在将几个 Spark 批处理管道从本地基础设施迁移到 Azure Kubernetes Service (AKS) 后不久,我们发现其中一个较大的作业反复出现执行器内存不足 (OOM) 故障。这些故障都发生在 shuffle 阶段,起初看起来像是典型的 Spark 内存调优问题。我们试过增加执行器内存、调整执行器数量,也多次重启作业,但都没什么效果。更让人困惑的是,这套管道在迁移前已经稳定运行了好几年。
最终根因完全不是 Spark 配置问题,而是迁移过程中引入的两项基础设施级设置发生了意想不到的交互:spark.kubernetes.local.dirs.tmpfs=true(基于内存的本地临时目录),以及一条严格的 podAffinity 规则,要求所有执行器都必须跑在同一节点上。这两项设置叠加,导致 shuffle 溢写吃掉了节点内存而不是磁盘空间,进而反复触发 OOM 终止。
本文记录我们排查的全过程、根因分析,以及最终解决该问题的配置变更。
系统环境与迁移背景
管道环境
我们的数据平台负责管理生产环境的批处理管道,为美国某大型金融机构提供交易数据的大规模聚合与转换。工作负载每天处理约 3 GB 的定宽平面文件,该文件包含多种交错的记录布局,需要多次解析和合并操作,因此 shuffle 强度远高于 3 GB 输入数据本身所暗示的水平。在本地环境中,这些管道已经稳定运行了三年多,从未出现过类似的内存不足模式。
AKS 集群配置
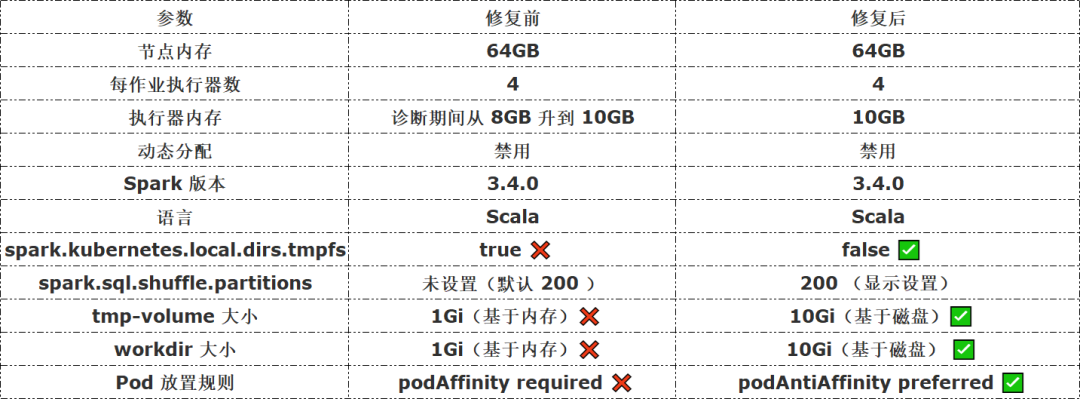
事件发生时的环境参数如下:
迁移背景
迁移到 AKS 是公司云现代化计划的一部分,这些工作负载被视为“平移”候选对象:只要匹配 CPU 和内存配置,就应该能在不修改应用程序的情况下保持原有行为。可事实证明这个假设是错误的——迁移过程中引入的两项基础设施设置,改变了 Kubernetes 处理执行器部署和本地存储的方式,而这两项设置在评审时都没被标记出来。
事件时间线
迁移后第一周
起初一切看起来挺平稳,较小的任务都能成功完成。第一次 OOM 故障出现在定宽多布局批处理任务中,具体是在需要对大量数据进行 shuffle 的合并阶段。该任务会使用不同的布局解析器多次读取同一个 3 GB 的文件,然后再合并结果。
第二到第三天
OOM 故障最初被看作偏发问题。人工重启后任务短暂恢复,于是这事被登记为间歇性故障,归因于集群层面可能存在资源争用。
第三到第四天:初步假设与堆配置
初步诊断集中在执行器堆内存配置上。我们把 spark.executor.memory 从 8 GB 上调到 10 GB。但在高负载下故障依旧出现,这就排除了堆内存配置不足作为根因的可能。
第四天:第二种假设与执行器数量
为了进一步分散工作负载,我们增加了执行器数量,但也没见明显效果;只要遇到大量 shuffle,系统仍然会瘫。
第四至第五天:Kubernetes Pod 放置分析
我们通过 AKS Pod 日志和 Datadog 检查了 Kubernetes Pod 的放置情况。Datadog 的 Kubernetes 节点概览仪表板显示,shuffle 阶段节点内存使用率会飙到 90% 以上。Kubernetes 事件持续报告:
Reason: OOMKilled
Exit Code: 137
同时,我们在 AKS Pod 日志里还看到一种明显的执行器更替模式:这个作业并没有用最初的四个执行器跑完,而是不断因为 OOM 被终止、替换,最终在第 50 个执行器时才宣告失败。在每次终止事件前的 shuffle 阶段,Datadog 显示的节点级内存使用量会在几秒内从约 42 GB 飙升到超过 58 GB。这清楚地表明,问题并不在堆大小配置上,而是节点级内存耗尽导致内核 OOM killer 杀掉了执行器进程。
第五天:根因确认
我们在审查 Spark 和 Kubernetes 配置时发现,spark.kubernetes.local.dirs.tmpfs 在迁移过程中被设成了 true,这意味着所有本地临时目录——包括 shuffle 溢出路径——都由内存而非磁盘提供支撑。更糟的是,临时卷(tmp-volume 和 workdir)的大小限制只有 1 GiB,对这套作业产生的 shuffle 数据来说根本不够。在本地环境中,原本是用本地磁盘空间来承接 shuffle 溢出数据,而且卷大小配置得比较合理,但在迁移审查时,这两处差异都没被记录下来。
第五天:方案部署
我们将 podAffinity 硬性规则替换为 podAntiAffinity,并使用 preferredDuringSchedulingIgnoredDuringExecution;同时把 spark.kubernetes.local.dirs.tmpfs 设为 false,并将 tmp-volume 和 workdir 的大小限制从 1 GiB 提升到 10 GiB。OOM 故障立刻停止了。这套修复方案至今已稳定运行六个月,没有再出现过任何故障。
根因分析
调查过程中,我们发现导致故障的三个因素。只有在高 shuffle 负载下,第二和第三个因素发生交互时,这些故障才会暴露出来。
因素 1:大数据量任务中 shuffle 引发的内存压力
在数据密集型任务里,大规模的 shuffle 阶段会让执行器内存使用急剧上升。这在 Spark 中是正常行为:shuffle 操作需要先将中间数据保存在内存里,再溢写到磁盘。如果资源配置恰当,这种数据保留通常是可控的。但当它与下文所述的其他因素叠加时,灾难就开始了。
虽然源文件只有大约 3 GB,但多布局定宽格式需要的多次解析迭代、按每种布局生成的中间 DataFrame、合并它们的 union 操作,以及下游的 shuffle 阶段,会使内存压力远远超过原始输入大小。对一个只有 4 个执行器的任务来说,3 GB 输入看似不重,但多轮处理会把实际工作集放大到远超输入大小的程度。
因素 2:亲和性配置错误导致执行器被迫挤在一起
实际上,执行器放置规则已经变成了一条硬性的共置约束。配置中存在一条使用 requiredDuringSchedulingIgnoredDuringExecution 的 podAffinity 规则。它并没有把执行器 Pod 分散到不同节点上,反而强制它们都待在同一个节点上。这并不是默认的装箱行为,Kubernetes 只是在忠实地执行一条显式配置的硬性放置规则。
Kubernetes 调度机制和这条配置错误的放置规则叠加,导致四个执行器 Pod 全部被塞进同一个 64 GB 的节点。这让 shuffle 期间的内存和 I/O 压力都集中在一台机器上。再叠加基于 tmpfs 的溢出机制,节点内存便立即告罄,内核 OOM killer 开始清理执行器。
在本地环境中,集群调度器原本配置了明确的放置约束,可以自然地将执行器分散到不同节点,但迁移时这个配置没有被保留下来。我们通过使用 preferredDuringSchedulingIgnoredDuringExecution 将共置行为替换为 podAntiAffinity,解决了这个问题。
因素 3:基于内存的本地临时目录
这是影响最大的配置错误。迁移后的 Spark 配置中包含:
spark.kubernetes.local.dirs.tmpfs: true
当这个属性设为 true 时,Spark 会要求 Kubernetes 使用基于内存的 emptyDir 卷(即 tmpfs)来支撑所有本地临时目录,包括 shuffle 溢出路径。在发生大规模 shuffle 时,Spark 不再将数据溢写到磁盘,而是全部写入节点内存。Spark 的 Kubernetes 配置文档中确实记录了这种行为,但它与卷大小限制、执行器共置之间的相互作用,在运维指南中却极少被提及。
基于 tmpfs 的存储配上极小的卷大小限制,让情况雪上加霜。下面是当时的原始配置:
# 修复前(有问题的配置)
volumes:
- emptyDir:
sizeLimit: 1Gi
name: tmp-volume # 基于内存,上限 1Gi
- emptyDir:
sizeLimit: 1Gi
name: workdir # 基于内存,上限 1Gi
当 tmpfs=true 时,这些卷消耗的是节点内存而不是磁盘空间。每个卷只有 1 GiB,对于需要多次读取、多次合并的 3 GB 定宽文件作业而言,这点空间对 shuffle 溢出来说几乎是个玩笑。一旦 shuffle 溢出超过这些基于内存的本地临时卷的有效容量,内存压力就会迅速攀升,内核 OOM killer 便开始终止执行器进程。而在本地部署中,tmpfs=false,并使用基于磁盘的本地存储来处理 shuffle 溢出,这个差异在迁移审查中完全被忽略了。
复利效应
单独看,每个因素都是可控的:
- 仅是 shuffle 压力:可以通过溢写到磁盘来处理;
- 仅是共置:虽然会增大压力,但在有磁盘溢出的情况下并不会造成灾难;
- 仅是 tmpfs:虽然存在问题,但分布式执行器限制了单节点的影响。
然而,当所有执行器都被强制分配到同一个节点上,而且它们的 shuffle 溢出又吃的是节点内存而不是磁盘空间时,内存几乎瞬间被负载耗尽,OOM 终止操作便反复上演。
为何迁移前的测试没能发现这个问题
迁移前的验证测试只跑了规模较小或 shuffle 强度较低的作业。只有在生产级别的负载模式下——即对全尺寸输入文件执行多布局迭代和合并阶段时——共置和基于内存溢出这两者的综合影响才会暴露出来。规模较小的测试都顺利完成了,于是给人一种修复方案可以稳定运行的假象。这个故事告诉我们:迁移前验证必须在预生产环境中模拟生产级负载量,仅靠有代表性的采样,无法揭示那些只在大规模运行时才会凸显的复合型基础设施缺陷。
修复
下图对比了执行器放置和存储的“修复前”与“修复后”状态:
修复前
┌──────────────────────────────────────────────────────┐
│ Node A (64 GB RAM) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │Executor 1│ │Executor 2│ │Executor 3│ │Executor 4│ │
│ │ shuffle │ │ shuffle │ │ shuffle │ │ shuffle │ │
│ │spill→RAM │ │spill→RAM │ │spill→RAM │ │spill→RAM │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ podAffinity: required (all on same node) │
│ spark.kubernetes.local.dirs.tmpfs: true │
│ tmp-volume: 1Gi (RAM-backed) │
└──────────────────────────────────────────────────────┘
执行器内存 + tmpfs 溢出 -> 节点内存耗尽
-> OOMKilled (Exit 137) → 执行器频繁更替 -> 作业失败
修复后
┌──────────────────┐ ┌──────────────────┐
│ Node A │ │ Node B │
│ ┌──────────┐ │ │ ┌──────────┐ │
│ │Executor 1│ │ │ │Executor 3│ │
│ │spill→disk│ │ │ │spill→disk│ │
│ └──────────┘ │ │ └──────────┘ │
│ ┌──────────┐ │ │ ┌──────────┐ │
│ │Executor 2│ │ │ │Executor 4│ │
│ │spill→disk│ │ │ │spill→disk│ │
│ └──────────┘ │ │ └──────────┘ │
└──────────────────┘ └──────────────────┘
podAntiAffinity: preferred (分散到多个节点上)
spark.kubernetes.local.dirs.tmpfs: false
tmp-volume: 10Gi (基于磁盘)
内存压力分散 -> 作业由 4 个执行器在 1 个小时内完成
修复 1:使用 Pod 反亲和性分散执行器
我们引入了 preferredDuringSchedulingIgnoredDuringExecution 反亲和性策略,将执行器分散到不同节点上:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: spark-role
operator: In
values:
- executor
topologyKey: kubernetes.io/hostname
我们特意选用 preferred 而非 required。这样,当集群面临容量压力时,调度器仍然允许一定程度的共置,避免因无法调度 Pod 而导致任务失败;而在正常情况下,它会尽量把执行器分散到不同节点。
修复 2:关闭 tmpfs 并提升卷大小限制
与此同时,我们还做了两项相关调整:禁用 tmpfs,并提高卷大小限制。
禁用 tmpfs:
# 修复前:基于内存的本地临时目录
spark.kubernetes.local.dirs.tmpfs: true
# 修复后:基于磁盘的本地临时目录
spark.kubernetes.local.dirs.tmpfs: false
提高卷大小限制:
# 修复前:1Gi 基于内存的卷
volumes:
- emptyDir:
sizeLimit: 1Gi
name: tmp-volume
- emptyDir:
sizeLimit: 1Gi
name: workdir
# 修复后:10Gi 基于磁盘的卷
volumes:
- emptyDir:
sizeLimit: 10Gi
name: tmp-volume
- emptyDir:
sizeLimit: 10Gi
name: workdir
把 spark.kubernetes.local.dirs.tmpfs 设为 false,相当于告诉 Spark 为所有本地临时目录(包括 shuffle 溢出路径)使用基于磁盘的 emptyDir 卷。Kubernetes 会把数据写入由节点文件系统支撑的临时存储,而不是内存。将卷大小限制从 1 GiB 提升到 10 GiB 也同样关键:原有的 1 GiB 限制远远不够容纳多轮、多合并作业的 shuffle 溢出数据,即便该卷是磁盘卷也不行。这两项更改必须同时进行。
此外,我们还验证了将 spark.sql.shuffle.partitions 设为 200 的效果。这个值可以为我们的工作负载合理平衡并行度,又不会生成过多的小 shuffle 文件。修复后,我们保留了 10 GB 的执行器内存配置,但存储和调度方面的调整才是真正起作用的改动——仅靠增加执行器内存,根本解决不了问题。
修复 3:验证节点内存可用空间
虽然节点配备了 64 GB 内存,但操作系统和 kubelet 的开销会挤占一部分供工作负载使用的内存。我们验证后确认,扣除执行器内存请求和开销后,余量仍然足够。现在,依照首选反亲和性规则,四个执行器分散到各个节点上,正常调度下每个节点最多承载一到两个执行器。即使在多布局合并作业 shuffle 最密集的阶段,峰值内存使用量也始终远低于安全阈值。
在 Standard_D16a_v4 节点上执行 kubectl describe node 命令,可以确认扣除 kubelet 和 OS 开销后的实际可用内存:
# kubectl describe node (Standard_D16a_v4)
Capacity:
memory: 65937008Ki (~62.8 GB)
ephemeral-storage: 129886128Ki (~124 GB)
Allocatable:
memory: 63530608Ki (~60.6 GB)
ephemeral-storage: 119703055367 (~111 GB)
# kubelet + OS 开销: ~2.3 GB
# 4 executors x 10g = 40 GB 执行器内存
# 剩余空间: ~20.6 GB
当然,把节点升级到更高规格的 SKU 可以带来更大的性能余量,但那也会增加基础设施成本。本文所述的配置调整方案,恰好能在保持现有节点规模、不产生额外开支的前提下解决问题。
结果
修复前

修复后

执行器频繁替换模式是最有说服力的指标。修复前,集群每次运行该作业都会启动最多 50 个执行器,陷在“OOM-Kill-替换”的无效循环里——既消耗大量集群资源,又无法让作业取得进展。修复后,同一任务仅凭四个执行器就能在一小时内稳定完成,无需任何额外基础设施。
云原生 Spark 的广泛影响
这次事件反映了 Spark 工作负载上云过程中反复出现的三种典型模式。
云存储的语义并非基础设施无关
spark.kubernetes.local.dirs.tmpfs=true 这个配置错误带有很强的隐蔽性。它确实有它的合理之处:对于能轻松放进内存的小型工作集,基于内存的临时目录能够带来性能提升。问题在于,我们把它用到了包含大量中间数据的作业的 shuffle 溢出路径上,并且将临时卷大小限制到只有 1 GiB——这对实际 shuffle 负载来说简直杯水车薪。
云原生存储抽象(如 emptyDir、PVC、实例存储)与本地物理磁盘在性能和容量上存在差异。迁移 Spark 工作负载的团队,一定要在投产前明确审查 spark.kubernetes.local.dirs.tmpfs 配置,根据预期的 shuffle 数据量验证临时卷的大小限制,并确认其在高负载下的运行行为。
Kubernetes 调度器不了解 Spark 的内部行为
Kubernetes 针对通用工作负载做了优化,但它对 Spark 的 shuffle 和执行器内存行为一无所知。我们的案例中,问题由于一条严格的 podAffinity 规则被进一步放大——该规则强制执行器共置在同一节点上,这并不是调度器的默认行为,而是一个显式配置下来的错误约束。在任何 Spark-on-Kubernetes 部署中,执行器的调度策略都应被当作一项明确的设计选择,而不能当成默认项,或者从无关的工作负载模式中直接照搬。
配置一致性检查清单常常被忽视
这次事件中的两处配置错误,并非有意为之,更多是疏忽导致——原本在本地环境中存在的配置没有完整迁移过来。为了避免重蹈覆辙,我们总结了一份具体的检查清单。
Spark-on-Kubernetes OOM 预防检查清单
本检查清单源自本文所分析的、导致 OOM 故障的 Spark-on-Kubernetes 配置缺陷。当你在诊断或预防环境中的类似故障时,可以从这里入手。
调度
- 为执行器 Pod 配置了 Pod 反亲和性
- 有意识地选择了亲和性模式(首选而非强制)
- 已按预期的执行器分布验证了节点池的规模
内存
- 节点内存计算中已考虑 OS 和 kubelet 开销
- 执行器的内存请求值和限制值,给每个节点留出安全余量
- 已在频繁 shuffle 的负载下验证了峰值内存使用
存储
- 显式将
spark.kubernetes.local.dirs.tmpfs 设为 false(基于磁盘的临时目录)
- 为峰值 shuffle 溢出预留了足够的本地卷空间
- 已通过大规模数据集验证了 shuffle 溢出行为
- 确认
spark.local.dir 指向的是基于磁盘的卷
配置一致性
- 记录了本地调度器的约束条件,并在云端进行了复现
- 明确比较了不同环境下的存储卷配置
- 针对云拓扑验证了网络和 I/O 配置
监控
- 已配置执行器 OOM 终止事件的告警
- 已设置节点内存使用率阈值
- 已启用作业重试率监控
- 按作业跟踪读写卷的随机访问情况
小结
这次经历再次提醒我们:云迁移不仅仅是把工作负载挪一个地方,它还会改变这些工作负载所依赖的基础设施“协议”。本文记录的故障,并非应用程序漏洞、Spark 版本变更或简单堆内存不足所致,而是源于两个在迁移过程中悄然改变了运行时行为的基础设施设置——而且它们只会在生产级负载下才会爆发出破坏力。
此后半年,该集群一直稳定运行。希望避免重蹈覆辙的团队,可以从上面的检查清单入手。在金融服务领域,日常批处理管道要为下游提供数据,过时数据会触发用户报告事件,这类故障模式带来的后果远不止工程层面的不便。虽然本文记录的存储和调度配置错误只是针对这个 Spark-on-Kubernetes 部署,但其背后隐含的“隐性配置漂移——仅在生产级负载下才会显现”这一动态模式,是任何云迁移过程中都值得警惕的典型现象。
本文由云栈社区编辑整理。
原文链接:https://www.infoq.com/articles/spark-oom-kubernetes-misconfigurations/
 发表于 2026-6-16 23:42:49
|
查看: 144|
回复: 0
发表于 2026-6-16 23:42:49
|
查看: 144|
回复: 0
