开篇
面试官问你“两数之和”,你写了双重循环,他追一句“能更快吗?”你用哈希表做到 O(n),他点头放过。
但你有没有想过:为什么哈希表就能更快? 为什么有些问题暴力只能 O(n²) 却存在 O(n log n) 的解法?为什么有些 O(n log n) 已经是极限,再怎么努力都不可能更快?
这篇文章不讲具体题目。我们退一步,从更高的视角回答一个根本问题:
算法优劣的本质差异是什么?
理解了这件事,后面每一篇具体的算法文章你都会知道——它在做什么、为什么能做到、以及什么时候该用它。
内功心法
一、算法的本质是搜索
所有算法都在做同一件事:在解空间中找到满足条件的解。
排序问题的解空间是 n 个元素的全排列——共 n! 种可能。一个正确的排序算法,就是从这 n! 种排列中找到唯一有序的那一个。
暴力法逐一检查每种可能。而好算法之所以快,是因为它每一步操作都能排除大量不可能的候选。
比较排序每次比较两个元素,结果只有“大于”或“小于”两种——相当于一个 yes/no 问题。每个 yes/no 最多把剩余可能性砍掉一半。n! 种可能需要砍多少次?
这就是比较排序 O(n log n) 下界的由来。不是某个算法恰好做到这么快,而是信息论决定了你至少需要这么多次比较才能确定答案。
核心命题:优化 = 利用更多信息来缩小搜索空间。
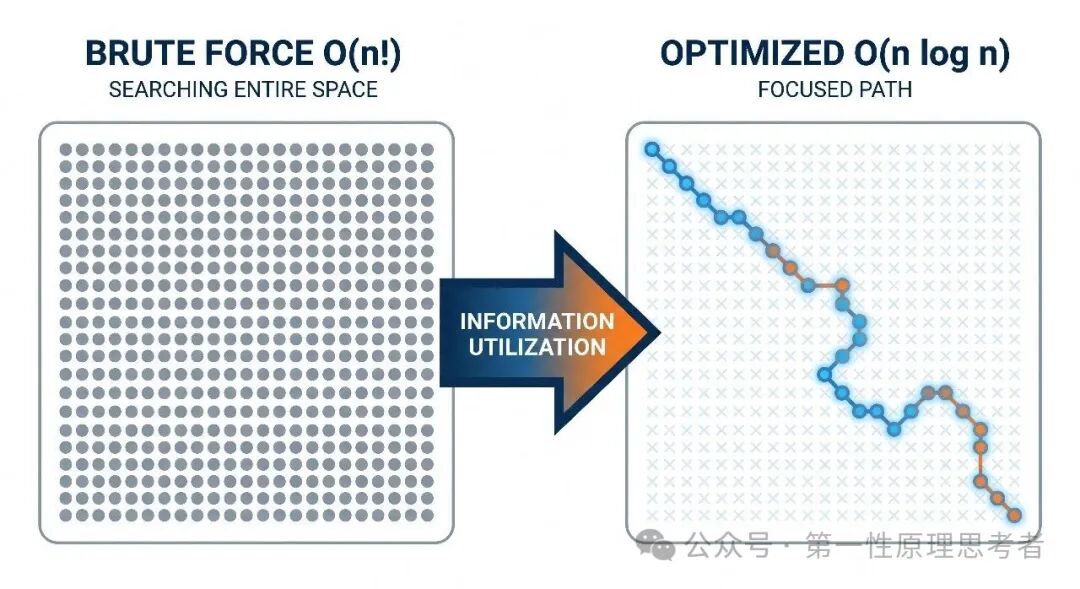
暴力法遍历全部空间(左)vs 好算法利用信息跳过大片区域(右)
暴力法不利用任何信息,所以它遍历全部空间。每一种“更好的算法”,本质上都是发现并利用了问题中的某种结构性信息,从而跳过大片不可能的区域。
二、五大策略:利用不同类型的信息
所有算法策略,归根结底都在回答同一个问题:“我能利用什么信息来缩小搜索空间?”只是它们利用的信息类型不同。
分治——利用“问题的递归结构”
如果一个大问题可以拆成若干互不影响的子问题,分别解决后合并,那搜索空间就从一整块变成了几小块之和。
归并排序把 n 个元素拆成两半分别排序再合并——每层做 O(n) 工作,共 log n 层,总计 O(n log n)。快速排序选一个 pivot 把数组分成“比它小”和“比它大”两部分,每个子问题的搜索空间直接减半。
典型应用:归并排序、快速排序、快速幂、二维矩阵搜索。
贪心——利用“局部最优 = 全局最优”的结构
有些问题存在一个强性质:每一步选当前最好的,最终结果就是全局最好的。这意味着你根本不需要考虑未来的所有可能,只需要看眼前。
贪心之所以快,是因为它把指数级的搜索空间压缩成了线性的“逐步选择”。但它的前提很严格——必须满足“贪心选择性质”和“无后效性”。一旦不满足,贪心就会给出错误答案。
典型应用:区间调度、Huffman 编码、股票买卖(单次/无限次)、分糖果、排序不等式。
动态规划——利用“重叠子问题 + 最优子结构”
如果问题可以拆成子问题,但子问题之间不是独立的(同一个子问题会被反复用到),那就把每个子问题的答案记下来,下次直接查表。
暴力递归可能是指数级的——因为同一个子问题被算了无数遍。动态规划通过“记忆化”把这些重复全部消除,时间复杂度降到“状态数 × 每个状态的转移代价”。
典型应用:背包问题(01/完全/多重/分组)、最长递增子序列(LIS)、最长公共子序列(LCS)、编辑距离、股票买卖 K 次、最长回文串、正则匹配、扔鸡蛋、打家劫舍。
回溯——利用“约束条件来剪枝”
有些问题没有贪心性质,子问题也没有重叠,只能老老实实穷举。但即便如此,也不必把所有可能都走完——一旦发现当前路径违反约束,立即回头。
回溯的本质是“带剪枝的深度优先搜索”。剪枝越狠,实际遍历的空间越小。好的剪枝策略可以把指数级的理论复杂度压缩到可接受的范围。
典型应用:组合/排列生成、N 皇后、矩阵路径搜索、切割问题、机器人计数。
二分搜索——利用“单调性/有序性”
如果解空间是有序的,或者目标函数具有单调性,那每次比较都能排除一半——搜索空间以指数速度收缩。
二分不仅仅用在“有序数组中找元素”。只要你能定义一个判定函数,它在某个分界点左边返回 true、右边返回 false(或反过来),就可以二分。
典型应用:旋转数组最小值、缺失数字、出现次数统计、值等于下标的元素。
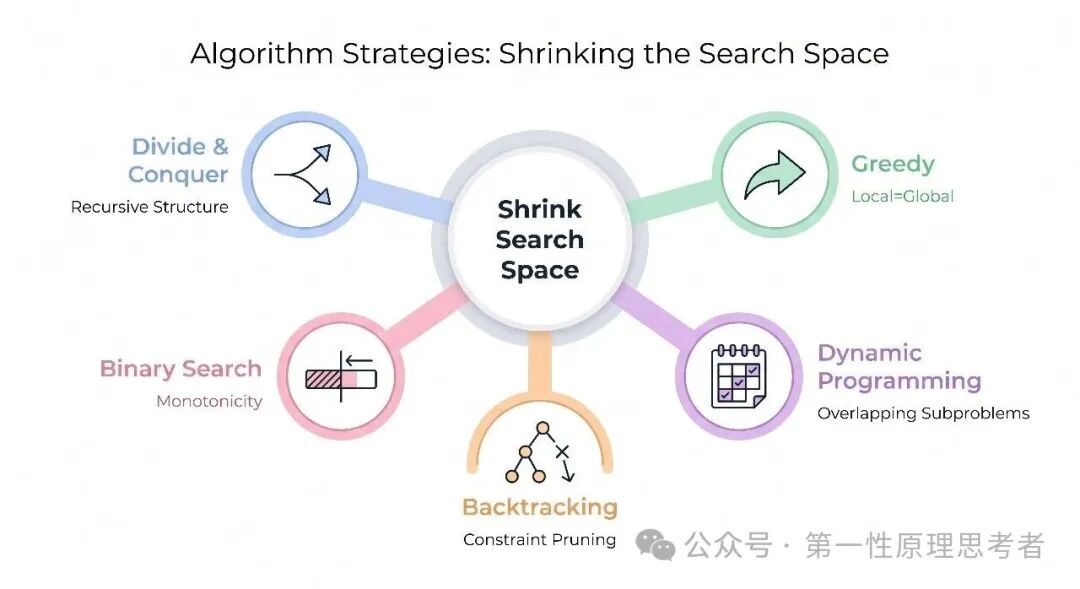
五大策略的统一视角:利用不同类型的信息
三、数据结构:预处理的信息容器
算法策略解决的是“用什么思路搜索”。数据结构解决的是另一个问题:如何提前把信息组织好,让后续查询更快?
每种数据结构都是一个“信息容器”——它预先花一些代价把数据整理成特定形式,换取后续操作的加速。选择数据结构,本质上是在问:“我后续最频繁的操作是什么?有没有一种结构能让这个操作接近 O(1) 或 O(log n)?”
| 数据结构 |
预存的信息 |
加速什么操作 |
| 哈希表 |
键→值的直接映射 |
O(1) 查找、判重(布隆过滤器是概率版本) |
| 堆 |
动态维护的极值 |
O(1) 取最大/最小,O(log n) 插入删除 |
| 单调栈 |
每个元素左/右第一个更大(更小)值 |
O(n) 完成所有元素的“最近更大值”查询 |
| 单调队列 |
滑动窗口内的极值 |
O(1) 获取窗口最值 |
| 前缀和 / 差分 |
区间的累加信息 |
O(1) 区间和查询 / O(1) 区间批量修改 |
| Trie |
字符串的公共前缀 |
O(L) 前缀匹配,多模式串搜索(AC 自动机) |
| 并查集 |
元素间的连通关系 |
近 O(1) 的合并与查询 |
| 跳表 |
多级索引的有序结构 |
O(log n) 有序查找(Redis 的选择) |
| B+ 树 / BST / Splay |
有序平衡结构 |
O(log n) 范围查询、第 K 大、中序后继 |
| Merkle 树 |
层层哈希摘要 |
O(log n) 数据完整性校验 |
| 链表 |
节点间的指针连接 |
O(1) 插入删除(反转、LRU、快慢指针) |
四、高级技巧:信息的巧妙编码
除了五大策略和数据结构选择,还有一类优化手段:用巧妙的编码方式把信息压缩到更紧凑的表示中,从而减少搜索代价。
双指针 ——用两个指针编码当前搜索状态。对于有序数组中的“两数之和”,左指针向右移动意味着“当前和太小”,右指针向左意味着“当前和太大”。每次移动都利用了有序性排除一整行/列的候选,把 O(n²) 降到 O(n)。盛水容器、接雨水、荷兰国旗分区都是同一思想的变体。
滑动窗口 ——维护一个满足条件的连续子段,右端扩张、左端收缩,指针只进不退。本质是利用了“子段的单调性”:如果当前窗口已经不满足条件,继续扩张右端不会让它更好;如果已经满足,收缩左端去寻找更优解。最长不重复子串、最短覆盖子串都靠这个。
位运算 ——把信息压缩到二进制的每一位上,一条指令并行处理 32 或 64 个 bool 值。n & (n-1) 消除最低位的 1,lowbit(n) = n & (-n) 取出最低位,XOR 的“相同为 0 不同为 1”能找出唯一出现一次的数。状态压缩 DP 用一个整数表示一个集合的选取状态,把集合枚举变成位操作。
扫描线 ——想象一条竖直线从左向右扫过平面,遇到“事件”(线段端点、矩形边界)时更新状态。它把二维问题降维成一维的事件序列处理。
摩尔投票 ——候选-抵消机制。用 O(1) 空间、O(n) 时间找到出现超过半数的元素。本质是利用了“多数元素数量 > 所有其他元素之和”这个信息。
字符串匹配(KMP / BM / Rabin-Karp) ——暴力匹配在失败时把主串指针回退,浪费了“已经匹配成功的前缀”这个信息。KMP 利用模式串自身的“部分匹配表”,失败时只回退模式串指针,主串指针永远不回头。BM 更激进,利用“坏字符”和“好后缀”两条规则一次跳过更多位置。
排序的利用 ——很多问题在排序后性质会变得明显。归并排序过程中可以顺带求逆序数(因为合并时左右两半的相对顺序就是逆序信息)。桶排序利用值域有限这个信息绕过比较模型。
概率与随机化 ——随机性打破最坏情况。随机快排的期望复杂度是 O(n log n),不存在能让它退化到 O(n²) 的“恶意输入”。HyperLogLog 用概率换空间,12KB 内存估算上亿基数。
数学公式 ——有些问题存在封闭解或递推公式,直接计算代替搜索。约瑟夫环 f(n,k) = (f(n-1,k) + k) % n 一行代码解决;第 N 位数字通过数位规律直接定位。
五、如何更轻松地拿下算法题
拿下算法题靠两条腿走路:想到更好的解法 + 肌肉记忆秒写代码。缺一不可。
5.1 想到更好的解法
面对一道新题,写出暴力解之后,问自己三个问题:
1. 我在重复计算什么?
如果暴力解中有大量重复的子计算,那答案往往是 DP 或预处理。斐波那契的递归树里 f(3) 被算了无数遍——加个备忘录就变成 O(n)。区间和被反复求——预计算前缀和就变成 O(1) 查询。
2. 我在遍历什么不可能的区域?
如果暴力解的内层循环中,很多迭代其实是“不可能产生更优解”的,那就找一个条件把它们跳过。有序性→二分;单调性→双指针/滑动窗口不回退;约束条件→回溯剪枝。
3. 有没有结构可以帮我预存信息?
如果每次迭代都需要查询某种信息(最大值?是否存在?前一个更大的?),考虑用一个数据结构提前维护好这个信息。需要 O(1) 判存→哈希表;需要动态最值→堆;需要最近更大→单调栈。
这三个问题不是万能的,但它们覆盖了面试中 90% 以上的优化思路。
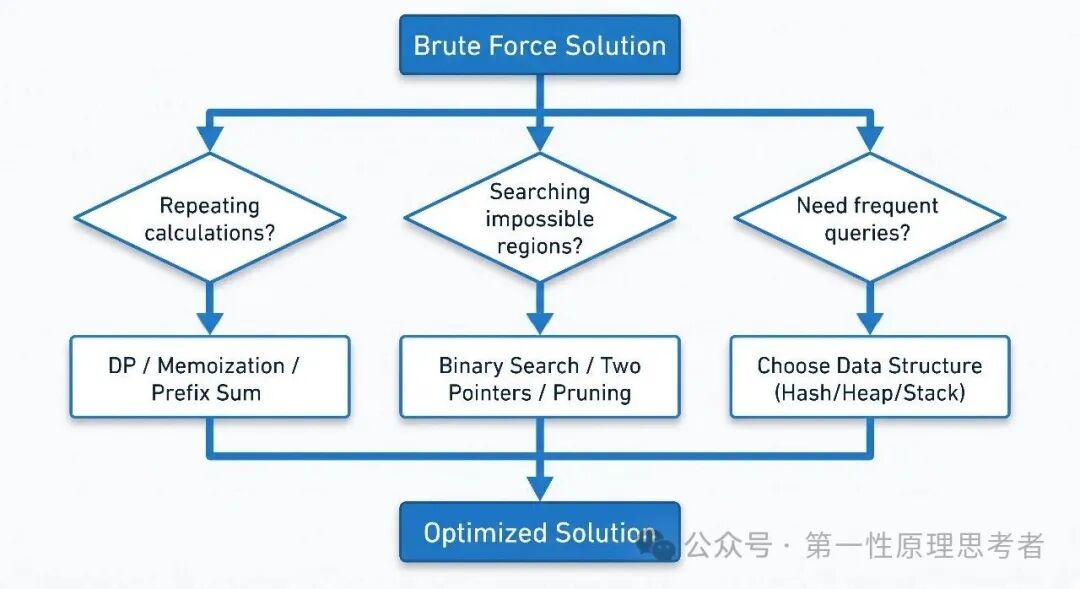
写出暴力解后,用这三个问题找优化方向
除了三个自问,还有两张“作弊表”帮你快速锁定方向:
Pattern 速查清单 ——遇到新题时,对照这张清单做匹配:
算法策略类
| Pattern |
识别信号 |
| 二分搜索 |
有序 / 单调判定函数 / 答案有范围 |
| 分治 |
子问题独立、合并代价可控 |
| 贪心 |
局部最优=全局最优(排序不等式/区间/Huffman) |
| 动态规划 |
重叠子问题 + 最优子结构(背包/LIS/LCS/区间DP/状态机DP/树形DP) |
| 回溯 |
求所有方案 / 组合排列 / 棋盘类 |
| DFS / BFS |
图/树遍历、连通性、最短路 |
数据结构类
| Pattern |
识别信号 |
| 哈希表 |
O(1) 判存 / 计数 / 去重 |
| 堆 |
动态 Top-K / 第 K 大 / 数据流 |
| 单调栈 |
“下一个更大/更小元素” |
| 单调队列 |
“滑动窗口内的最值” |
| 前缀和 / 差分 |
频繁区间和查询 / 频繁区间修改 |
| 并查集 |
动态连通性 / 集合合并 |
| Trie |
前缀匹配 / 多模式串 |
| 二叉树 / BST |
递归结构 / 有序查找 / 第K大 |
| 链表 |
原地操作 / 快慢指针 / 反转 |
编码技巧类
| Pattern |
识别信号 |
| 双指针 |
有序数组 / 对撞方向 / 奇偶分区 |
| 滑动窗口 |
连续子段 + 满足/不满足条件 |
| 位运算 |
集合状态 / 唯一出现 / 并行判断 |
| 扫描线 |
区间/矩形覆盖 / 事件排序 |
| 字符串匹配 |
模式串搜索(KMP/BM/Rabin-Karp/AC自动机) |
| 排序 + 贪心/二分 |
排序后性质变明显 / 归并求逆序 |
| 数学公式 |
规律递推 / 封闭解(约瑟夫/数位/丑数) |
| 概率随机化 |
打破最坏情况 / 近似计数(HyperLogLog) |
| 摩尔投票 |
找出现超过半数/三分之一的元素 |
从 n 的范围倒推算法选择 ——这张表最初是 ACM/OI 竞赛选手的“作弊表”,比赛中看到数据范围就能秒判该用什么复杂度的算法。面试同样适用:面试官给你一个 10⁵ 量级的输入,如果你写了 O(n²),他一定会追问“能更快吗”。
一般在线评测系统 1 秒能执行约 10⁸ 次简单操作。根据 n 的范围,你能接受的复杂度上限是:
| n 的范围 |
可接受的时间复杂度 |
通常对应的策略 |
| n ≤ 20 |
O(2ⁿ) 或 O(n!) |
回溯穷举、状态压缩 DP |
| n ≤ 100 |
O(n³) |
区间 DP、Floyd 最短路 |
| n ≤ 5,000 |
O(n²) |
朴素 DP、双重循环 |
| n ≤ 10⁵ |
O(n log n) |
排序 + 二分、分治、堆 |
| n ≤ 10⁶ |
O(n) |
双指针、前缀和、单调栈/队列、线性 DP |
| n ≤ 10⁹ |
O(log n) 或 O(√n) |
二分答案、数学公式 |
5.2 模板题的肌肉记忆
光“想到”还不够。面试是限时赛,你需要对每种 pattern 的模板题烂熟于心——看到题目 3 秒内识别类型,30 秒内写出骨架代码。
这就像练武:招式(pattern)要理解原理,但出招(写代码)必须靠肌肉记忆。
每种 pattern 都有 1~2 道“祖师爷题”——后续每篇文章都会标注哪道是模板题,建议反复写到闭眼能写。这里先给出方法论:
- 先理解,再背 ——先搞懂这个 pattern 利用了什么信息、为什么能加速,然后再去记模板代码。顺序反了就是死记硬背,遇到变体就不会了。
- 每个 pattern 只精练 1 道模板题 ——贪多嚼不烂。二分就练“旋转数组找最小”,滑动窗口就练“最长不重复子串”,回溯就练“全排列”。
- 间隔重复 ——今天写完,明天再写一遍,三天后再写一遍。三遍之后就是肌肉记忆了。
- 变体 = 模板 + 微调 ——面试中的题几乎都是模板题的变体。能识别出“这是哪道模板题的变形”,就等于解了 80%。
后续每篇文章会明确标注:本篇模板题(必须达到肌肉记忆级别)和 变体题(在模板基础上微调)。
六、下界、上界与普通人的定位
比较排序的 O(n log n) 是少数“理论下界 = 已知最优算法”的完美案例。但大多数问题没这么幸运——理论下界和已知最优算法之间往往存在一道 gap。
矩阵乘法的理论下界是 Ω(n²)(你至少得读完所有输入),但目前最好的算法是 O(n^{2.37}),没人知道能不能做到 O(n²)。整数排序的下界是 Ω(n),而最好的确定性算法是 O(n√(log log n))——离下界只差一个几乎看不见的因子,但几十年来没人消除它。
缩小这道 gap 需要的是:发明全新的组合结构、改变计算模型、引入随机性或近似容忍。这是顶级计算机科学家做的事情。
这不是面试考你的东西。
面试考的是:给定一个已知有高效解法的问题,你能不能——
- 识别它的结构性质(有序?重叠子问题?局部最优=全局最优?)
- 匹配到对应的 pattern(二分?DP?贪心?)
- 正确地实现出来
换句话说,你不需要发明新算法,你需要的是记住有限的几种 pattern,识别问题属于哪种,然后套用。
这正是本系列后续文章要做的事。
结尾
这篇文章没有一道具体的题目,但它是后面所有文章的“操作系统”。
记住三件事:
- 算法优化的本质是信息利用 ——每种策略利用不同类型的信息来缩小搜索空间。
- 数据结构是预处理的信息容器 ——选结构就是选“我最常做的查询是什么”。
- 面试不考你发明算法,考你识别 pattern ——记住有限的几种,匹配问题,正确实现。
从下一篇开始,我们逐个击破每种数据结构和算法策略。第一站:1.4.1 数组与矩阵 ——看似最简单的结构,却藏着原地操作、螺旋遍历、前缀和等大量面试高频考点。
 发表于 2026-6-10 20:04:05
|
查看: 104|
回复: 0
发表于 2026-6-10 20:04:05
|
查看: 104|
回复: 0
