文章概览
- 工作背景
- 分片管理核心原理
- 分片恢复核心参数与调优实践
- 分片重平衡参数与性能优化
- 分片策略最佳实践
- 分片治理生产案例
- 分片运维高频实操命令
- 分片使用运维总结
- 参考文献
一、工作背景
日常ES集群运维中,相当大比例的稳定性问题、性能瓶颈和扩容故障,根源都集中在分片规划不合理、分片恢复参数使用默认值、对重平衡机制不熟悉这三点上。这篇文章从相关原理展开,结合生产实践(十万级分片治理),阐述ES分片的使用与实践方案,可作为日常使用与运维的参考。
二、分片管理核心原理
2.1 主分片与副本分片核心机制
ES 集群由多个索引构成,索引由多个分片构成。单个索引的数据会被拆分成多份,分散存储在集群的不同节点上,以此实现海量数据存储、读写负载分担和高可用容灾。
分片分为主分片和副本分片两类,分工明确。
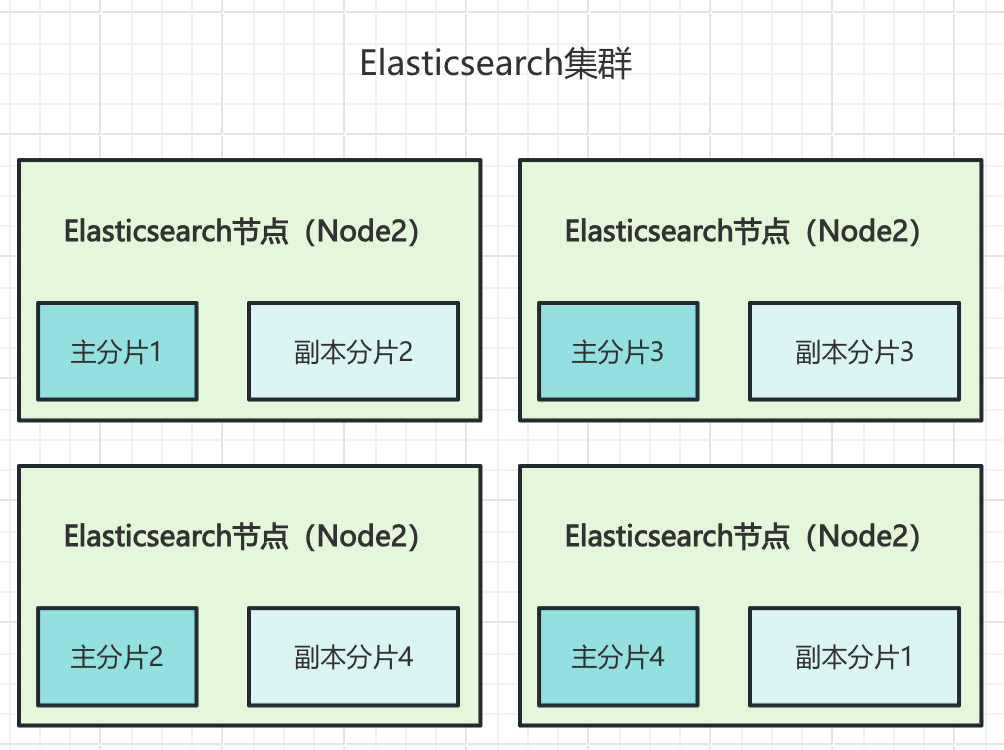
主分片(Primary Shards):集群写操作的唯一核心执行者,索引的新增、修改、删除请求,都会先在主分片执行成功,再同步数据至对应副本分片,保障集群数据一致性。
注意:索引创建后,主分片数量无法修改。若规划失误,只能通过重建索引或Reindex迁移数据解决。
副本分片(Replica Shards):主分片的完整数据备份,不参与任何写请求,核心作用有两个:
- 高可用容灾:当主分片所在节点宕机、离线,副本分片会自动晋升为主分片,避免数据丢失、服务中断;
- 分担读压力:所有查询、检索请求并行命中主、副本分片,大幅提升集群查询吞吐量。
注:主分片只能有一份,副本分片可以设置0到多份。生产环境禁止配置0副本,否则存在丢数据风险。
2.1.1 生产分片分配核心原则
ES 内置的分片分配策略(自动动态调整)需要掌握:
- 核心定律:同一主分片和自身的副本分片绝对不会分配在同一个节点,避免单节点宕机导致分片整体丢失。
- 负载优先:集群会自动将分片分配到分片数较少、CPU/内存/磁盘负载更低的节点,以均衡集群压力。
- 整体均衡:自动调整各节点分片数量,避免单节点分片过多引发资源耗尽或查询超时。
ES自带的分配策略不一定是最优的,有时必须人工干预。例如日志集群新增3个节点后创建次日索引,大量分片会倾斜给新节点。若不干预,势必导致新节点压力飙高甚至宕机。
2.2 分片恢复与重平衡机制
当集群发生扩缩容、节点故障重启、索引创建时,ES会自动触发分片恢复与重平衡(Rebalance)操作,该阶段也是集群抖动的高发期。深入理解底层机制,才能精准调参、有效规避故障。
2.2.1 分片恢复机制
当节点故障离线、集群新增节点后,集群中会出现大量未分配分片,ES会自动将这些分片恢复、迁移至正常节点,恢复分片副本,保障数据高可用。
2.2.2 分片重平衡机制
当集群拓扑发生变化(节点新增、离线、故障)导致分片分布不均衡时,ES会自动执行重平衡,跨节点迁移分片以保证整体负载均匀。
中小集群重平衡利大于弊,但十万级大集群的自动重平衡往往是故障根源。
2.2.3 生产常见分片状态解读
日常运维排查故障,重点关注这5种分片状态,可快速定位问题:
- STARTED:分片初始化完成,正常运行、可读写。
- UNASSIGNED:分片未分配到任何节点,属于异常状态,需排查原因(磁盘不足、分配规则限制、节点故障等)。
- INITIALIZING:分片正在初始化,节点重启、分片新建后常见临时状态。
- RECOVERING:分片正在从其他节点同步恢复数据,扩容、重启后高频出现。
- RELOCATED:分片正在跨节点迁移,重平衡过程中的临时状态。
三、分片恢复核心参数与调优实践
分片恢复参数是集群运维的核心,默认参数适配性低,集群扩容、节点重启后,极易出现恢复过慢、长时间卡在恢复中,或者恢复并发过高打满磁盘、带宽的问题。合理调整参数对集群恢复正常运维至关重要。
3.1 核心恢复参数详解(业务集群使用)
以下参数均支持集群全局配置,适配ES主流版本,包括默认参数与生产建议值:

集群参数恢复配置示例:
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.node_concurrent_recoveries": 8,
"cluster.routing.allocation.node_concurrent_incoming_recoveries": 8,
"cluster.routing.allocation.node_concurrent_outgoing_recoveries": 8,
"cluster.routing.allocation.node_initial_primaries_recoveries": 8,
"indices.recovery.max_bytes_per_sec": "200mb"
}
}
注:如果集群同时配置了 transient 和 persistent,通常 transient 会覆盖后者,但重启后会丢失。修改配置前请务必确认两者是否冲突,不一致时系统以 transient 为准。
3.2 分片恢复过程监控命令
扩容、重启、故障恢复期间,需实时监控分片恢复进度和节点负载:
# 1. 监控分片恢复详细进度、耗时、源目标节点
GET /_cat/recovery?v=true&h=i,s,t,ty,shost,thost,f,fp,b,bp
# 2. 查看集群整体健康状态,定位分片异常
GET /_cluster/health
# 3. 查看节点磁盘、堆内存负载,防止恢复过程资源打满
GET /_cat/nodes?v&h=name,diskUsed,diskAvail,heapUsed,heapMax
四、分片重平衡参数与性能优化
重平衡机制是一把双刃剑:默认自动均衡能保证分片均匀,但频繁、大规模重平衡会占用带宽和磁盘IO,导致业务查询超时。
4.1 重平衡核心参数详解
4.1.1 重平衡开关控制
cluster.routing.rebalance.enable:控制集群分片迁移、重平衡的权限,生产运维高频使用,支持4种配置:
- all:默认值,允许所有分片迁移、全量重平衡。
- primaries:仅主分片允许重平衡,副本禁止迁移。
- replicas:仅副本分片允许重平衡,主分片禁止迁移。
- none:关闭所有分片重平衡。维护、重启、扩容期间必备配置。
注:cluster.routing.rebalance.enable 和 cluster.routing.allocation.enable 容易搞混,以下是整理的区别:
- cluster.routing.rebalance.enable:控制「已分配的分片要不要迁移均衡」(重平衡)有效值:all、primaries、replicas、none。
- cluster.routing.allocation.enable:控制「新分片能不能分配、恢复」(分片分配)有效值:all、primaries、new_primaries、none。
4.1.2 重平衡并发控制
cluster.routing.allocation.cluster_concurrent_rebalance:控制集群全局同时执行的重平衡数量,默认2。高配集群可按需调大以加速均衡。
4.1.3 实操配置命令
# 1. 集群维护、节点重启:禁用所有分片迁移
PUT /_cluster/settings
{
"transient": {
"cluster.routing.rebalance.enable": "none"
}
}
# 2. 仅允许主分片移动
PUT /_cluster/settings
{
"transient": {
"cluster.routing.rebalance.enable": "primaries"
}
}
# 3. 维护完成,恢复默认重平衡规则
PUT /_cluster/settings
{
"transient": {
"cluster.routing.rebalance.enable": "all",
"cluster.routing.allocation.cluster_concurrent_rebalance": 2
}
}
4.2 重平衡配套优化策略
磁盘水位线是控制分片迁移的关键参数,生产环境必须提前配置:
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": "85%",
"cluster.routing.allocation.disk.watermark.high": "90%",
"cluster.routing.allocation.disk.watermark.flood_stage": "95%"
}
}
参数说明:
- low(85%~90%):ES停止向该节点分配新分片,已有分片正常读写。
- high(90%~95%):ES 会主动把当前节点上已有的分片迁移到其他空闲节点,逐步清空该节点压力。
- flood_stage(95%):节点上的所有索引被强制设为只读,无法写入。
注:磁盘空间需配置告警,提前预警并及时处理,避免达 flood_stage 影响业务。
五、分片策略最佳实践
5.1 分片数量规划规范
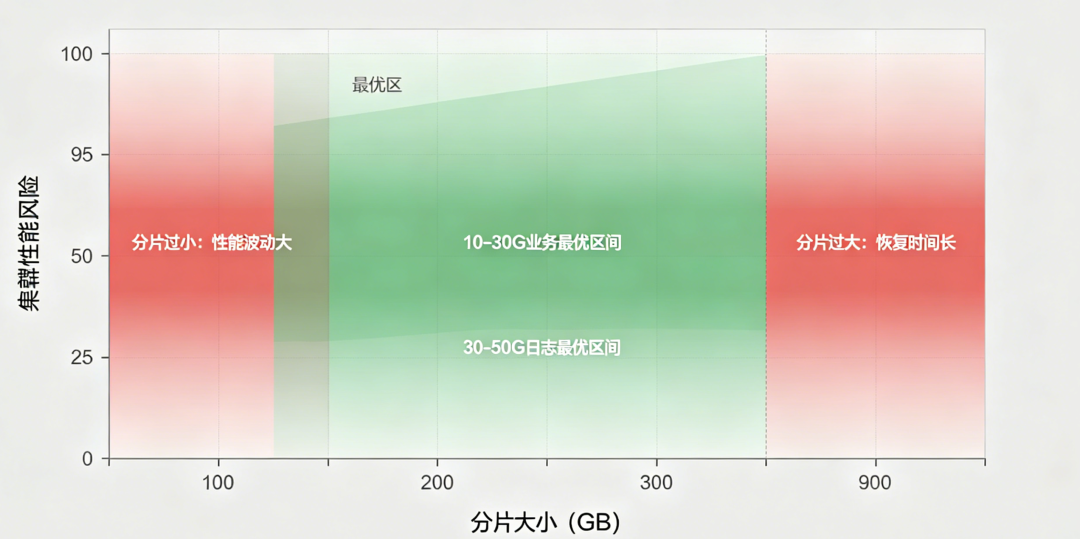
分片数量是前期规划的重中之重,一旦创建无法修改,不合理的分片数会长期拖累集群性能。统一的生产标准:
- 单分片最优大小:业务索引10-30GB,日志索引可达50GB左右。过小浪费资源,过大影响恢复和查询。
- 分片数量上限:单索引总分片数不超过集群数据节点数的2倍。
- 集群分片总数:建议不超过10万。
- 节点分片总数:默认不超过1000,最大建议不超过3000。过多会影响元数据和master稳定性,导致节点脱离集群。
分片数调整方案
主分片数创建后无法直接修改,只能通过重建索引调整:
5.1.1 常规分片重构(停服方式)
# 1. 新建目标分片数的索引
PUT /new-index
{
"settings": { "number_of_shards": 3 },
"mappings": { "properties": {} }
}
# 2. 全量迁移数据
POST /_reindex
{
"source": { "index": "my-index" },
"dest": { "index": "new-index" }
}
# 3. 删除原始索引并回写
DELETE my-index
POST /_reindex
{
"source": { "index": "new-index" },
"dest": { "index": "my-index" }
}
注:Reindex重构成本高,需停写与补数。若不接受停服,推荐使用下方别名方式。
5.1.2 生产推荐分片重构(零停机别名切换)
按照上述的索引名称:
- 旧索引:
my-index(主分片不能改)
- 新索引:
my-index-v2(可设置需要的新分片数)
- 业务使用别名:
my-index-alias
# 1. 给旧索引绑定别名(业务统一使用别名访问)
POST /_aliases
{
"actions": [{ "add": { "index": "my-index", "alias": "my-index-alias" } }]
}
# 2. 创建新索引(设置新的主分片数)
PUT /my-index-v2
{
"settings": { "number_of_shards": 3, "number_of_replicas": 1 },
"mappings": { "properties": { ... } }
}
# 3. 异步Reindex迁移数据
POST /_reindex?wait_for_completion=false
{
"source": { "index": "my-index" },
"dest": { "index": "my-index-v2" }
}
# 4. 查看进度:
GET _tasks/task_id
# 5. 无缝切换别名(原子操作,0停服)
POST /_aliases
{
"actions": [
{ "remove": { "index": "my-index", "alias": "my-index-alias" } },
{ "add": { "index": "my-index-v2", "alias": "my-index-alias" } }
]
}
# 6. 验证
GET my-index-alias/_alias
# 确认别名指向 my-index-v2 即为切换成功
注:后续业务代码、查询、写入全部使用别名 my-index-alias,切勿直接使用真实索引名。
5.2 副本数配置规范
- 高可用生产集群:默认配置1个副本,兼顾容灾与资源消耗。
- 高查询、低写入场景:适当增加副本数分担读压力(需更多节点支撑)。
- 离线归档/日志数据:可配置0副本节省空间(需接受丢数据风险)。
5.3 单节点分片数限制配置
通过参数限制单节点最大分片数量,避免分片集中堆积,导致单节点负载过载:
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.shards_per_node": 2
}
}
注:如集群6个数据节点、索引6个分片,可设置shards_per_node: 2,保证主副分片均衡落入每个节点。
六、分片治理生产案例
6.1 案例一:集群扩容后分片负载不均问题
问题背景:5节点ES集群扩容至10节点后,旧节点负载过高,新节点闲置,业务查询卡顿。
解决方案:
-
优化分片恢复参数,提升迁移效率,避免长时间卡顿
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.node_concurrent_recoveries": 8,
"cluster.routing.allocation.node_concurrent_incoming_recoveries": 8,
"cluster.routing.allocation.node_concurrent_outgoing_recoveries": 8,
"cluster.routing.allocation.node_initial_primaries_recoveries": 8,
"indices.recovery.max_bytes_per_sec": "200mb"
}
}
-
开启重平衡并调高并发
PUT /_cluster/settings
{
"transient": {
"cluster.routing.rebalance.enable": "all",
"cluster.routing.rebalance.cluster_concurrent_rebalance": 8
}
}
-
全程监控分片分布与节点负载。
-
对重要索引配置 shards_per_node 保证节点分片均衡。
复盘最佳实践:扩容必须分步操作,禁止一次性批量加节点;扩容前提前调优恢复参数,扩容后监控均衡进度。
6.2 案例二:十万级分片超大集群治理实战
集群背景:Qunar-实时日志平台目前采用的是 ELK 架构方案,承载全司实时日志,集群节点规模达到数百节点,全局总分片最高突破10万,日均写入数据量数百TB级,属于典型的海量分片、高吞吐、低延迟稳态运行集群。长期以来面临诸多挑战,此案例将痛点风险一一拆解并给出实际生产运维方案。

核心痛点梳理如下:
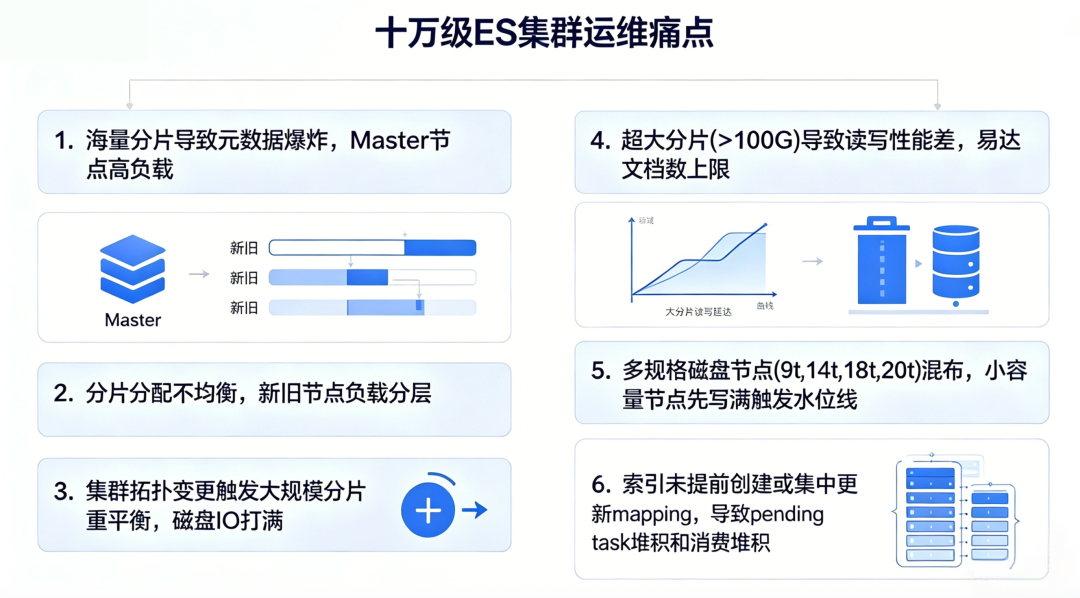
1、海量分片导致集群元数据体量巨大:master节点频繁处理分片状态变更、元数据同步,CPU、线程池长期高负载,偶发集群状态更新超时、轻微脑裂风险;
2、分片分配不均衡:每周批量创建索引(周维度),原生分片分配机制将新分片优先分配至空闲节点,导致新旧节点分片数量与负载严重分层,高负载节点频繁脱离集群;同时加重 master 元数据管理压力,进而引发更大范围的节点崩溃。
3、集群加减节点导致分片同步压力大:节点滚动重启、增减节点、或者小规模扩容时,默认自动重平衡触发数百甚至上千分片同时同步,磁盘IO直线上升,影响读写,甚至消费堆积波动;
4、超大分片导致读写不均衡:个别大索引的分片数分配不合理,导致单个分片超大(大于100G甚至150G),平衡时间长。也有日志索引分片条数多,导致很快达到21.47 亿条(ES 单分片文档数上限为 2,147,483,519),超过最大限额无法写入。
5、节点存储规格不同导致小存储节点更易先写满:集群配置有9t、14t、18t、20t多种规格(同时也有SSD和非SSD磁盘),小存储更容易写满,触发磁盘水位线继而引发写入终止。
6、索引未提前创建、mapping统一更新导致集群pending task上升和消费堆积:索引如果未提前创建(新周期),在新周期统一写入时创建,会有大量任务导致集群卡死,消费堆积。提前创建索引也会因为大索引的mapping更新导致pending task上升,继而加剧消费堆积。
区别于中小集群轻量化运维,超大集群治理核心是锁死稳态参数、禁用原生自动重平衡机制、人工可控调度,以下是实际生产运维调优的方案:
6.2.1 全局恢复参数固化(杜绝默认参数隐患)
ES默认并发、限速、磁盘水位参数仅适配千级分片小集群,十万级分片场景下,要么恢复过慢堆积大量未分配分片。我们通过持久化参数统一固化分片恢复相关配置,长期生效不丢失,完整DSL如下:
// ==================== 分片恢复参数说明 ====================
// node_concurrent_recoveries: 单节点分片恢复并发,适配高负载大集群
// node_concurrent_incoming_recoveries: 入向/出向恢复并发差异化管控,避免单向流量打爆
// node_initial_primaries_recoveries: 节点重启后主分片初始化并发,加速主分片恢复效率
// max_bytes_per_sec: 万兆网卡SSD集群提速分片传输,减少恢复时间
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.node_concurrent_recoveries": 20,
"cluster.routing.allocation.node_concurrent_incoming_recoveries": 10,
"cluster.routing.allocation.node_concurrent_outgoing_recoveries": 10,
"cluster.routing.allocation.node_initial_primaries_recoveries": 20,
"indices.recovery.max_bytes_per_sec": "200mb"
}
}
6.2.2 磁盘水位线调整
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": "92%",
"cluster.routing.allocation.disk.watermark.high": "95%",
"cluster.routing.allocation.disk.watermark.flood_stage": "98%"
}
}
注:统一调高三类水位线,延迟触发各项风险,可以将磁盘利用率达到最大化。
6.2.3 永久禁用全局自动重平衡(从根源杜绝集群抖动)
自动重平衡对于小集群(节点小于100,或者分片数低于10000)稳定高效,对大集群而言则是稳定性灾难:

// ==================== 禁用自动重平衡参数说明 ====================
// rebalance.enable: 彻底关闭所有场景自动重平衡,禁止已分配分片自动迁移
// cluster_concurrent_rebalance: 全局重平衡并发置0,作为兜底防护防止误开启后触发大规模迁移
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.rebalance.enable": "none",
"cluster.routing.allocation.cluster_concurrent_rebalance": 0
}
}
注:关闭重平衡后,在节点扩容、重启、离线时,避免了集群节点成百上千分片跨节点同步,避免集群整体抖动,磁盘io打满等风险。
6.2.4 增加delayed_timeout时间
// ==================== delayed_timeout参数说明 ====================
// log_test-2026.21为示例索引,实际使用时请替换为目标索引名
PUT log_test-2026.21/_settings
{
"index.unassigned.node_left.delayed_timeout": "50m"
}
注:默认 delayed_timeout 为1分钟,节点短暂脱离后极易触发大规模分片重分配与恢复,加剧集群负载。将其调整为50m,可为节点重启或网络抖动预留充足的自愈窗口,避免无效的跨节点数据搬迁,保障集群稳定。
不同索引分片大小不同,delayed_timeout 可有所偏差(分片大的适当延长,分片小的适当缩短)。全量索引均需设置此参数,生产中通过索引模板统一管理,禁止逐索引手动修改。
6.2.5 索引提前创建机制与配置模板管理
时序性日志索引需提前批量创建,并通过独立模板实现个性化配置,具体措施如下:
1. 模板管理
对于索引创建一个通用模板log_default,存储通用 settings 与 mappings,类似如下:
{
"order": 1,
"index_patterns": ["log_*"],
"settings": {
"index": {
"routing": {
"allocation": {
"total_shards_per_node": "1"
}
},
"refresh_interval": "60s",
"number_of_shards": "12",
"translog": {
"durability": "async"
},
"number_of_replicas": "0"
}
},
"mappings": {
"dynamic_templates": [
{
"strings": {
"mapping": {
"norms": false,
"ignore_above": 256,
"type": "keyword"
},
"match_mapping_type": "string",
"match": "*"
}
}
],
"properties": {
"@timestamp": { "type": "date" },
"log_name": { "ignore_above": 256, "type": "keyword" },
"content": { "norms": false, "type": "text" }
}
},
"aliases": {}
}
注:统一模板匹配log_*全量日志索引,可以覆盖新索引和老索引,新业务索引也会有默认mapping与分片配置,保证结构一致性,默认的12个分片也可以保证写入顺畅,不至于超过分片限额。
对于具体索引采用个性化模板,每个索引一个模板,模板中只写独特的settings、mappings。
每周任务进行索引mappings、settings的更新,主要针对于以下几个:
mappings:主要针对当前索引的mappings相较于通用模板的mappings新增字段,如有,则更新。
settings:针对分片数、total_shards_per_node进行调整(下方具体阐述)。
2. 索引创建调度任务
主要做以下几件事:
- 分析索引的存储量:分析当前周索引的存储量,并增加一定比例buffer(因为是提前创建),作为索引下周存储量级。
- 规范分片大小:按照30~50GB大小为基准来计算分片数,统一更新到索引对应的模板。
- total_shards_per_node调整:为了避免多分片集中在某个节点上,提前算出每个索引的per_node,保证分片的均衡分布(计算方式:math.ceil(分片数/节点数))。
- 索引提前创建:每周固定时间提前2天低峰创建次周索引(取用最新分片数信息)。
实际例子的模板调整案例:
log_test-2026.21索引(存储量40TB,节点数550):
// ==================== 索引模板更新说明(个性化覆盖) ====================
// order: 99 高优先级,用于覆盖通用模板 log_default 中的同名配置
// total_shards_per_node: 【更新】由通用模板默认值调整为2,适配当前550节点规模下的分片均衡
// number_of_shards: 【更新】按单分片50GB基准重新计算,由原值调整为820
// reqSize: 【新增字段】long类型,用于记录请求体大小
// gid: 【新增字段】keyword类型,ignore_above=256,用于全局追踪标识
PUT _template/log_test_template
{
"order": 99,
"index_patterns": ["log_test-*"],
"settings": {
"index": {
"routing": {
"allocation": {
"total_shards_per_node": "2"
}
},
"refresh_interval": "90s",
"number_of_shards": "820",
"number_of_replicas": "0"
}
},
"mappings": {
"properties": {
"reqSize": { "type": "long" },
"gid": { "ignore_above": 256, "type": "keyword" }
}
},
"aliases": {}
}
注:这个DSL涵盖了新增的字段mappings,更新的分片数(按照50g计算)、均衡total_shards_per_node(820/550取2),每个节点最多有2个分片,也保留了一定冗余,同时避免分片倾斜。
6.2.6 自研离线分片调度体系(替代原生实时均衡,可控负载)
禁用自动均衡后,放弃ES原生实时调度,采用凌晨低峰批量调度方案,自动/人工可控实现集群负载均衡。
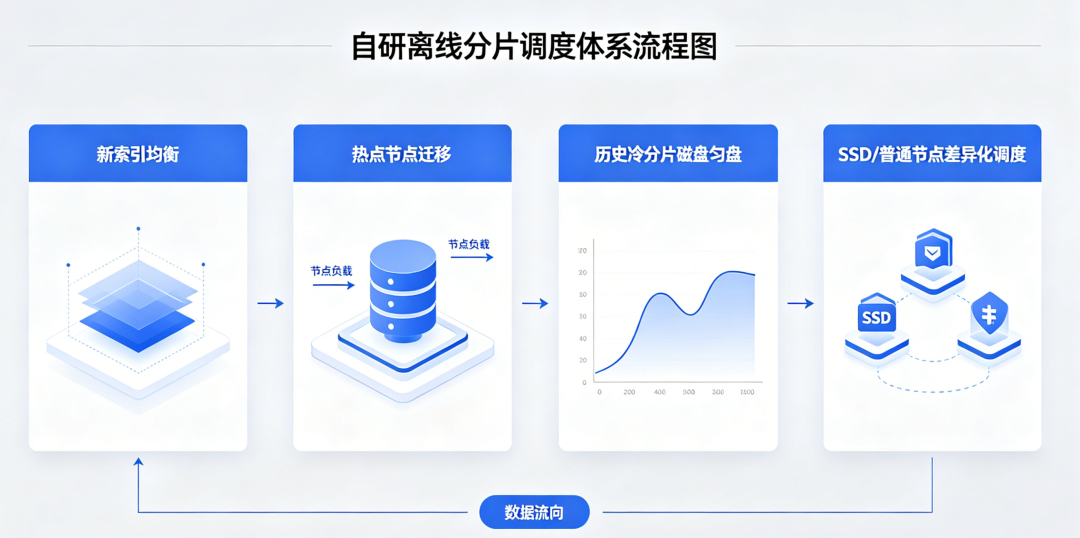
核心实操逻辑:
自研离线分片调度涵盖了索引创建均衡、迁移与磁盘均衡,具体如下:
第一步:新索引(提前生成的)提前均衡分片
主要是分析新创建的总索引的分片数,计算出节点平均分片数,将高负载迁移到低负载。
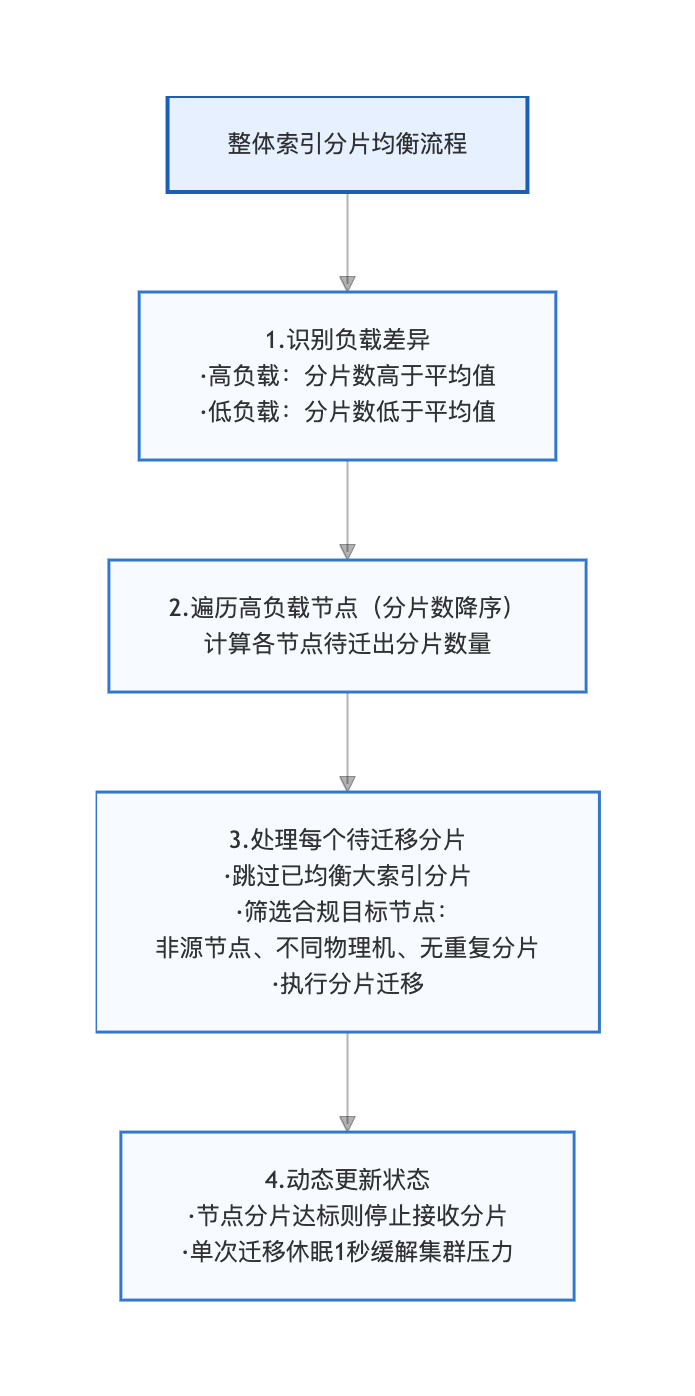
注:其中对于SSD和非SSD节点也做区分,前者分配更多分片,后者分配少量分片。
第二步:索引(当前索引或者历史索引)低峰均衡调度
低峰调度有两种情况:
-
调度load高节点到低load节点
对于当前load较高的节点,将其对应的当前写的分片迁移到load低的节点上。
POST /_cluster/reroute
{
"commands": [
{
"move": {
"index": "target-log-index",
"shard": 0,
"from_node": "高负载节点",
"to_node": "空闲节点"
}
}
]
}
通过定时脚本自动化执行以上逻辑,实现无感知、低压力、零抖动的分片均衡,完全替代原生激进均衡机制。
-
调度高存储占比节点的历史索引到低存储占比节点
尤其是9t、14t等低存储节点在当周写到周三周四会有存储压力,需要提前几天低峰进行历史索引的同步。
将上一周(已经不写的索引)同步到低存储压力节点。历史索引读写量小,低峰同步不影响集群整体性能,可以整体控制磁盘使用量。
落地优化效果
- master负载大幅回落:集群元数据同步频次大幅降低,彻底解决了master CPU高负载、线程池阻塞及集群状态超时问题,master节点长期使用率可控制在10%以内。
- 集群节点变化零抖动:永久禁用自动重平衡后,扩容、滚动重启、节点上下线等运维操作,不再触发大规模分片迁移,节点压力大导致的消费延迟问题得以避免。
- 节点磁盘利用率达到最大化且可控:整合现有不同规格的磁盘节点,利用低峰期批量迁移高存储分片,最大化提升磁盘利用率,同时结合新的水位线参数实现磁盘利用率的精细化管控。
- 故障恢复效率翻倍:集群分片恢复卡顿、超时问题彻底解决,单批次分片恢复耗时缩短60%。
复盘总结
- ES集群运维存在明显的规模分水岭:千级分片以内的中小集群,依赖原生自动均衡、默认参数即可稳定运行;
- 万级以上海量分片超大集群,原生机制、通用特性,反而会成为集群最大隐患,需转为人工标准化管控。
- 通过生产环境持续迭代验证与参数调优,逐步逼近集群最佳状态与性能上限。
七、分片运维高频实操命令
7.1 集群监控命令
# 查看全量分片分布状态
GET /_cat/shards
# 查看未分配分片及异常原因
GET /_cat/shards?v&h=index,shard,prirep,state,unassigned.reason
7.2 手动分片迁移命令
# 1. 手动迁移指定分片
POST /_cluster/reroute
{
"commands": [{
"move": {
"index": "my-index", "shard": 0,
"from_node": "node1", "to_node": "node2"
}
}]
}
# 2. 手动分配副本分片
POST /_cluster/reroute
{
"commands": [{
"allocate_replica": {
"index": "my-index", "shard": 0, "node": "node3"
}
}]
}
八、分片使用运维总结
分片是ES分布式集群的核心基础,所有运维操作的本质都是平衡性能、稳定性与资源成本。
- 前期规划:严格遵守单分片业务10-30GB、日志30-50GB标准,控制总分片数,合理配置副本。
- 日常调优:常态化配置恢复并发、传输限速、磁盘水位线,适配硬件。
- 变更管控:扩容/重启/变更前必须关闭重平衡,完成后逐步开启。
- 常规监控:重点关注主/副本分片数、UNASSIGNED Shard数、节点负载、磁盘使用率。
- 大规模集群:百级节点或万级分片以上的集群必须禁用重平衡,自研分片调度策略。
九、参考文献
- Elastic. Size your shards[EB/OL]
- Elastic. Modules-cluster cluster setting[EB/OL]
- Elastic. Cluster reroute API[EB/OL]
- 微信公众号. ES分片运维实战[EB/OL]
- CSDN博主. Elasticsearch分片分配原理详解[EB/OL]
- Elastic. 分片内部原理[EB/OL]
- Elastic. 索引别名[EB/OL]
- 腾讯云开发者. Elasticsearch分片规划最佳实践[EB/OL]
 发表于 6 天前
|
查看: 35|
回复: 0
发表于 6 天前
|
查看: 35|
回复: 0
