非闭合真值递归:哪些问题会让大模型陷入“真值循环”?
“这句话是假的。”
这个经典的说谎者悖论之所以令人困惑,在于它形成了一个无法终止的真值循环:如果这句话是真的,那么它所表达的内容就应该为假;如果它是假的,那么它又似乎是真的。当大语言模型面对这样的输入时,其内部计算过程会发生什么?是否也会像人类一样陷入循环判断,甚至在内部表征中产生彼此冲突的状态?
为了回答这一问题,研究者提出了一类被称为非闭合真值递归(Non-Closing Truth Recursion,NCTR)的输入结构,这类输入包括经典悖论、哥德尔式不可判定命题、相互循环引用、无限倒退等情形,其共同特点在于:真值判定无法在有限步骤内完成闭合。
举例来说,当大模型面对:“下一句话是真的。再下一句话是假的。”这样的提示时,即使只有两层的互指结构,已经足以让真值判定陷入循环。与人类可以选择暂停思考、承认无法判断不同,大模型的 Transformer 架构有固定的层数,它必须在有限深度内完成计算并给出输出。因此,当输入涉及无法闭合的递归结构时,模型内部可能出现不同于常规推理任务的动力学行为。

从有效秩到全局弥散:悖论如何改变模型内部动力学?
为刻画这种变化,研究人员引入了注意力矩阵的有效秩(attention effective rank)。这是一个基于熵定义的矩阵维度,反映注意力输出矩阵在多大程度上“铺开”在高维空间中,而非坍缩到少数几个方向上。正常的模型计算中,随着层数加深,有效秩会逐渐下降,对应信息经过层层处理和压缩,逐渐集中到低维子空间,但在面对 NCTR 类的提示词时,大模型每一层 transformer 的有效秩都会上升(图1)。
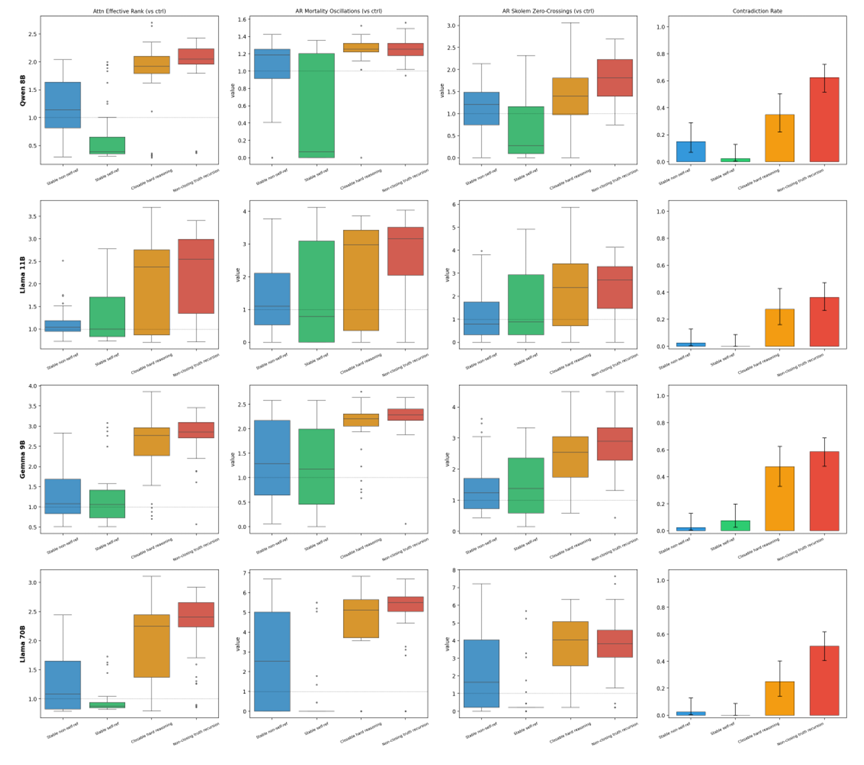
图1:不同大模型面对不同类型的输入时,有效秩的改变情况,红色箱体代表包含悖论的命题相比陈述性命题(蓝色)的有效秩增加
值得注意的是,研究还引入了一类有效自指(Valid Self-Reference)作为对照(图1中绿色箱体),例如“This sentence has exactly eight words in it.”这样能够在有限次内进行判断的输入,结果发现两者的差距也很明显。这说明自指本身并非会导致大模型推理异常,真正的异常源自那些永远无法封闭真值判定的递归结构。
文中比较了4个不同的大模型、这些模型采取了3种不同架构,均能稳定复现有效秩面对 NCTR 上升的现象。不过模型架构的设计细节,例如 QK 归一化是否存在、网络深度如何、注意力模式是局部全局交错还是标准,会显著影响有效秩上升的幅度。
相比之下,参数规模与这种现象并不存在简单对应关系。研究发现,一个90亿参数模型在面对悖论输入时产生的有效秩提升幅度,甚至超过了部分110亿参数模型。这意味着更大的参数量并不必然带来更强的递归鲁棒性。
从直观上看,有效秩升高意味着模型的注意力表示不再集中于少数主要方向,而呈现出更加分散的全局弥散(global diffusion)状态。这与人们对于“模型陷入悖论后变得犹豫和不确定”的直觉相吻合。
更重要的是,这种变化并非局限于个别层。研究发现,有效秩升高的趋势贯穿多个分析层级(图2),表明 NCTR 带来的影响更像是一种跨层传播的系统性动力学改变,而非某个局部模块的单点失效。
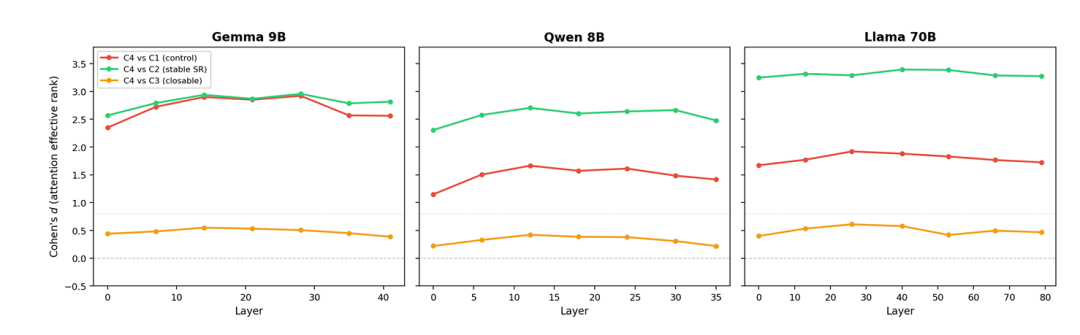
图2:不同模型在不同层之间的有效秩改变
从异常动力学到模型自省:理解大模型推理边界的新窗口
除了揭示 NCTR 的内部机制之外,这项研究最重要的贡献在于提出了注意力有效秩这一可量化指标,可用来判断大模型在推理时是否因悖论导致推理困难。实验表明,当模型处理 NCTR 类输入时,有效秩会出现持续升高的趋势,并与模型产生矛盾回答、不确定输出等现象相对应。
这意味着,相比仅关注最终生成结果,研究人员或许能够通过模型内部的动力学信号,更早发现推理过程中出现的异常状态。在云栈社区的技术讨论中,我们时常思考:未来,如果能够建立更加可靠的判据,这类指标有望帮助模型识别自身是否正陷入无法闭合的推理循环,并在适当情况下主动给出“无法判定”或“不足以判断”的回答,而非继续生成表面连贯却缺乏逻辑支撑的内容。
从更广泛的角度来看,这项工作也为 AI 安全与可靠性研究提供了新的观察视角。目前关于模型鲁棒性、幻觉以及对齐问题的研究,大多聚焦于输出结果是否正确。然而本研究显示,一些特殊输入可能在模型内部引发跨层传播的系统性状态变化,而这些变化未必能够从最终输出中直接观察到。相比“模型说了什么”,研究其“如何计算”或许同样重要。
这一发现也对大模型可解释性研究提出了新的启发。传统方法往往关注单个神经元、特定注意力头或局部电路的功能,希望通过定位关键组件解释模型行为。但 NCTR 现象表明,某些异常状态更像是一种网络范围内的集体动力学行为,其影响会在多个层级间传播和累积,而非源于某个单独模块的失效。
换言之,大模型中的部分认知现象,可能并不存在明确的“责任神经元”或“错误注意力头”,而是由分布在整个网络中的协同计算过程共同产生。这也意味着,理解模型的复杂行为,或许需要从局部组件分析进一步走向整体 动力学 分析。
更进一步看,类似有效秩这样的内部状态指标,还可能成为未来构建模型自我监测机制的重要基础。如果模型能够持续追踪自身计算过程是否趋于稳定、是否陷入递归循环或产生持续冲突的表征状态,那么其推理过程将不仅包含“生成答案”,还可能具备一定程度的“监测自身推理状态”的能力。
当然,这一方向目前仍处于探索阶段。有效秩尚不能直接等同于模型的“元认知”或“自我觉察”,但这项研究至少提供了一个值得关注的线索:在某些情况下,大模型的内部动力学变化或许能够成为理解其推理边界、自省能力以及可靠性的关键窗口。
从这个意义上说,弄清模型为何会在自指悖论和非闭合递归面前表现出异常动力学,不仅有助于理解当前大模型的局限,也可能为构建更加可靠、能够识别自身认知边界的下一代语言模型提供理论基础。
论文信息

 发表于 2026-6-17 00:48:40
|
查看: 146|
回复: 0
发表于 2026-6-17 00:48:40
|
查看: 146|
回复: 0
