度字典,决定物料下一步流向哪里。
LangGraph 中有两种基础边:
- 普通边 (Normal Edges):固定映射,逻辑是“如果 A 结束,永远去 B”。字典的 Key 是上游节点名,Value 是下游节点名。这里全部使用字符串名而非函数名,是为了解耦,方便随时重命名或替换节点。
- 条件边 (Conditional Edges):动态映射,依据 Router 函数的输出来分流。
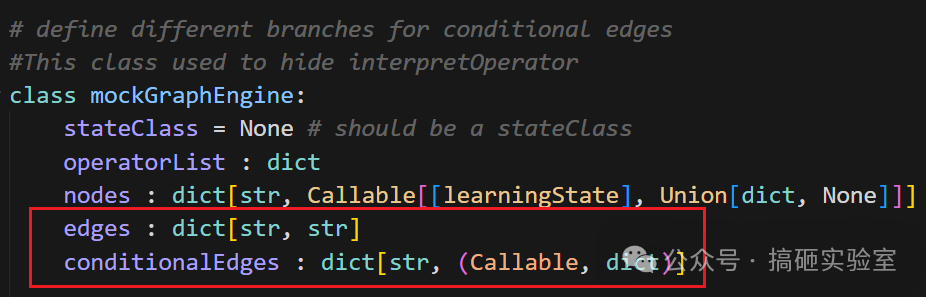
下图模拟了 Edge 结构,其中 edges 是普通边,conditionalEdges 是条件边:
定义普通边的语法很简单,就是显式调用 add_edge 并传入字符串名字:

03. 条件边:让 Agent 学会“看人下菜碟”
条件边需要三要素:上游节点的“名字”、路由函数、以及一张路径映射表。它本质是让 Graph 具备了判断能力。
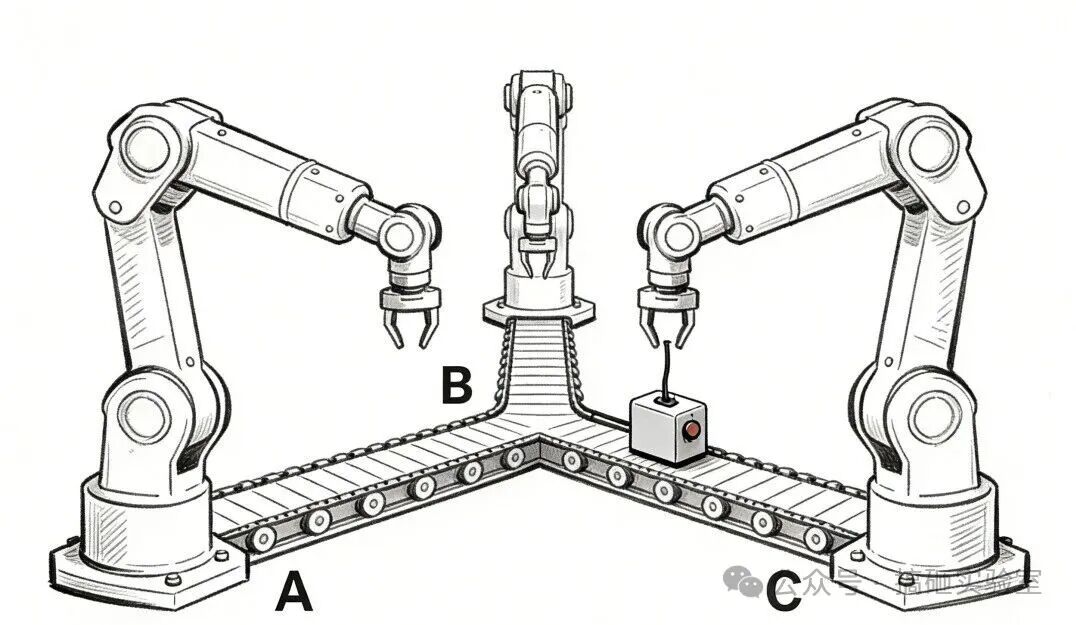
比如我们要做一个 VIP 用户分流:用户是 VIP 就去 VIP 通道,否则去普通通道。流程大致如下:
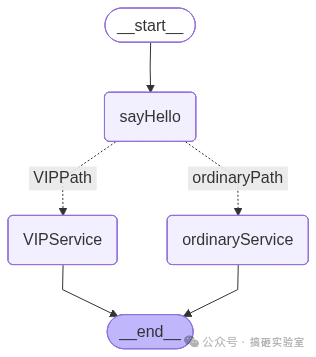
首先定义 Router 函数 checkVIP,它根据 State 里的 memberTier 字段返回不同的“意图字符串”:
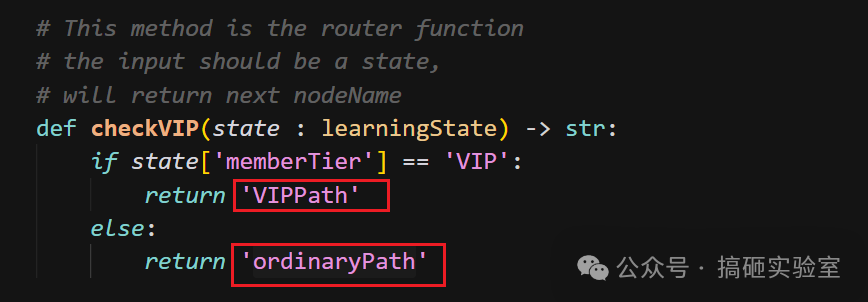
调用 add_conditional_edges 时的语法如下,注意 pathMap 的作用是把意图字符串映射到真实的 Node 名字:
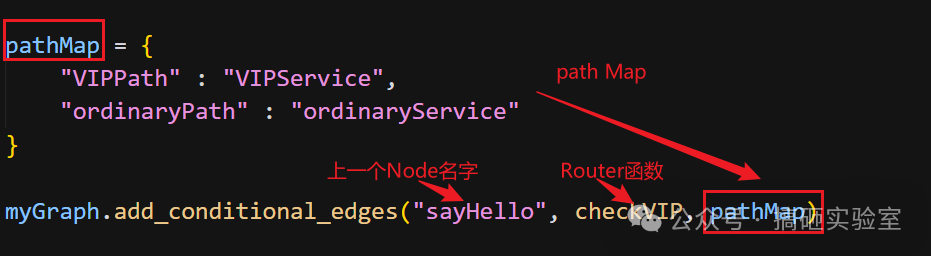
当然,如果你的 Router 函数返回的字符串本身就和 Node 名字一致,也可以直接传一个列表,框架会自动做“恒等映射”。官网示例经常这么做:
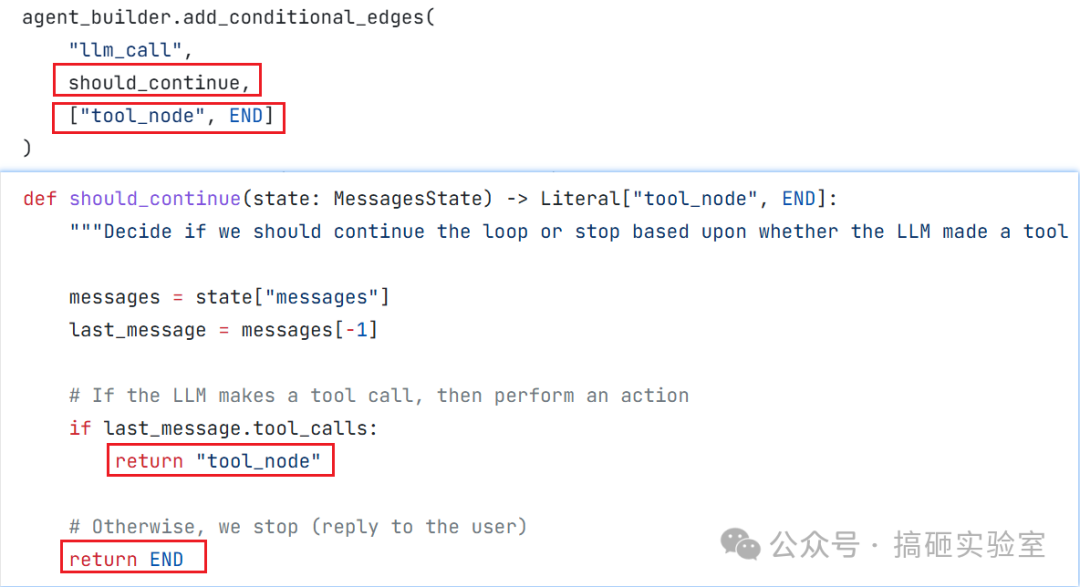
04. 组装 Graph 与编译
理解了三大要素,就可以组装 Graph 了。步骤概括为:传 State、加 Node、连 Edge。下面是一段完整的构建代码示例:
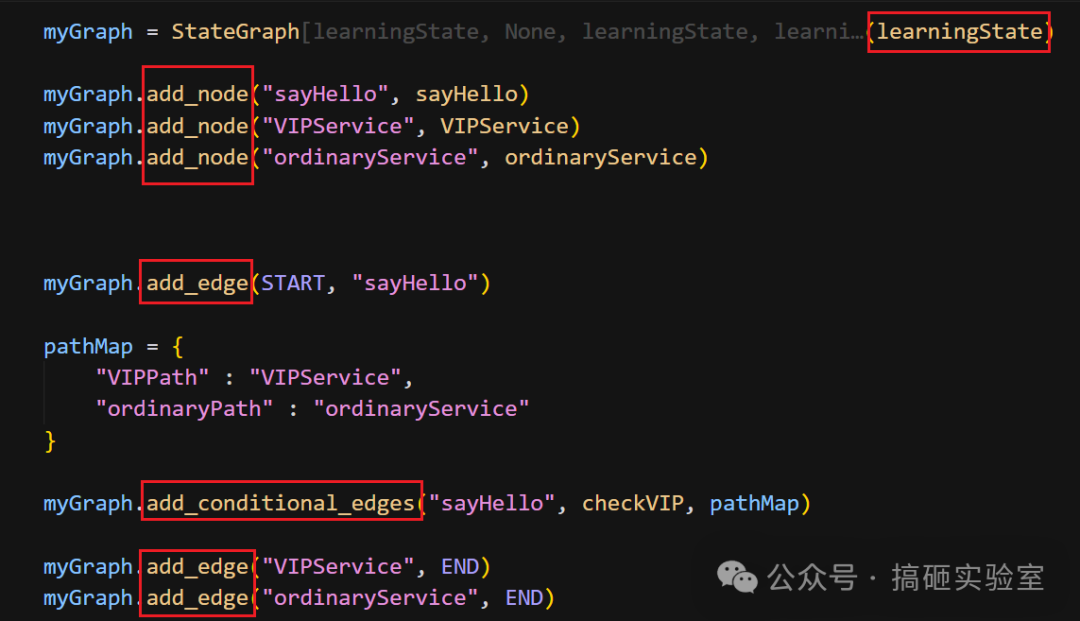
定义好图后,务必执行一次 compile()。这步操作会解析那些字符串形式的配置,将 Annotated 的归并函数等还原为真实对象,为实际运行做好准备。

编译完成后,调用 invoke 传入初始 State,工作流就能跑起来了:

主程序逻辑与 Graph 本身要分清楚。最简单的主程序就是定义初态、调用 Graph、输出结果:
05. 实战:做个会反思的“邮件起草 Bot”
理论讲完,我们来动手做一个能跟人对话、反复修改的邮件起草助手。整个 Graph 只有一个核心 Node,但包含了与 LLM 交互和融合人类反馈的完整逻辑。
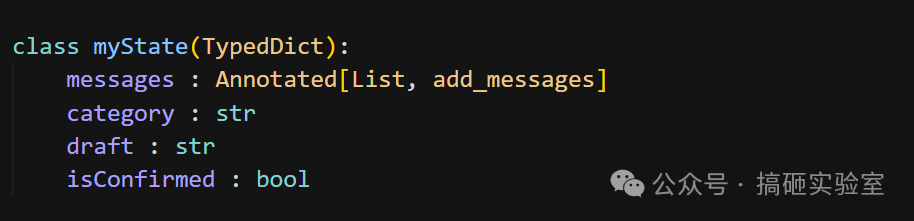
第一步:定义 State
起草邮件需要知道消息历史、分类、草稿和用户确认状态。因此 State 设这四个字段,isConfirmed 默认 False 以驱动修改循环。
第二步:用 Pydantic 约束输出
LLM 的输出不可控,必须用 Pydantic 给它装个“精密收纳盒”。它基于 Python 类型提示,比普通字典约束更强:数据不对会直接报错,还能自动做类型强制与序列化。在 AI 工程里,Pydantic 就是连接“天马行空的 LLM”与“严谨逻辑”的桥梁。
我们定义 ProposerOutput 类作为输出格式:
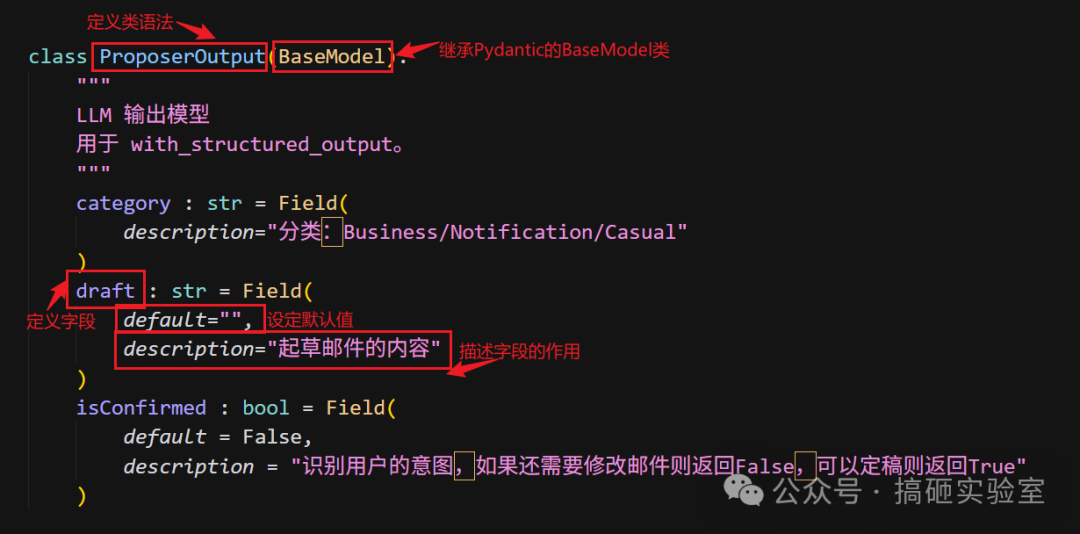
写 description 非常重要,这不仅是给开发者看的,更会作为提示传给 LLM,帮它理解输出要求。
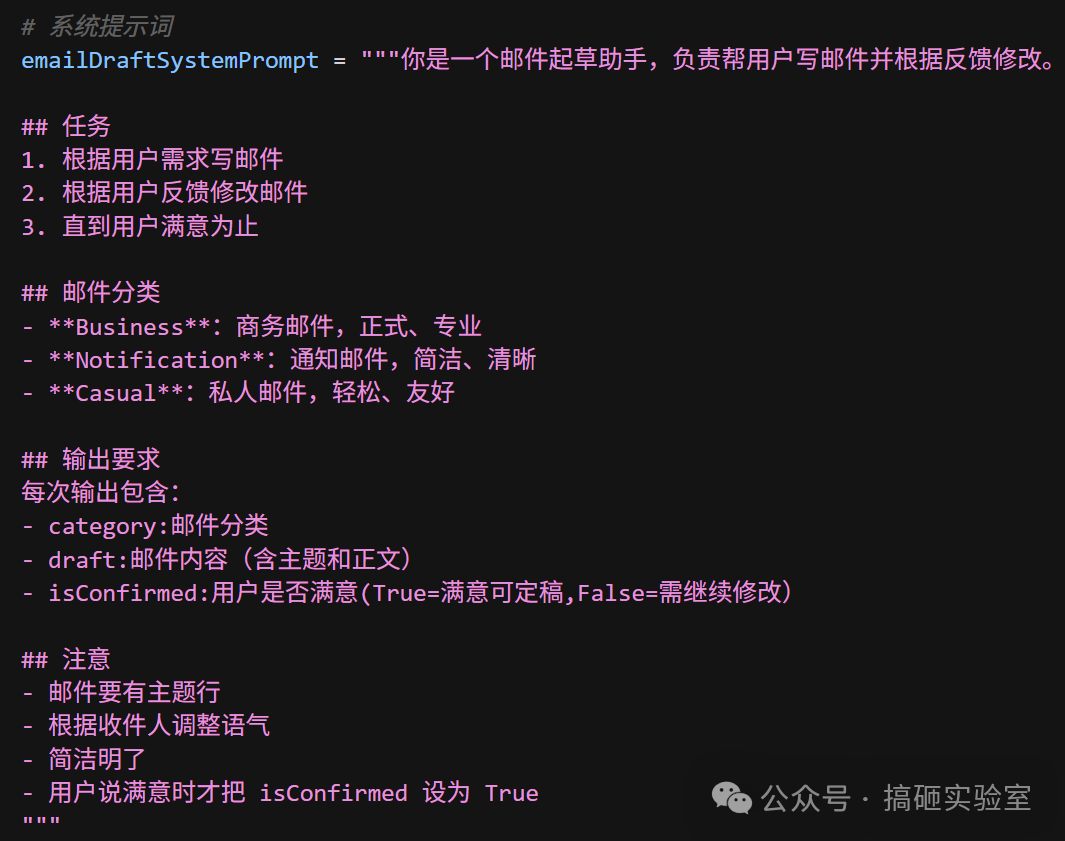
第三步:系统提示词
提示词定义了这个 Node 的人设,建议抽离到函数外部方便微调:
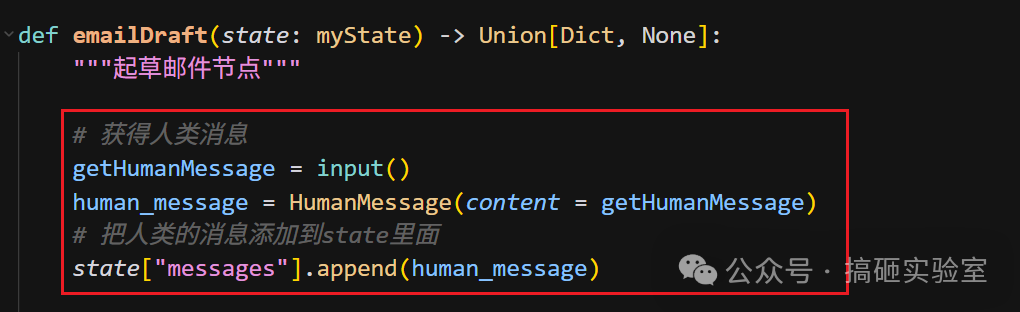
第四步:编写核心 Node
为了让例子可交互(只要基于终端就能跑),我们在 Node 内部用 input() 来接收人类反馈。这里必须强调:生产环境千万别这么干!因为 input() 会阻塞线程,导致资源无法释放。正确的做法我们下篇文章讨论。
人类输入通过 HumanMessage 封装后推入 State 的 messages 列表。
接下来是核心:如何让 LLM 返回结构化数据?重点在于 with_structured_output。
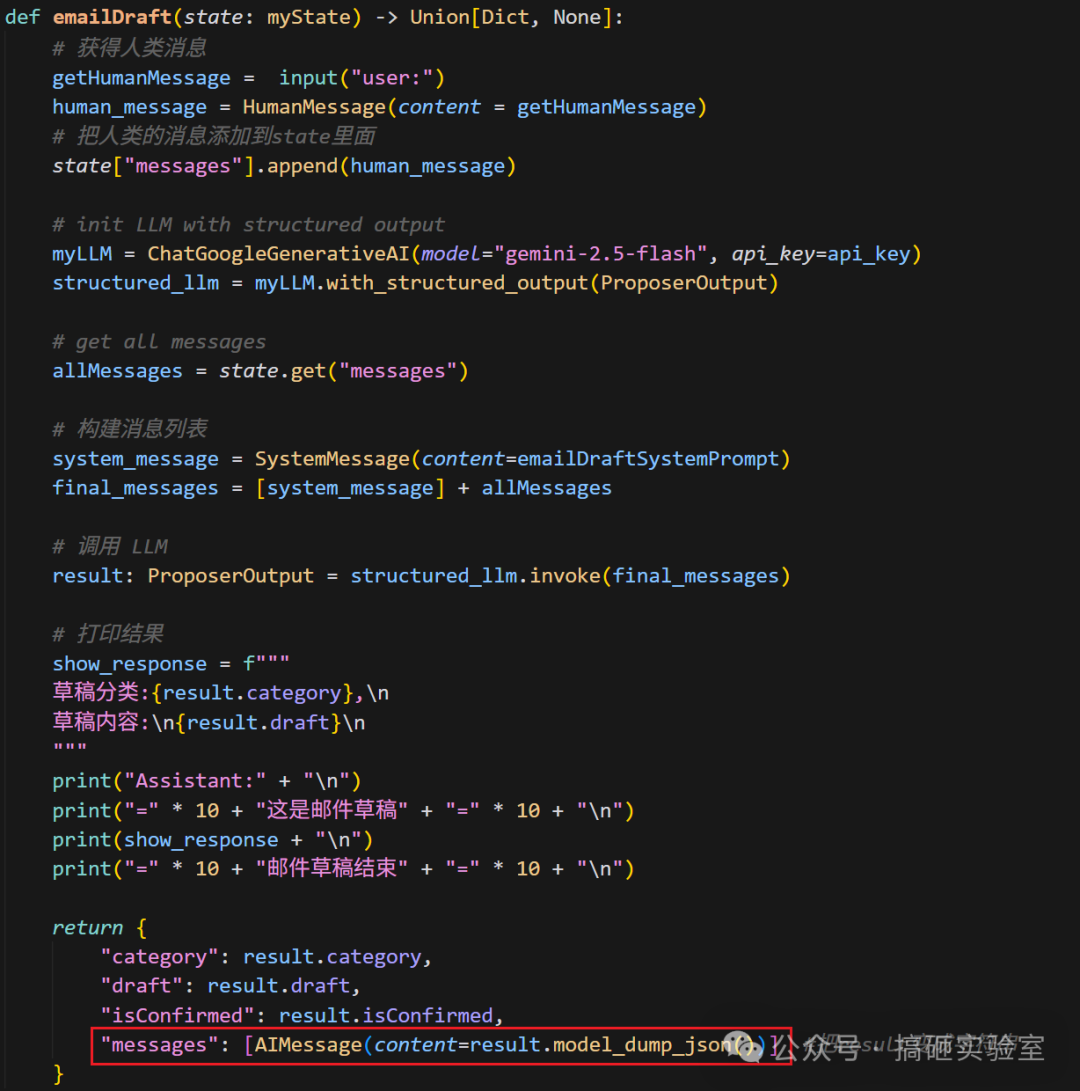
先用自己熟悉的 API(这里以 Gemini 为例)初始化模型,然后把 ProposerOutput 传给 with_structured_output 方法。LangGraph 在底层会玩一个“骗术”:它把我们的数据结构伪装成一个 Function Tool,让 LLM 误以为自己在调工具,从而严格按参数格式输出。如果 LLM 输出的 JSON 校验不通过,Pydantic 会直接报错,并不让错误数据蒙混过关。


构建消息列表时,通常会把系统提示词和 State 里的历史消息拼接起来。为简单起见,这里把历史消息全量传给 LLM(实际生产需用摘要或截断来防止超 Token 限制)。

拿到结构化结果后,我们在终端打印出草稿:

最后,Node 返回“增量”数据。为了让 LLM 记住历史,必须把它的回答(AIMessage)也追加到 messages 字段。
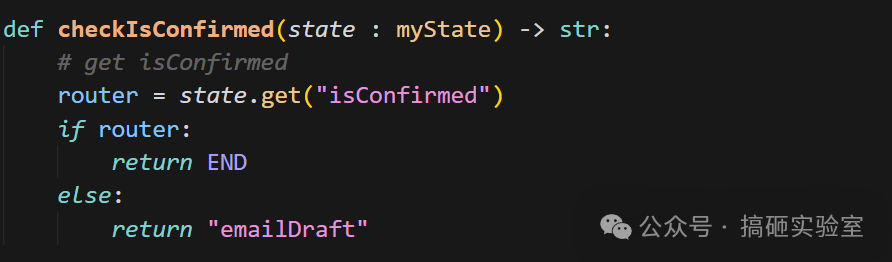
第五步:定义条件边与循环
这个 Graph 需要循环,条件边的 Router 函数根据 isConfirmed 决定是结束还是再跑一遍 emailDraft。
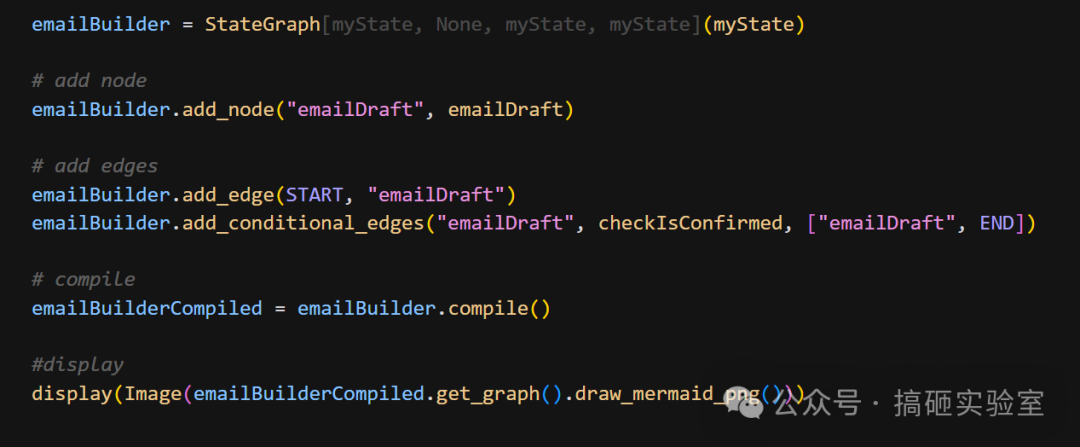
第六步:构建与运行
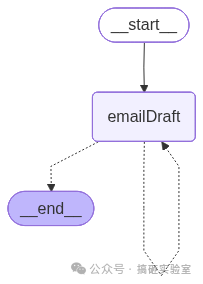
把节点和边拼装起来,编译,并用 display 查看生成的流程图,能直观看到那个从 emailDraft 指回自身的循环回路。
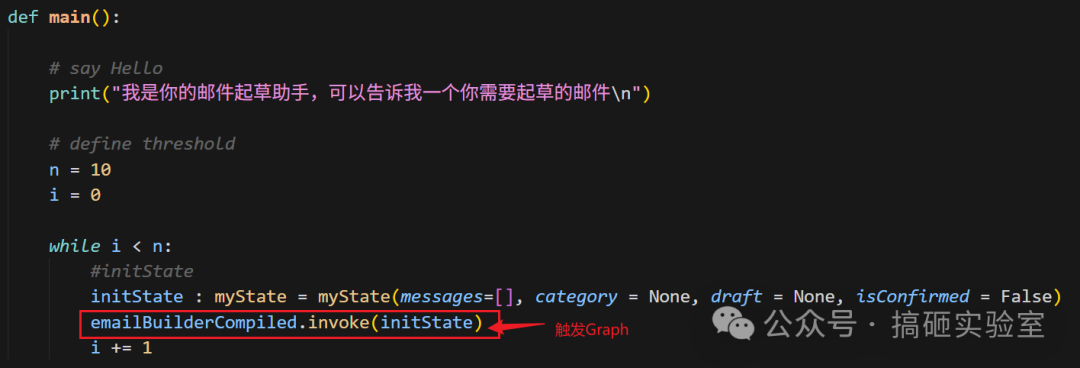
主程序用一个 while 循环不断触发 Graph,直到用户确认为止。
最终的运行结果:系统发来问候,我输入“写一个请假申请”后,Bot 马上生成了一份带占位符的模板。当我补充个人信息后,它草拟出了完整的请假邮件。我再提出“礼貌一点”,它立刻润色得更加得体。
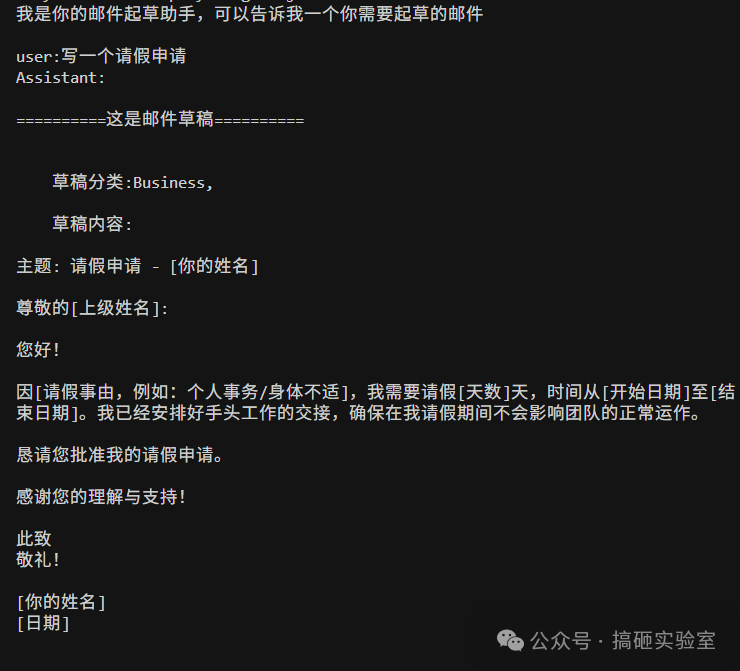
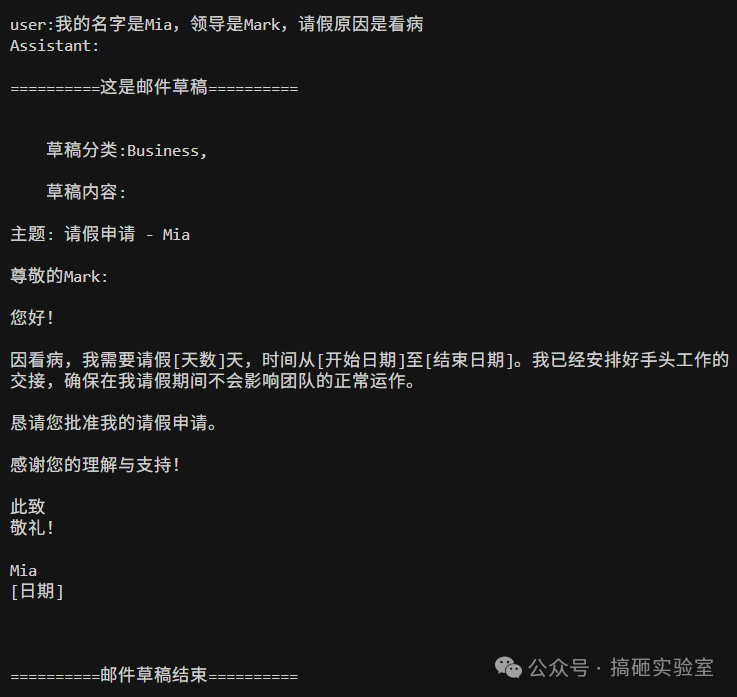
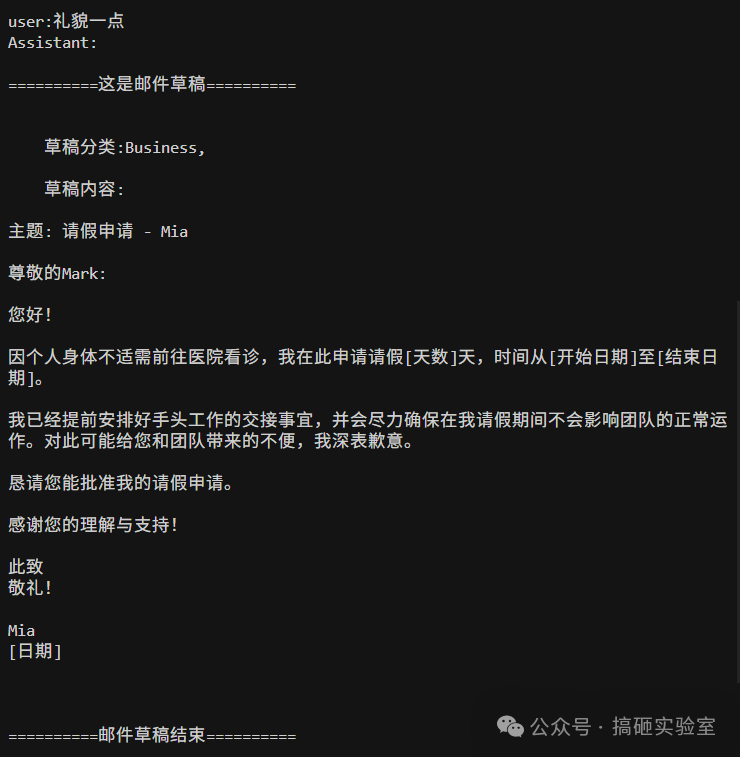
06. 总结
总的来说,Node 是加工 State 的工作站,我们遵循“单一职责”并只返回增量数据;Edge 是连接它们的传送带,分普通和条件两种,依赖“字符串名字”进行解耦导航;Graph 需要编译后通过 invoke 运行。
而借助 Pydantic 与 with_structured_output 这套组合拳,我们能驯服 LLM 的野性输出,将其转变成严丝合缝的 Python 对象。
虽然直接在 Node 里用 input() 有悖最佳实践,但它确实清晰地展示了人类反馈如何注入 Agent 循环。下一篇我们聊聊怎么用“打断(Interrupt)”机制来优雅地解决阻塞问题,让生产级的交互真正流畅起来。
 发表于 2026-6-7 18:44:02
|
查看: 124|
回复: 0
发表于 2026-6-7 18:44:02
|
查看: 124|
回复: 0
